linux:io基础
1.文件理解
基本理解
1.文件 = 文件内容 + 文件属性:文件内容为0不代表文件占用空间为0,因为文件属性是一定存在的,一定会占用一定空间
2.访问文件就需要先打开文件,打开文件的方式就是将文件加载到内存当中
3.文件没有被打开之前就会存储在磁盘中
4.文件的打开流程:编写代码,通过bash启动进程,进程通过调用库函数,库函数内部调用系统调用,从而让操作系统去打开文件
2.c语言中的文件操作
2.1访问方式
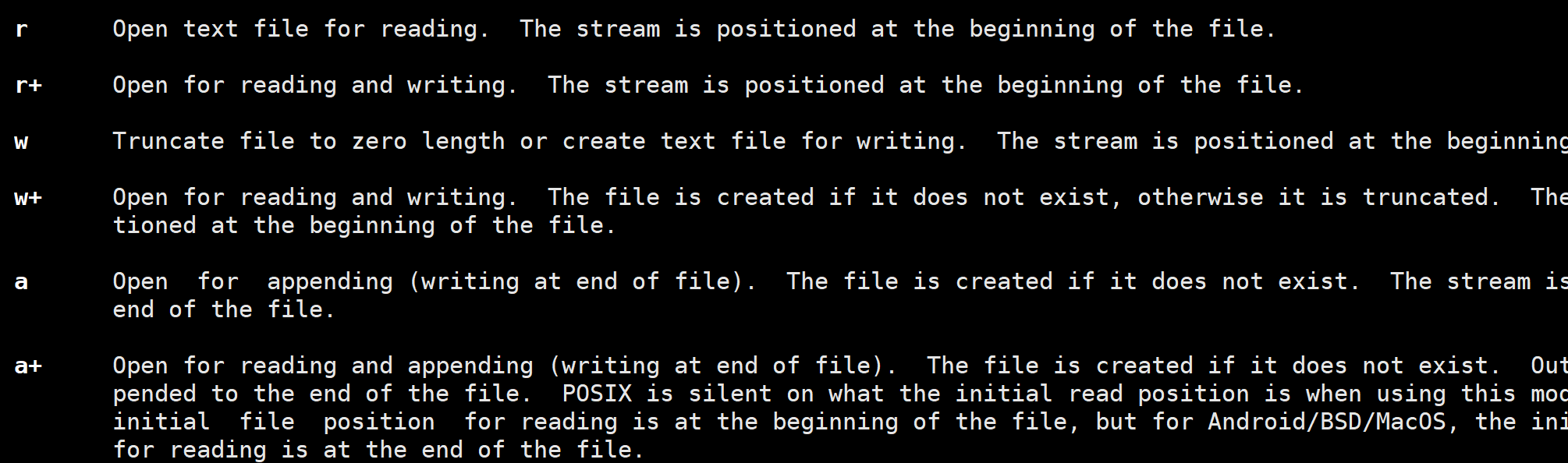
一共有六种方式
1.r:以只读方式打开,文件不能修改,只能阅读,阅读位置是从文件开头位置开始
2.r+:以读写方式打开,同样是在文件开头位置进行读写
3.w:若文件存在,将文件清空后从文件开头写,若文件不存在则创建文件
4.w+:和w相比多了读功能
5.a:文件不存在就创建文件并追加内容,文件存在就从文件内容结尾位置开始追加内容
6.a+:和a区别在于多了读功能,且读是从文件内容开头开始,追加是从文件的结尾位置开始
2.2文件调用接口
1.fopen与fclose
fopen主要用于将文件流打开,第一个参数是文件的路径,若选择打开当前路径文件,直接写文件名即可,若不是当前工作路径就需要完整的路径。第二个参数是打开模式。
打开失败返回NULL,成功返回对应的文件指针
fclose用于关闭文件流,参数就是文件指针。成功返回0,否则返回EOF(-1)
这里我们直接在当前路径下创建一个test.txt文件,然后利用fclose关闭文件
这里我们使用了w方式访问,当使用a访问方式时,相当于将操作设置为追加操作,在文件内容结尾进行追加写入
疑问1:这里只传递了一个文件名,而没有文件路径,进程是如何知道具体的创建路径的?
其实是因为进程会记录下当前工作路径cwd,然后将文件默认创建在cwd路径下
旧知识原理理解:
1.文件的读写有位置,意味着文件其实可以看成一个“一维数组”,文件的读写位置就是数组下标,而写入文件的就是一个个字符2.输出重定向其实就相当于C语言中使用w访问文件,有内容就清空目标文件内容然后写入,没有内容就直接清空文件
3.追加重定向同理,等于c语言中的a访问方式,直接将文件内容追加到目标文件结尾处
4.输入原理:我们向键盘文件输入的都是一个个字符,然后C语言中的scanf有格式化字符,如%d,就可以将输入字符按照整型方式解读出来,然后将值传递给对应整型变量
根据这个知识我们也可以理解#include" " 和#include<> 的查找是谁在查找,如何查找了
#inlcude""是在编译器在当前路径下查找(编译器也有cwd),而#include<>是在库文件中查找,找不到再从当前路径查找
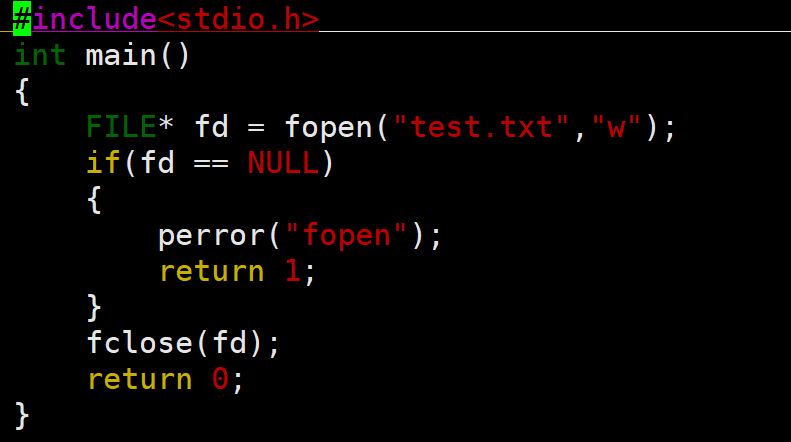
2.fwrite
fwrite用于向指定文件写入内容,第一个参数是写入内容的指针,第二个参数是写入内容的单位大小,第三个参数是写入的个数,最后的参数是文件指针
返回值:成功时返回数据项总量,失败时返回值小于目标数据项传输量
注意传输数据项单位大小时,不要为了补充c字符串结尾的\0写成strlen()+1,因为这是c语言的格式要求,写在文件里可能会出现乱码




2.3进程默认打开文件
进程默认会打开三个文件,标准输入流stdin,标准输出流stdout,标准错误流stderr
1.stdin:属于键盘文件,一般我们输入键盘的数据都会写入键盘文件中
2.stdout:属于显示器文件,我们输出的数据其实就是写入到了显示器文件中
3.stderr:属于显示器文件,错误信息需要告诉程序员,所以会写入到显示器文件中
3.系统文件io
3.1文件描述符
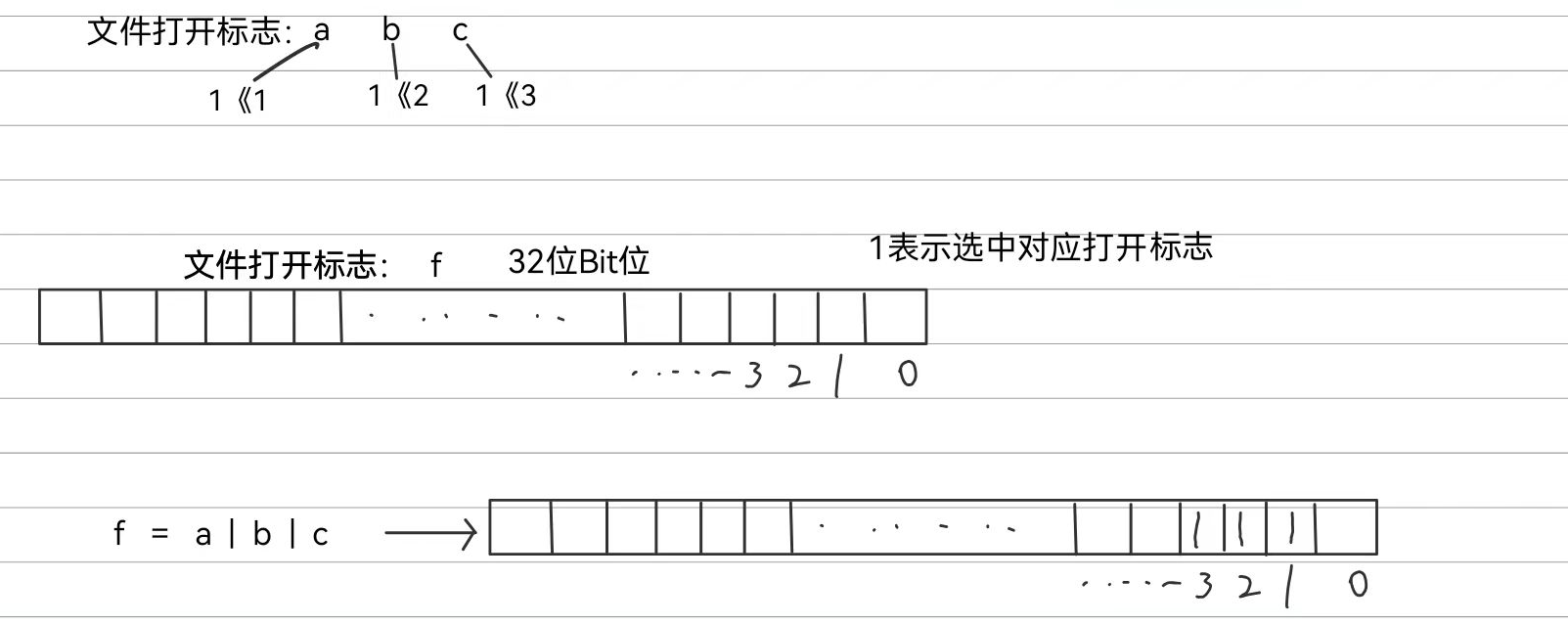
这是系统调用的打开文件接口,其中第二个整型参数flags就是文件打开标志的集合,可以按照位图方式将标记位整合起来
图示:
a,b,c分别代表三种不同的文件打开标志,其中a的值为1<<1,b的值为1<<2,c的值是1<< 3.
