【LLM】LLaMA-Factory 训练模型入门指南
1. 前言
这篇文章主要带你了解如何使用 LLaMA-Factory 来微调大模型,包括如何安装、如何使用其web可视化界面训练、在线测试、导出模型等。
你可以先阅读我的这篇文章,了解 QLoRA 微调流程 一篇文章带你入门QLoRA微调。
2. 安装
2.1 从源码安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
建议使用虚拟环境管理 python 依赖,我这里使用 uv (也可以使用 conda)。
# 安装 uv
pip install uv# 进入项目目录
cd LLaMA-Factory# 创建基于 python 3.11 的虚拟环境
uv venv --python=3.11# 激活虚拟环境
.\.venv\Scripts\activate# 安装依赖
pip install -e ".[torch,metrics]" --no-build-isolation
2.2 验证
验证 torch 是否正确安装
# 验证 GPU 版torch是否安装,返回true说明安装正确
python -c "import torch; print(torch.cuda.is_available())"
如果返回 false,请参考我之前的文章,安装对应版本的 cuda
【踩坑笔记】50系显卡适配的 PyTorch 安装_cuda13.0对应pytorch-CSDN博客
我的显卡型号为:NVIDIA GeForce RTX 5070 Ti Laptop,50系显卡可参考以下命令安装:
# 先卸载(可选)
pip uninstall torch torchvision
# 安装
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu129
安装完成后,继续执行上述验证代码查看是否正确安装。
验证 llamafactory 是否正确安装
# 出现下图说明成功
llamafactory-cli version

2.3 LLaMA Board 可视化微调
llamafactory-cli webui
启动成功

浏览器访问:http://127.0.0.1:7860 进入 LLaMA Factory web 面板。
