从零开始搭建 flask 博客实验(3)
本文主要聚焦于将数据库整合进 Flask 博客项目中,使用 MySQL + SQLAlchemy + Flask-Migrate 的组合。本文将从“为什么”“如何配置”“模型设计”“数据操作”四个维度,整理并总结这篇教程的核心内容,同时分享几个实践中的小建议。
一、为什么要在博客项目中使用数据库
作为一个完整的博客系统,数据持久化能力是必不可少的:文章、用户、评论、标签、分类……这些都需要存储、检索、修改。作者指出,虽然很多教程使用 SQLite,但他决定用 MySQL 来做演示。 CSDN博客
使用 MySQL 的好处包括:
-
生产环境更常见,对规模、并发、连接数会更有保障;
-
配合 ORM(如 SQLAlchemy)更容易扩展;
-
使用迁移工具(如 Flask‑Migrate)可以方便地管理数据库变更。
所以,如果你的博客有可能演变为一个长期维护、功能增长的项目,从一开始就选好数据库是明智的。
二、环境准备与配置步骤
作者的环境准备流程清晰:
-
安装 Flask SQLAlchemy:
pip install flask-sqlalchemy。 CSDN博客 -
安装 Flask-Migrate:
pip install flask-migrate。 CSDN博客 -
安装 PyMySQL,因为 Python3 不再自带 MySQLdb:
pip install pymysql。
SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://root:123456@localhost:3306/flaskblog?charset=utf8'
SQLALCHEMY_TRACK_MODIFICATIONS = False
``` :contentReference[oaicite:7]{index=7}
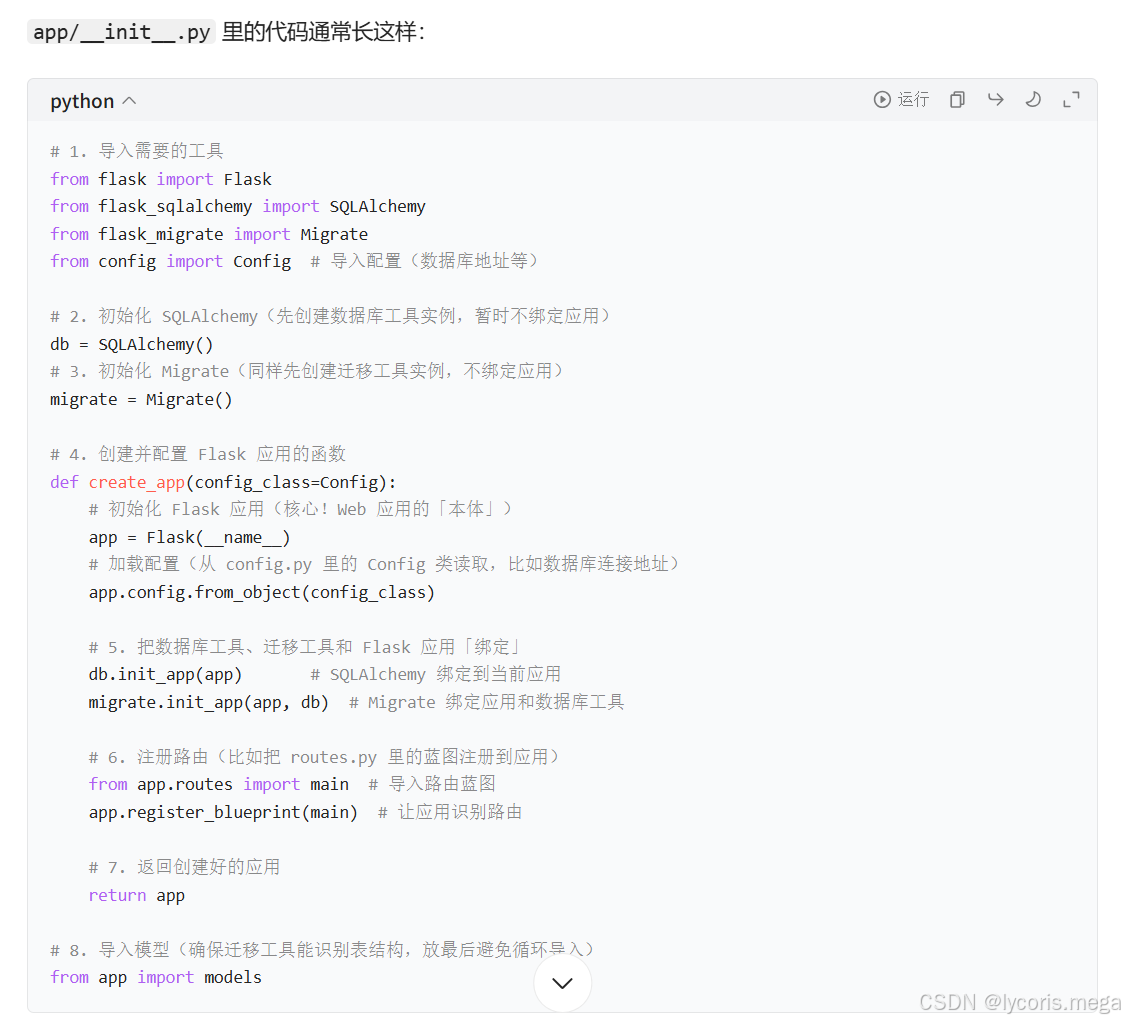
在 app/__init__.py 中初始化 Flask 应用、SQLAlchemy、Migrate:
from flask import Flask
from config import Config
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrateapp = Flask(__name__)
app.config.from_object(Config)
db = SQLAlchemy(app)
migrate = Migrate(app, db)from app import routes, models
``` :contentReference[oaicite:8]{index=8}
在 app/__init__.py 中初始化 Flask 应用、SQLAlchemy 和 Migrate,是 Python Web 开发中非常基础且重要的步骤,它们分别对应「Web 应用核心」「数据库操作工具」「数据库迁移工具」。我们一步步拆解它们的作用和初始化逻辑:
1. 先理解这三个东西到底是啥?
- Flask 应用:Flask 是一个轻量级的 Web 框架,相当于一个「容器」,用来管理你的网页路由(比如访问
/login对应哪个函数处理)、模板渲染、请求响应等核心 Web 功能。没有它,就没有 Web 应用的基础。 - SQLAlchemy:一个「数据库工具包」,它能让你用 Python 代码(而非直接写 SQL)来操作数据库(比如增删改查数据)。比如你想往
user表加一条数据,不用写INSERT INTO user ...,直接用User(name="xxx").save()这种 Python 语法就行,更简单且跨数据库(换 MySQL/PostgreSQL 不用改代码)。 - Migrate(Flask-Migrate):基于 SQLAlchemy 的「数据库迁移工具」。当你后期修改数据库结构(比如给表加个新字段、改字段类型)时,它能帮你自动同步这些变化到数据库,避免手动删表重建(防止数据丢失)。