flags是整型变量,有32个bit位,每个比特位上可以表示一种文件打开标志的选择状态,1表示选中对应的文件打开标志,0则表示没选中
我们通过按位或的操作可以将不同的文件打开标志选择状态合并起来,然后赋值给flags,从而flags就有了对应文件打开标志的选择状态
需要注意的是,虽然可以自由选择不同的文件打开标志,但是有三个打开标志是必须从中三选一的
就是要确定访问方式是读,写还是读写都有
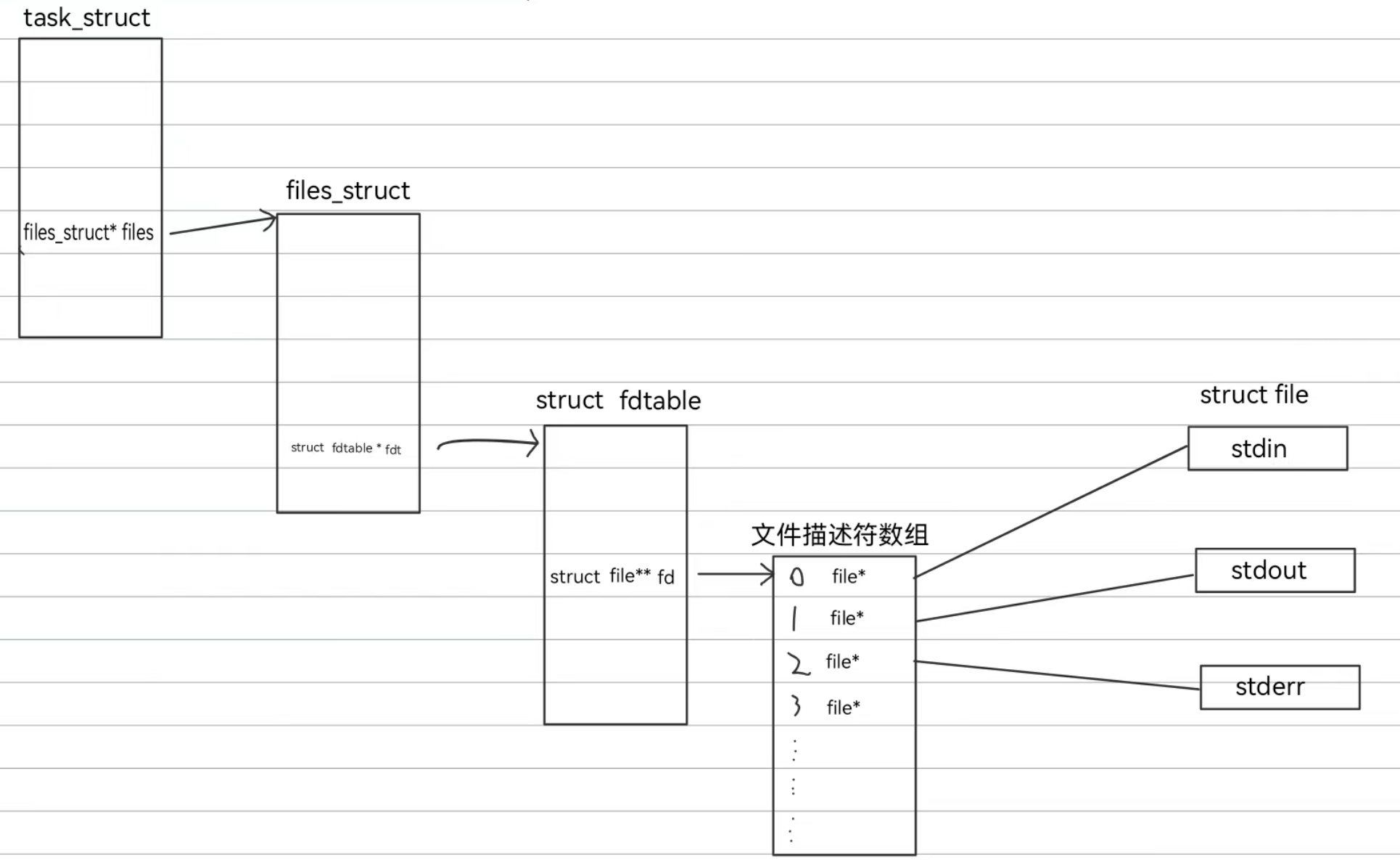
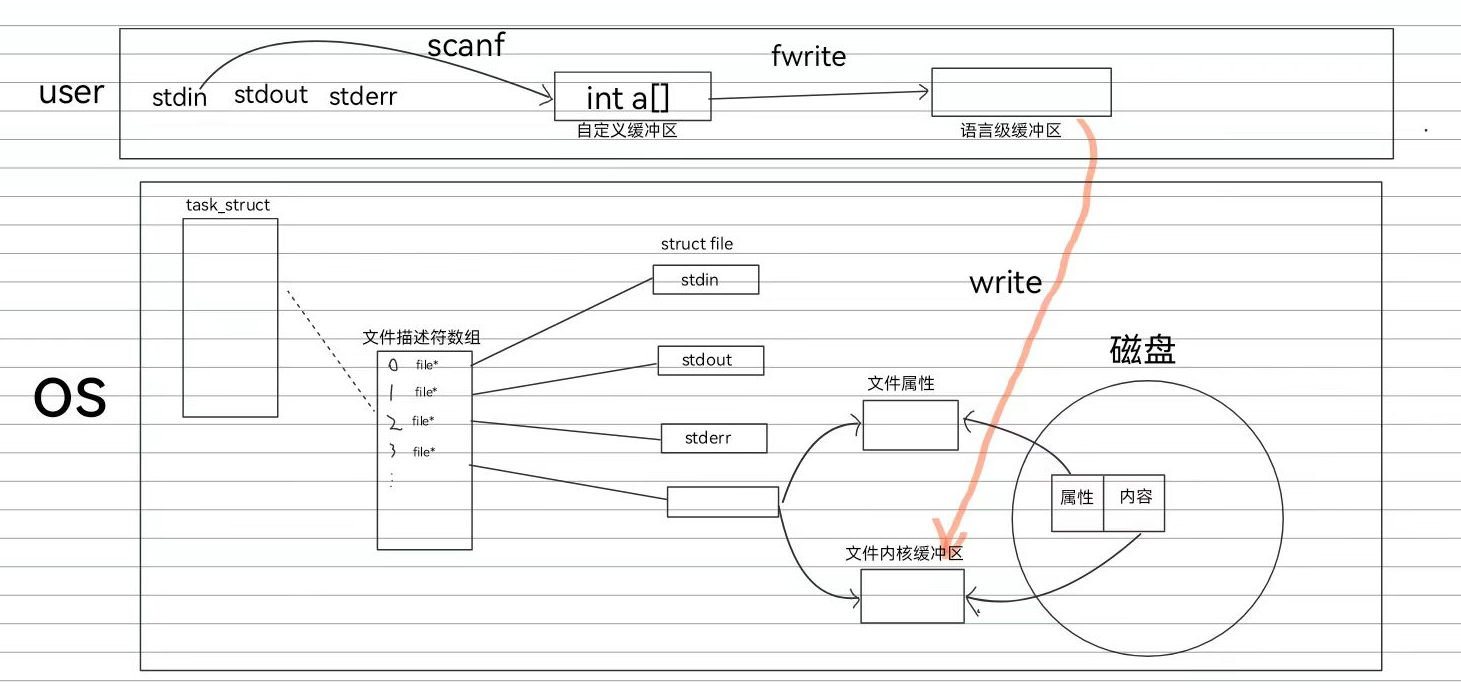
文件描述符的本质:数组的下标
层级结构:
进程控制块(task_struct)->files_struct(文件管理结构体)->fdtable(文件描述符表)
->fd_array[](文件描述符数组)
在文件描述符指针数组中记录了指向各个打开文件结构体file的指针,然后该数组的下标就是文件文件描述符,是局部进程中操作系统用于识别文件的标识
注意:
1.前三个索引的文件描述符默认为0:标准输入流(stdin),1:标准输出流(stdout),2:标准错误流(stderr),后面的索引才会给到新创建的文件

3.2系统调用接口
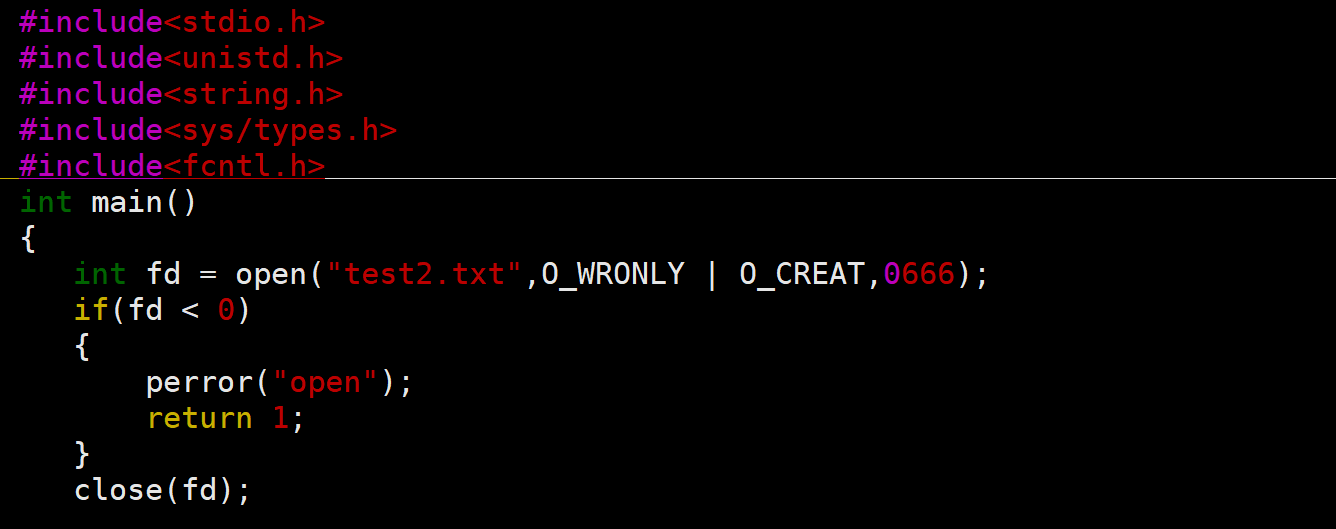
1.open与close
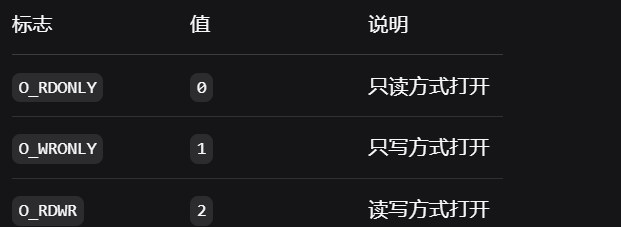
我们在当前工作路径中创建一个只写入的文件test2.txt,并设置权限为0666。
如果open成功就返回对应的文件描述符(相当于文件在文件管理结构体中的id),失败返回-1
注意:系统调用中不会默认创建文件,我们需要自己传递O_CREAT才会创建,权限也是同理,我们需要自己设置权限信息
疑问:这里为什么test2.txt的权限信息是0664,而不是我们设置的0666?
