Data+AI 时代,对象存储为 AI 应用注入全局动力
Data + AI 时代,AI Storage 新挑战
在 Data+AI 时代,我们正处在一个由数据驱动创新的新纪元。尤其是在生成式 AI 和智能驾驶等前沿领域,海量数据的产生、流动与存储已成为推动技术突破的核心引擎。然而,数据的爆炸式增长也给传统的存储方案带来了前所未有的挑战,面对 AI 时代 “海量容量、超大规模、并发密集” 的极致需求,传统的文件存储与对象存储逐渐打破各自独立的界限,高性能文件存储与海量对象存储紧密结合、文件与对象统一访问的模式正在成为主流。在这一趋势下,得益于对象存储弹性容量、高扩展性、低成本等特点,在 AI 大模型训练、推理、智能驾驶等场景,越来越多的客户选择对象存储作为支持 AI 训练级别的统一存储底座,这也对对象存储的吞吐、性能、生态兼容、安全性和可靠性提出了新的挑战。
POSIX 协议转换性能不足:AI 训练框架通常依赖 POSIX 文件系统接口与数据进行交互,而标准对象存储服务则基于HTTP 协议。尽管社区提供了S3FS、Goofys等协议转换工具,但这些工具往往更关注功能的实现,而忽略了 AI 场景对高吞吐、低延迟的极致性能追求,导致协议转换成为性能瓶颈。
分布式训练数据协同困难:大模型训练往往采用分布式集群,训练数据也可能分散在不同地域。传统的跨区域数据复制方案,不仅效率低下,而且一旦某个地域的存储出现故障,就可能导致整个训练任务中断,造成巨大的资源浪费。
