3.5.6 高速缓冲存储器【2010统考真题】


好的,这是一道非常经典的计算机组成原理关于Cache的综合分析题。它通过对比两种不同的数组遍历方式,深刻地揭示了程序局部性原理是如何影响Cache性能,进而影响程序执行效率的。
我们来详细地解析这道题。
首先,附上题目原文:
题目原文
3.5.6 高速缓冲存储器
(5)【2010统考真题】某计算机的主存地址空间大小为256MB,按字节编址。指令Cache和数据Cache分离,均有8个Cache行,每个Cache行大小为64B,数据Cache采用直接映射方式。现有两个功能相同的程序A和B,其伪代码如下所示:
// 程序A
int a[256][256];
...
int sum_array1(){int i, j, sum=0;for(i=0; i<256; i++){for(j=0; j<256; j++){sum += a[i][j];}}return sum;
}
``````c
// 程序B
int a[256][256];
...
int sum_array2(){int i, j, sum=0;for(j=0; j<256; j++){for(i=0; i<256; i++){sum += a[i][j];}}return sum;
}
假定int型数据用32位补码表示,程序编译时,i、j和sum均分配在寄存器中,数组a按行优先方式存放,其首地址为320(十进制数)。回答下列问题,要说明理由或给出计算过程。
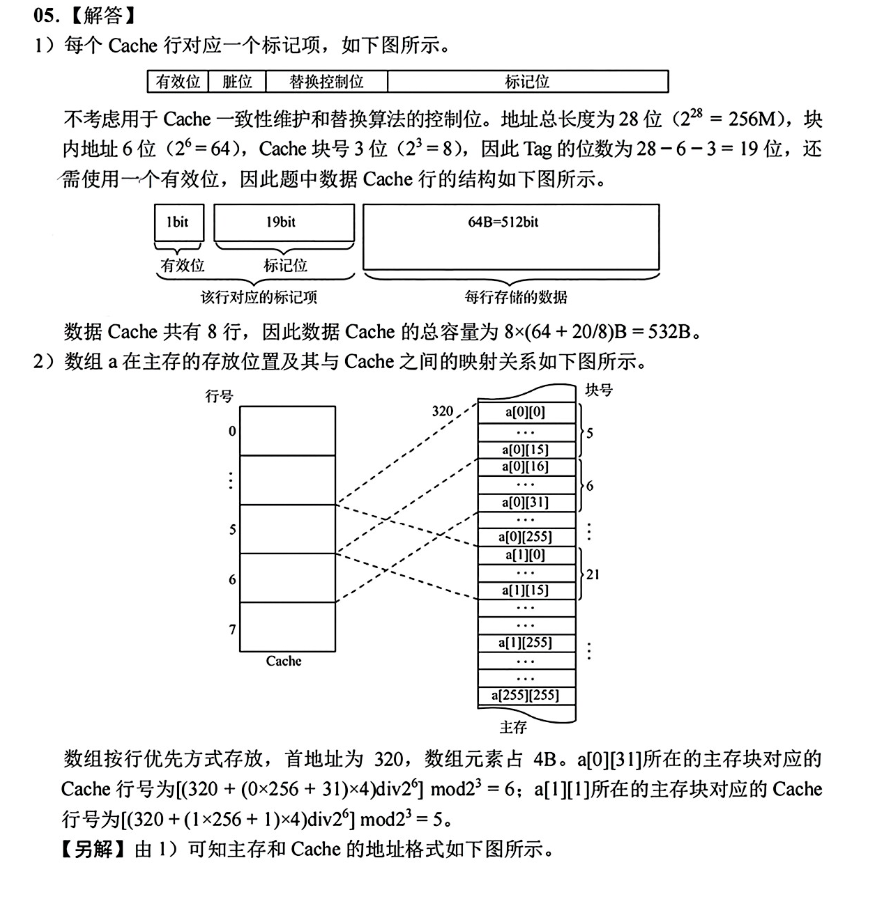
- 不考虑用于Cache一致性维护和替换算法的控制位,数据Cache的总容量为多少?
