李宏毅机器学习笔记40
目录
摘要
1.parameter quantization
2.architecture design
3.dynamic computation
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是network compression的三个方法,分别是parameter quantization,architecture design,dynamic computation。
1.parameter quantization
parameter quantization是用比较少的空间存储参数的,比如高精度表示(如32位浮点数)转换为低精度表示(如8位整数或4位整数),还有一种方法叫做weight clustering,在下面的图示中假设方框内是network的参数,按照参数的数值分群,数值接近就分为一群,每一群只拿一个数字来表示。这样的好处是存储参数只需要记录表格和对应的表即可。
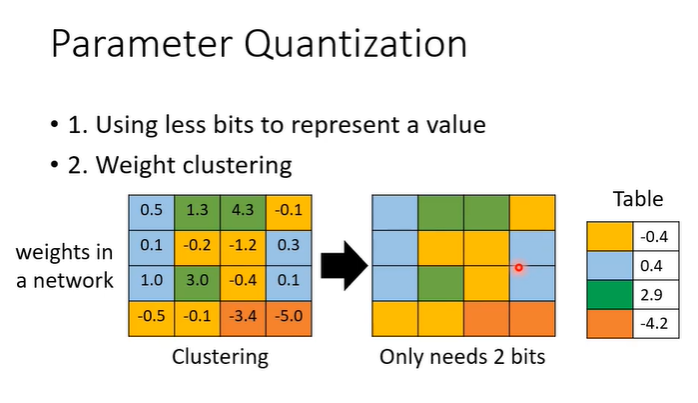
最好的情况是可以压缩到1bit,可以说network的参数只要1和-1,这种叫做binary weight。
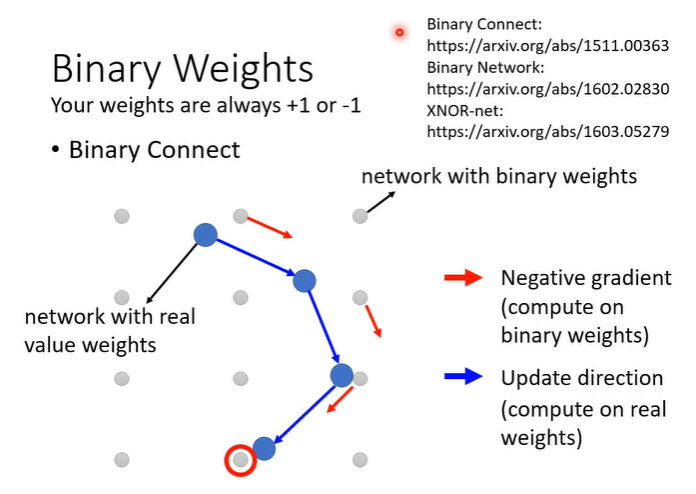
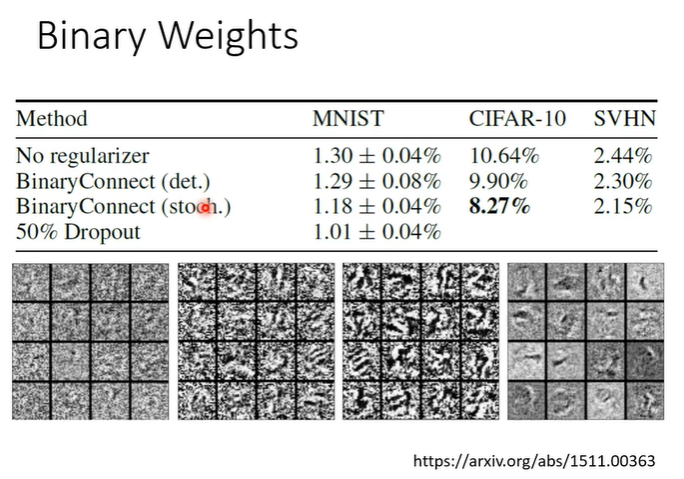
参数是1或-1是否会导致network的效果很差呢?在一个实验中表明并不是这样,实验采用的是binary connect的方法用于做影像辨识,下图的实验结果中,数值为错误率,第一排为正常network,在使用了binary connect后结果更好了,解释是使用binary network时,受到的限制较大,比较不容易overfitting。