存储性能瓶颈拖慢训练效率:在分布式训练中,训练集、特征库、模型权重、CheckPoint 文件等需要被高频、并发地访问,这对存储的带宽和 QPS 都提出了极高的要求。如果存储性能不足,就会出现“算力等数据”的尴尬局面,GPU资源被大量闲置,严重拖慢模型训练的整体进度。
那么,如何才能打破这些瓶颈,让数据真正成为AI应用的“全局动力”?火山引擎对象存储 TOS 提供了一套创新的全链路加速解决方案,旨在解决 AI 场景下的数据存储与访问难题。本文将深入剖析TOS 如何通过其核心组件——FSX for TOS、多区域接入点(MRAP)和 TOS 加速器,为 AI 应用注入澎湃动力,并提供可复现、可落地的实操指引。
面向 AI 数据读取和训练推理,提供全链路加速和智能数据流动能力
为了应对 AI 时代的存储挑战,火山引擎 TOS 推出了一套创新的全链路加速解决方案,通过 FSX for TOS、多区域接入点(MRAP)和 TOS 加速器三大核心组件的协同工作,为AI应用提供从数据接入、处理到消费的全程加速能力。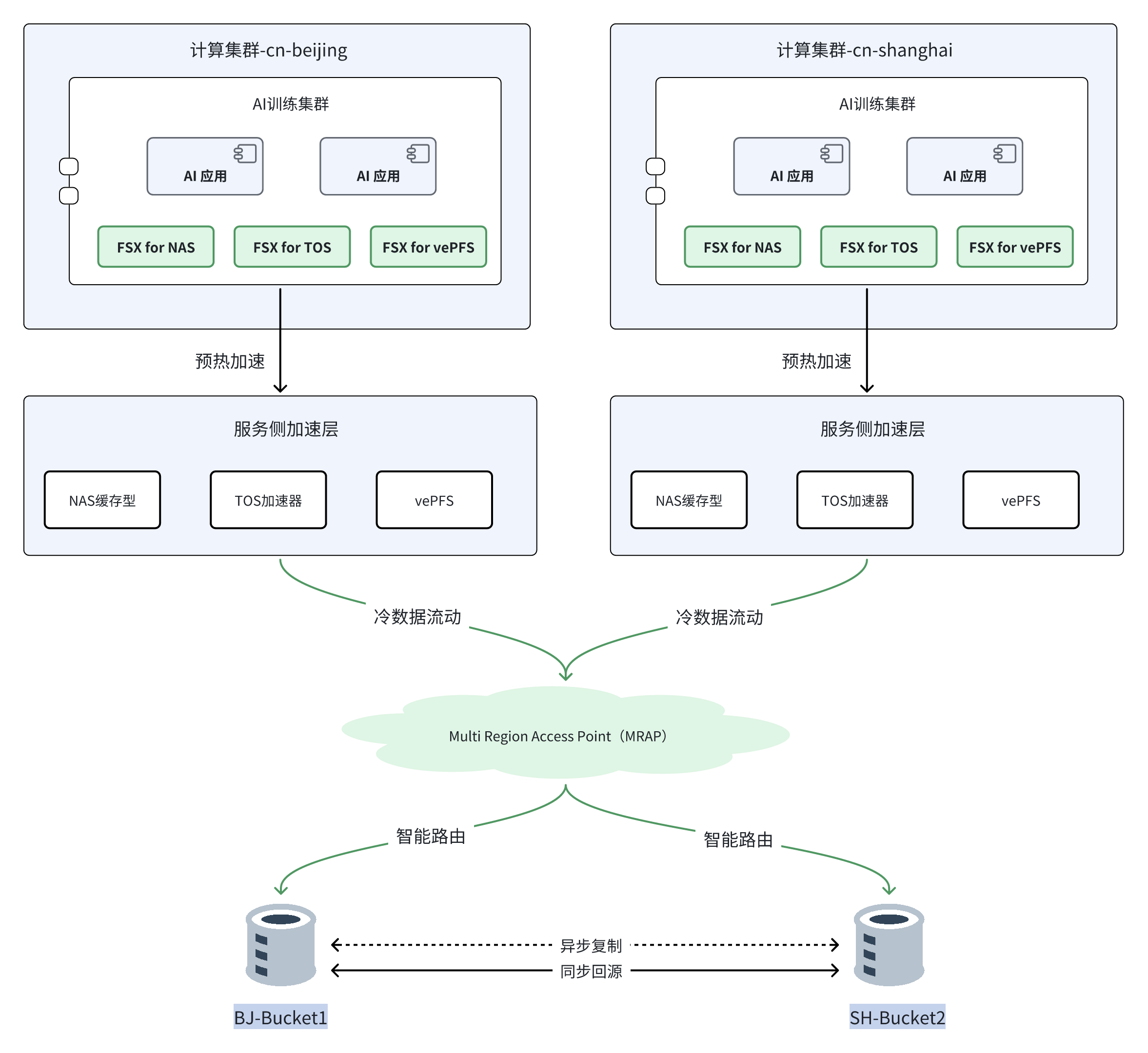
FSX for TOS:提供高性能的 POSIX 语义,让 AI 训练框架能够像访问本地文件一样访问 TOS,同时通过一系列优化手段,大幅提升读写性能。
多区域接入点(MRAP):实现多地域数据的统一接入和智能路由,解决分布式训练中的数据协同难题。
TOS加速器:提供近计算的服务端缓存,为热点数据提供毫秒级的访问延迟和超高的吞吐能力。