因为有权限掩码为0002,将other用户的写权限删掉了,我们可以在代码中将权限掩码设置为0,那么最终的权限就是0666了
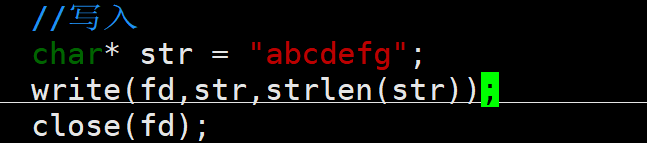
2.write
参数1:文件描述符
参数2:写入的内容的指针
参数3:写入的内容所占字节大小
返回值:成功写入就返回写入的字节数大小,有可能小于我们要求写入的字节数。失败就返回-1
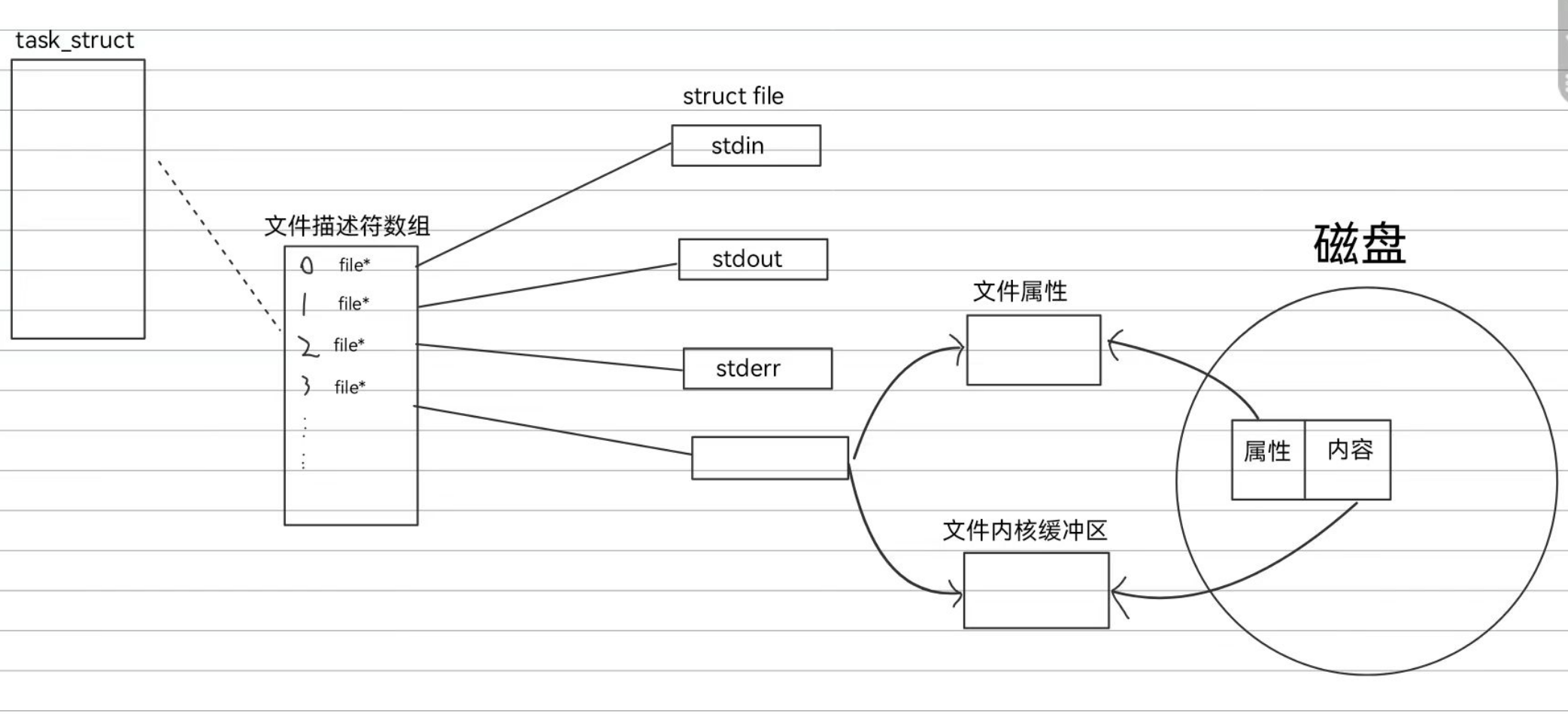
write的本质:将数据从用户定义的缓冲区中拷贝到文件内核缓冲区
当我们打开文件时,磁盘就会将文件属性和文件内容分别加载出来,然后file结构体就可以用指针指向对应的加载空间,当我们需要使用write进行文件内容写入时,直接将用户定义的缓冲区的内容拷贝到文件内核缓冲区,然后等待操作系统将文件内核缓冲区的内容同步给磁盘空间
注意:
1.由于冯诺依曼体系结构,我们无法直接读写磁盘中的文件,所以不仅在写的时候是将内容拷贝到文件内核缓冲区,进行读操作的时候也是只能读取文件内核缓冲区,所以如果磁盘中的内容还没有加载到该地区,我们的读操作是会被阻塞的
3.系统调用模拟库函数的功能
1.模仿w选项功能
w功能不仅需要在没有文件的时候创建对应文件,且需要对原有文件数据信息清空,所以选用了O_CREAT和O_TRUNC
2.模仿a选项功能
a功能同样需要创建不存在文件,但是不用情况旧文件内容,而是直接追加在旧文件内容末尾,所以选用O_CREAT和O_APPEND
3.模仿r选项功能
理解1:C语言的fopen库函数就是封装了上述的系统调用来实现r/w/a功能的
理解2:C语言封装系统调用接口的目的,一是为了降低用户使用门槛,二是为了让C语言具有跨平台性(跨操作系统),从而在不同操作系统都可以运行
为什么要有跨平台性?
为了让该语言的使用者更广泛,维持语言的活力
如何具有跨平台性?