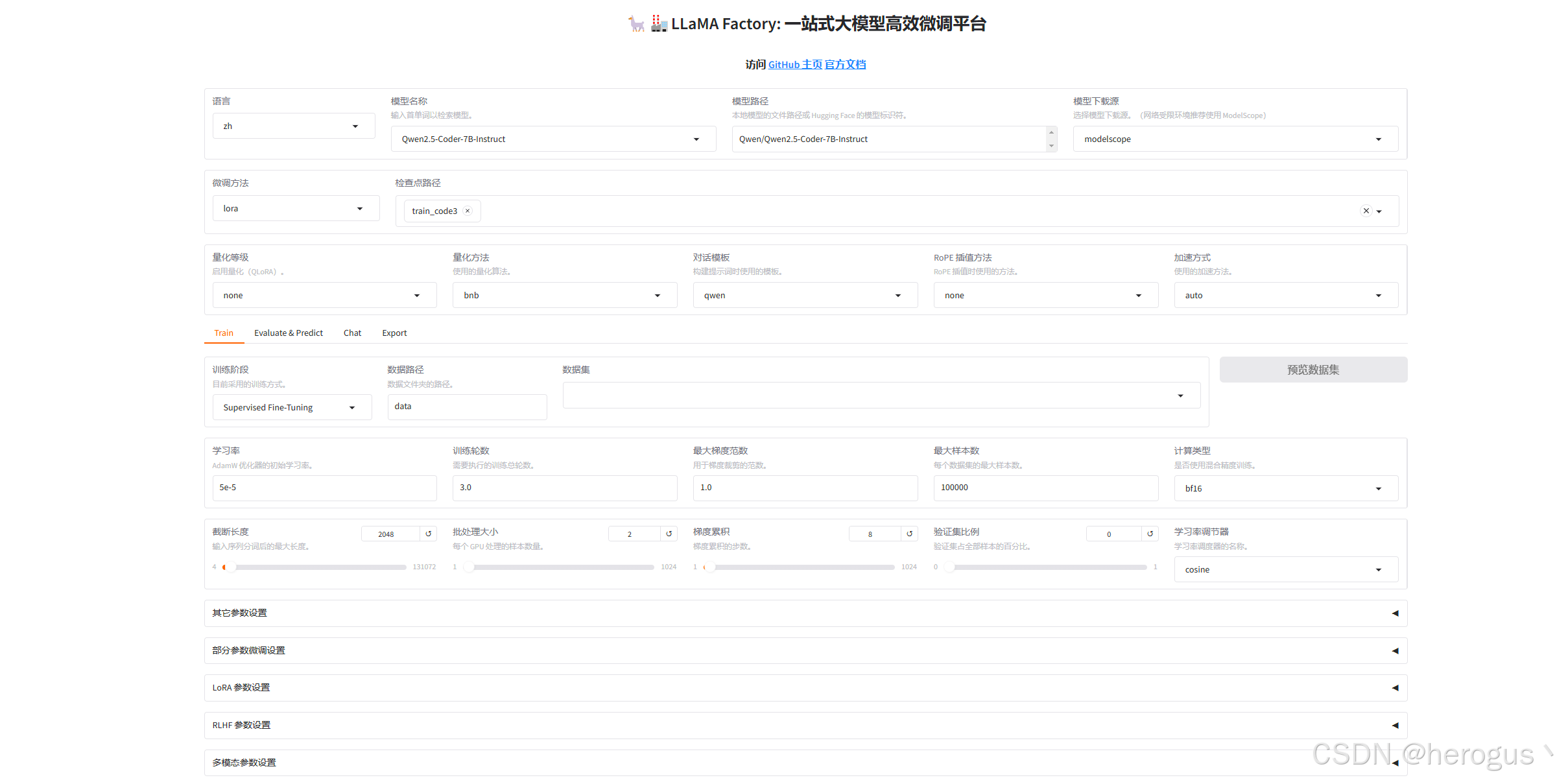
3. 数据集准备
在训练之前我们需要先准备数据集,LLaMA-Factory 支持HuggingFace / ModelScope / Modelers 上的数据集或加载本地数据集。如何配置参考:
LLaMA-Factory/data/README_zh.md at main · hiyouga/LLaMA-Factory
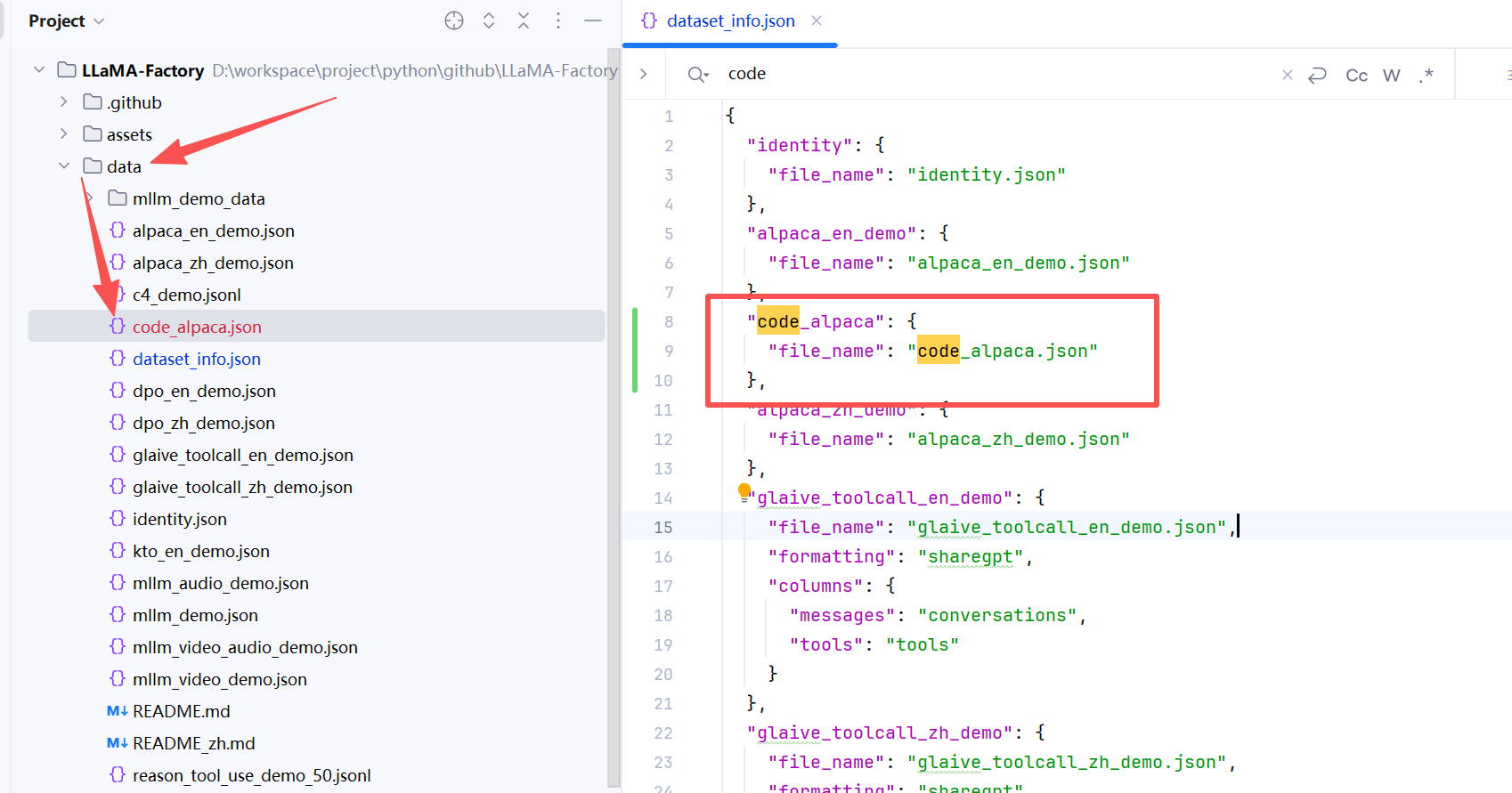
以配置本地数据集为例,首先将数据集放到 /data 路径下,然后打开 dataset_info.json 文件,增加如下配置:
"code_alpaca": {"file_name": "code_alpaca.json"
},
4. 模型训练(Train)
4.1 基础配置
配置你要训练的模型以及是否启用量化等信息。

4.2 训练配置
可配置一些训练相关的参数,learning_rate(初始学习率)、num_train_epochs(训练轮数)、per_device_train_batch_size(每个 GPU 处理的样本数量)等等