接下来,我们将逐一深入探讨这三大“法宝”的技术细节和实战应用。
FSX for TOS:打破协议瓶颈,释放读写性能
FSX for TOS 是火山引擎 TOS 为 AI 大模型场景量身打造的高性能客户端解决方案。它能够将 TOS存储桶(无论是扁平命名空间还是分层命名空间)挂载为本地文件系统,不仅让上层应用可以无缝地通过 POSIX 接口进行数据读写,还充分结合了 HNS 能力。借助 HNS,FSX for TOS 能够在对象存储之上实现接近本地文件系统的高性能目录操作,支持毫秒级的目录创建、重命名和批量遍历,大幅降低传统扁平命名空间下目录管理的开销。更重要的是,FSX for TOS 针对 AI 场景的特点,在数据读写链路上进行了深度优化,能够充分发挥 TOS 的高吞吐能力。
深度读写优化
为了满足 AI 训练对性能的苛刻要求,FSX for TOS 在读写流程上进行了大量的优化。
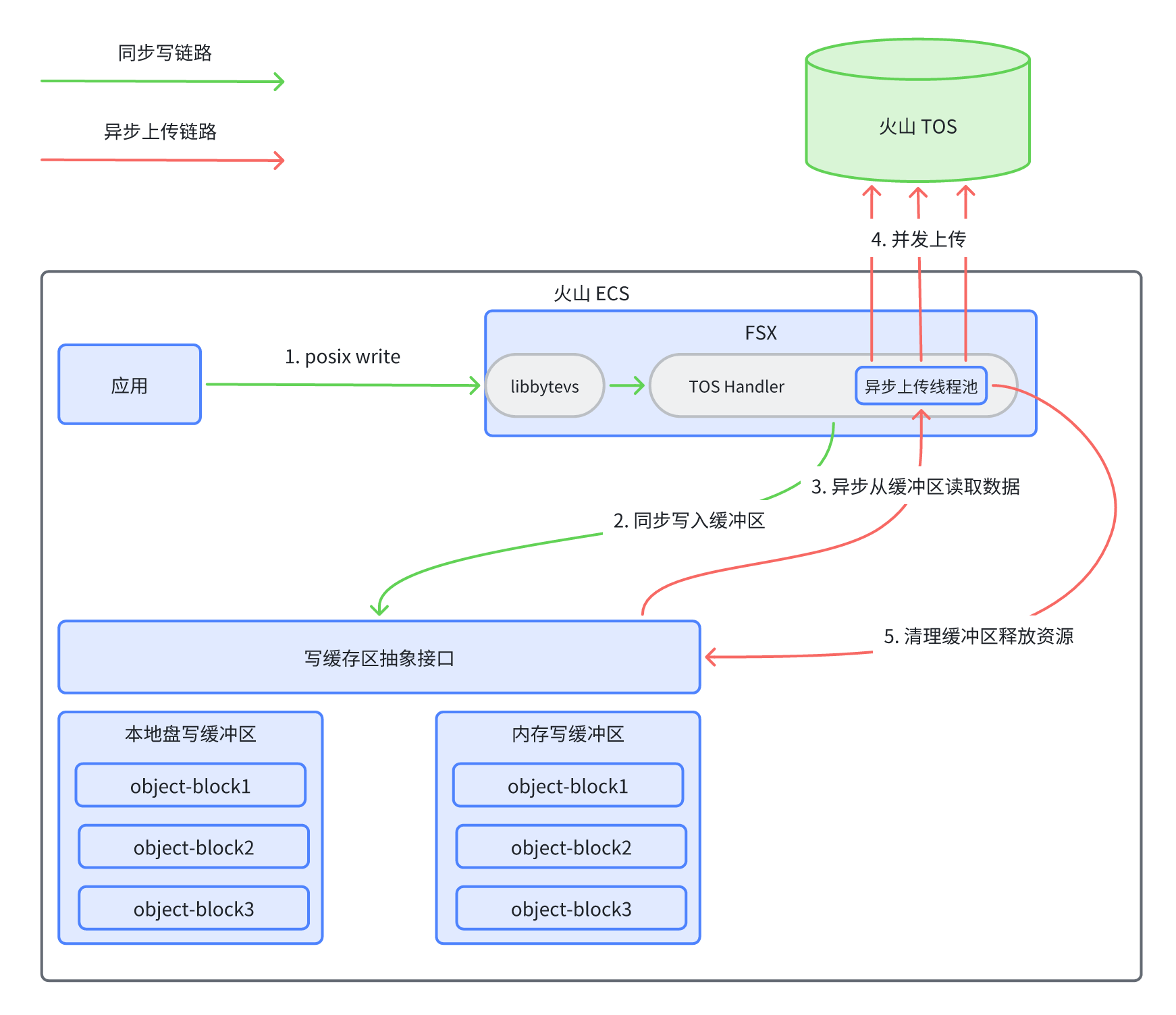
写流程优化
FSX for TOS 采用“异步并发上传”的策略,将写操作转化为后台任务,并利用 TOS 的分片上传能力来大幅提升写入性能。实测单挂载点可达到 12.5GB/s 的带宽吞吐和 11K 的小文件写入 IOPS。
写性能对比(VS S3FS)
写带宽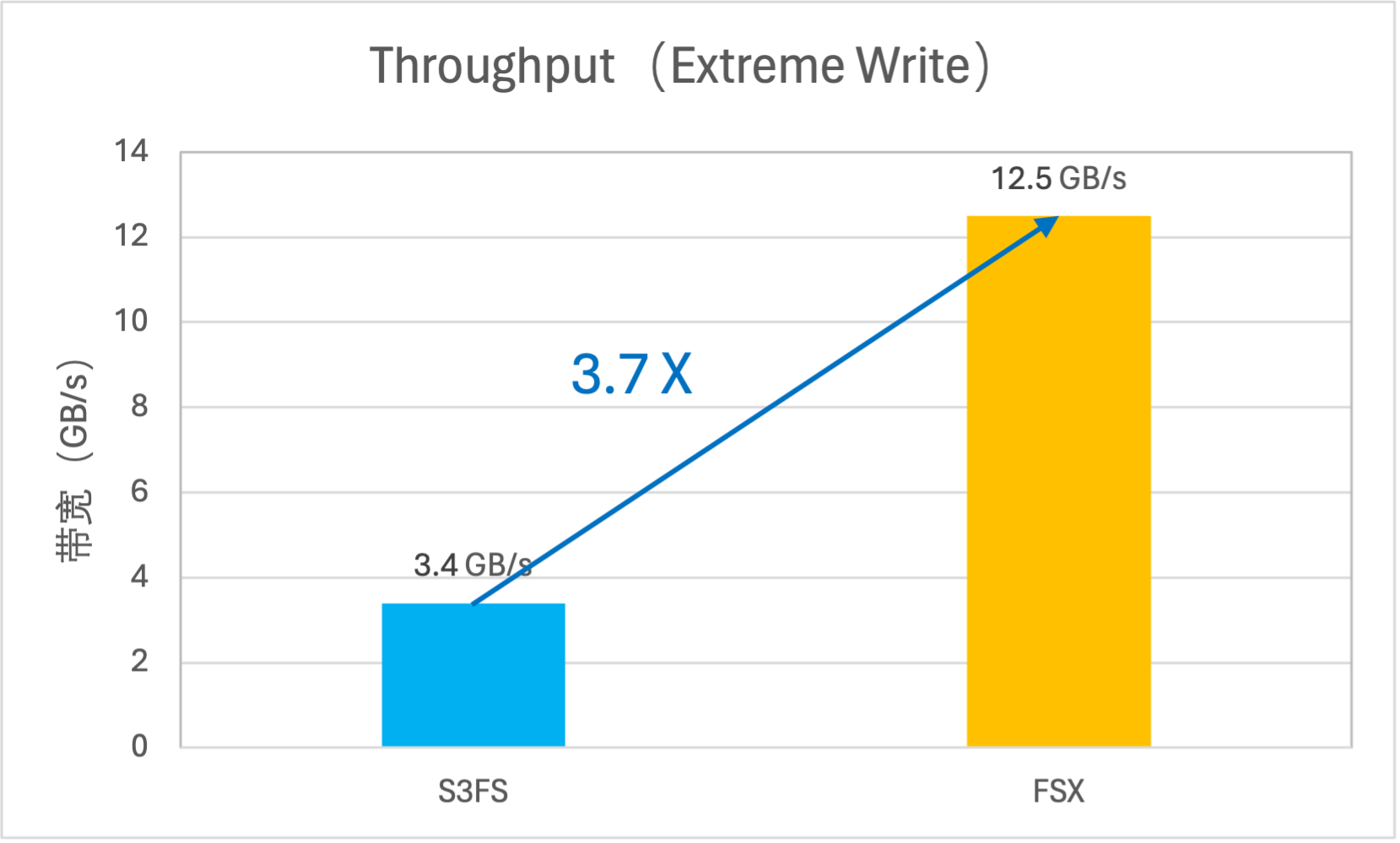
写 IOPS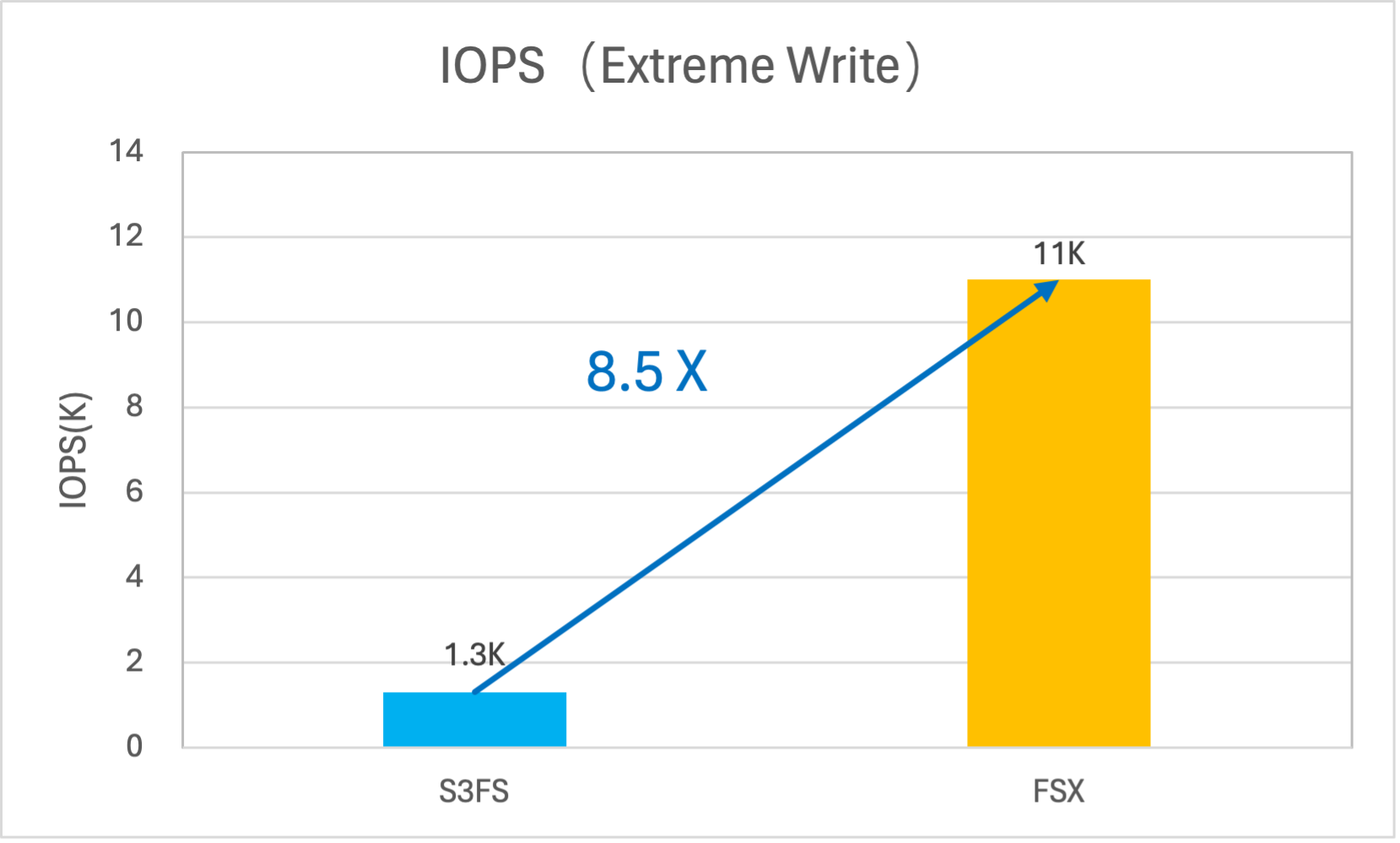
读流程优化
