【JVM】Java为啥能跨平台?JDK/JRE/JVM的关系?
【JVM】Java为啥能跨平台?JDK/JRE/JVM的关系?
- 一、JVM是什么
- 二、Java 的跨平台特性:一次编译,处处运行
- 三、JDK、JRE、JVM:三者的关系
- 1. JVM(Java Virtual Machine)
- 2. JRE(Java Runtime Environment)
- 3. JDK(Java Development Kit)
- 四、JVM运行代码流程
- 1. 第一步:类加载系统
- 2. 第二步:运行时数据区
- 3. 第三步:执行引擎
- 4. 第四步:本地方法接口(JNI)+ 本地方法库
JVM到底是个啥?Java为啥能跨平台、一次编译处处运行?JDK、JRE、JVM三者到底啥关系?JVM又是怎么把我们写的代码跑起来的?
一、JVM是什么
JVM 全称 Java Virtual Machine(Java虚拟机),本质就是 Java程序的运行环境——它不直接和硬件打交道,而是介于Java代码和操作系统之间的“中间层”。
我们写的 .java 源代码,经过编译器(javac)编译后,会变成 .class 文件——这是Java的二进制字节码文件(不是操作系统能直接执行的机器指令)。而JVM的核心作用,就是读取并执行这份 .class 文件,让代码真正跑起来。
二、Java 的跨平台特性:一次编译,处处运行
这是Java最核心的优势之一,而背后的关键,就是JVM的“适配性设计”——不同操作系统有不同版本的JVM,但它们都能运行同一份 .class 文件。
具体逻辑很简单:
- 你写的Java代码,只需要编译一次,就能生成统一格式的
.class字节码文件(不管你是在Windows、Mac还是Linux上编译,生成的.class文件完全一样); - Windows、Mac、Linux等不同操作系统,都会提供对应的JVM版本(比如Windows版JVM、Mac版JVM);
- 当你在某个操作系统上运行Java程序时,对应的JVM会把
.class字节码,“翻译”成该操作系统能直接执行的机器指令; - 操作系统执行这些机器指令,最终完成程序运行。
举个例子:你在Windows上编译好的 .class 文件,复制到Mac上,Mac版JVM会自动把它翻译成Mac系统的指令,无需重新编译——这就是“一次编译,处处运行”的本质。