2. 为什么要在 app/__init__.py 中初始化?
__init__.py 是 Python 包的标识文件,当你用 from app import ... 导入时,会先执行这个文件里的代码。把初始化逻辑放这里,主要是为了:
- 让整个项目的核心组件(Flask 应用、数据库工具)集中管理,方便其他模块(比如路由、模型)导入使用。
- 避免循环导入问题(比如路由文件需要导入 Flask 应用,应用初始化又需要用到路由,放这里能解耦)。
-
三、模型设计与表关系
文章中接着讲了如何在 models.py 中设计数据库模型,也就是 ORM 层。 CSDN博客
关键点包括:
-
模型类继承
db.Model,定义字段、关系、方法。 -
使用 Flask-Migrate 管理迁移:先
db init,再db migrate,最后db upgrade(尽管文章在这一篇里可能没详述,但这是常规流程)。 -
建立“一对多”关系作为博客系统中常见的表关联方式(用户→文章、文章→评论等)。
-
模型设计应考虑可扩展性,例如用户表中可能有头像、简介、注册时间等;文章表可能有标题、正文、发布时间、作者、标签、分类等。
小建议:
-
在博客系统设计中,标签(tags)和分类(category)往往是多对多的关系,建议在设计阶段思考好。
-
给模型添加
__repr__方法对于调试很有帮助。 -
常用字段如
created_at,updated_at可以通过基类统一管理。
四、数据操作与数据库迁移
在模型建好之后,接下来是数据的增删改查操作,以及迁移脚本管理。文章中提到了如何进行这些操作,从模型到数据库的同步。 CSDN博客
迁移工具 Flask-Migrate/Alembic 的使用,使得在开发中修改模型(如新增字段)不再需要手动去数据库操作,而是通过版本化的脚本来处理。作者展示了如何使用这些工具。
小建议:
-
在每次模型修改后,务必先在开发环境运行
db migrate→db upgrade,确认无误后再部署到生产。 -
在生产环境部署之前,建议先备份数据库。
-
对于删除字段或修改字段类型等破坏性更改,要格外小心,可能需要额外迁移步骤或数据迁移脚本。
五、总结与感想
通过第三篇教程,作者将博客项目从“有前端 + 路由”阶段,推进到“有数据库支持”的完整阶段。这是一个重要里程碑:一个真实可用的博客系统离不开数据存储。
我个人的几点收获:
-
从实践来看,尽早决定好数据库方案有利于后续功能扩展。
-
模型设计阶段不要拖延,越早清晰定义结构,对后续开发越有益。
-
使用 migration 工具不仅是好习惯,也几乎是必备。
-
虽然教程以 MySQL 为例,但在开发初期采用 SQLite + 再切换策略也很常见。
如果你正在着手用 Flask 做博客或 Web 应用,这篇文章是值得细读并 “动手跟做” 的。下一篇(教程第四篇)预计会讲更多功能(如用户系统、登录、权限、文章管理等),敬请期待。
--------------------------------------------------------------------------------------------------------------------------------
-----------------疑难解答-------------------
from flask import Flask from config import Config from flask_sqlalchemy import SQLAlchemy from flask_migrate import Migrate app = Flask(__name__) app.config.from_object(Config) db = SQLAlchemy(app) migrate = Migrate(app, db) from app import routes, models 此时 Flask 已经和 MySQL“握手成功”。 还是不理解工作原理,怎么就联上了