FSX for TOS通过“异步并发预取”的机制,提前将数据加载到内存中,大幅提升读取性能。实测单挂载点直读带宽可达 12GB/s,小文件读取 IOPS 可达 330K。
暂时无法在飞书文档外展示此内容
读性能对比(VS S3FS
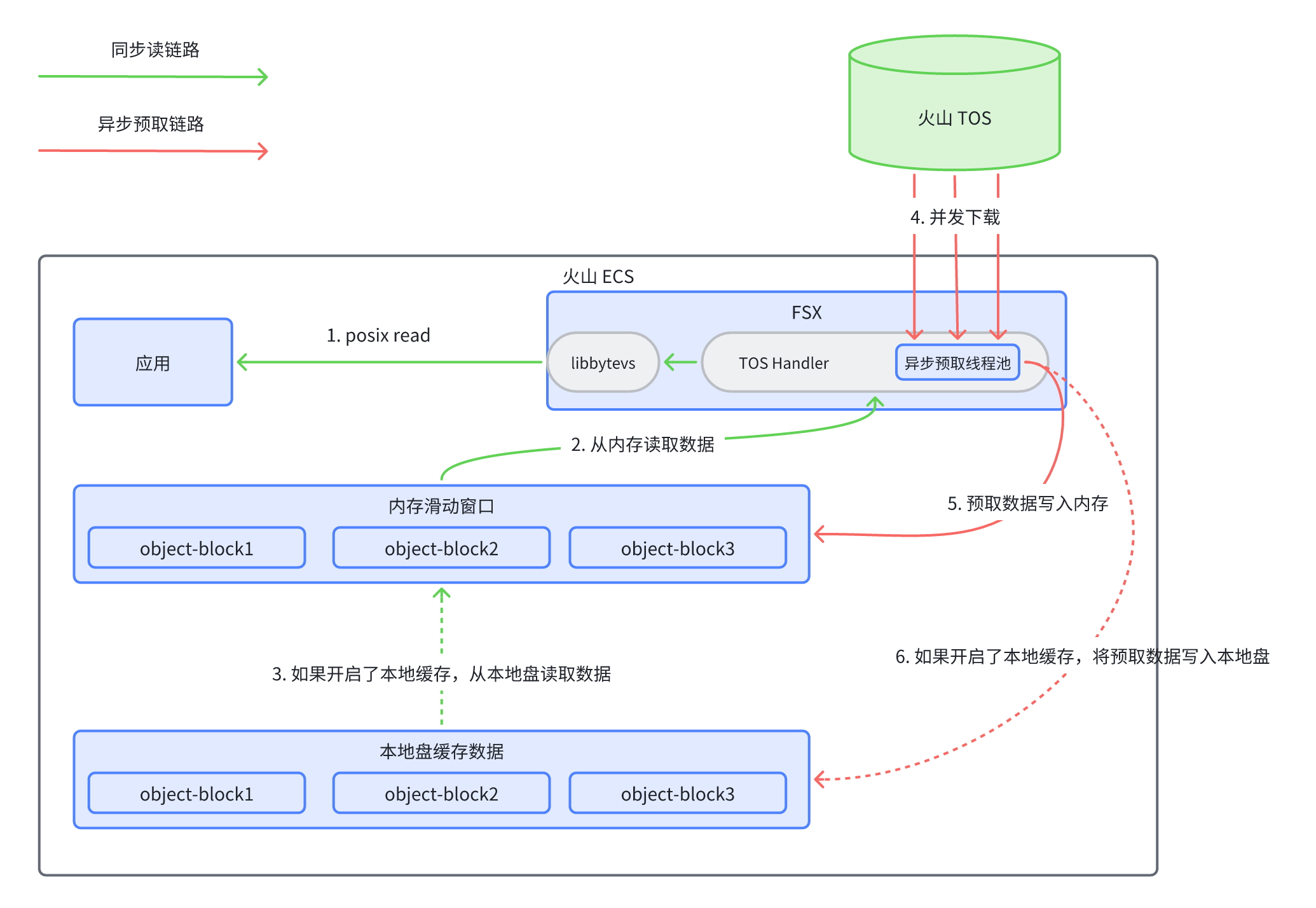
读带宽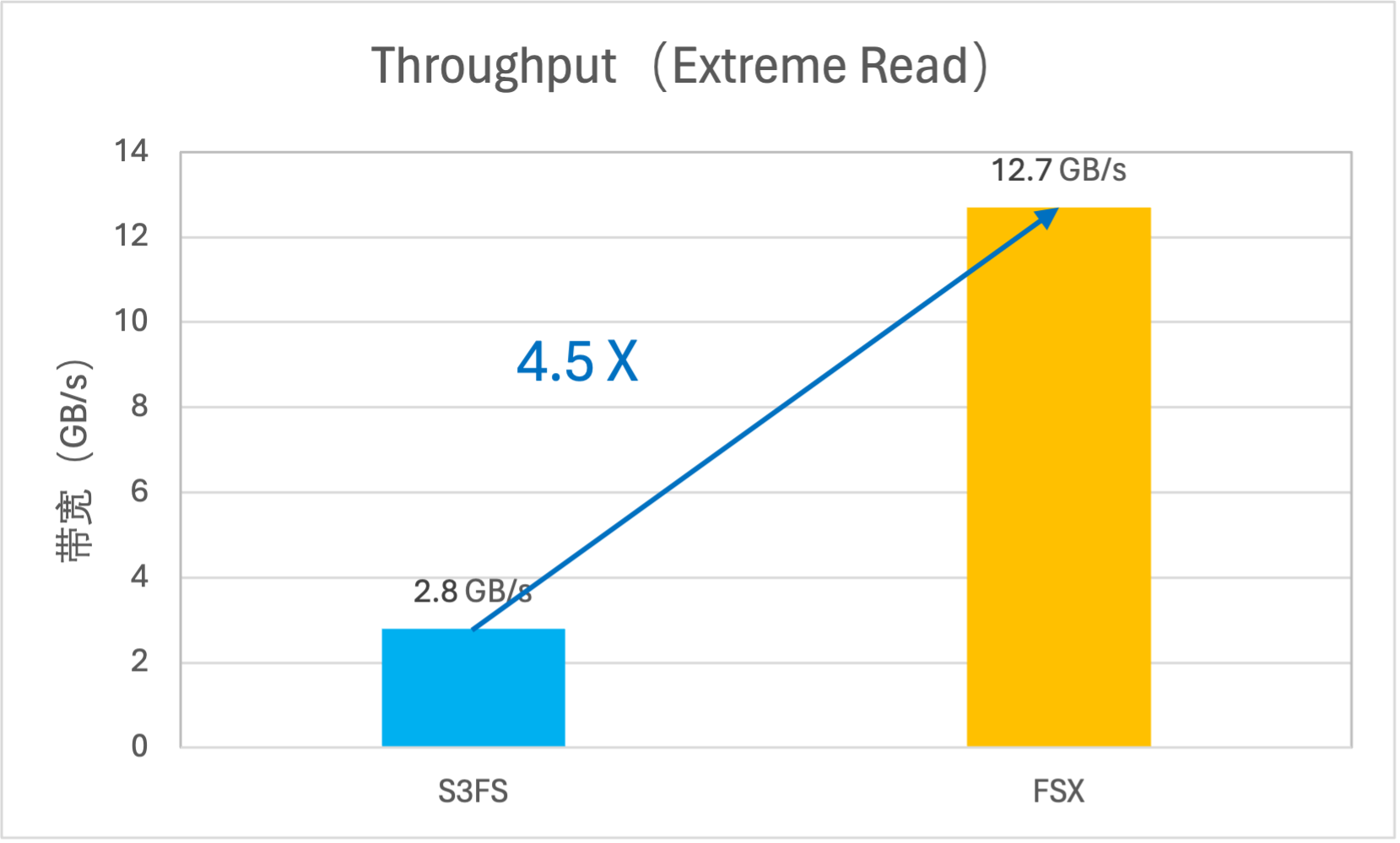
读 IOPS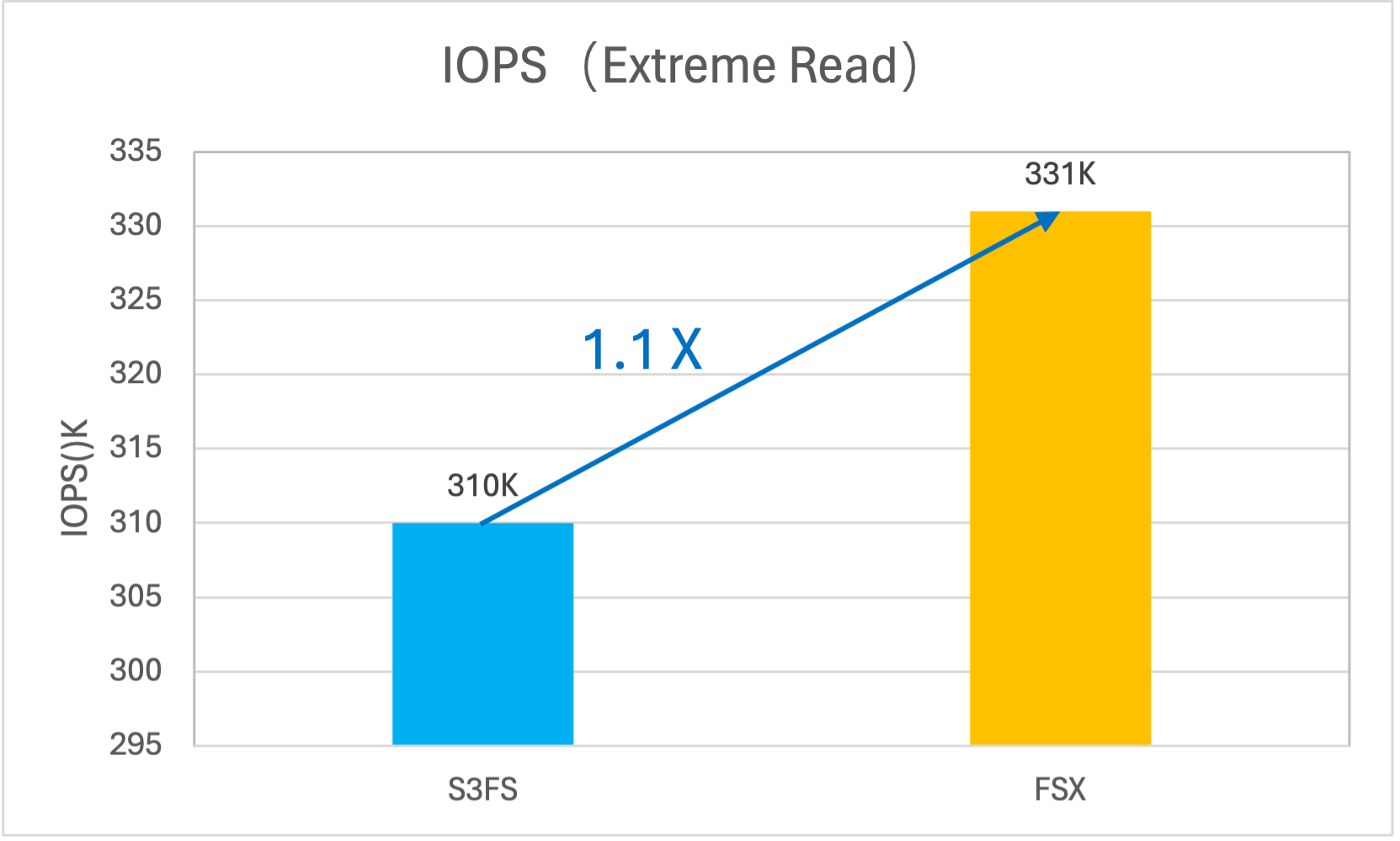
分布式缓存
为了追求极致性能,FSX for TOS 还提供了一项“黑科技”:分布式缓存,基于火山存储自研的分布式KV存储,提供可多节点共享的读缓存能力,缓存容量不受限于单机本地盘规格,使用本地缓存读带宽可达 27GB/s,搭载分布式缓存后读吞吐能力更是高达 45GB/s,完美匹配 AI 训练等大带宽需求场景。
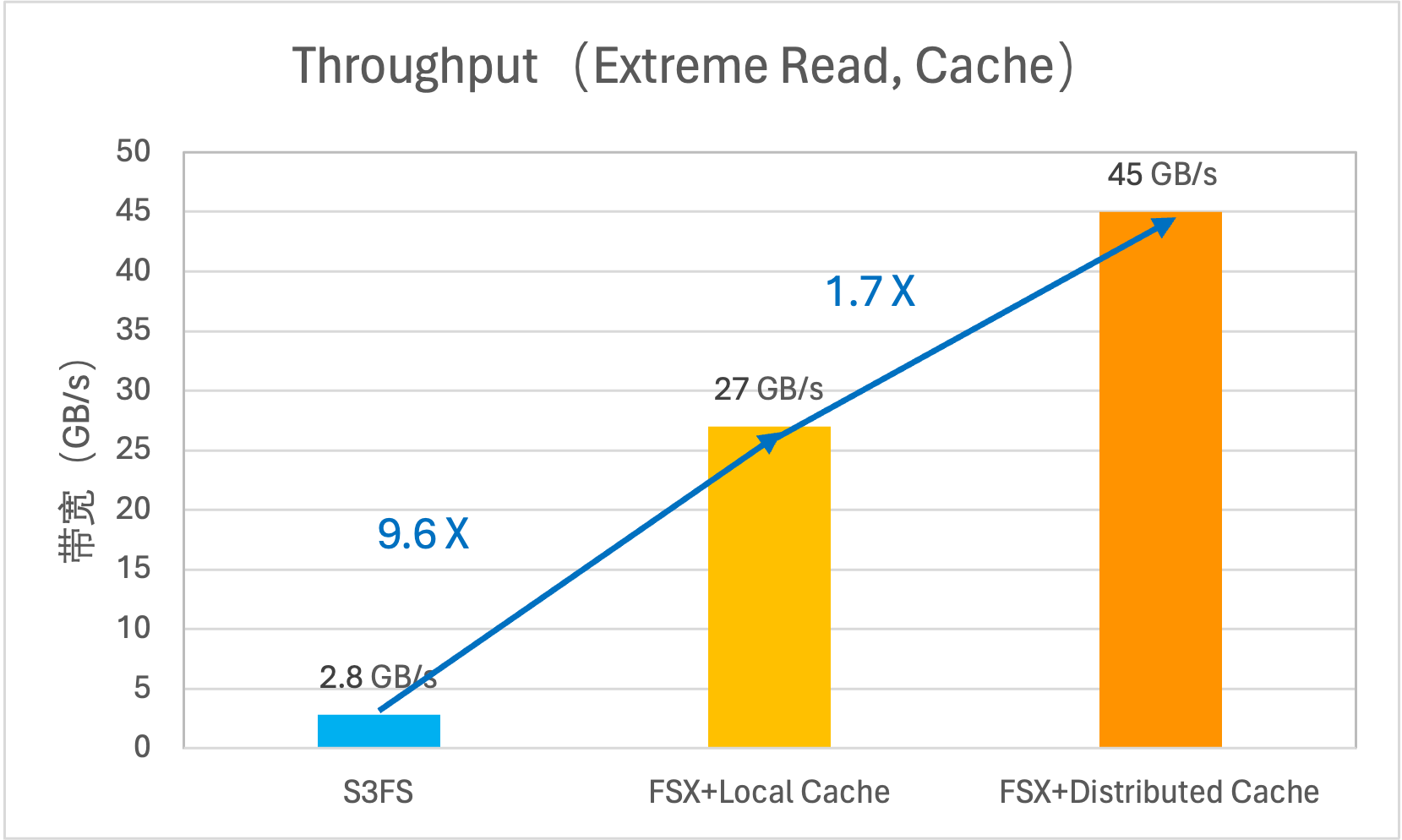
崩溃恢复与热升级
在AI训练等长周期任务中,稳定性至关重要。FSX for TOS 具备强大的崩溃恢复能力,当挂载点因 OOM 等原因异常退出时,能够自动重新拉起并恢复上下文,整个过程对上层业务几乎无感。同时,FSX for TOS 还支持客户端热升级,更新版本无需重新挂载,极大地提升了运维效率和业务连续性。
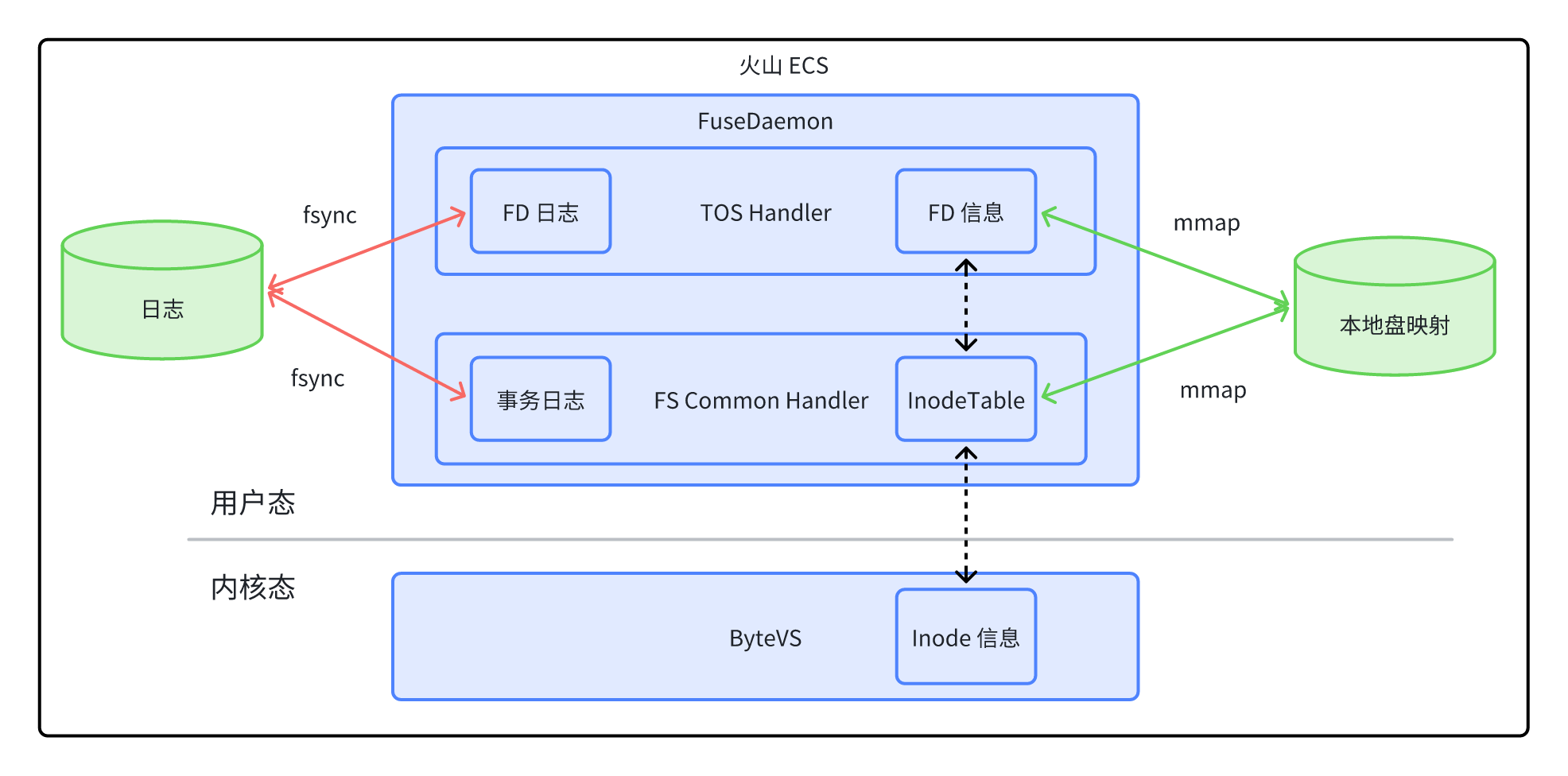