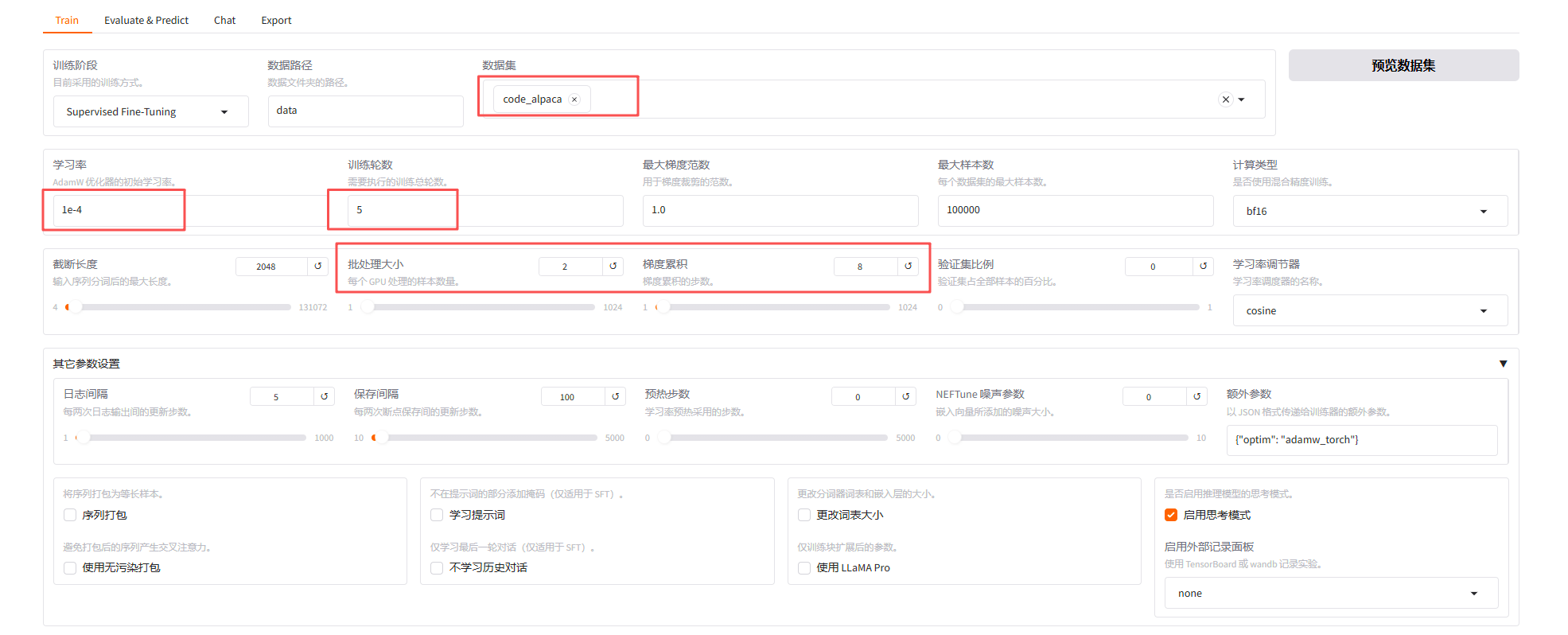
4.3 其他参数配置
参数配置可参考:参数介绍

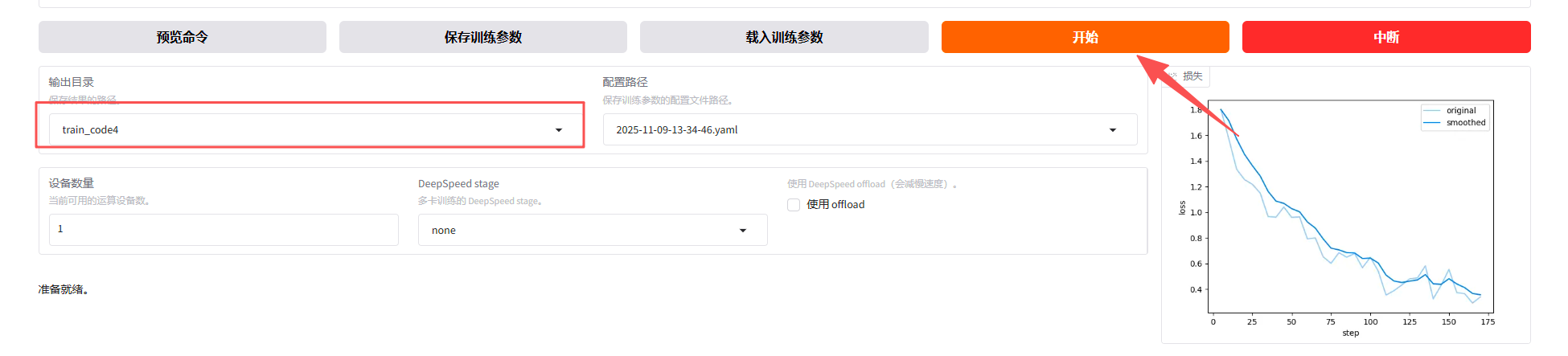
4.4 开始训练
点击 开始 按钮即可开始训练,你可以在这边预览 llamafactory-cli 训练命令。
llamafactory-cli 命令
llamafactory-cli train `--stage sft `--do_train True `--model_name_or_path Qwen/Qwen2.5-Coder-7B-Instruct `--preprocessing_num_workers 16 `--finetuning_type lora `--template qwen `--flash_attn auto `--dataset_dir data `--dataset code_alpaca `--cutoff_len 2048 `--learning_rate 0.0001 `--num_train_epochs 5.0 `--max_samples 100000 `--per_device_train_batch_size 2 `--gradient_accumulation_steps 8 `--lr_scheduler_type cosine `--max_grad_norm 1.0 `--logging_steps 5 `--save_steps 100 `--warmup_steps 0 `--packing False `--enable_thinking True `--report_to none `--output_dir saves\Qwen2.5-Coder-7B-Instruct\lora\train_code4 `--bf16 True `--plot_loss True `--trust_remote_code True `--ddp_timeout 180000000 `--include_num_input_tokens_seen True `--optim adamw_torch `--quantization_bit 4 `--quantization_method bnb `--double_quantization True `--lora_rank 8 `--lora_alpha 16 `--lora_dropout 0 `--lora_target all
训练日志截图:可以看到训练总步数等信息。

4.5 loss曲线
4.5.1 什么是 loss 曲线
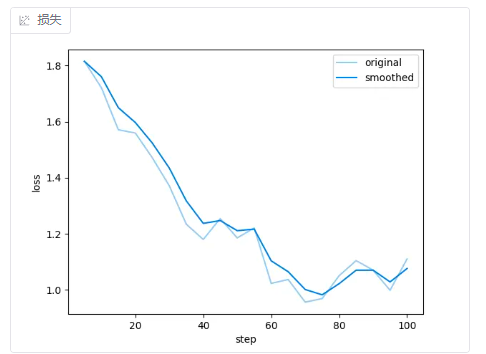
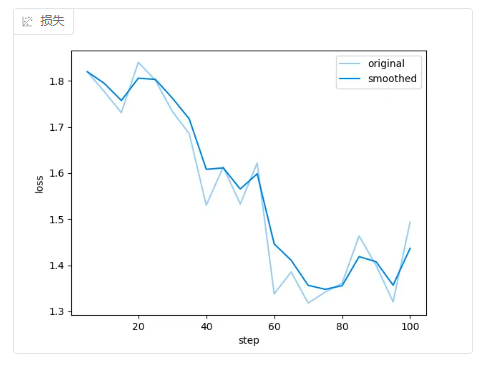
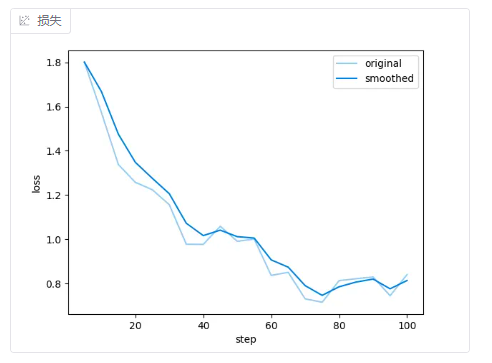
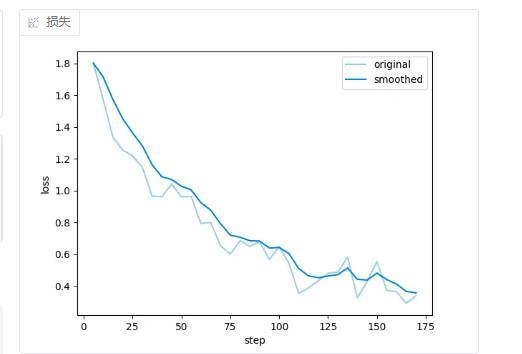
Loss 曲线(损失函数曲线) 展示模型在训练过程中的误差随迭代次数(或 epoch)变化的趋势。
理想情况是:持续下降,趋于稳定
4.5.2 original 和 smoothed 曲线
| 名称 | 含义 | 特点 | 常见用途 |
|---|---|---|---|
