【大模型学习3】预训练语言模型详解
预训练语言模型详解
一、引言
在自然语言处理(NLP)领域,Transformer模型的出现带来了革命性的变革。基于Transformer架构,研究者们发展出了多种预训练语言模型(PLM),这些模型通过"预训练+微调"的模式,在各类NLP任务中取得了突破性进展。
根据对Transformer结构的不同使用方式,预训练语言模型可分为三大类:
- Encoder-only(仅使用编码器)
- Decoder-only(仅使用解码器)
- Encoder-Decoder(同时使用编码器和解码器)
本章将详细介绍这三类模型中最具代表性的主流预训练模型,包括它们的架构设计、预训练任务和核心优势。
二、Encoder-only预训练模型
Encoder-only模型基于Transformer的编码器部分构建,特别适合自然语言理解(NLU)任务。这类模型能够有效捕捉文本的双向语义信息,在文本分类、命名实体识别等任务中表现出色。
2.1 BERT:双向编码器的里程碑
BERT(Bidirectional Encoder Representations from Transformers)是Google于2018年发布的预训练模型,在多个NLP任务上刷新了当时的最优性能,标志着预训练模型时代的正式到来。
2.1.1 核心思想
BERT的成功源于两个关键思想的融合:
- Transformer架构:采用Transformer的编码器堆叠而成,充分利用自注意力机制捕捉文本中的依赖关系
- 预训练+微调范式:先在海量无标注文本上进行预训练,再针对具体下游任务进行微调
2.1.2 模型架构
BERT的架构由三部分组成:
- 嵌入层(Embedding):将输入的文本token转换为向量表示,包含词嵌入、段嵌入和位置嵌入
- 编码器层(Encoder Layers):由多个Transformer编码器堆叠而成,Base版本包含12层,Large版本包含24层
- 预测头(prediction_heads):根据不同下游任务设计的输出层,通常是线性层加激活函数
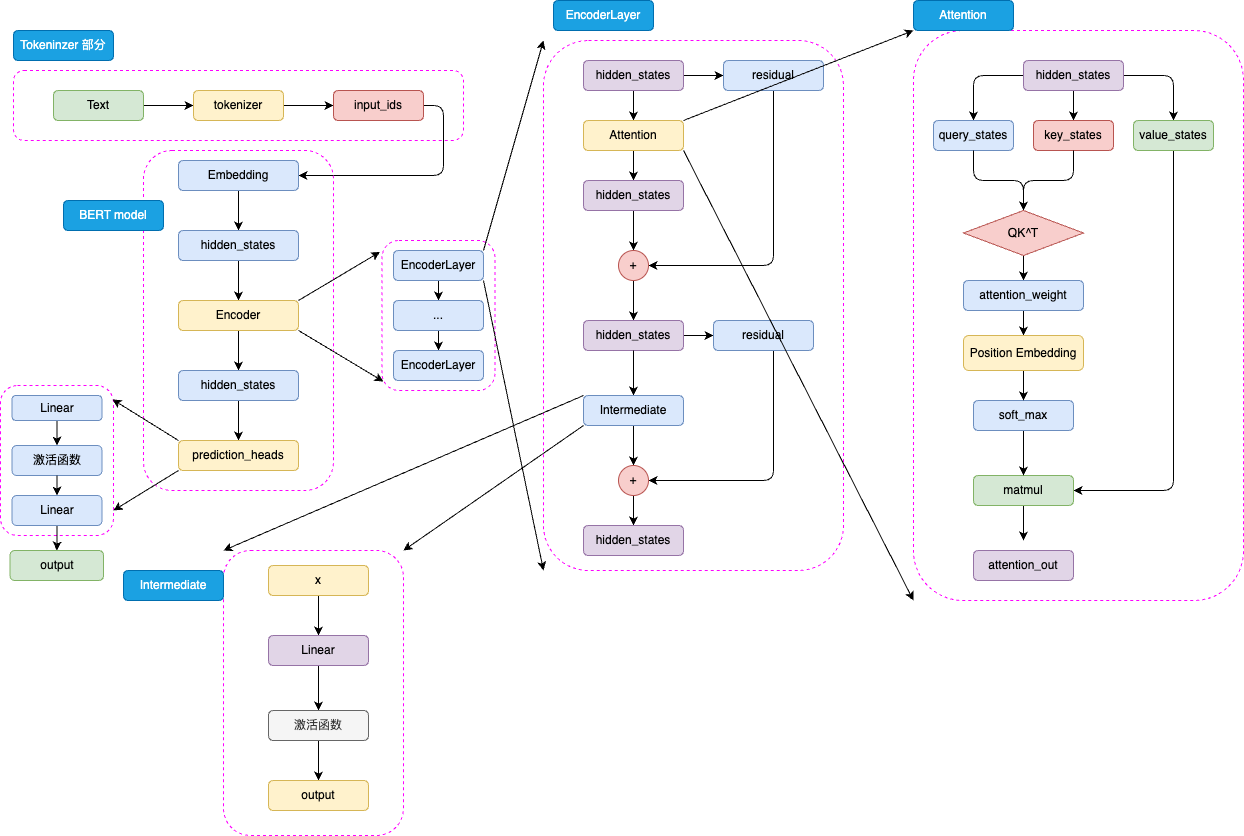
BERT采用WordPiece分词方法,将单词拆分为子词单元(如"playing"拆分为[“play”, “##ing”]),对于中文则通常以单个汉字作为基本单位。