由于不同的操作系统有不同的系统调用,所以我们一种语言实现一个库函数,实际上需要对不同的操作系统进行区分,然后根据不同的操作系统的接口来进行封装,最后实现语言兼容多操作系统



4.重定向
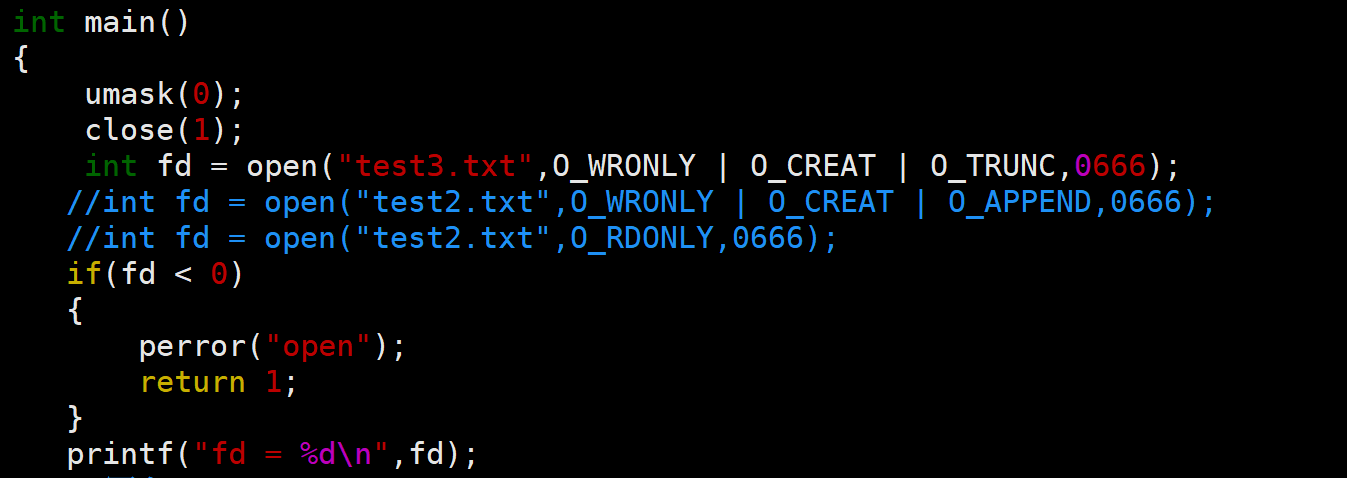
我们先看看如下的现象
我们先关闭文件描述符为1的文件,然后申请了一个叫test3的文件并设置为只写权限,最后往显示器输出一个语句
实际结果:运行之后没有输出信息,但是信息写入了新创建的文件test3中
这是因为关闭了文件描述符为1的文件相当于将标准输出流给关闭了,然后新申请的文件分配文件描述符的方式是直接分配能够获取的最小的文件描述符,所以新文件的文件指针就存储到了文件描述符为1的位置
又因为printf实际上就是往文件描述符为1的位置进行写入(一般情况下文件描述符为1都是stdout),所以此时就会在新文件中进行写入
输出的内容从显示器变为了指定文件中,这种情况不正是我们的输出重定向吗!!!
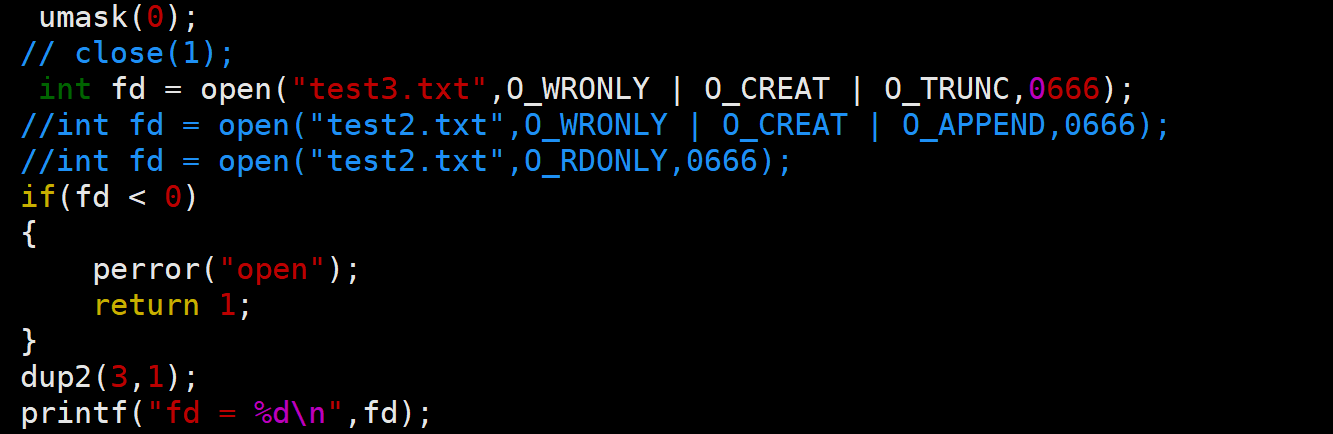
实际上我们会使用系统调用函数dup2来进行文件指针改变,从而实现重定向
参数1:旧文件描述符,参数2:新文件描述符
假设我们要把信息打印从显示器重定向到某个新文件(fd = 3),那么我们可以利用dup2将文件描述符为3位置的文件指针拷贝覆盖文件描述符为1位置的文件指针
函数作用描述:将oldfd文件指针拷贝覆盖newfd文件指针
所以在这里,oldfd就是3,newfd就是1
利用dup2实现输出重定向
我们使用了dup2函数将输出重定向为fd=3的新文件,所以后面的printf语句输出的位置就不是显示器,而是新文件test3.txt
疑问1:在重定向中,子进程是如何看待父进程打开的文件的?
子进程会直接浅拷贝继承父进程的文件描述符表,对应位置的指针数据都会拷贝下来,但是不会新创建对应的文件,而是和父进程指向同样的文件。而子进程继承父进程文件描述符表,正是子进程默认打开stdin,stdout和stderr的原因由于管理文件时采用引用计数方案,所以子进程关闭某个文件不会影响父进程的访问,只会让引用计数--,直到引用计数变为0才会真正关闭对应文件
疑问2:进程程序替换会影响我们之前打开的文件吗?
不会,任何对文件的操作如创建/关闭/重定向等都会继承给信替换的程序
补充:
stdout与stderr重定向实现输出流与错误流分离