实现崩溃恢复的核心要点是持久化记录 InodeTable 信息、FD 信息以及正在执行的请求状态。从技术实现上,FSX 使用 mmap 零拷贝技术来记录 InodeTable 和 FD 信息,使用日志来记录请求的执行状态,如下图:
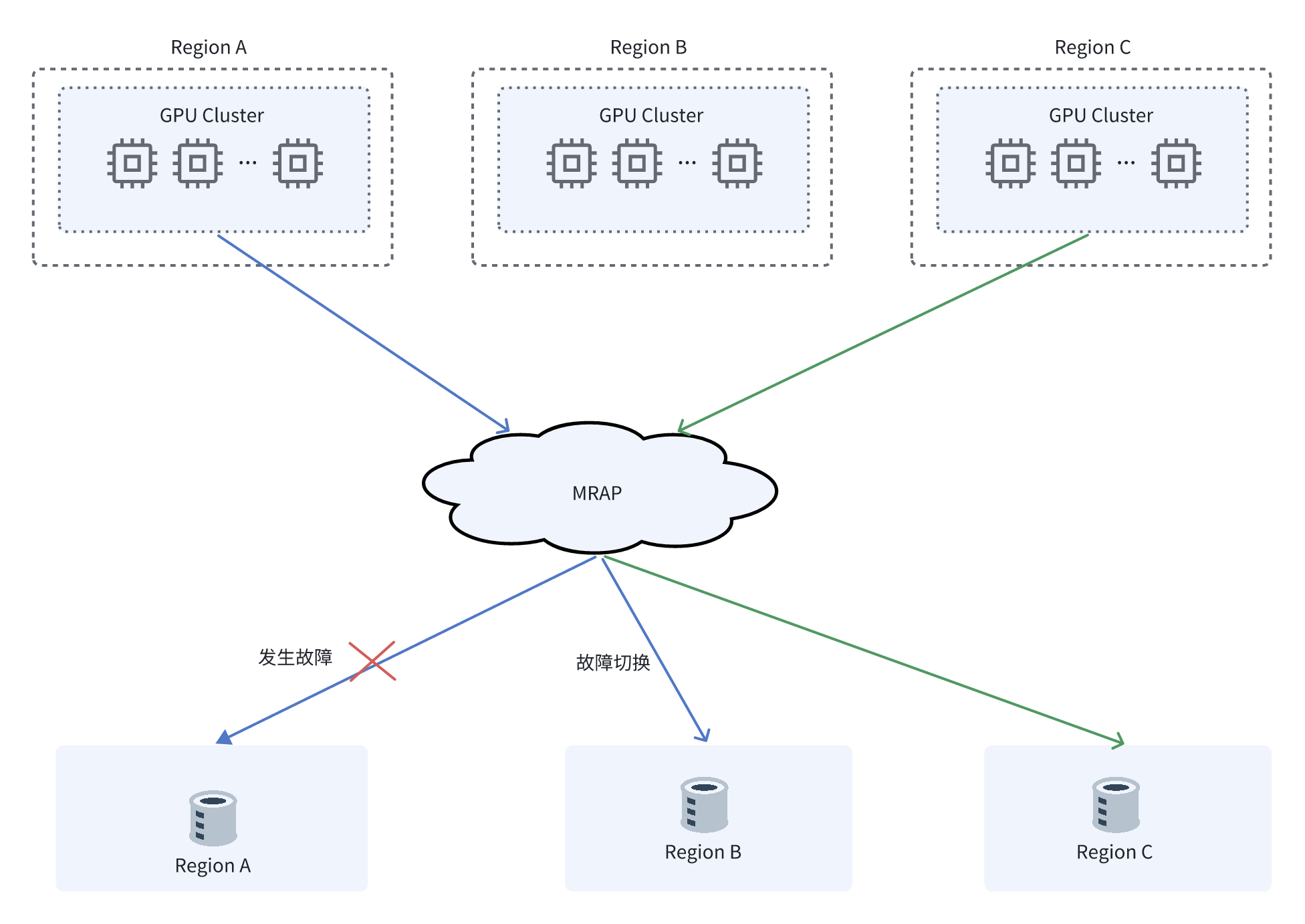
多区域接入点:实现全局数据的智能流动
Multi-Region Access Point(MRAP) 是火山引擎 TOS 为多地域数据流动场景提供的一站式解决方案。它为分布在不同地域的多个存储桶提供“单一全球入口”的能力,应用只需面向一个全球统一域名发起请求,TOS 会基于请求来源位置与网络状态智能路由到就近的目标区域桶,实现低时延访问与弹性冗余。
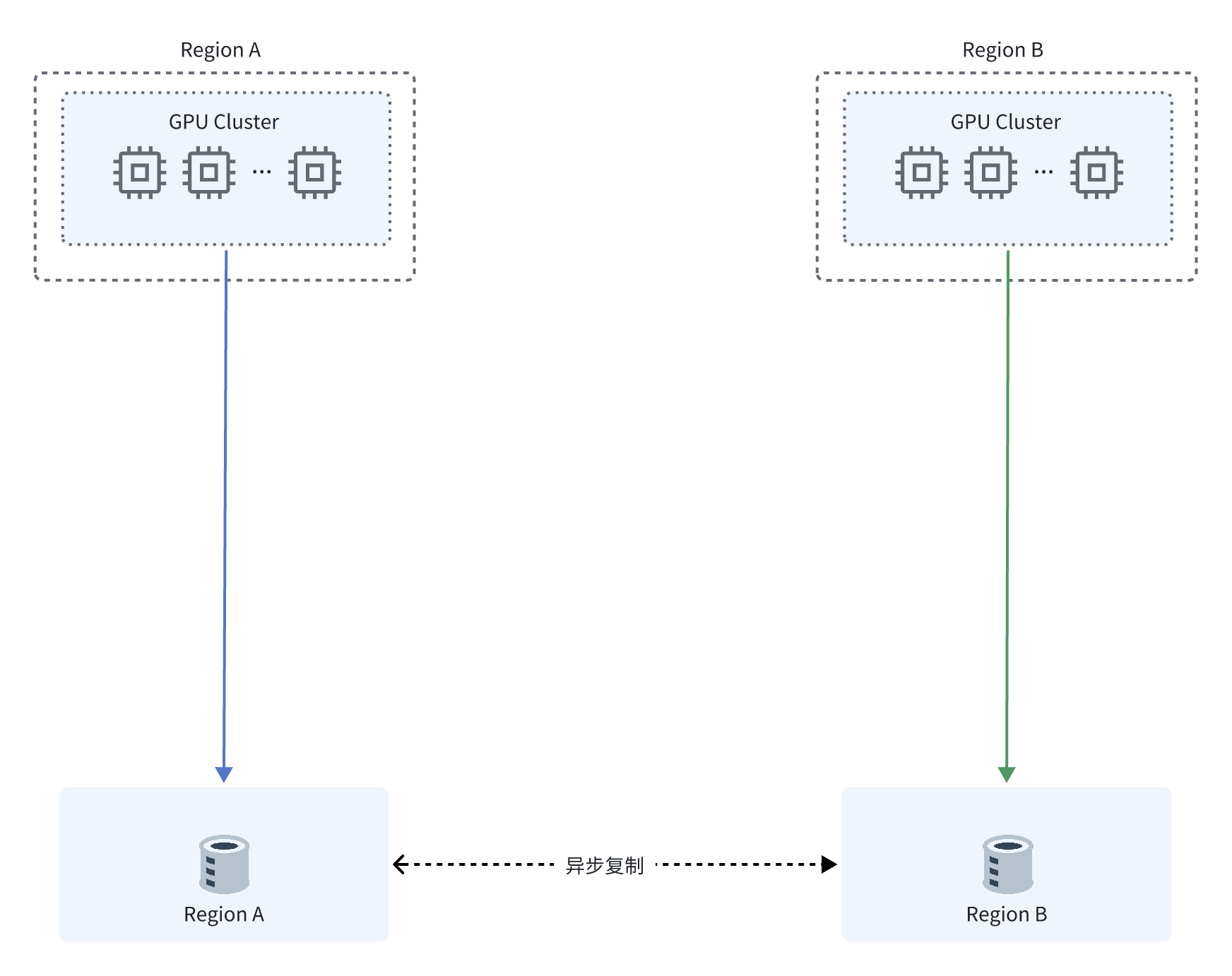
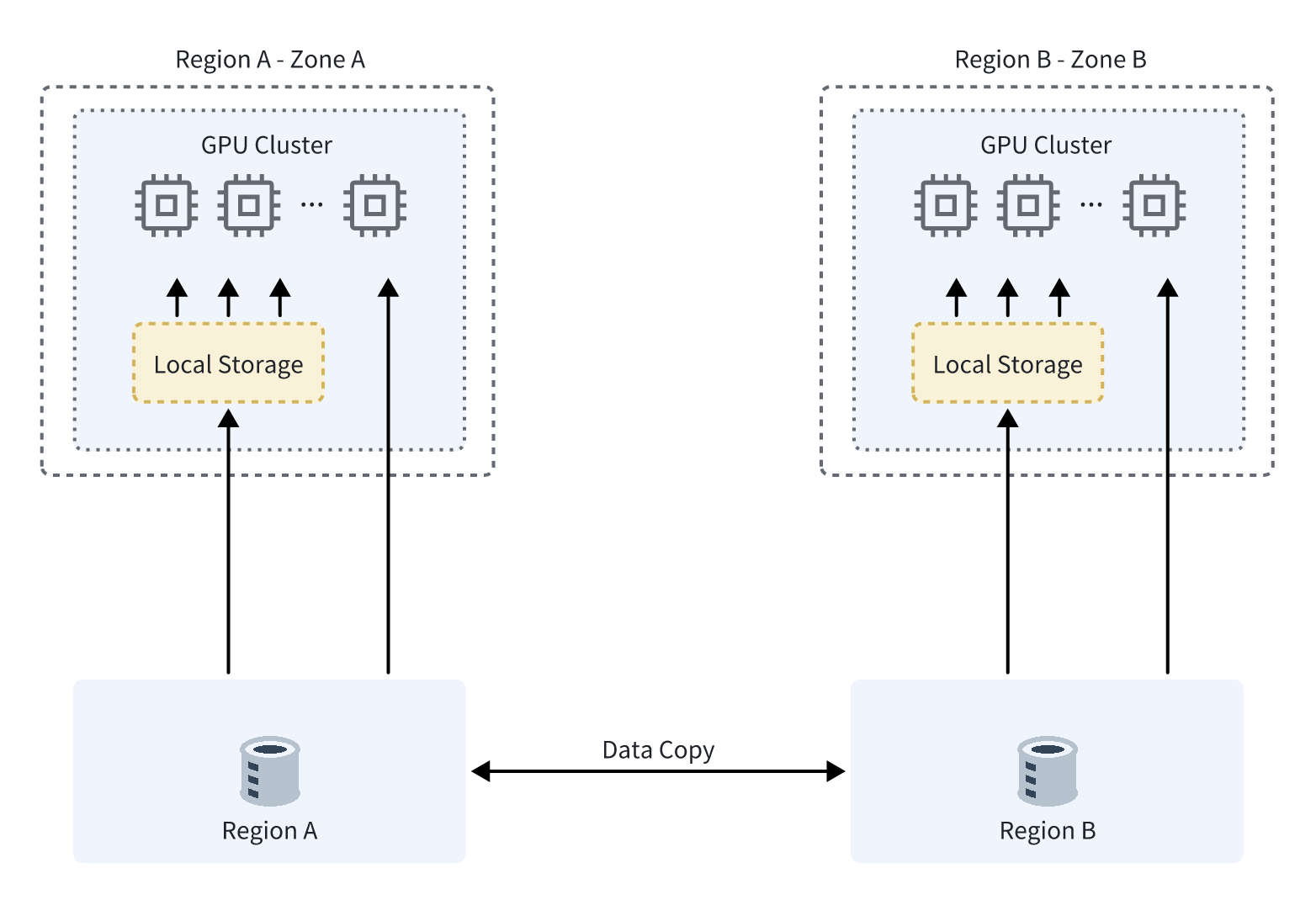
传统多地域数据协同模式
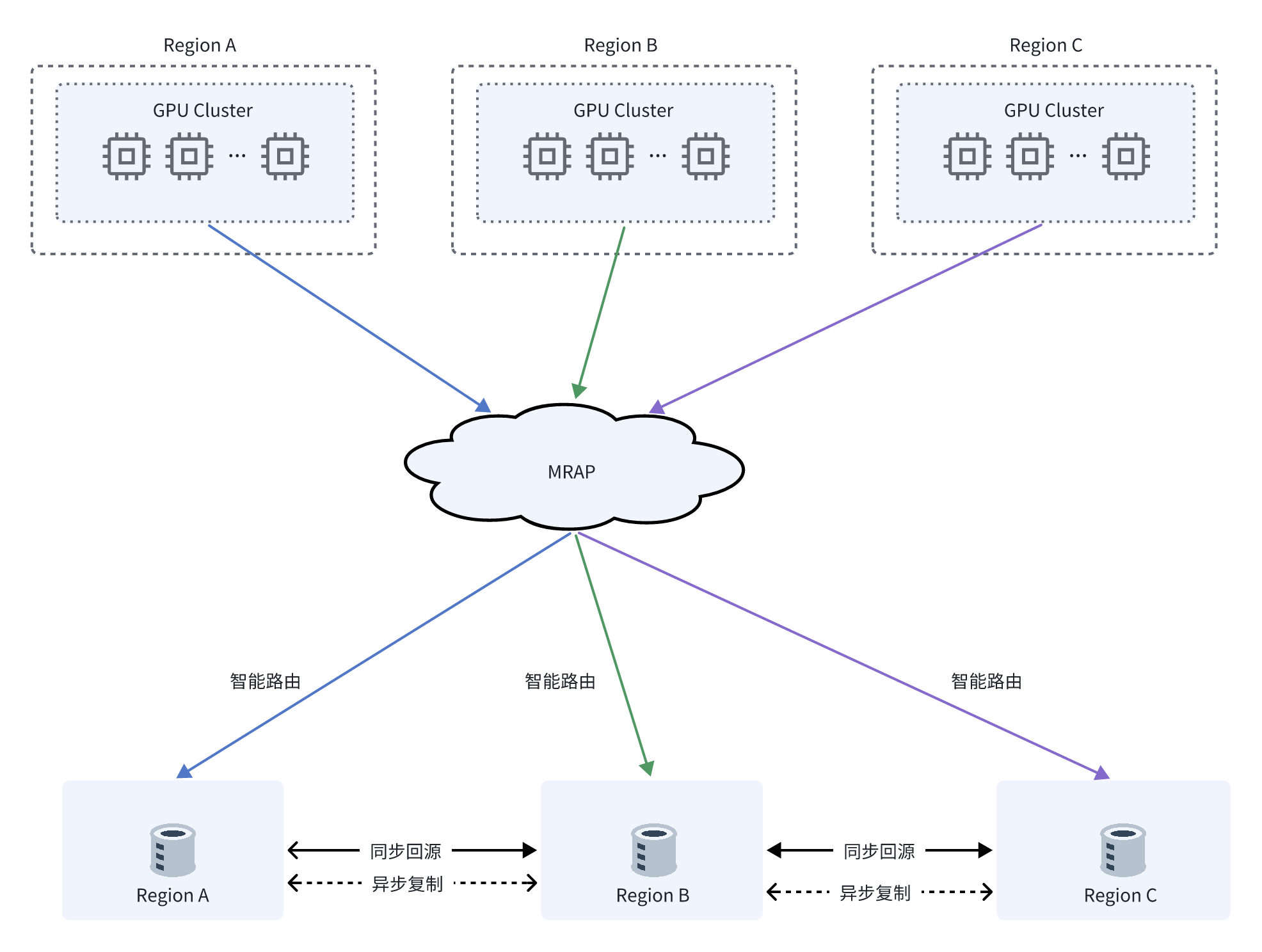
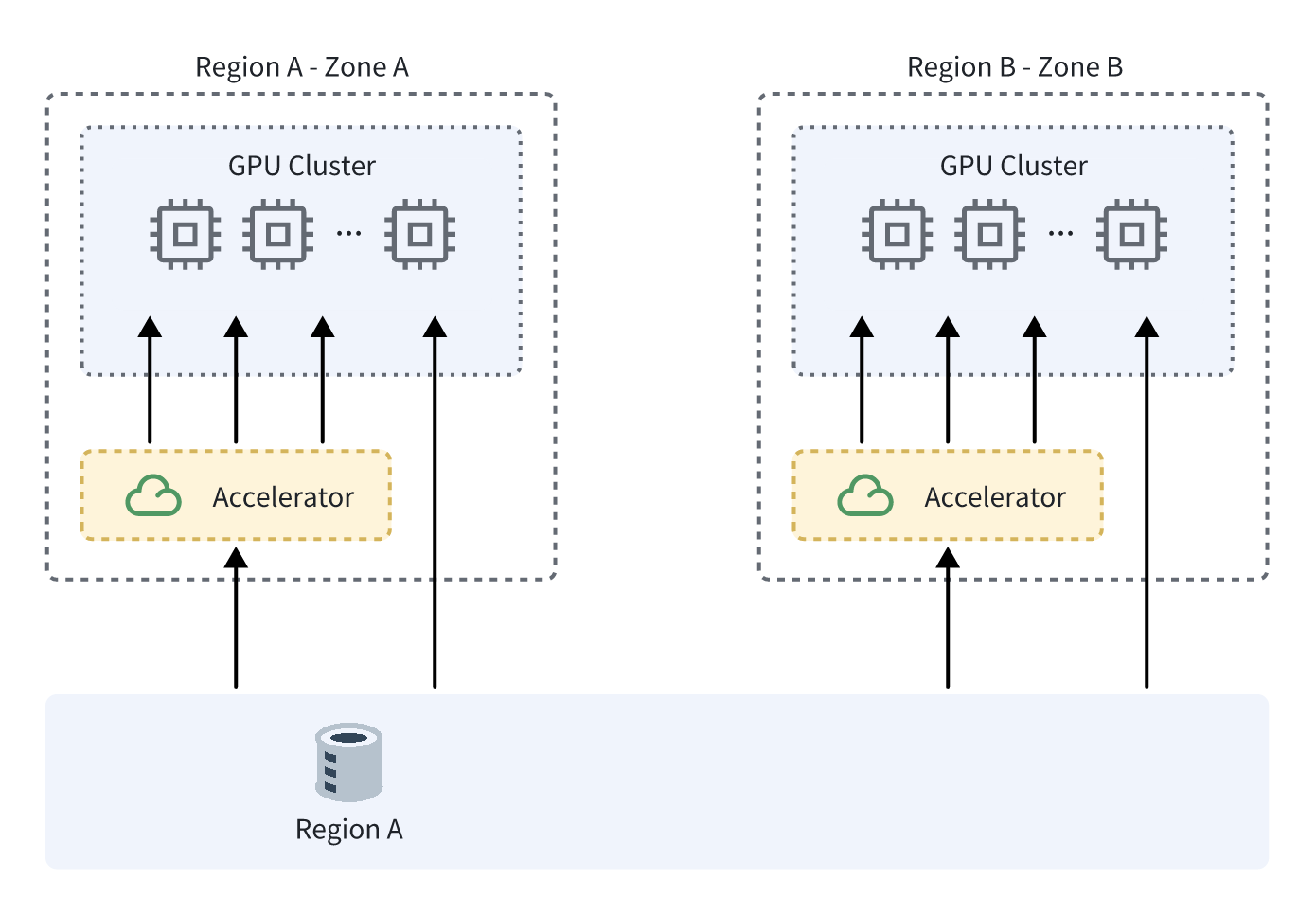
MRAP 模式
传统模式的痛点
数据复制完成时间不可控,长期等待导致 GPU 闲置
单地域故障后,业务不可用
访问域名繁多,增加了复杂度和维护成本
TOS MRAP 的优势
支持同步回源,全局写后即读,无需等待异步复制
支持故障转移,实现区域级容灾
统一访问域名,简化网络和运维配置
首创跨域回源