- 数组元素
a[0][31]和a[1][1]各自所在的主存块对应的Cache行号是多少(Cache行号从0开始)? - 程序A和B的数据访问命中率各是多少?哪个程序的执行时间更短?
综合解析
这道题的核心是分析直接映射Cache的工作原理,以及程序的访存模式如何与Cache的映射方式相互作用,从而产生巨大的性能差异。
一、运用了什么知识点?
-
Cache 的基本概念与参数:
- 主存地址空间: 256MB
- Cache行数 ©: 8行
- Cache行大小/块大小 (B): 64B
- 映射方式: 直接映射
- 分离Cache: 指令Cache和数据Cache分开。
-
主存地址的划分 (直接映射):
- 一个主存地址会被硬件逻辑地划分为三部分:标记(Tag) | Cache行号(Index/Set) | 块内偏移(Offset)。
- 块内偏移位数 (w):
2^w = B(块大小)。 - Cache行号位数 ©:
2^c = C(Cache行数)。 - 标记位数 (t):
t = 主存地址总位数 - c - w。
-
二维数组的存储方式:
- 行优先存储: 在内存中,二维数组
a[M][N]的元素是按行连续存放的。a[i][j]的下一个内存位置是a[i][j+1],a[i][N-1]的下一个位置是a[i+1][0]。 - 地址计算: 元素
a[i][j]的地址 =首地址 + (i * N + j) * sizeof(element)。
- 行优先存储: 在内存中,二维数组
-
Cache 命中率 (Hit Rate):
命中率 = 命中次数 / 总访问次数- 理解空间局部性: 如果一个存储位置被访问,那么它附近的存储位置也可能很快被访问。
- 理解时间局部性: 如果一个存储位置被访问,那么它可能在不久的将来再次被访问。
二、考了什么?为什么这么考?
- 第1、2问:考察的是Cache的基本计算。这是分析Cache性能的基础,要求考生能够根据给定的Cache参数,正确地划分主存地址,并计算出任意一个主存地址应该映射到Cache的哪一行。
- 第3问:考察的是Cache性能分析,也是本题的灵魂。它通过两个功能完全相同但访存顺序相反的程序,深刻地揭示了代码写法如何影响空间局部性,进而导致Cache命中率的天壤之别。
- 程序A (i在外, j在内): 按行遍历,与数组在内存中的行优先存储方式完全一致,具有极好的空间局部性。
- 程序B (j在外, i在内): 按列遍历,在内存中进行大跨度的“跳跃式”访问,严重破坏了空间局部性。
为什么这么考? 因为这道题完美地连接了计算机体系结构(硬件)和软件编程(算法)。它告诉我们,一个程序员如果不了解底层硬件(如Cache)的工作原理,可能会写出功能正确但性能极差的代码。这是计算机科学教育中一个非常重要的思想:软硬件协同设计与优化。
三、解题思路与详细分析 (为什么怎么样?)