不过要提一句:Docker出现后,Java的跨平台优势被削弱了(Docker本身就是“容器化跨平台”),但JVM作为Java程序的核心运行环境,依然是不可或缺的。
三、JDK、JRE、JVM:三者的关系
很多人会把这三个概念搞混,其实它们是“包含与被包含”的关系,用一句话就能概括:JDK > JRE > JVM。
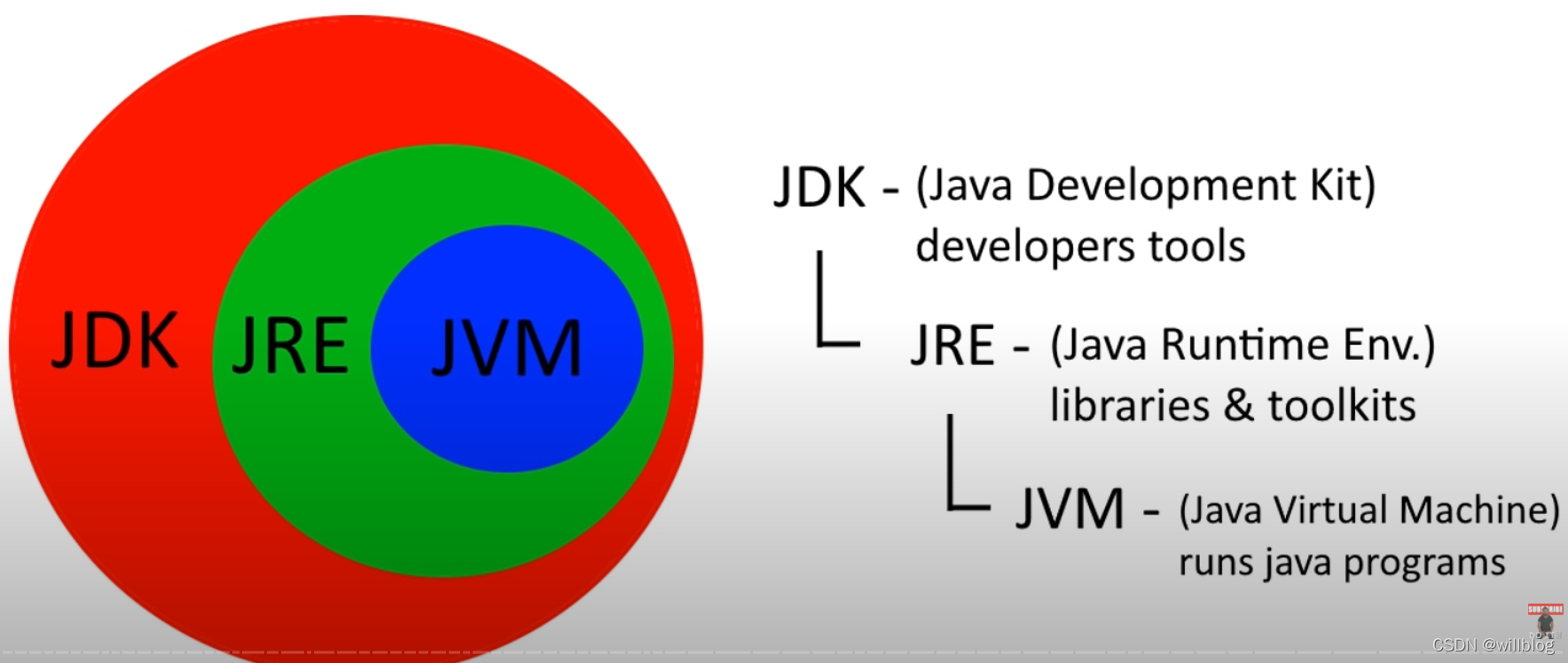
1. JVM(Java Virtual Machine)
就是我们前面说的运行 .class 文件的虚拟机——只负责运行 .class 字节码文件,是Java程序能跑起来的基础。但它光自己不行,还需要依赖类库才能工作。
2. JRE(Java Runtime Environment)
JRE = JVM + Java核心类库(比如 java.lang.String、java.util.ArrayList 这些基础类)。
因为代码执行需要调用很多 Java SE 的类库(比如字符串处理、集合操作),所以 JRE 在 JVM 的基础上自带了这些类库。
3. JDK(Java Development Kit)
但我们不是一上来就写 .class 文件的,我们写的是 .java 文件,而 .java 文件需要编译成 .class 文件。这个编译工作由 JDK 提供的工具完成 ——JDK 其实就是 JRE 加上编译、调试、打包等各种开发工具的集合。
JDK = JRE + 编译、调试、打包等开发工具(比如javac编译器、java运行命令、jar打包工具、jdb调试工具等)。
我们写Java代码时,不是一上来就写 .class 文件的,我们写的是 .java 文件,而 .java 文件需要用 javac 命令编译 .java 文件成 .class 文件,用 jar 命令打包程序——这个编译工作由 JDK 提供的工具完成 ,JDK 其实就是 JRE 加上编译、调试、打包等各种开发工具的集合。
四、JVM运行代码流程
JVM运行 .class 字节码的过程,核心依赖5个核心组件:类加载系统、运行时数据区、执行引擎、本地方法接口(JNI)、本地方法库。整个流程就像“工厂加工产品”,一步步把字节码变成可执行的指令。
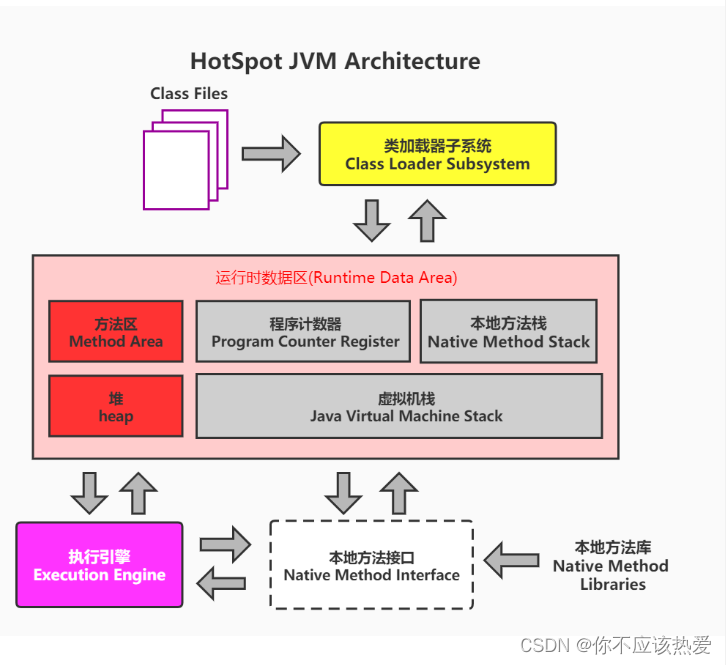
1. 第一步:类加载系统
