【2025 CVPR】EmoEdit: Evoking Emotions through Image Manipulation

文章目录
- 🧩 一、核心问题
- 💡 二、核心思想
- ⚙️ 三、方法
- 1. EmoEditSet 数据集构建
- 2. EmoEdit 模型框架
- 📊 四、实验与结果
- 🧠 五、主要贡献
- 🚀 六、局限与展望
🧩 一、核心问题
Affective Image Manipulation (AIM) 的目标是:通过修改图像内容,使观者产生特定的情感反应,同时保持图像结构完整。
然而,现有方法主要:
- 只调整颜色或风格(如色调、滤镜),
- 缺乏对语义内容的修改能力,
- 无法在结构保真与情感表达之间取得平衡。
核心问题:如何设计一个能理解情感语义、在保持图像结构的前提下,通过内容编辑有效唤起目标情绪的模型?
💡 二、核心思想
提出一种新框架 EmoEdit,其关键思想是:让图像生成模型具备“情感感知”的能力,不仅调整视觉风格,更能基于情感语义对内容进行有意义的改动。

为实现目标,设计:
- 情感知识注入机制(Emotion Adapter):作为可插拔模块,让扩散模型(如 InstructPix2Pix)具备“情感理解”能力。
- 大规模配对数据集(EmoEditSet):构建 40,120 对“原图–目标情绪–编辑结果”的数据,涵盖八种基本情绪。
- 情感指导损失(Instruction Loss):结合传统的扩散损失,使模型在像素层面与语义层面同时学习情绪变化。
⚙️ 三、方法
1. EmoEditSet 数据集构建