//输出流与错误流分离 ./a.out 1>output.txt 2>err.txt实现输出流与错误流一起重定向到指定文件
./a.out >log.txt 2>&1>log.txt其实就是1>log.txt,然后&1的含义是将索引为1的文件描述符表存储的指针拷贝给索引为2的文件描述符表位置,也就是让fd为2的文件重定向为fd为1的文件


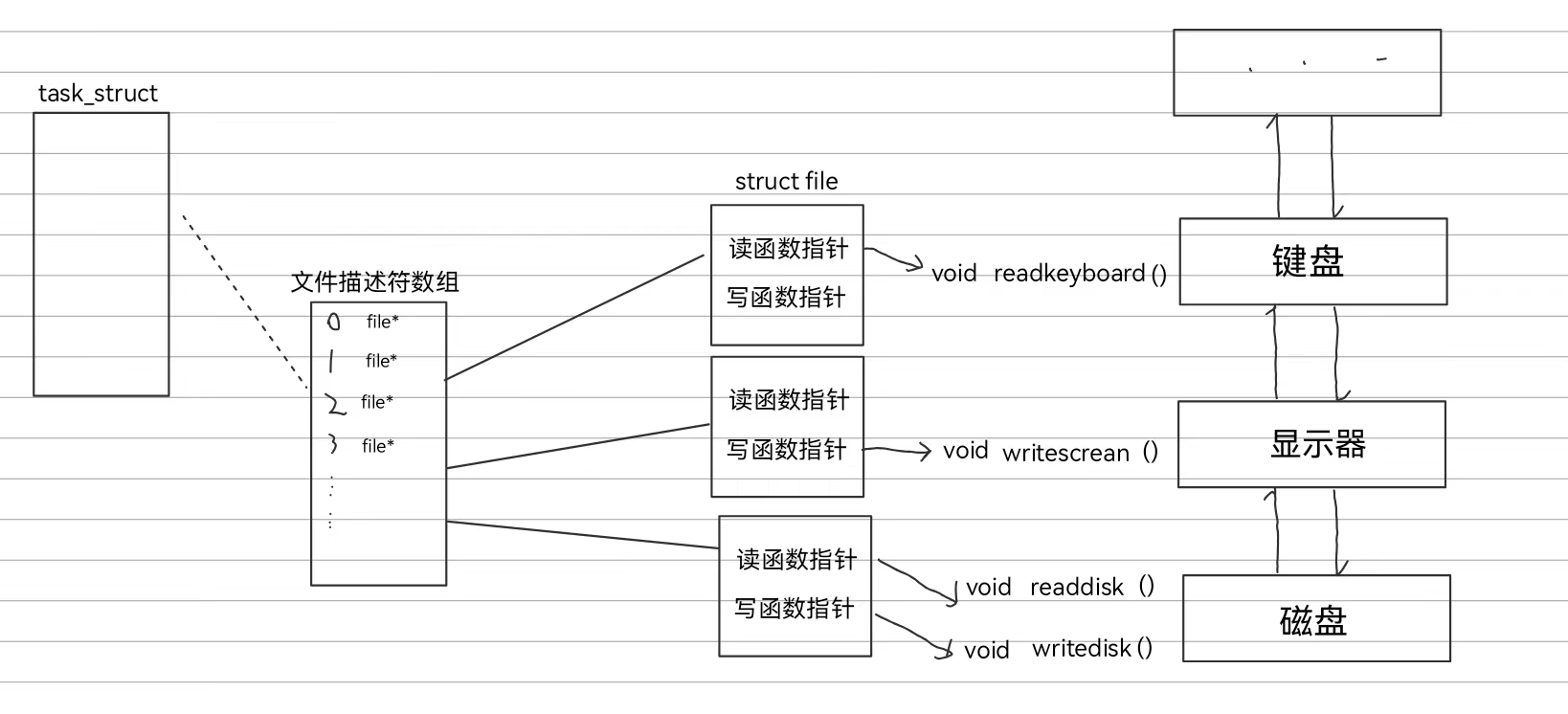
4.一切皆文件文件理解
(1)对硬件访问上
图示:
所有硬件的访问方式都是不一样的,每种硬件都有对应的读写函数,而访问设备都是进程在进行访问,进程中会有PCB进行进程管理,而PCB又会管理文件描述符表,文件描述符表会用指针指向FILE结构体,这些结构体用于文件管理。
由于我们说一切皆文件,所以对硬件的读写就会通过FILE结构体中的读写来进行,所以在进程层面上我们看到一切都是文件的操作
如图所示:需要访问不同硬件的文件会利用自身的读写函数指针去指向对应硬件的读写函数,从而在进程层面我们不需要关注访问的硬件是什么类型,FILE结构体会帮我们解决
注意:
系统调用的read和write负责把数据拷贝到文件内核缓冲区,主要是属于虚拟文件系统区域的
而这里的read和write函数负责去访问对应硬件,是属于硬件区域的
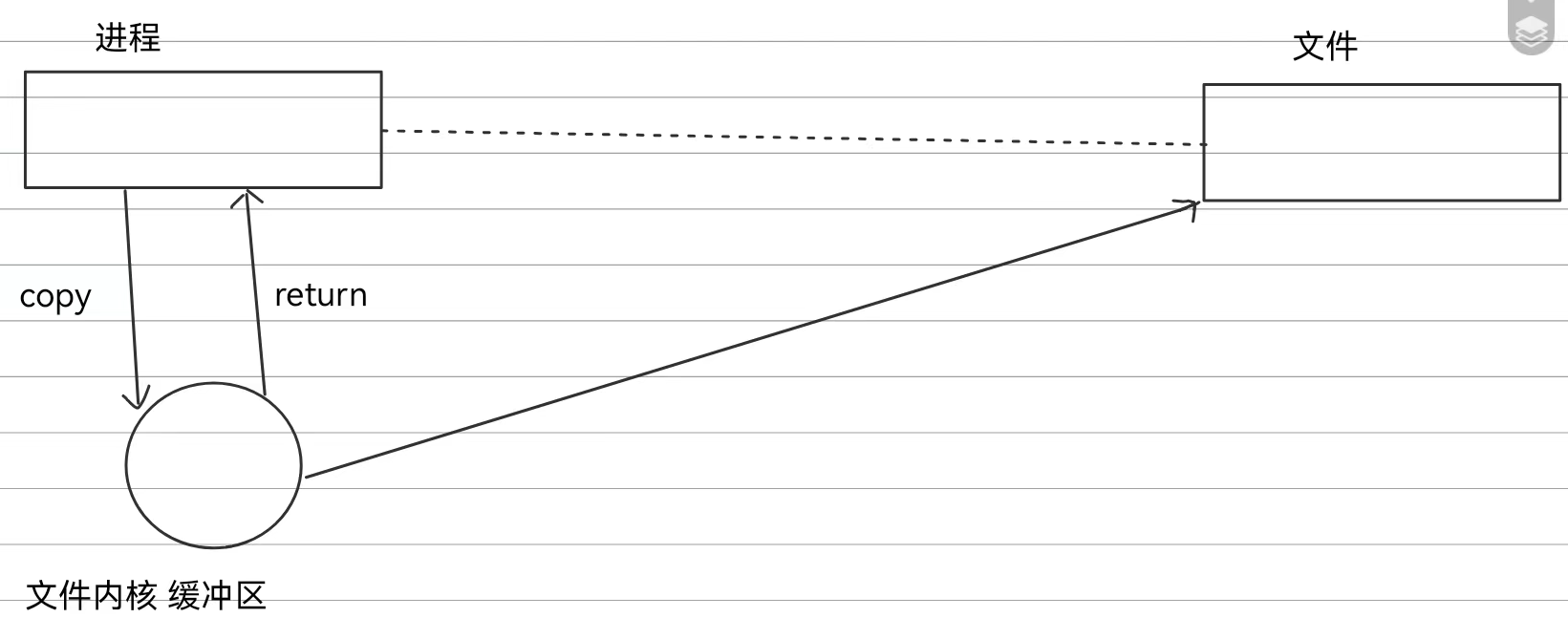
5.缓冲区
本质:缓冲区就是一段内存空间
缓冲区的意义:提高使用缓存的进程的效率
图示:
解释:
由于对文件进行写入是一个较为缓慢的过程,如果我们让进程直接和文件交互,进程就会一直阻塞等待写入完成,此时等待的时间由进程承担,他不能在写入过程运行其他代码功能。
如果我们将进程要写入的数据交给对应缓冲区,那么接下来就由缓冲区负责等待写入,而进程就可以运行其他代码功能了
疑问:为什么缓冲区不直接有数据就刷新,而是会有数据积压?
这是因为每次一有数据就刷新会导致缓冲区过度浪费cpu等资源,io操作耗时是很高的,缓冲区的意义不仅是提高使用缓存的进程的效率,还有减少底层io次数的作用
缓冲区刷新策略:
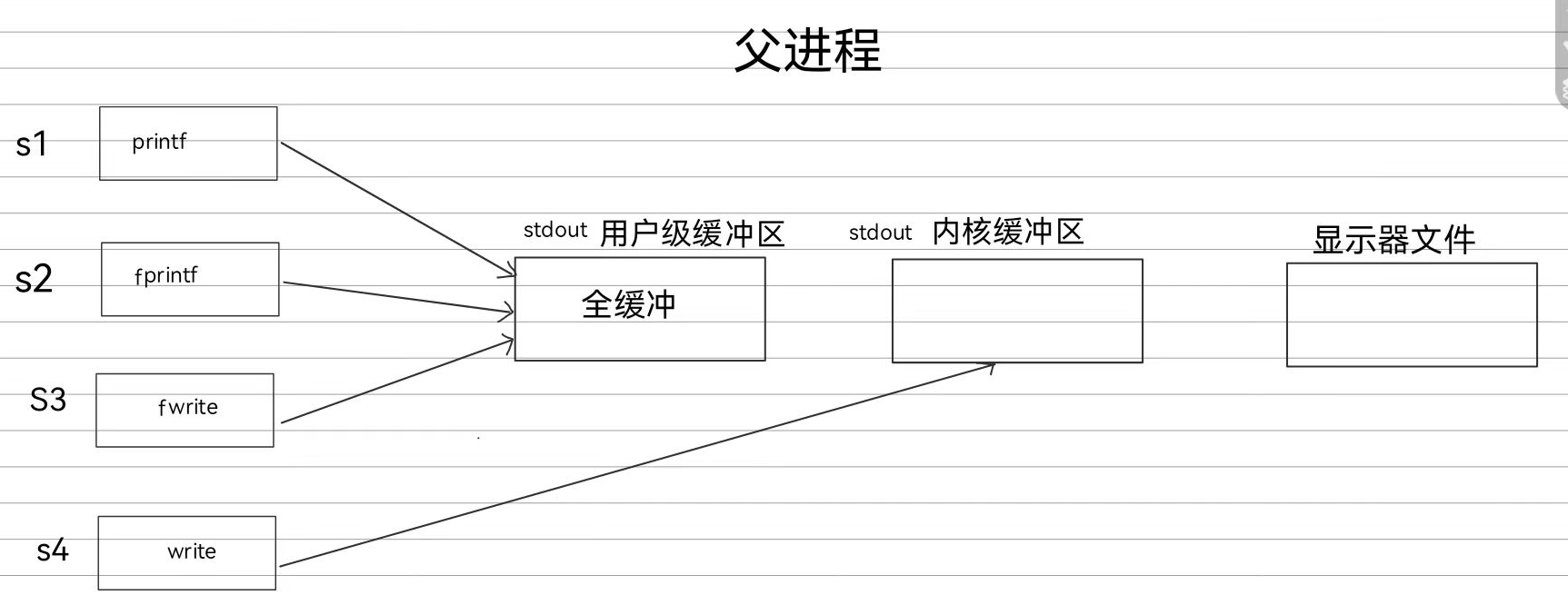
1.用户级缓冲区:
1.无缓冲:立即刷新
2.全缓冲:写满缓冲空间再刷新
3.行缓冲:根据换行符进行刷新,一遇到\n就刷新该符号前的数据
常见刷新情景:
1.进程结束自动刷新2.使用fflush强制刷新
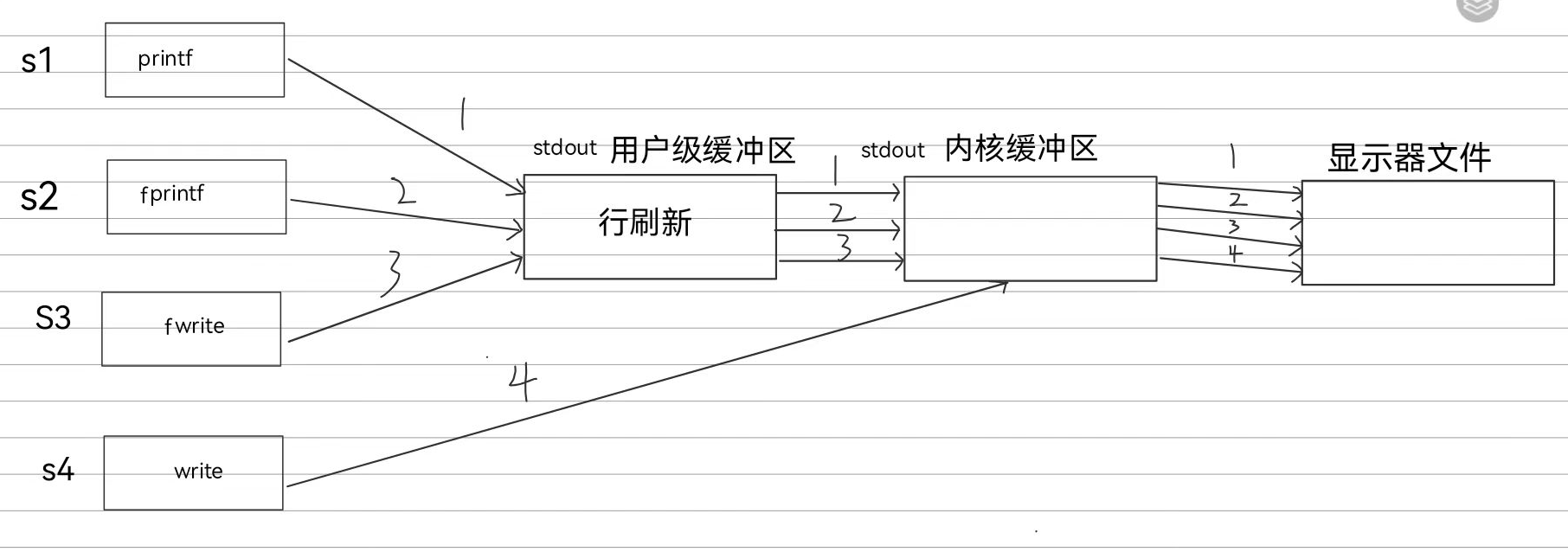