.class 文件里包含了类的所有信息(类名、父类、接口、字段、方法、访问修饰符等),类加载系统的作用,就是把这些 .class 文件加载到JVM的“内存区域”(运行时数据区)。
2. 第二步:运行时数据区
加载后的类、代码执行时产生的数据(比如对象、变量、方法调用信息),都会存放在这里。它相当于JVM的“工作内存”,主要分为5个部分:
| 内存区域 | 核心作用 |
|---|---|
| 方法区(Method Area) | 存放已加载类的元数据(类名、父类、接口、字段、方法等),比如你定义的 User 类信息就存在这 |
| 堆(Heap) | 存放代码中 new 出来的对象(比如 User user = new User()),是JVM中最大的内存区域 |
| 虚拟机栈(VM Stack) | 存放方法调用的信息(比如调用 main() 方法、add() 方法时,会创建“栈帧”存在这里),方法执行完栈帧就销毁 |
| 程序计数器(Program Counter Register) | 记录当前线程执行到哪一行字节码指令(多线程时,切换线程后能恢复执行位置,避免乱序) |
| 本地方法栈(Native Method Stack) | 存放Java调用的“本地方法”(用C/C++写的方法,比如Java底层的IO操作、线程管理)的调用信息 |
3. 第三步:执行引擎
.class 文件里的字节码,只是JVM能识别的“指令集规范”,不是操作系统能直接执行的机器指令——这时候就需要执行引擎来“翻译”。
执行引擎的核心工作:
- 读取运行时数据区里的字节码指令;
- 把字节码指令“解释”(或编译)成当前操作系统能识别的机器指令;
- 把机器指令交给CPU执行。
这里要提一句:Java不是纯“解释执行”,还会用到JIT(Just-In-Time 即时编译器)——热点代码(频繁执行的代码)会被JIT编译成机器指令缓存起来,下次执行直接用,不用重复解释,这样能提升性能。Java 编译器把 .java 文件编译为字节码文件后,JVM 执行引擎将字节码指令解释为对应操作系统能运行的指令并执行,这也就是为什么说 Java 是编译和解释共存的语言。
4. 第四步:本地方法接口(JNI)+ 本地方法库
Java代码执行时,会遇到一些“Java做不了”的操作(比如操作硬件、底层IO、线程调度),这些操作都是用C/C++写的“本地方法”,存放在本地方法库中。
前文也提到了,本地方法执行时,相关信息会放到运行时数据区的本地方法栈里。