我来一步步拆开,讲清楚——为什么写几行 db = SQLAlchemy(app) 和 migrate = Migrate(app, db),Flask 就能“握手成功”。
🧩 一、Flask 是“中间人”
当你创建 Flask 应用:
app = Flask(__name__)
这行代码只是启动了一个“Web 框架容器”,它本身并不知道数据库的存在
接下来:
app.config.from_object(Config)
你往 Flask 的“配置字典”里放了数据库的连接信息,比如:
SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://root:123456@localhost:3306/flaskblog'
Flask 只是保存了这条字符串,它自己不会去连 MySQL。
⚙️ 二、SQLAlchemy 是“数据库翻译器”
当你写:
db = SQLAlchemy(app)
这一刻非常关键,发生了几件事:
-
SQLAlchemy()是 Flask-SQLAlchemy 提供的一个类; -
它会从
app.config里读取上面的SQLALCHEMY_DATABASE_URI; -
它用 SQLAlchemy 的 Engine(引擎)对象 创建数据库连接;
-
这个 Engine 会调用底层驱动
pymysql(就是你安装的那个库),通过 TCP/IP 协议和 MySQL 建立连接; -
一旦连接成功,
db就是一个“ORM 工厂”:-
它能帮你把类 → 表;
-
对象 → 行;
-
属性 → 列。
-
也就是说,db = SQLAlchemy(app) 做了这件事:
🧠 “从 Flask 读取配置 → 创建数据库引擎 → 建立连接 → 注册 ORM 上下文。”
🧱 三、Migrate 是“数据库版本控制器”
migrate = Migrate(app, db)
这一行并不会立即连接数据库。
它只是帮你注册好一个“迁移管理器”,以后当你运行:
flask db init flask db migrate flask db upgrade
这些命令时,Migrate 就能自动找到 app 和 db,知道该连接哪一个数据库,并同步你的模型变更。
🧬 四、当你导入 models 时,ORM 注册模型
from app import routes, models
当 models.py 被导入时,你的模型定义(例如):
class User(db.Model): id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(64))
会自动注册到 SQLAlchemy 的“元数据(metadata)”系统中。
到这一步,数据库引擎 + 模型映射 + 应用上下文都已经在内存中绑定完成。
🧠 五、真正的“握手时刻”
当你第一次执行:
flask db upgrade
或在 shell 中执行:
db.create_all()
这时候,SQLAlchemy 调用底层引擎:
-
读取配置中的数据库地址;
-
调用 PyMySQL 打开 TCP 连接(例如
127.0.0.1:3306); -
发送
CREATE TABLE/INSERT等 SQL; -
MySQL 返回确认。
这就是“握手成功”的那一瞬间。
连接是通过 数据库驱动(PyMySQL) 实际建立的。
🪄 六、一句总结
| 层次 | 职责 |
|---|---|
| Flask | 提供应用上下文和配置 |
| Flask-SQLAlchemy | 读取配置并创建数据库连接 |
| SQLAlchemy | ORM 映射引擎,负责把 Python 类转成 SQL |
| PyMySQL | 真正执行 SQL、连接 MySQL 的驱动 |
| Flask-Migrate | 追踪 ORM 变化并生成迁移脚本 |
所以你看到的那行“看似简单”的代码,其实背后是五层机制的协同。
Flask 自己不会连 MySQL,是 Flask-SQLAlchemy 帮你创建了引擎,并注册进 Flask 的上下文。