数据流过程:以从键盘读取数据并写入指定文件为目的
首先从文件标准输入流中获取数据并存储到我们的数组中,然后调用fwrite函数将内容拷贝到FILE结构体内部的用户级缓冲区,当满足对应用户级缓冲区的刷新条件后(比如行缓冲,就是读取到了\n)fwrite会内部调用write系统调用将数据从用户级缓冲区拷贝到文件内核缓冲区,最后文件内核缓冲区的内容就交给操作系统管理进行真正的写入
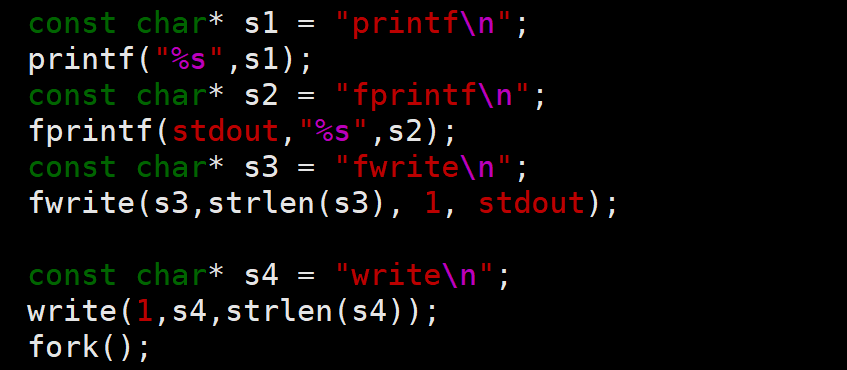
思考题:请说明为何如下代码的直接运行和重定向结果存在差异
前面三种函数都是C语言库函数调用,最后一个是系统调用
解答直接运行结果:
对于前面三个C语言库函数调用,由于每个语句都带有\n,所以在数据写入用户级缓冲区后,直接满足行缓冲刷新条件,底层调用了write系统调用,把数据依次拷贝给了内核缓冲区对于最后一个系统调用,直接写入的内核缓冲区,然后虽然fork了,可是子进程没有需要执行的代码,只看父进程输出即可,故父进程的内核缓冲区依次为上述四个句子,按顺序输出显示器
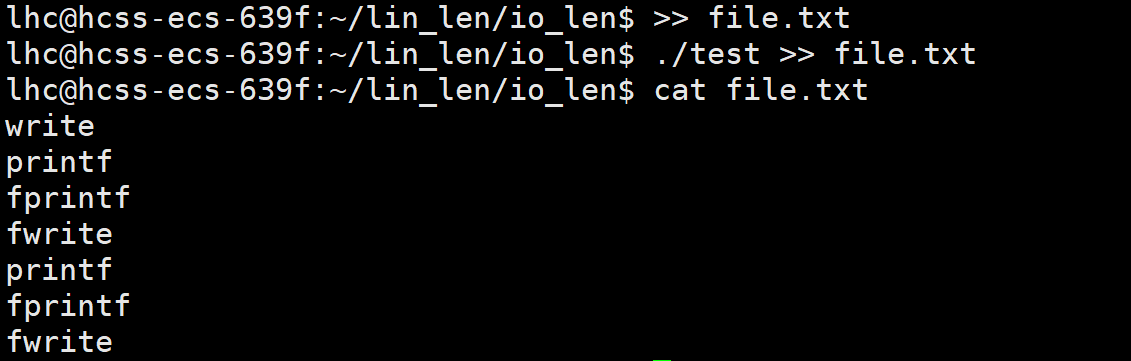
解答重定向结果:
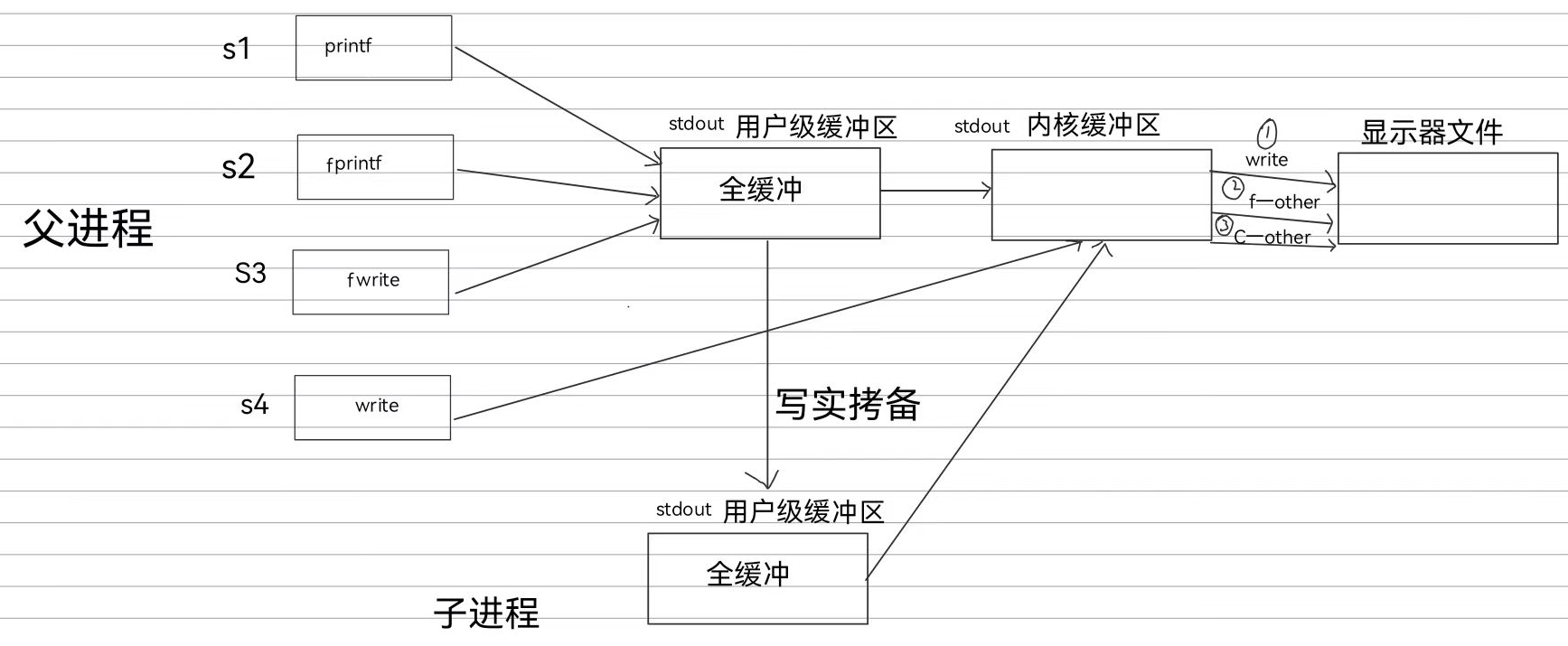
核心:当fd为1的文件不再指向真正的指示器文件时,该文件的缓冲机制变为全缓冲
所以父进程的前面三个语句会积压在用户缓冲区,而最后一个系统调用语句由于是直接写入内核缓冲区的,所以不会积压在用户缓冲区,他是第一个到达文件内核缓冲区的
然后fork
由于fork是浅拷贝直接拷贝指针,所以子进程也会指向父进程的用户缓冲区,而最后进程结束要刷新缓冲区,刷新缓冲区就是对缓冲区做修改,此时子进程会对用户缓冲区进行写实拷贝,这次子进程和父进程才是真正的都有一样的缓冲区内容,而不是共享。故最后打印了两次前三个语句
2.文件内核缓冲区一般是全缓冲,显示器文件是行缓冲,但是会有多种特殊情况,场景比较复杂
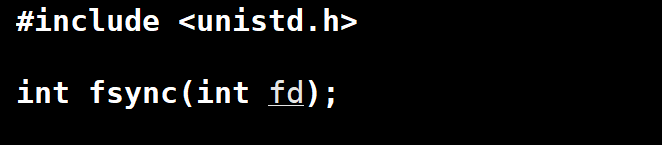
利用fsync函数将数据从文件内核缓冲区强制刷新写入到文件
只需要传递需要强制刷新写入的文件的fd值即可
三种缓冲区层次:
1.自定义缓冲区:我们在代码中定义的数组等可存储数据的结构都可以称为一个自定义的缓冲区
如果我们使用a数组存储信息,且最终需要利用a数组将其中信息传递给某个文件,那么我们可以说这个a数组就是自定义的缓冲区