值得注意的是,BERT使用GELU(高斯误差线性单元)作为激活函数,计算公式为:
GELU(x)=0.5x(1+tanh(2π)(x+0.044715x3))GELU(x) = 0.5x(1 + tanh(\sqrt{\frac{2}{\pi}})(x + 0.044715x^3))GELU(x)=0.5x(1+tanh(π2)(x+0.044715x3))
在位置编码方面,改进版BERT采用了可训练的相对位置编码,相比Transformer原始的绝对位置编码能更好地捕捉相对位置关系,但也限制了模型处理超过训练长度(512个token)的输入。
2.1.3 预训练任务
BERT的预训练包含两个创新任务:
-
掩码语言模型(MLM)
- 随机选择15%的token进行特殊处理:
- 80%概率替换为
<MASK>标记 - 10%概率替换为随机token
- 10%概率保持原token不变
- 80%概率替换为
- 模型需要预测被处理的原始token
- 优势:使模型能够学习双向语义关系
- 解决预训练与微调不一致问题:通过保留10%的原token
- 随机选择15%的token进行特殊处理:
-
下一句预测(NSP)
- 输入由两个句子组成,模型判断它们是否为连续的上下文
- 正样本:连续的两个句子
- 负样本:随机组合的两个句子
- 作用:帮助模型学习句子级别的语义关系
BERT使用了33亿个token的预训练数据,包括BooksCorpus(8亿token)和英文维基百科(25亿token),在TPU上训练了约4天。
2.1.4 下游任务微调
BERT通过统一的输入输出设计,能够高效适配多种下游任务:
- 在输入序列首部添加特殊token
<CLS>,其输出用于句子级任务 - 针对不同任务,只需修改预测头部分
- 微调过程使用少量标注数据,更新模型参数
BERT在11个NLP任务上取得了当时的最优结果,奠定了其在NLU领域的统治地位。
2.2 RoBERTa:优化版BERT
RoBERTa(Robustly Optimized BERT Pretraining Approach)是Facebook在BERT基础上进行优化改进的模型,通过调整训练策略进一步提升了性能。
2.2.1 主要改进
-
移除NSP任务
- 实验证明NSP任务对模型性能提升有限,甚至可能产生负面影响