问题1分析:数据Cache总容量
- 思路: Cache总容量只计算存储数据的空间。
- 计算:
总容量 = Cache行数 × 每个Cache行的大小总容量 = 8行 × 64B/行 = 512B
- 结论: 数据Cache的总容量为 512字节。
问题2分析:计算Cache行号
第一步:确定主存地址的划分
- 主存地址总位数:
256MB = 2⁸ * 2²⁰ B = 2²⁸ B。所以主存地址有 28 位。 - 块内偏移位数 (w): 块大小
B = 64B = 2⁶ B。所以块内偏移占 6 位。 - Cache行号位数 ©: Cache行数
C = 8 = 2³。所以行号占 3 位。 - 标记位数 (t):
t = 28 - 6 - 3 = 19位。 - 划分结果:
主存地址 (28位) = [ 标记(19位) | 行号(3位) | 偏移(6位) ]
第二步:计算主存地址
int型数据占32位 = 4B。- 数组
a是a[256][256]。 a[i][j]的地址 =首地址 + (i * 256 + j) * 4- a的地址:
地址 = 320 + (0 * 256 + 31) * 4 = 320 + 124 = 444(十进制)
- a的地址:
地址 = 320 + (1 * 256 + 1) * 4 = 320 + 257 * 4 = 320 + 1028 = 1348(十进制)
第三步:从主存地址中提取Cache行号
-
方法:
Cache行号 = (主存块号) mod (Cache总行数)主存块号 = floor(主存地址 / 块大小)
-
a的Cache行号:
- 地址 = 444。块大小 = 64。
- 主存块号 =
floor(444 / 64) = floor(6.9375) = 6。 - Cache行号 =
6 mod 8 = 6。
-
a的Cache行号:
- 地址 = 1348。块大小 = 64。
- 主存块号 =
floor(1348 / 64) = floor(21.0625) = 21。 - Cache行号 =
21 mod 8 = 5。
-
结论:
a[0][31]对应的Cache行号是 6;a[1][1]对应的Cache行号是 5。
问题3分析:命中率与执行时间
1. 程序A (按行遍历)
- 访存模式:
a[0][0], a[0][1], ..., a[0][255], a[1][0], ...这种访问是连续的。 - Cache行为分析:
- 当访问
a[0][0]时,发生强制性不命中 (Compulsory Miss)。 - 包含
a[0][0]的整个主存块 (64B) 被调入到对应的Cache行中。 - 一个Cache块可以存放
64B / 4B/int = 16个int元素。 - 因此,接下来对
a[0][1]到a[0][15]的 15次访问,全部都会在刚才调入的Cache块中命中 (Hit)。 - 这个 “1次不命中,15次命中” 的模式会一直重复。
- 当访问
- 计算命中率: 在每16次访问中,有15次是命中的。
命中率 = 15 / 16 = 93.75%
- 结论A: 程序A的命中率是 93.75%。
2. 程序B (按列遍历)
- 访存模式:
a[0][0], a[1][0], a[2][0], ..., a[255][0], a[0][1], ...这种访问是跳跃的。 - 地址间隔分析:
- 访问
a[i][j]后,下一个访问的是a[i+1][j]。 a[i+1][j]的地址与a[i][j]的地址相差((i+1)*256+j)*4 - ((i)*256+j)*4 = 256 * 4 = 1024字节。
- 访问
- Cache行为分析:
- 访问
a[0][0]时,不命中。包含a[0][0]的块被调入Cache。 - 下一个访问
a[1][0],其地址与a[0][0]相差1024字节。它们位于不同的主存块。a[0][0]的块号 =floor(320/64) = 5,映射到Cache行5 mod 8 = 5。a[1][0]的块号 =floor((320+1024)/64) = floor(1344/64) = 21,映射到Cache行21 mod 8 = 5。- 致命问题出现了!
a[1][0]和a[0][0]映射到了同一个Cache行!
- 因此,当访问
a[1][0]时,不仅会不命中,还会把刚刚调入的、包含a[0][0]的Cache行替换掉。 - 再下一个访问
a[2][0],其地址又与a[1][0]相差1024字节,同样映射到Cache行5,再次发生不命中和替换。 - 这个过程会一直持续。每一次访问都会导致不命中,并且会“踢走”前一次调入的数据块。
- 访问
- 计算命中率: 每次访问都不能命中。
命中率 = 0 / (256*256) = 0%
- 结论B: 程序B的命中率是 0%。
3. 哪个程序执行时间更短?
- Cache命中的影响: Cache命中时,CPU从高速的Cache中获取数据,速度极快。Cache不命中时,CPU需要暂停,等待数据从慢速的主存中调入Cache,耗时要长得多(通常是几十到上百倍)。
- 比较: 程序A的Cache命中率高达93.75%,而程序B的命中率是0%。这意味着程序A的大部分时间都在高速运行,而程序B的CPU大部分时间都在“空等”。
- 结论: 程序A 的执行时间更短。