2.用户级别缓冲区:这是语言的库函数中定义的缓冲区(C语言标准库中的FILE结构体),我们做显示器输入的时候,数据首先可能会从用户自定义缓冲区(定义的存储数据的数组),拷贝到用户级别的缓冲区中
c标准库中定义的FILE结构体就是用于虚拟文件层面的文件管理的,他内部会指向我们语言(用户)级别的输入输出缓冲区,所以我们要写入对应文件的数据都是先写入到该缓冲区中
3.文件内核缓冲区:这是操作系统定义的缓冲区,当我们的数据从用户级别缓冲区拷贝到文件内核缓冲区中后,在用户层面我们可以认为写入已经完成,因为文件内核缓冲区由操作系统决定何时进行刷新写入真正的文件中
文件内核缓冲区是由操作系统定义的file结构体指向的
疑问:FILE和file有什么关联?
FILE是用户级别缓冲区的管理者,也是属于用户态的结构体。file是文件内核缓冲区的管理者,也是属于内核态的结构体。FILE是基于file的上层封装,FILE依赖file实现底层io具体场景:
当我们使用fopen打开文件时,fopen会调用open系统调用创建文件,然后返回文件的fd,并存储到FILE中,然后使用fwrite对fd文件进行数据写入(先将数据写入用户缓冲区),fwrite调用write系统调用,此时write将用户缓冲区的信息写入文件内核缓冲区

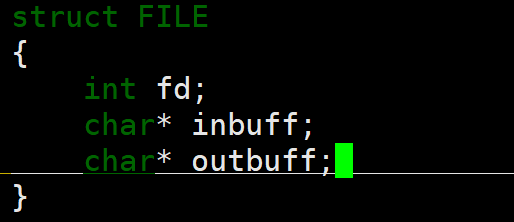
6.mystdio
为了更加理解库函数是如何封装利用底层系统调用实现功能,我们模仿底层代码核心思路,写几个方法
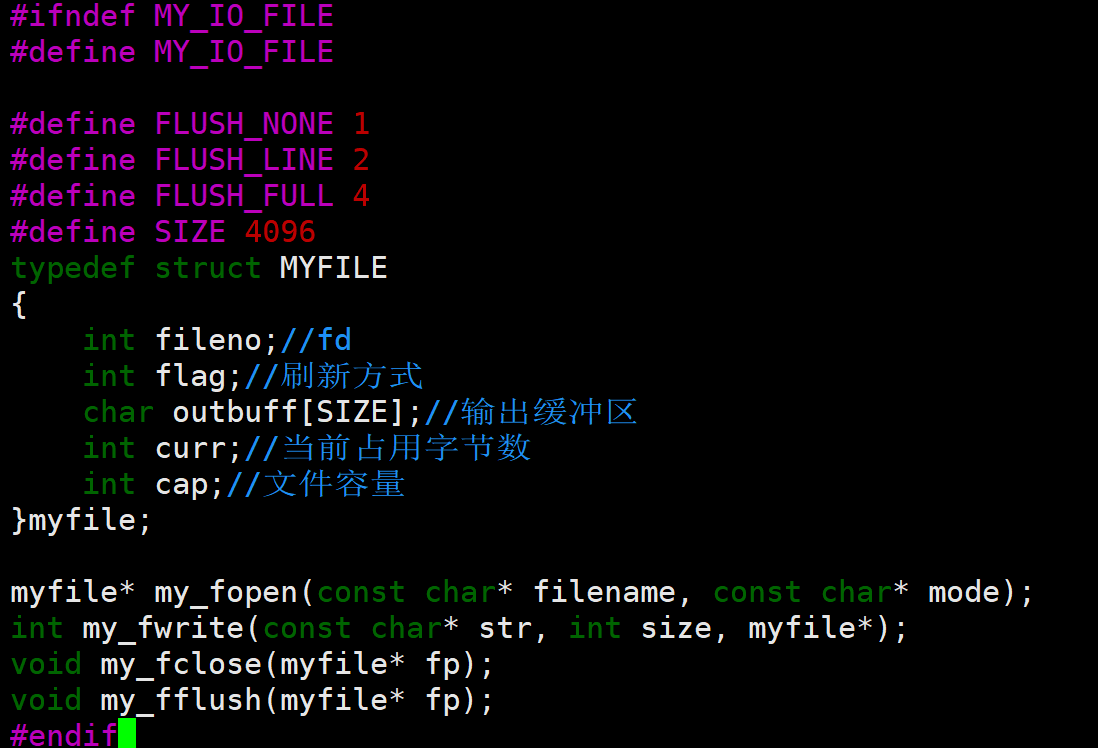
(1)mystdio.h
利用宏定义了不同类型的缓冲区刷新方式,并给myfile结构体设置了和底层有关联的成员变量以及用户级缓冲区,最后声明四个我们将要模拟的方法
(2)mystdio.c
头文件
特别注意要包含mystdio.h的头文件
1.my_fopen函数
myfile* my_fopen(const char* filename, const char* mode) { int fd = -1;//fd初始化 if(strcmp(mode,"r")==0) { fd = open(filename,O_RDONLY,UMASK); } else if(strcmp(mode,"w")==0) {fd = open(filename,O_CREAT | O_WRONLY | O_TRUNC, UMASK);}else if(strcmp(mode,"a")==0){fd = open(filename, O_CREAT | O_APPEND | O_TRUNC, UMASK);}else{//....