- 仅保留MLM任务,使用更长的文本序列进行训练
-
动态遮蔽策略
- 将掩码操作从数据预处理阶段移至训练阶段
- 每个epoch中掩码的位置都不同,增强了模型的泛化能力
-
更大规模的训练数据
- 总数据量达160GB,是BERT的10倍
- 新增了CC-NEWS、OPENWEBTEXT和STORIES等数据集
-
其他优化
- 使用更大的batch size(8K,BERT为256)
- 所有训练都使用512长度的序列
- 采用更大的BPE词表(50K,BERT为30K)
RoBERTa的成功证明了更大规模的数据、更长的训练时间和更优的训练策略对模型性能的重要性。
2.3 ALBERT:轻量级BERT
ALBERT(A Lite BERT)专注于减少模型参数同时保持甚至提升性能,通过结构优化实现了更高效的预训练模型。
2.3.1 主要优化
-
嵌入参数分解
- 将词嵌入维度与隐藏层维度解耦
- 先将词嵌入映射到低维空间(如128维),再通过线性变换升至隐藏层维度(如1024维)
- 大幅减少嵌入层参数:从V×H变为V×E + E×H(E<<H)
-
跨层参数共享
- 所有编码器层共享同一套参数
- 24层模型仅需存储1层参数,显著减少总参数量
- 例如:ALBERT-xlarge(24层,2048维)仅59M参数,远少于BERT-large的334M
-
改进的预训练任务
- 提出句子顺序预测(SOP)任务替代NSP
- 正样本:连续的两个句子
- 负样本:交换顺序的两个句子
- 更专注于学习句子间的语义关系而非主题差异
尽管ALBERT参数量大幅减少,但由于计算步骤并未减少,其训练和推理速度提升有限,这也限制了它的广泛应用。
三、Encoder-Decoder预训练模型
Encoder-Decoder结构同时使用Transformer的编码器和解码器,兼顾了语言理解和生成能力,在机器翻译、文本摘要等序列到序列(Seq2Seq)任务中表现出色。
3.1 T5:文本到文本的统一框架
T5(Text-To-Text Transfer Transformer)是Google提出的一种通用预训练模型,其核心思想是将所有NLP任务统一表示为文本到文本的转换问题。
3.1.1 模型结构
T5采用完整的Encoder-Decoder架构:
- 编码器(Encoder):处理输入文本,生成上下文相关的表示
