【NLP】Penn Treebank 与 Parsing:让计算机看懂句子结构
Penn Treebank 与 Parsing:让计算机看懂句子结构
让我们举一个从古至今津津乐道的例子:
浮云长长长长长长长消
你能一下子读懂吗?
如果用不同的停顿方式,这句话可能有完全不同的意思:
-
浮云涨,常常涨,常涨常消 说这云经常涨啊,还经常消失。
-
浮云长,常长常长,常常消
说这云可真长啊,经常这么长,还经常消失。 -
还有别的断句方法可参考 https://zhuanlan.zhihu.com/p/400511819
同样的字,如果没有结构,就会出现多种理解方式——这就是歧义。
而我们的大脑之所以能在语境中选出一种“最顺”的读法,是因为它在无意识中画出了一棵语法树:哪几个字是一组(短语)?哪个动作修饰谁?哪些部分是描述,哪些是主要事件?
对计算机来说,如果想正确理解这句话,也必须学会画语法树。
而这项工作,就叫做 Parsing(句法分析)——让机器和我们一样,识别句子的结构,排除错误的理解。
语法上,我们会分为:主语、谓语、宾语、修饰语……这种分层结构,就像一棵语法树(Syntax Tree)。
比如:
“北京是属于中国的。”
如果画成语法树,
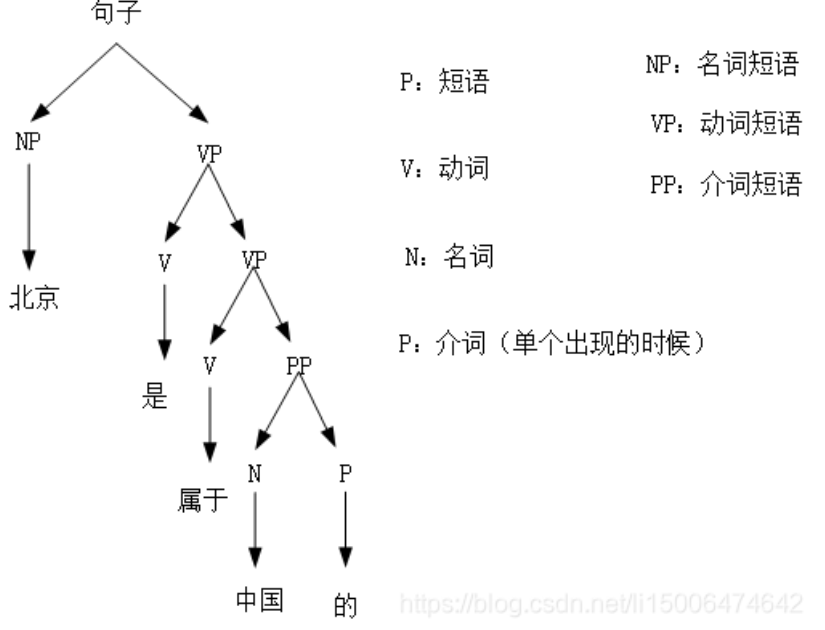
[1]
在这里,“北京”这个名词是主语,之后是谓