}//判断底层是否成功if(fd < 0){return NULL;} //封装myfile对象的属性myfile* fp =(myfile*)malloc(sizeof(myfile));if(fp == NULL){return NULL;}fp->fileno = fd;fp->flag = NONE_FLUSH;fp->outbuff[0]=0;//布置\0充当字符串开头,相当于是空串fp->curr = 0;fp->cap = SIZE;return fp;}底层实现逻辑:
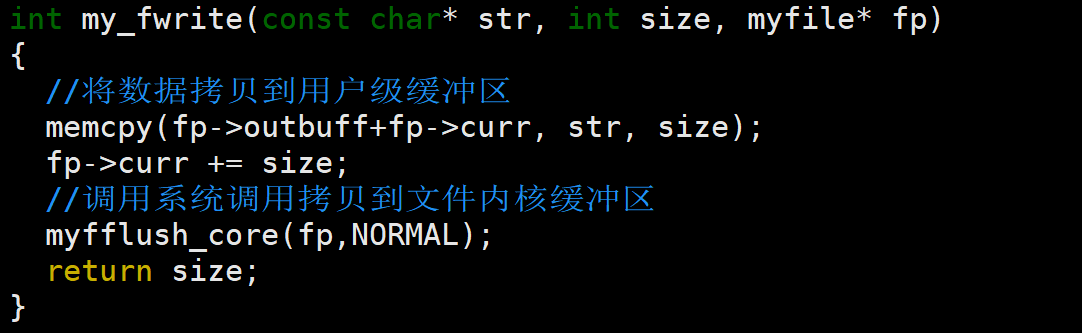
先利用底层的open函数根据给定的打开模式进行文件访问,若打开失败则返回NULL,成功则继续动态开辟myfile结构体对象空间,并返回对应指针,然后将各种信息给到对象的成员变量记录下来,并完成初始化2.my_fwrite
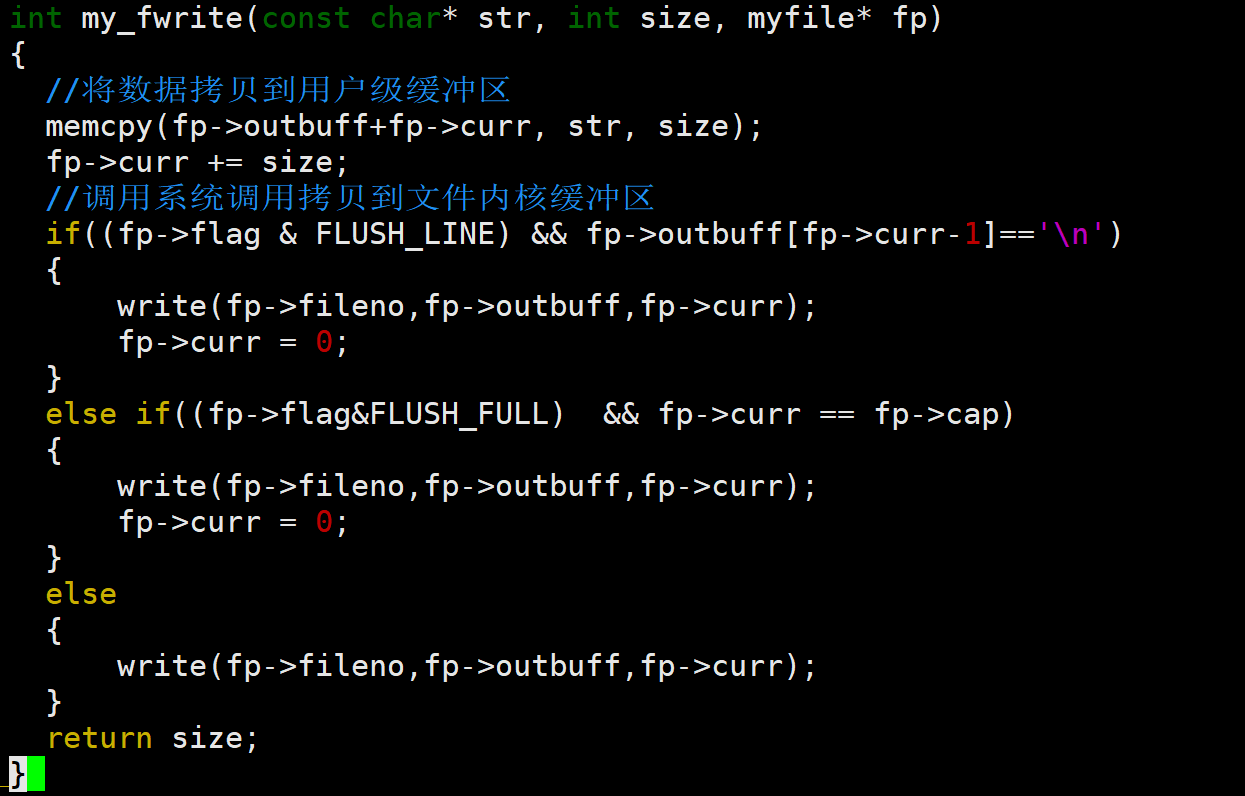
底层实现逻辑:
先将用户输入数据放入myfile的用户级缓冲区中,然后根据文件对应的刷新方式调用write系统调用,将用户级缓冲区的数据刷新到文件内核缓冲区,最后注意将curr重置为0,并返回成功写入的字节数size
3.myfflush_core 与 myfflush
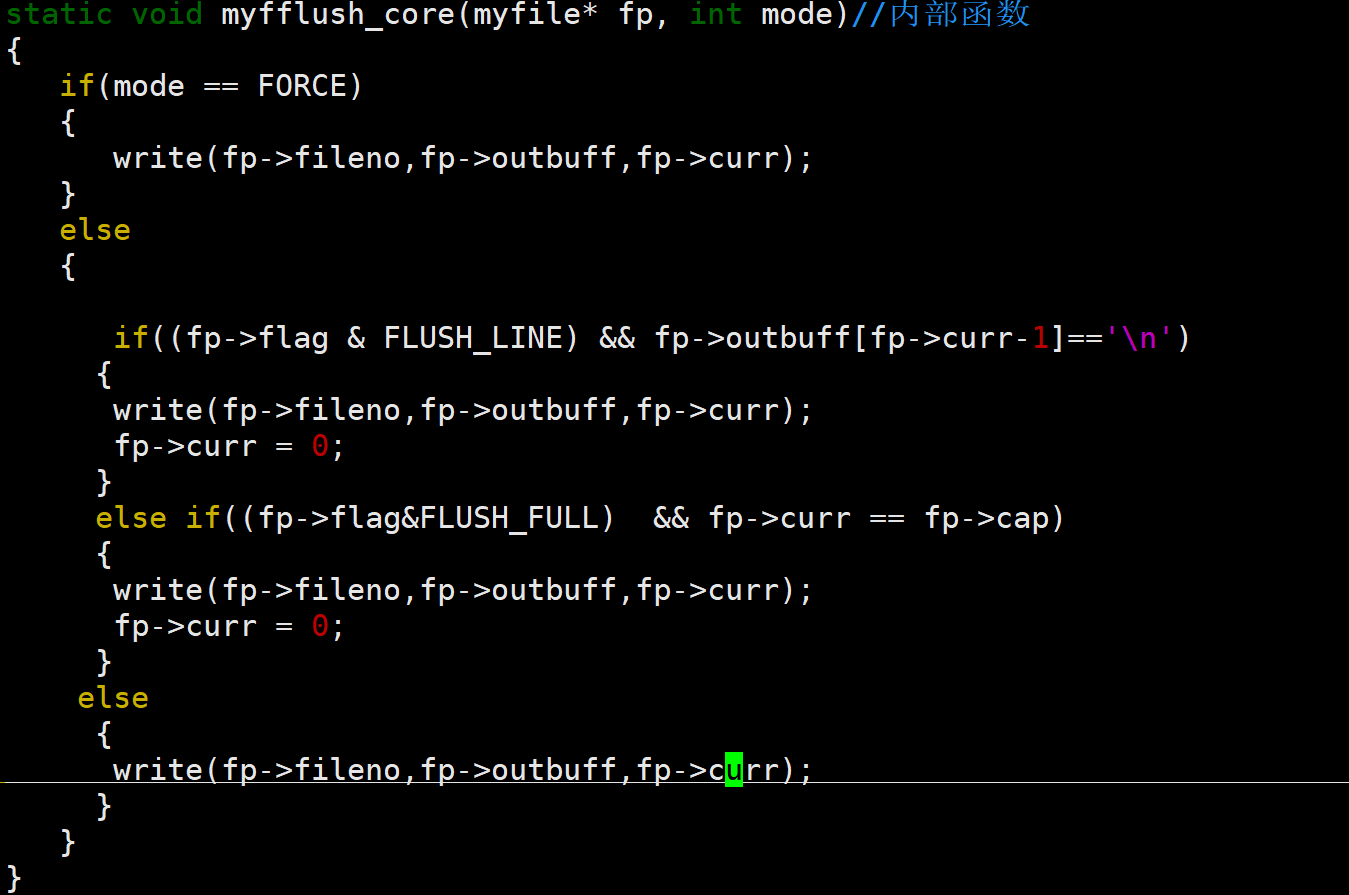
myfflush_core
其实我们刚才在fwrite函数模拟实现的时候已经把刷新功能封装好了,只需要直接cv过来即可。且我们可以给my_fwrite封装使用该内部函数
唯一不同的点在于我们还需区分强制刷新和正常调用刷新
实现方式:增加一个参数并在内部用条件判断语句区分开即可
使用场景:在fwrite内部的就需要判断刷新,用NORMAL模式,直接使用fflush函数的就是强制刷新,使用FORCE模式
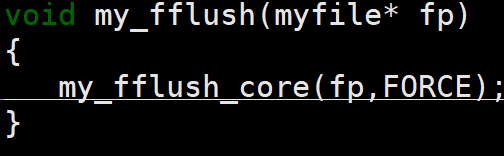
my_fflush
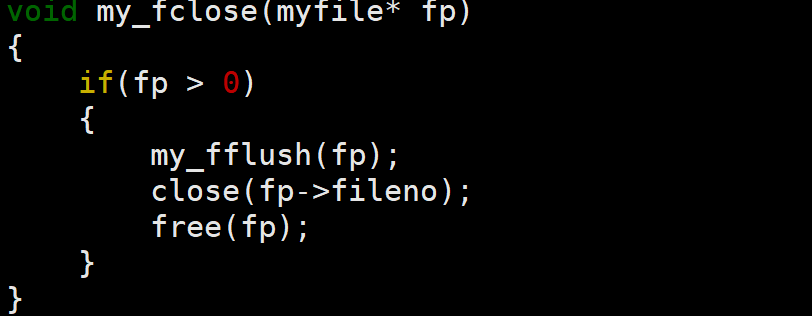
4.my_fclose
在关闭文件前需要冲刷缓冲区,然后再调用close关闭文件,最后由于我们使用了fp指针,而文件已经关闭,该指针已经闲置,直接释放