火山引擎 TOS MRAP 支持跨地域同步回源能力,用户在某一地域上传对象后,在其他任意地域都可以实时读取,无需等待异步复制完成,提供强大的写后读一致性。
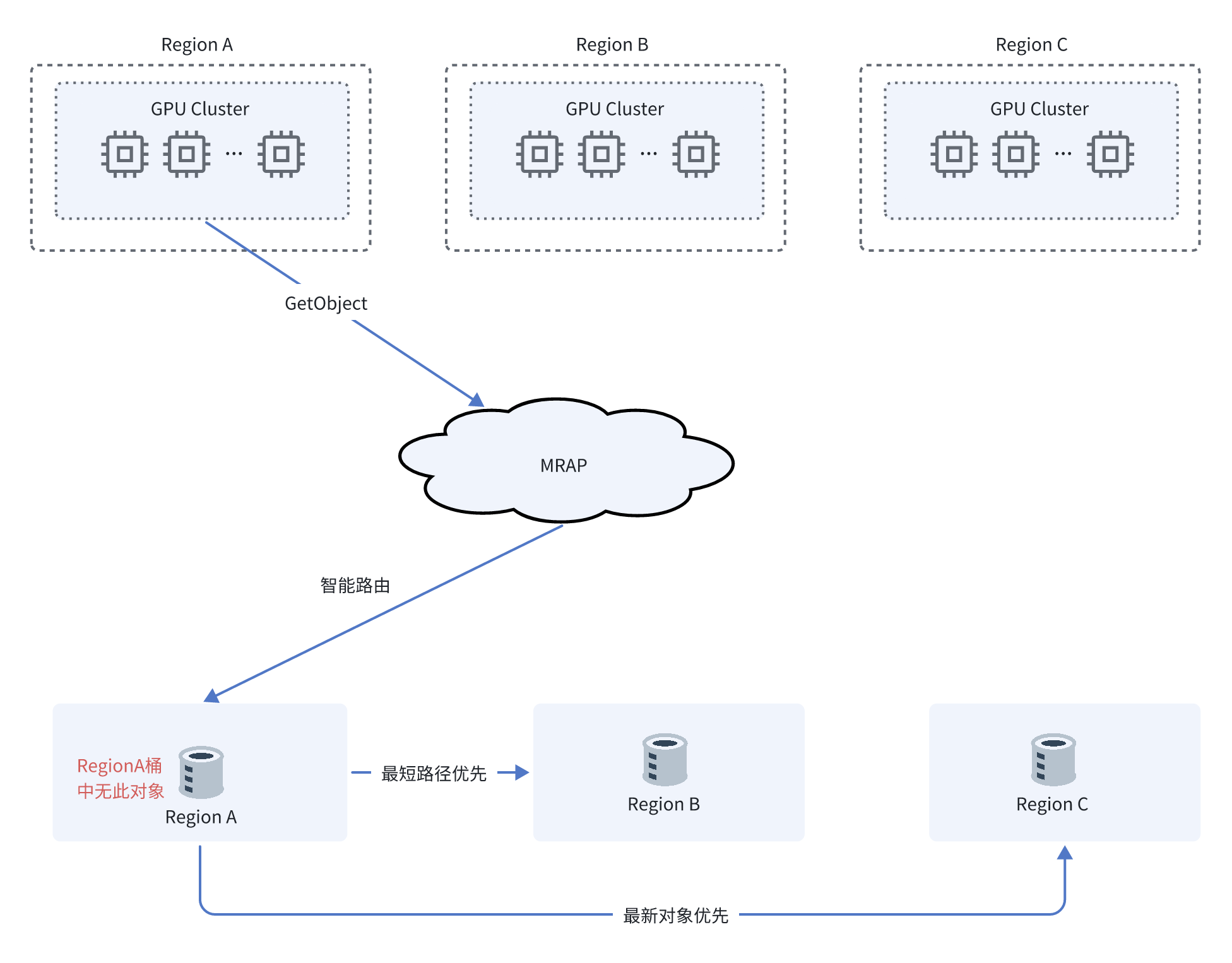
故障转移控制
MRAP 还具备分钟级的故障控制转移能力,当单个区域出现故障时,可以自动切换路由,实现区域级的 failover,整个过程对应用层透明。
TOS 加速器:AZ亲和的服务端缓存
TOS 加速器是专为AI训练、推理等需要海量带宽和数据重复读取的场景设计的全托管缓存服务。它基于高性能的 SSD存储介质,将数据“拉近”到计算集群,提供毫秒级的访问延迟和高达百 GB/s 的吞吐能力。
传统近计算缓存的局限
客户端空间有限,扩缩容复杂,成本高。
数据一致性多为最终一致,难以保证。
多产品拼装,增加了复杂度和维护成本。
TOS 加速器的优势
弹性伸缩,容量可灵活调整。
强一致性,更新即生效。
服务端全托管,集成与运维零负担。
工作流程
创建加速器时绑定加速器域名(MRAP 域名),通过绑定的加速域名即可轻松访问加速器内的资源,具体访问流程如下。
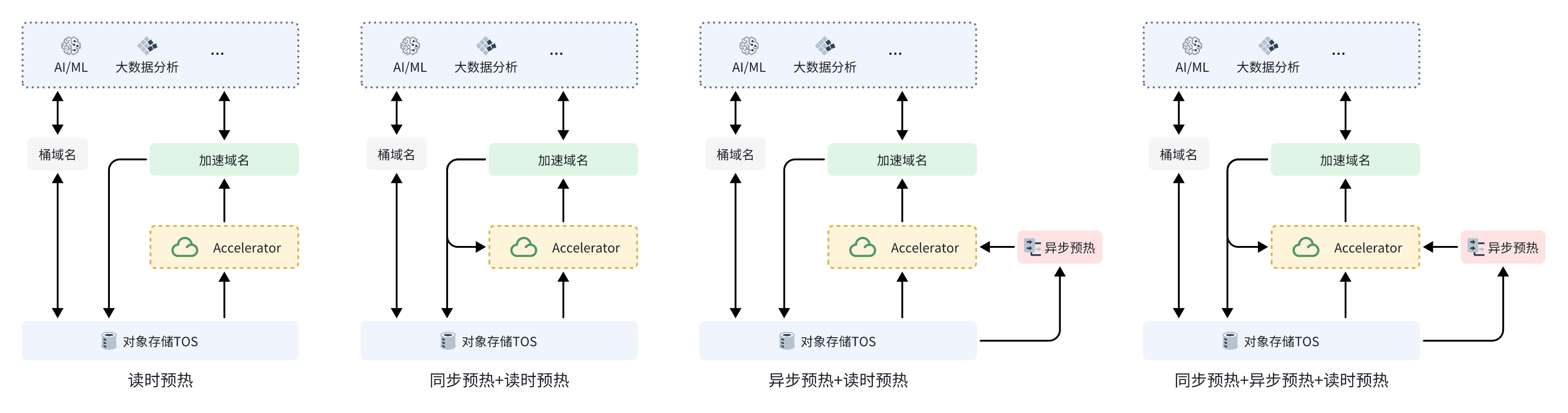
读请求
客户端通过加速域名向加速器发送读请求,该请求会自动转发到 TOS 加速器。
收到读请求后,TOS 加速器会从缓存空间中查找数据。
如果加速器中存在该数据,则直接返回给客户端。
如果加速器不存在该数据,则从 TOS 中读取数据返回给客户端,同时写入到缓存空间,此时如果缓存空间已满,则根据数据热度淘汰缓存空间中的低热度数据,再将数据写入缓存空间。
