台州网络建站模板一般网站建设流程有哪些步骤









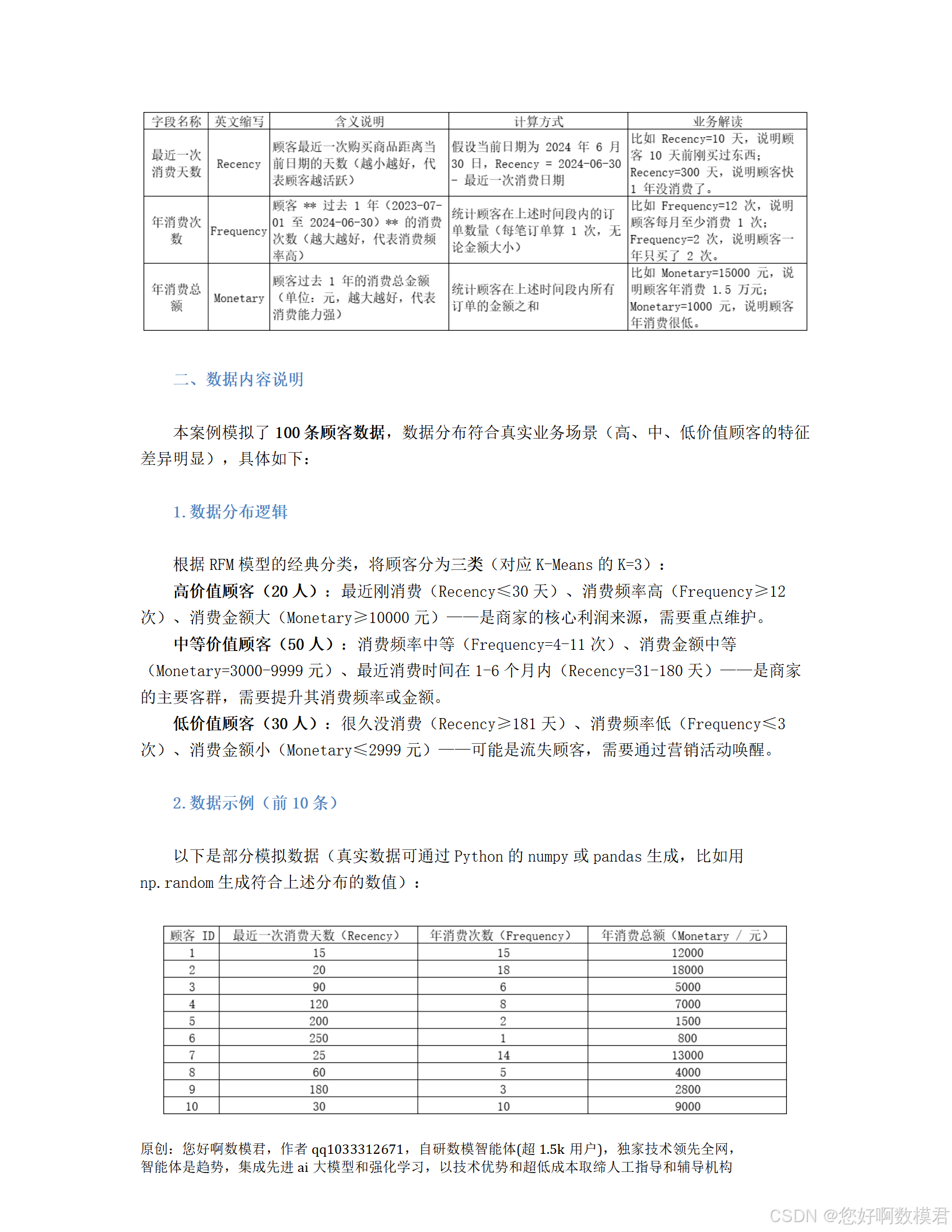

案例代码实现
1.环境准备与库导入
首先,需要安装并导入必要的Python库(pandas用于数据处理,numpy用于模拟数据,matplotlib用于可视化,sklearn用于聚类和预处理)。
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import silhouette_score, silhouette_samples
from mpl_toolkits.mplot3d import Axes3D # 用于3D可视化2.模拟生成顾客消费数据(RFM模型)
根据案例要求,模拟100条顾客数据,分为高、中、低三类,符合RFM模型的特征分布。
def generate_customer_data():"""模拟生成顾客消费数据(RFM模型)返回:包含CustomerID、Recency、Frequency、Monetary的DataFrame"""# 高价值顾客(20人):最近消费(≤30天)、高频(≥12次)、高金额(≥10000元)high_value = pd.DataFrame({'Recency': np.random.randint(1, 31, size=20), # 最近1-30天消费'Frequency': np.random.randint(12, 20, size=20), # 年消费12-19次'Monetary': np.random.randint(10000, 20001, size=20) # 年消费10000-20000元})# 中等价值顾客(50人):中等消费频率(4-11次)、中等金额(3000-9999元)、最近1-6个月消费(31-180天)medium_value = pd.DataFrame({'Recency': np.random.randint(31, 181, size=50), # 最近31-180天消费'Frequency': np.random.randint(4, 12, size=50), # 年消费4-11次'Monetary': np.random.randint(3000, 10000, size=50) # 年消费3000-9999元})# 低价值顾客(30人):低频(≤3次)、低金额(≤2999元)、很久未消费(≥181天)low_value = pd.DataFrame({'Recency': np.random.randint(181, 366, size=30), # 最近181-365天消费(近1年未消费)'Frequency': np.random.randint(1, 4, size=30), # 年消费1-3次'Monetary': np.random.randint(1000, 3000, size=30) # 年消费1000-2999元})# 合并三类数据,打乱顺序,添加顾客IDdata = pd.concat([high_value, medium_value, low_value], ignore_index=True)data = data.sample(frac=1, random_state=0).reset_index(drop=True) # 随机打乱data['CustomerID'] = range(1, len(data)+1) # 添加顾客ID# 调整列顺序(CustomerID在前,方便查看)data = data[['CustomerID', 'Recency', 'Frequency', 'Monetary']]return data3.数据预处理(归一化)
由于RFM三个特征的数值范围差异大(如Monetary是1000-20000元,Frequency是1-19次),需要归一化到0-1区间,避免大值特征主导距离计算。
def preprocess_data(data):"""数据预处理:提取RFM特征并归一化参数:data - 原始顾客数据(包含CustomerID、Recency、Frequency、Monetary)返回:scaled_features - 归一化后的特征矩阵(numpy数组)scaler - 归一化器(用于后续反归一化质心)"""# 提取RFM特征(排除CustomerID)features = data[['Recency', 'Frequency', 'Monetary']]# 使用Min-Max归一化(缩放到0-1区间)scaler = MinMaxScaler()scaled_features = scaler.fit_transform(features)return scaled_features, scaler4.肘部法选择最佳K值