- 解码器(Decoder):基于编码器的输出生成目标文本
- 注意力机制:
- 编码器内部使用自注意力
- 解码器内部使用自注意力(带掩码,防止未来信息泄露)
- 解码器使用编码器-解码器注意力,关注输入文本信息
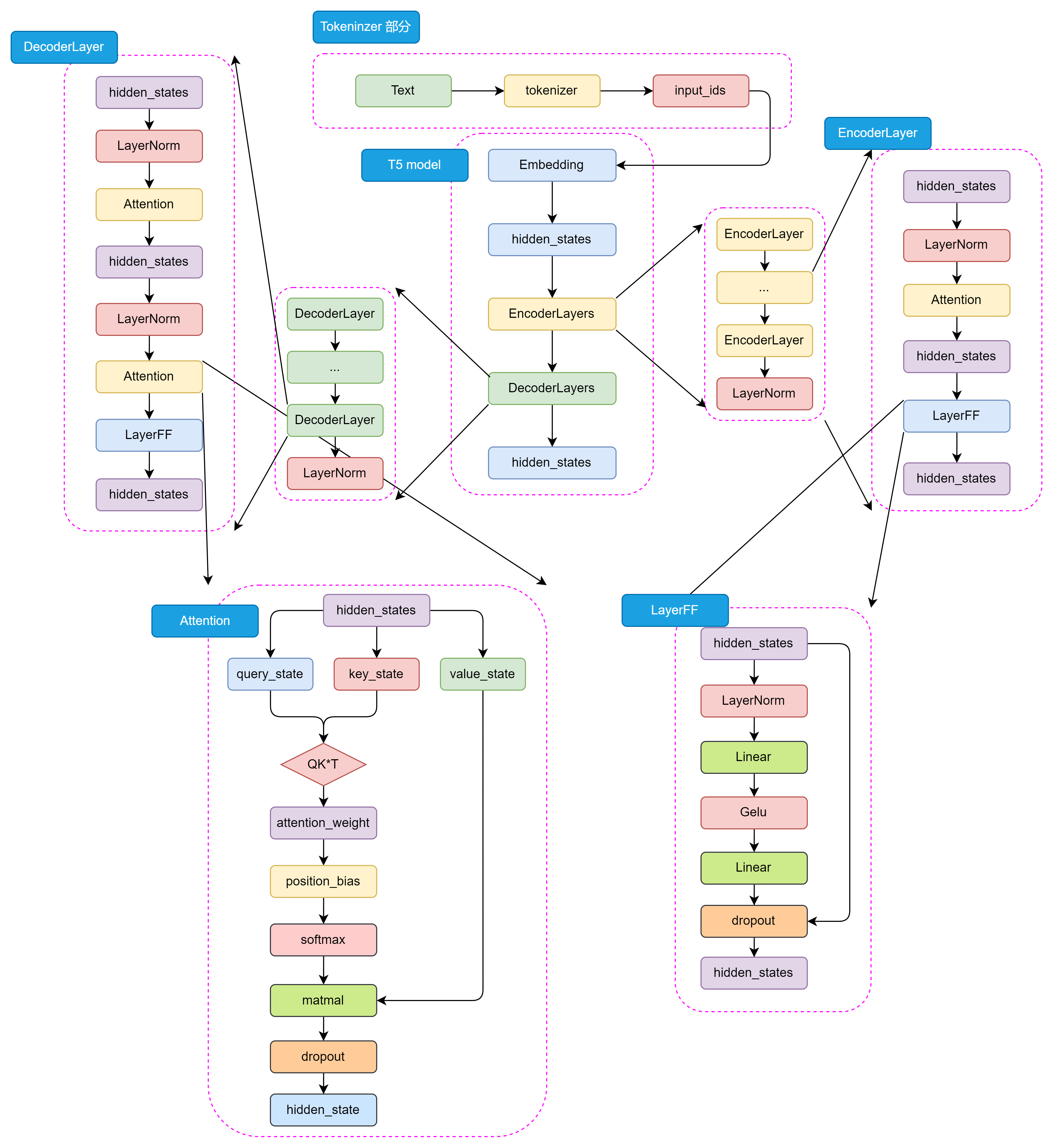
T5使用RMSNorm替代了传统的LayerNorm,计算公式为:
RMSNorm(x)=x1n∑i=1nxi2+ϵ⋅γ\text{RMSNorm}(x) = \frac{x}{\sqrt{\frac{1}{n}\sum_{i=1}^{n}x_i^2 + \epsilon}} \cdot \gammaRMSNorm(x)=n1∑i=1nxi2+ϵx⋅γ
其中γ\gammaγ是可学习的缩放参数,这种归一化方式参数更少,有助于稳定训练过程。
3.1.2 大一统思想
T5的创新之处在于将所有NLP任务统一为文本到文本的形式:
- 文本分类:输入"情感分析:这篇文章很棒",输出"积极"
- 机器翻译:输入"翻译为法语:Hello world",输出"Bonjour le monde"
- 问答任务:输入"问答:问题:地球是什么形状?答案:“,输出"圆形”
这种统一表示带来诸多优势:
- 简化模型设计,同一模型可处理多种任务
- 便于共享参数和训练框架
- 提高模型泛化能力
- 减少任务特定的调试工作
3.1.3 预训练任务
T5的预训练任务基于C4数据集(750GB文本),主要采用掩码语言模型:
- 随机遮蔽输入文本中的15%token
- 模型需要预测这些被遮蔽的token
- 与BERT类似,但融入了Encoder-Decoder结构的特点
通过这种统一的框架和预训练策略,T5在多种NLP任务上都取得了优异的性能,展示了其强大的通用性和适应性。
四、总结
预训练语言模型的发展极大推动了NLP领域的进步,从Encoder-only的BERT及其改进版RoBERTa、ALBERT,到Encoder-Decoder的T5,每一种模型都有其独特的设计理念和适用场景。
这些模型的成功证明了:
- Transformer架构的强大潜力
- 预训练+微调范式的有效性
- 更大规模数据和更优训练策略的重要性
- 统一框架对提升模型通用性的价值
理解这些经典模型的设计思想,对于深入掌握现代NLP技术和理解大型语言模型(LLM)的发展脉络具有重要意义。