写请求
客户端通过加速域名向加速器发起写请求时,请求会直接转发至 TOS,并将数据写入到 TOS 中。
功能优势
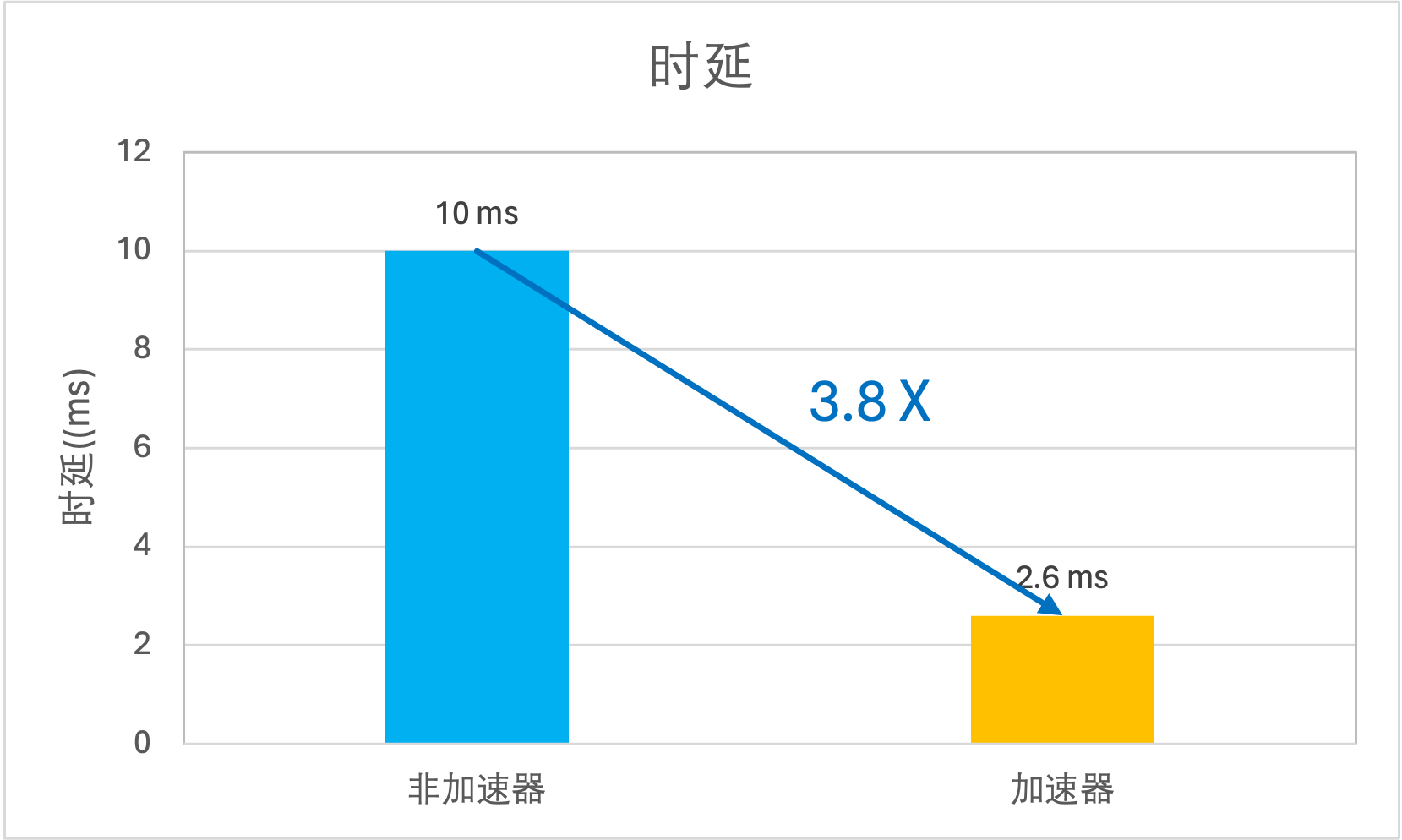
时延
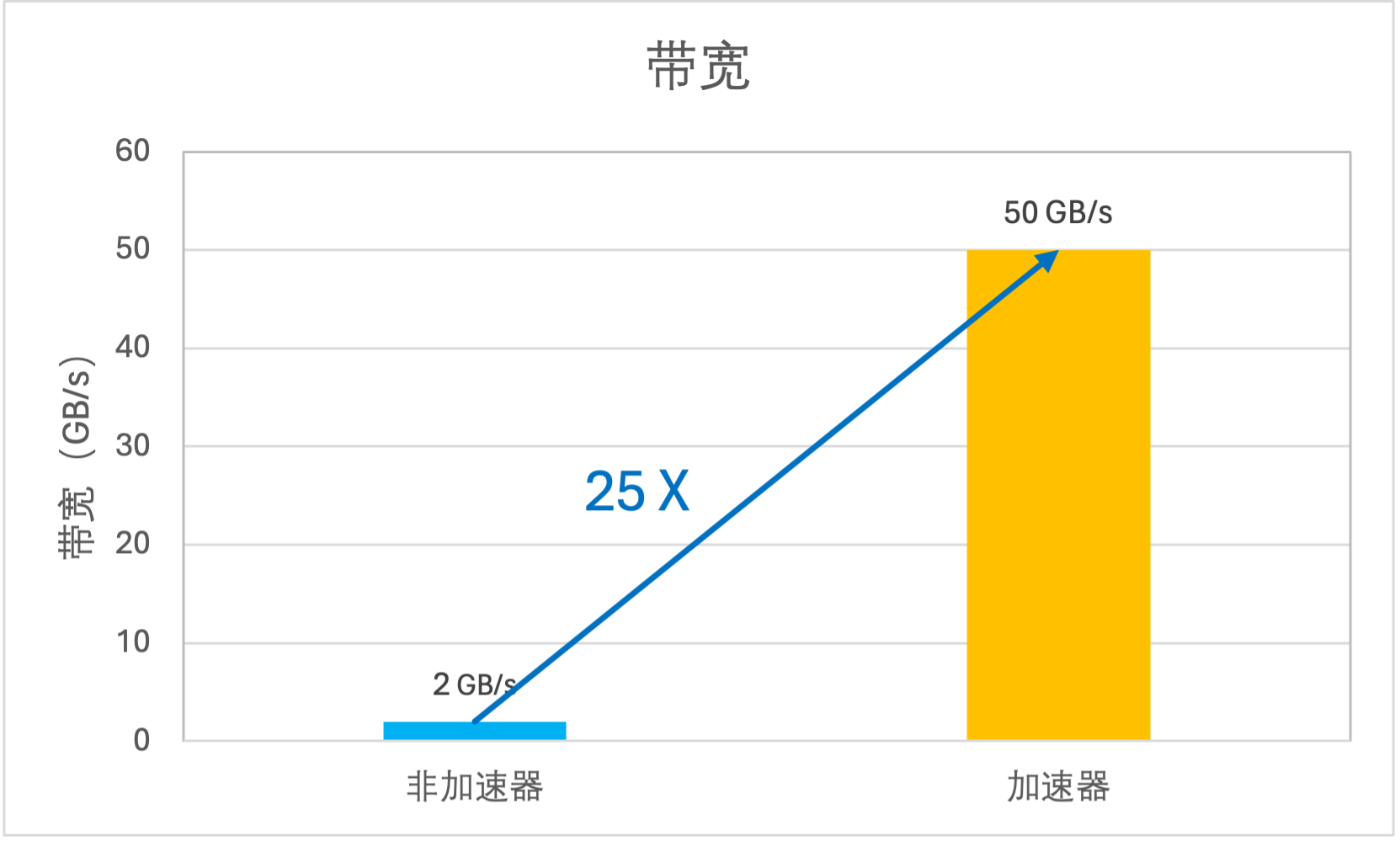
带宽
低时延:加速器缓存数据与用户计算资源处于同一可用区,可提供毫秒级下载时延。
高吞吐:加速器带宽随容量线性增长,提供高达百 GB/s 的吞吐能力。
弹性伸缩:加速器容量可以灵活地扩容或缩容,适应业务快速变化。
强一致性:当 TOS 上的数据发生变化,通过加速器读取数据时,加速器会自动重新加载新数据,确保始终获取到最新的数据。
多种预热策略:提供多种预热方式,包括读时预热、同步预热和异步预热,满足不同业务场景的预热需求,提升访问效率。
数据一次写入,多可用区加速:数据写入 TOS 后,用户在任何计算资源所在可用区创建加速器,即可获得性能加速效果,而无需重复写入数据或者迁移数据。
实际客户解决方案解构
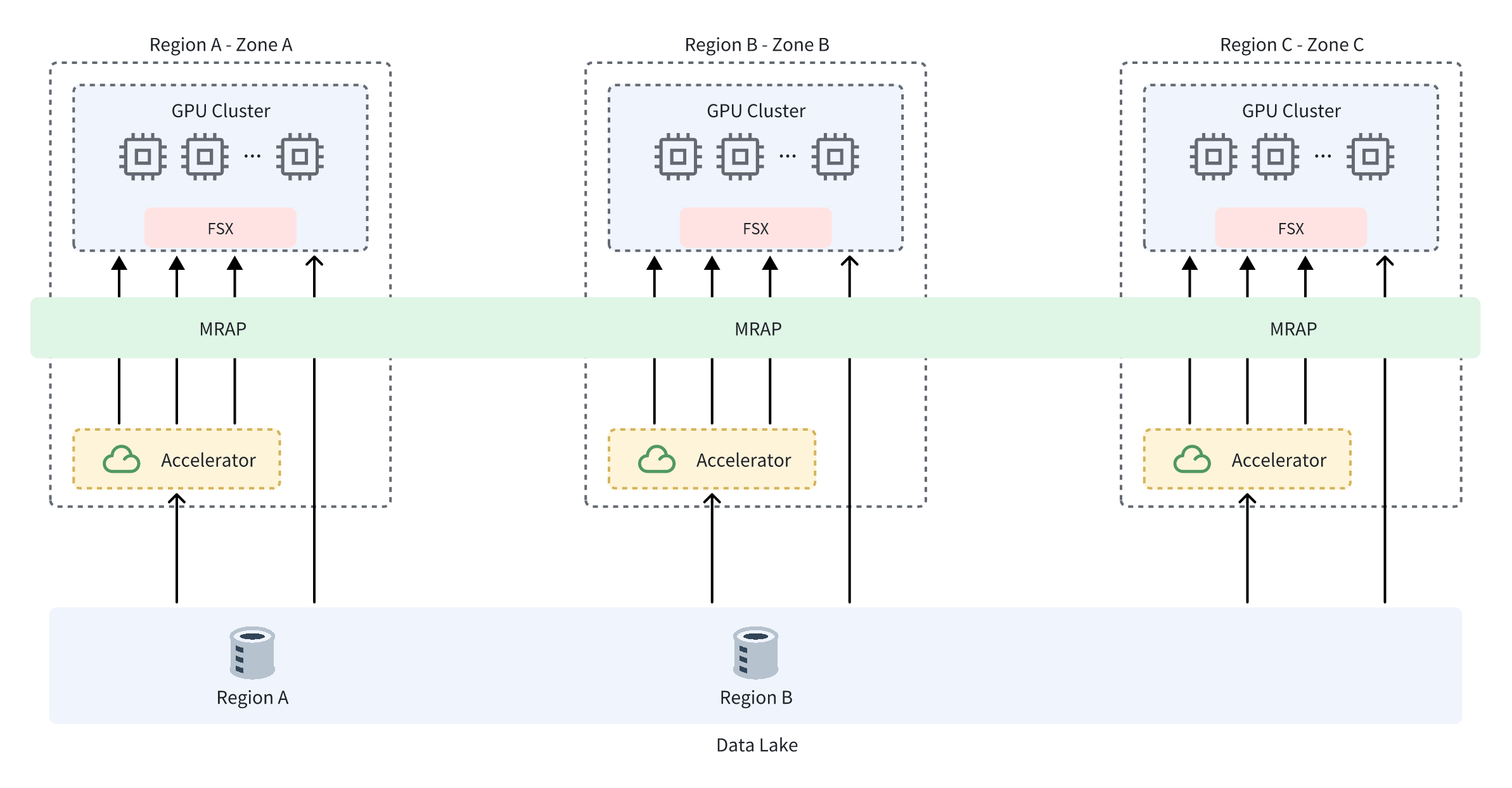
智能驾驶客户,海量多地域训练数据,存储到 TOS 数据湖,使用 FSX+加速器+MRAP 实现全链路加速和数据流动
面向跨地域的训练数据采集与复用,统一存储到 TOS 数据湖;在训练集群端侧通过 FSX 提供高性能 POSIX 文件访问,在访问接入层通过 MRAP 做跨地域统一接入与就近路由;在数据侧通过 TOS 加速器实现热点数据低时延高吞吐的读加速,形成端到端的数据流动与性能闭环。