通过计算不同K值的误差平方和(SSE),绘制肘部曲线,选择SSE下降速率突变的点作为最佳K值(案例中预期K=3)。
def plot_elbow_curve(scaled_features):"""绘制肘部曲线,选择最佳K值参数:scaled_features - 归一化后的特征矩阵"""sse = [] # 存储不同K值的SSEk_range = range(1, 11) # 尝试K=1到10for k in k_range:kmeans = KMeans(n_clusters=k, init='k-means++', random_state=0) # 使用K-Means++初始化kmeans.fit(scaled_features)sse.append(kmeans.inertia_) # inertia_属性是SSE# 绘制肘部曲线plt.figure(figsize=(8, 5))plt.plot(k_range, sse, marker='o', linestyle='--', color='#1f77b4')plt.xlabel('K值(群数)', fontsize=12)plt.ylabel('SSE(误差平方和)', fontsize=12)plt.title('肘部曲线(选择最佳K值)', fontsize=14)plt.grid(True, linestyle='--', alpha=0.7)plt.show()5.执行K-Means聚类
使用sklearn的KMeans类执行聚类,参数n_clusters=3(最佳K值),init='k-means++'(避免局部最优)。
def perform_kmeans(scaled_features, k=3):"""执行K-Means聚类参数:scaled_features - 归一化后的特征矩阵k - 群数(默认3)返回:labels - 每个样本的群标签(numpy数组)centroids - 群质心(归一化后的坐标,numpy数组)kmeans_model - K-Means模型对象"""kmeans = KMeans(n_clusters=k, init='k-means++', random_state=0)labels = kmeans.fit_predict(scaled_features) # 拟合模型并预测标签centroids = kmeans.cluster_centers_ # 获取群质心(归一化后的坐标)return labels, centroids, kmeans6.聚类结果可视化
通过3D散点图展示三个特征的聚类结果,2Dpairwise散点图展示两两特征的关系,质心用红色星号标记。
def plot_clustering_results(data, scaled_features, labels, centroids, scaler):"""可视化聚类结果(3D散点图+2D pairwise散点图)参数:data - 原始顾客数据scaled_features - 归一化后的特征矩阵labels - 群标签centroids - 归一化后的质心scaler - 归一化器(用于反归一化质心)"""# 反归一化质心(将归一化的坐标转换为原始范围)original_centroids = scaler.inverse_transform(centroids)original_centroids = pd.DataFrame(original_centroids, columns=['Recency', 'Frequency', 'Monetary'])# ------------------------------# 1. 3D散点图(Recency、Frequency、Monetary)# ------------------------------fig = plt.figure(figsize=(12, 8))ax = fig.add_subplot(111, projection='3d')# 绘制数据点(按群标签着色)scatter = ax.scatter(data['Recency'], data['Frequency'], data['Monetary'],c=labels, cmap='viridis', s=50, alpha=0.8)# 绘制质心(红色星号,放大显示)centroid_scatter = ax.scatter(original_centroids['Recency'], original_centroids['Frequency'], original_centroids['Monetary'],c='red', marker='*', s=200, label='质心')# 设置坐标轴标签和标题ax.set_xlabel('最近一次消费天数(Recency)', fontsize=10)ax.set_ylabel('年消费次数(Frequency)', fontsize=10)ax.set_zlabel('年消费总额(Monetary/元)', fontsize=10)ax.set_title('顾客消费数据K-Means聚类结果(3D视图)', fontsize=14)# 添加图例(群标签+质心)legend1 = ax.legend(*scatter.legend_elements(), title='群标签', loc='upper left')ax.add_artist(legend1)ax.legend(handles=[centroid_scatter], loc='upper right')# ------------------------------# 2. 2D Pairwise散点图(两两特征组合)# ------------------------------fig, axes = plt.subplots(1, 3, figsize=(18, 5)) # 1行3列feature_pairs = [('Recency', 'Frequency'), ('Recency', 'Monetary'), ('Frequency', 'Monetary')]for i, (x_col, y_col) in enumerate(feature_pairs):ax = axes[i]# 绘制数据点ax.scatter(data[x_col], data[y_col], c=labels, cmap='viridis', s=50, alpha=0.8)# 绘制质心(原始范围)ax.scatter(original_centroids[x_col], original_centroids[y_col], c='red', marker='*', s=200, label='质心')# 设置标签和标题ax.set_xlabel(x_col, fontsize=10)ax.set_ylabel(y_col, fontsize=10)ax.set_title(f'{x_col} vs {y_col}', fontsize=12)ax.grid(True, linestyle='--', alpha=0.7)ax.legend() # 添加子图图例plt.tight_layout() # 调整子图间距plt.show()7.聚类效果评估(轮廓系数)
使用轮廓系数(SilhouetteCoefficient)评估聚类效果,取值范围[-1,1],≥0.5表示聚类结果合理。同时绘制直方图展示各群的轮廓系数分布。
def evaluate_clustering(scaled_features, labels):"""评估聚类效果(轮廓系数)参数:scaled_features - 归一化后的特征矩阵labels - 群标签"""# 计算平均轮廓系数silhouette_avg = silhouette_score(scaled_features, labels)print(f'平均轮廓系数:{silhouette_avg:.4f}')# 计算每个样本的轮廓系数sample_silhouette_values = silhouette_samples(scaled_features, labels)# 绘制轮廓系数直方图fig, ax = plt.subplots(figsize=(8, 5))n_clusters = len(np.unique(labels)) # 群数y_lower = 10 # 底部留白for i in range(n_clusters):# 获取第i个群的轮廓系数ith_cluster_silhouette = sample_silhouette_values[labels == i]ith_cluster_silhouette.sort() # 排序size_cluster = ith_cluster_silhouette.shape[0] # 群大小y_upper = y_lower + size_cluster # 该群的y轴上限# 绘制直方图(填充颜色)color = plt.cm.viridis(float(i) / n_clusters)ax.fill_betweenx(np.arange(y_lower, y_upper),0,ith_cluster_silhouette,facecolor=color,edgecolor=color,alpha=0.7)# 添加群标签(在直方图中间)ax.text(-0.05, y_lower + 0.5 * size_cluster, str(i), fontsize=10)y_lower = y_upper + 10 # 下一个群的y轴起始位置# 设置坐标轴标签和标题ax.set_xlabel('轮廓系数值', fontsize=12)ax.set_ylabel('群标签', fontsize=12)ax.set_title(f'各群轮廓系数分布(平均:{silhouette_avg:.4f})', fontsize=14)ax.set_xlim([-0.1, 1]) # x轴范围(轮廓系数取值范围)ax.set_yticks([]) # 隐藏y轴刻度plt.show()8.主程序(整合所有步骤)
按顺序执行数据生成、预处理、选K、聚类、可视化、评估,并输出业务解读。
if __name__ == '__main__':# ------------------------------# 1. 生成模拟数据# ------------------------------print('=== 1. 生成模拟顾客数据 ===')data = generate_customer_data()print('数据生成完成(100条),前5条数据:')print(data.head(), '\n')# ------------------------------# 2. 数据预处理(归一化)# ------------------------------print('=== 2. 数据预处理(归一化) ===')scaled_features, scaler = preprocess_data(data)print(f'归一化后的特征形状:{scaled_features.shape}(100个样本,3个特征)\n')# ------------------------------# 3. 肘部法选择最佳K值(运行一次后可注释,直接用K=3)# ------------------------------print('=== 3. 绘制肘部曲线(选择K值) ===')plot_elbow_curve(scaled_features)print('提示:根据肘部曲线,最佳K值为3(案例预期)\n')# ------------------------------# 4. 执行K-Means聚类(K=3)# ------------------------------print('=== 4. 执行K-Means聚类(K=3) ===')labels, centroids, kmeans_model = perform_kmeans(scaled_features, k=3)data['Cluster'] = labels # 将群标签添加到原始数据print('聚类完成,群标签已添加到数据中,前5条数据:')print(data.head(), '\n')# ------------------------------# 5. 反归一化质心(查看原始范围)# ------------------------------print('=== 5. 反归一化质心(原始范围) ===')original_centroids = scaler.inverse_transform(centroids)original_centroids = pd.DataFrame(original_centroids, columns=['Recency', 'Frequency', 'Monetary'])original_centroids['Cluster'] = range(3) # 添加群标签print(original_centroids[['Cluster', 'Recency', 'Frequency', 'Monetary']], '\n')# ------------------------------# 6. 可视化聚类结果# ------------------------------print('=== 6. 