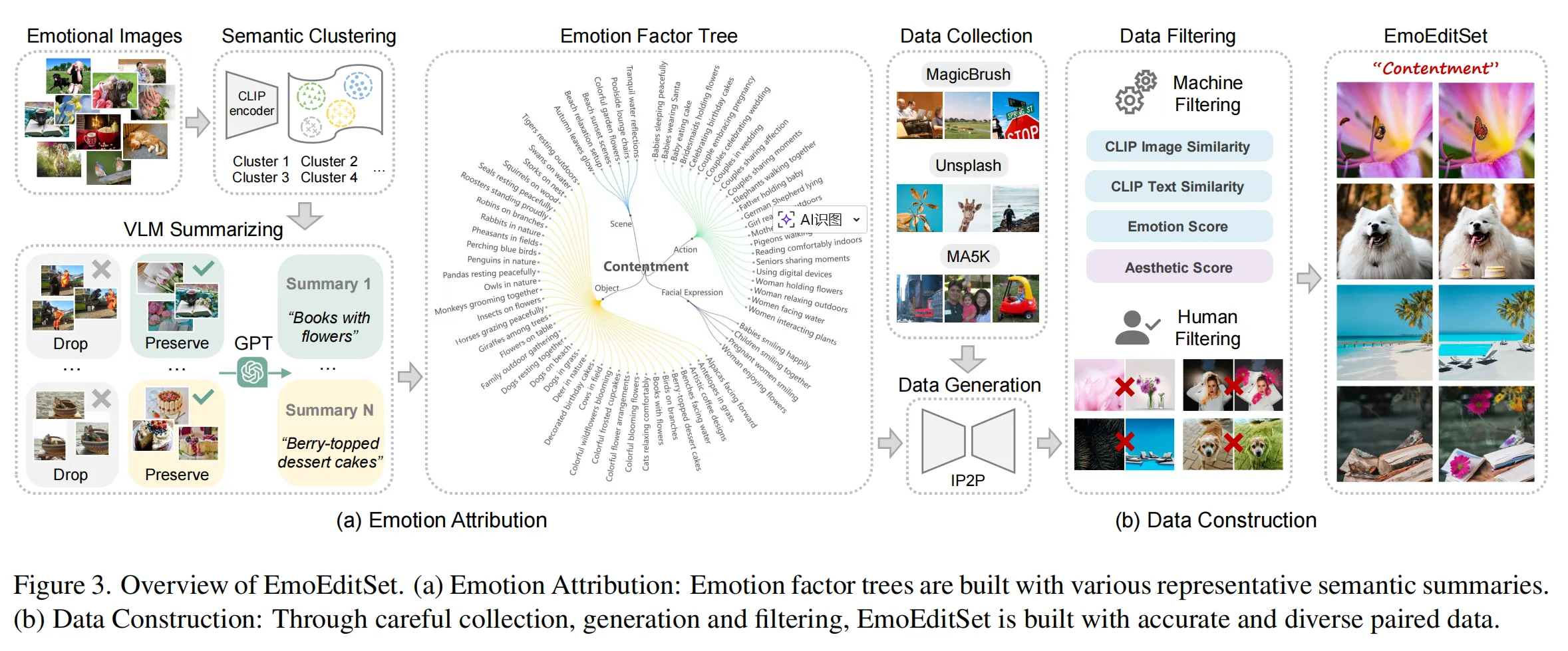
(1) Emotion Attribution(情感归因)
- 基于 EmoSet(2023 ICCV 数据集)进行语义聚类,
- 使用 CLIP 向量提取语义并构建“情感因子树(Emotion Factor Tree)”,每个情感节点(如“喜悦”、“悲伤”)包含多种触发要素(如场景、动作、表情、物体)。
- 通过 GPT-4V 总结每个因子的语义说明。
(2) Data Construction(数据生成)
- 从 MagicBrush、MA5K、Unsplash 收集原图;
- 使用 InstructPix2Pix 按情感因子生成目标图;
- 采用多重指标(CLIP 图像相似度、文本相似度、情感分数、审美分数)+人工筛选;
- 最终得到 40,120 对高质量情感编辑样本。
2. EmoEdit 模型框架
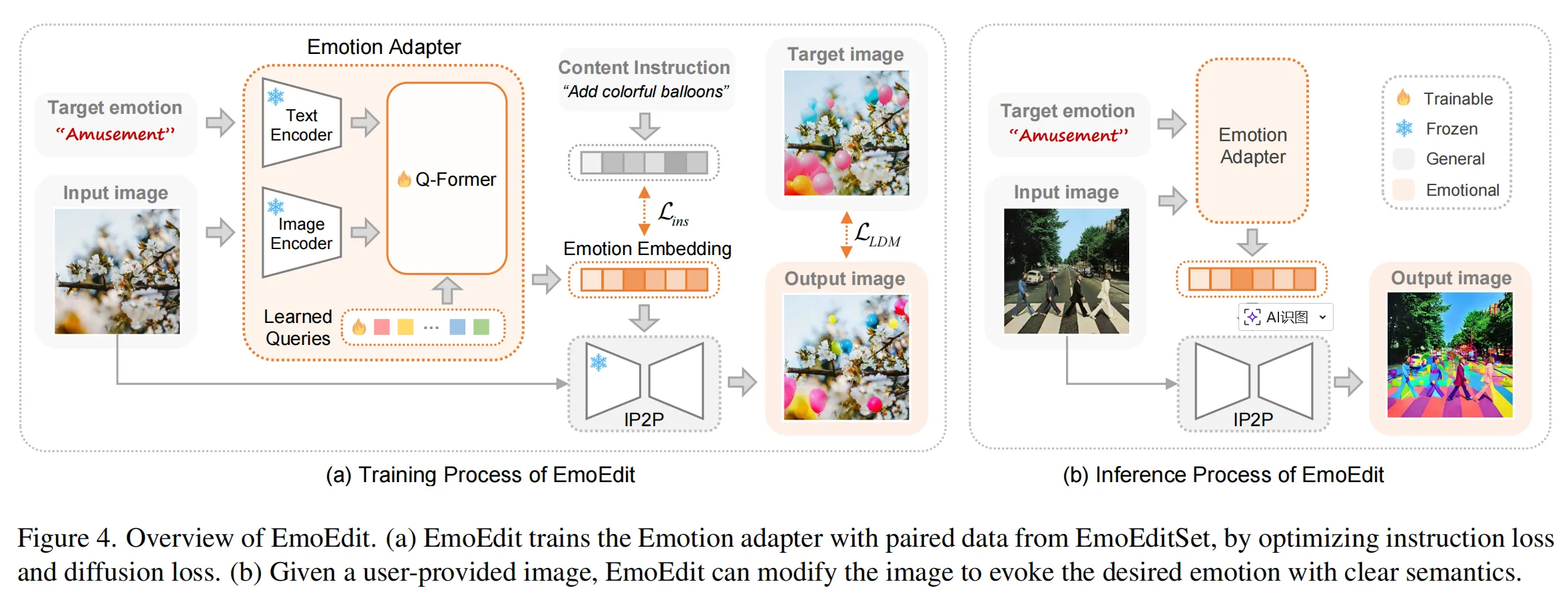
(1) Emotion Adapter 模块
- 结构借鉴 Q-Former,通过自注意力与交叉注意力融合三种信息:
- 情感字典(learned queries)
- 目标情绪嵌入
- 输入图像特征
- 生成最终的情感向量 cec_ece ,作为编辑条件注入到扩散模型。
(2) Instruction Loss - 用于捕捉语义变化,目标是让生成图像与情感指令文本保持一致:
Lins=∣ce−Etxt(tins)∣2L_{ins} = |c_e - E_{txt}(t_{ins})|^2Lins=∣ce−Etxt(tins)∣2 - 与扩散损失 LLDML_{LDM}LLDM 共同优化模型,使模型兼顾:
- 结构保真(diffusion loss)
- 情感表达(instruction loss)
📊 四、实验与结果
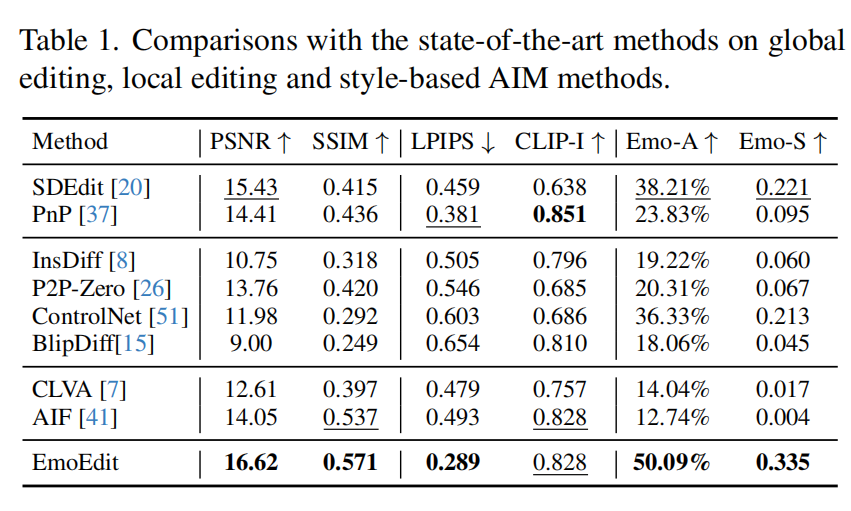
比较对象:SDEdit, PnP, ControlNet, InstructDiffusion, CLVA, AIF 等。
评估指标:
- 结构指标:PSNR, SSIM
- 语义指标:LPIPS, CLIP-I
- 情感指标:Emo-A(情绪分类准确率), Emo-S(情绪提升分数)
主要结果:
主观测试(41名参与者):
- 89.1% 认为 EmoEdit 在结构与情感平衡上最优;
- 70.1% 认为结构保真度最高;
- 75.7% 认为情感表达最到位。
🧠 五、主要贡献
- 提出 EmoEdit:首个能进行内容层面情感编辑的扩散模型框架,仅需输入情绪类别即可生成结果。
- 构建 EmoEditSet 数据集:首个 大规模情感图像编辑配对数据集(40,120 对样本),语义丰富、质量高。
- 设计 Emotion Adapter:可插拔模块,使扩散模型获得情感理解能力,可迁移到其他生成任务(如艺术风格生成)。
- 提出 Instruction Loss:引入语义层级的损失函数,提升情感编辑的语义一致性。
🚀 六、局限与展望
- 当前仅覆盖 8 类基本情绪,未能涵盖更复杂、细腻的情感;
- 依赖 EmoSet 数据,存在潜在偏差;
- AIM 属于高度人本任务,需更多 人类交互式评价;
- 未来可拓展更丰富的情感维度与用户可控性。