FSX
POSIX 文件访问,高吞吐低时延。
就地挂载,兼容训练框架文件接口。
MRAP
跨地域统一入口与就近路由。
故障转移与策略统一配置。
TOS 加速器
同 AZ SSD 服务端读缓存,强一致。
缓存预热与淘汰策略。
以某头部 AI 大模型公司的实践为例,通过深度整合 FSX+MRAP+加速器的全链路加速方案,其训练数据加载环节实现了从 "数据流动效率" 到 "访问时延" 的多维性能跃升。FSX 通过分布式缓存、Bypass Kernel 模式等技术将读取吞吐提升至传统方式 2 倍以上;MRAP 实现多地域数据即时协同访问;TOS 加速器将热数据同 AZ 访问 P99 时延从 200ms~400ms 降至 70ms,最终数据加载整体效率提升 100%。
总结
在 Data+AI 时代,面对生成式 AI 与智能驾驶等场景所催生的海量数据存储需求,传统对象存储需应对三大核心挑战:POSIX 协议转换性能不足、分布式训练数据跨域协同困难、分布式训练场景下的存储性能瓶颈(高频并发访问导致算力空转)。针对这些问题,TOS 创新性地提出 FSX+MRAP+加速器 全链路加速方案。其中,FSX 实现了 AI 场景下 POSIX 协议转换能力的打通,MRAP 解决了分布式训练场景下多地域数据协同的难题,加速器在近计算资源侧提供全托管缓存服务,以满足模型训练推理的极致性能需求,为 AI 应用赋予全局动力。