| Original curve(原始曲线) | 数据未经平滑处理,直接绘制的曲线 | 保留所有波动、噪声明显 | 用于展示真实观测值或模型输出的原貌 |
| Smoothed curve(平滑曲线) | 通过数学方法去除短期波动,使趋势更清晰 | 噪声减少,更易观察整体趋势 | 用于趋势分析、可视化优化、报告展示 |
示例
针对我的数据集,下面是不同 学习率 + **训练轮数 **的loss曲线。
- 5e-5 + 3轮
- 2e-5 + 3轮
- 1e-4 + 3轮
- 1e-4 +** 5轮**
5. 模型对话(Chat)
检查点路径选择上面训练阶段结果导出的路径,然后点击加载模型,即可在web端与模型对话。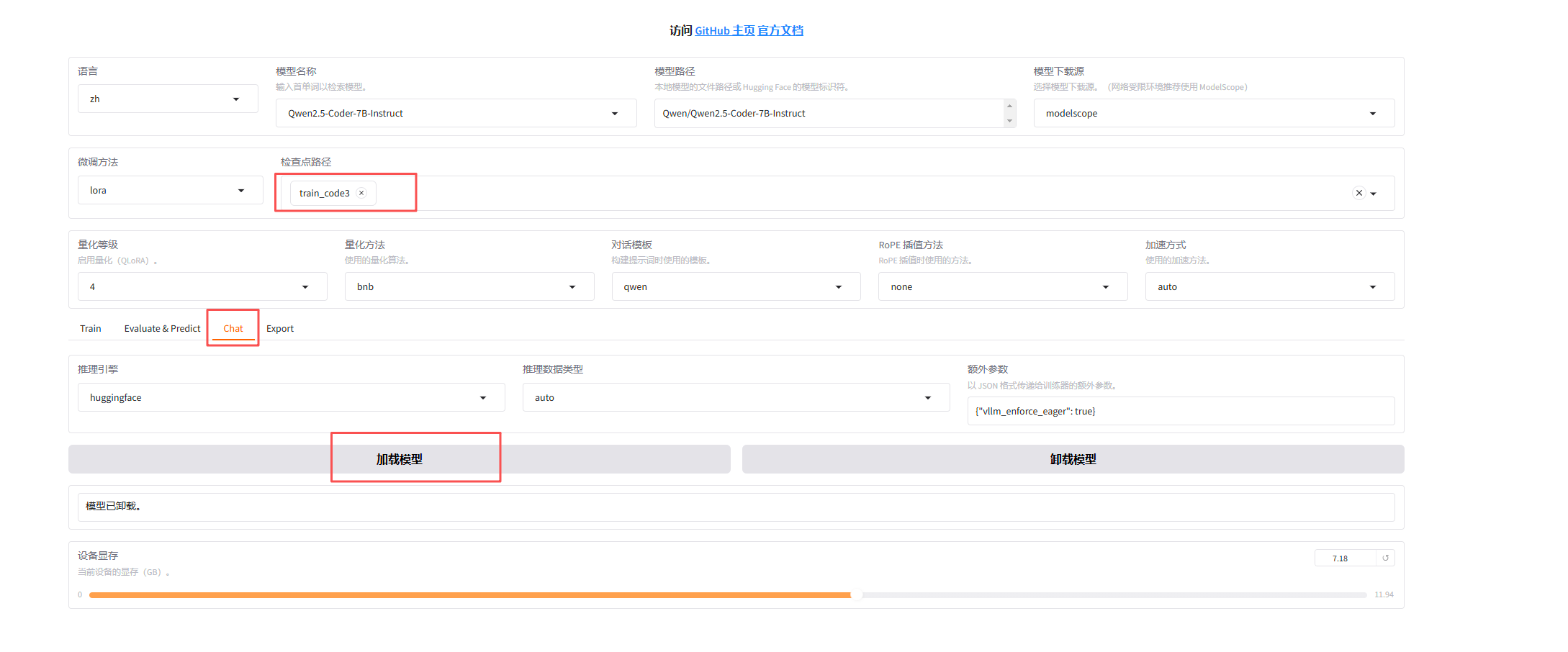
6. 导出
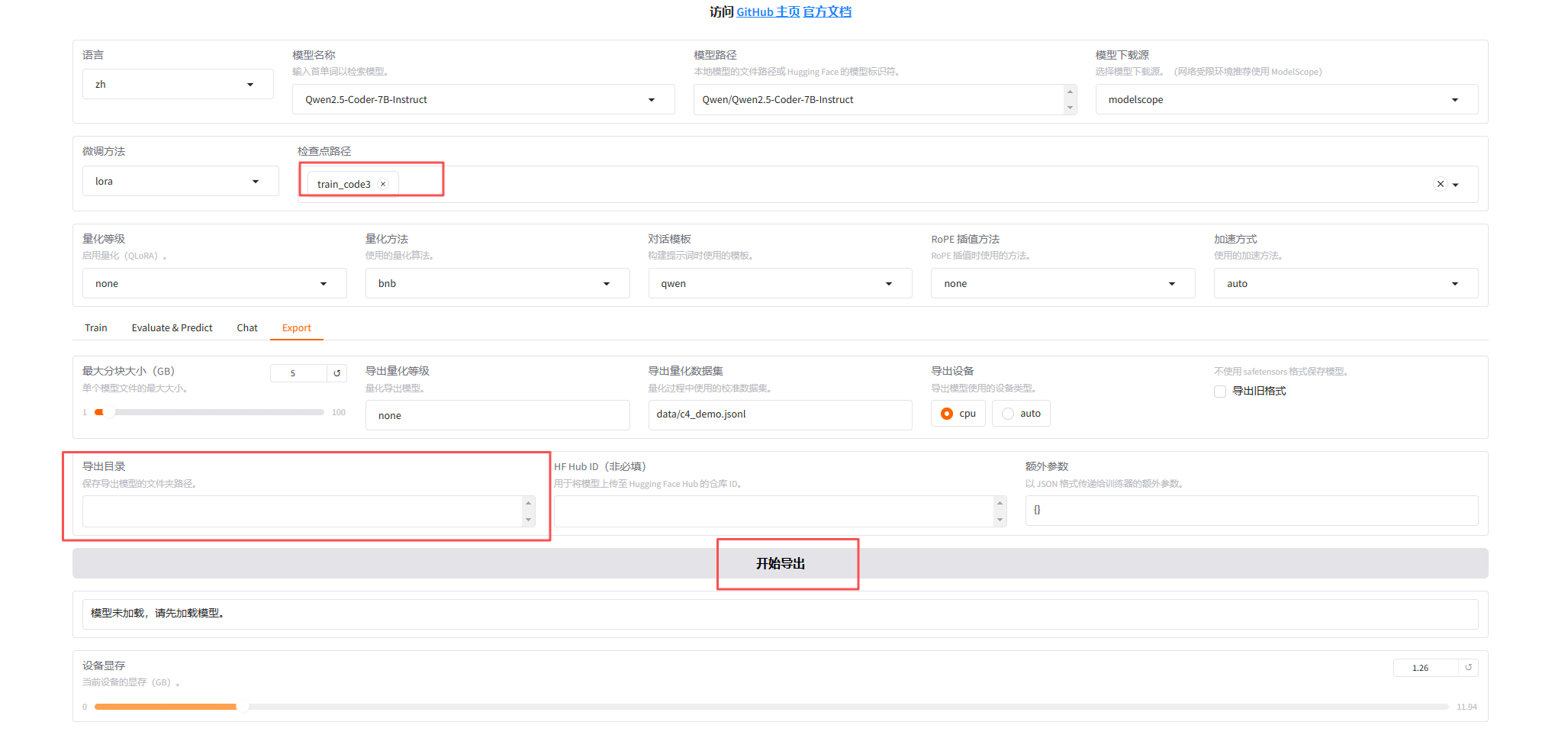
检查点路径选择上面训练阶段结果导出的路径,然后点击 开始导出,即可导出模型。
7. 参考文档
LLaMA-Factory github
LLaMA Factory-参数介绍