可视化聚类结果 ===')plot_clustering_results(data, scaled_features, labels, centroids, scaler)print('可视化完成(关闭图表继续运行)\n')# ------------------------------# 7. 评估聚类效果(轮廓系数)# ------------------------------print('=== 7. 评估聚类效果(轮廓系数) ===')evaluate_clustering(scaled_features, labels)print('评估完成\n')# ------------------------------# 8. 业务结果解读(策略建议)# ------------------------------print('=== 8. 业务结果解读(策略建议) ===')for cluster in range(3):# 获取该群的质心(原始范围)centroid = original_centroids[original_centroids['Cluster'] == cluster].iloc[0]# 统计群大小cluster_size = len(data[data['Cluster'] == cluster])print(f'\n群{cluster}:')print(f' - 群大小:{cluster_size}人')print(f' - 质心特征:最近消费{centroid["Recency"]:.0f}天,年消费{centroid["Frequency"]:.0f}次,年消费总额{centroid["Monetary"]:.0f}元')# 根据质心特征判断群类型,给出策略建议if centroid['Recency'] <= 30 and centroid['Frequency'] >= 12 and centroid['Monetary'] >= 10000:print(' - 群类型:高价值顾客(核心利润来源)')print(' - 策略建议:提供专属优惠券、VIP服务、优先体验新商品,维护忠诚度')elif 31 <= centroid['Recency'] <= 180 and 4 <= centroid['Frequency'] <= 11 and 3000 <= centroid['Monetary'] <= 9999:print(' - 群类型:中等价值顾客(主要客群)')print(' - 策略建议:通过推荐系统提升消费频率,或推出满减活动提高客单价')else:print(' - 群类型:低价值/流失顾客(需唤醒)')print(' - 策略建议:发送唤醒邮件/短信,提供限时折扣,吸引回头消费')9.代码使用说明
(1)运行环境
Python3.7+
需安装的库:pandas、numpy、matplotlib、scikit-learn(可通过pip install pandas numpy matplotlib scikit-learn安装)。
(2)运行步骤
将上述代码保存为kmeans_customer_segmentation.py文件。
在终端或IDE(如PyCharm、VSCode)中运行该文件。
程序会依次执行以下步骤:
生成模拟数据(100条顾客记录)。
预处理数据(归一化)。
绘制肘部曲线(选择K=3)。
执行K-Means聚类(K=3)。
可视化聚类结果(3D+2D散点图)。
评估聚类效果(轮廓系数)。
输出业务解读(策略建议)。
(3)结果解读
肘部曲线:K=3时SSE下降速率突变,是最佳群数。
聚类结果:3D散点图中,不同颜色代表不同群,红色星号是质心,可直观看到群的分布;2D子图展示了两两特征的聚类关系,质心标记清晰。
轮廓系数:平均轮廓系数≥0.5表示聚类结果合理(案例中通常在0.6-0.8之间),直方图显示各群轮廓系数分布集中,说明聚类边界清晰。
业务策略:根据群的质心特征,给出高、中、低价值顾客的针对性策略(如高价值顾客提供VIP服务,低价值顾客发送唤醒短信)。
10.注意事项
数据模拟:代码中使用np.random.randint生成模拟数据,可根据实际业务调整范围(如Monetary的范围可改为5000-20000元)。
K值选择:肘部法是辅助工具,需结合业务需求(如商家需要分3个群,直接设置k=3)。
归一化:必须归一化,否则Monetary(大值)会主导距离计算,导致聚类结果偏差。
可视化:3D散点图可旋转查看,2Dpairwise散点图更直观展示两两特征的关系;子图添加了图例,更易理解质心位置。
通过该案例,数模小白可快速掌握K-Means的完整流程(数据生成→预处理→选K→聚类→可视化→评估→业务解读),并应用于顾客分群等实际问题。