2.architecture design
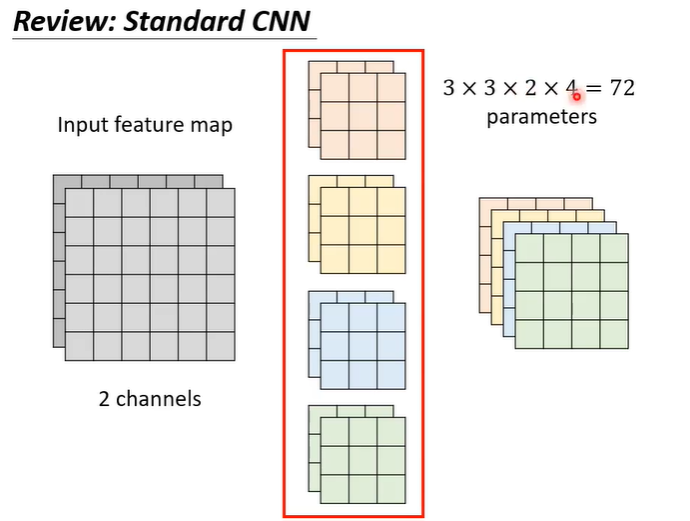
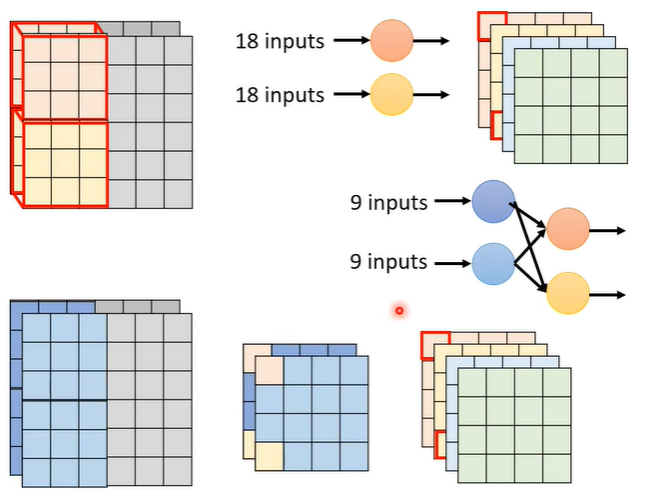
在CNN中,每个layer的input是一个feature map,在下面的例子中,feature map有两个channel,那么每一个filter的高度也是2,用filter扫过feature map后得到另一个matrix。总共有4个filter,每个filter的参数是3x3x2,所以总参数量是72。
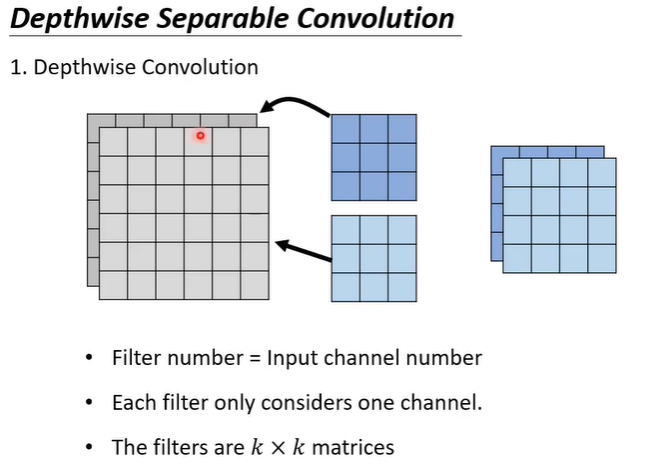
用depthwise separable convolution的方法进行压缩,首先是depthwise convolution,即有几个channel就有几个filter,每个filter只管一个channel。
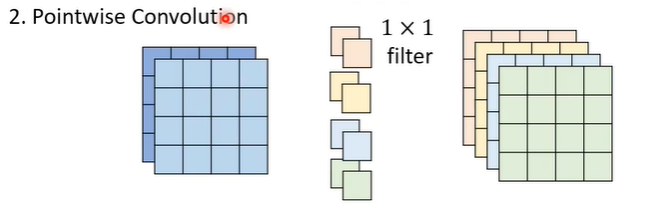
但是这样channel之间无互动,假设有一个pattern是跨channel的才能看出来的,depthwise convolution就无能为力了。所以需要多加一个pointwise convolution,即与一般的convolution layer是一样的,有很多的filter,但是有一个限制是filter的大小是1x1,它的作用就是考虑不同channel之间的关系。
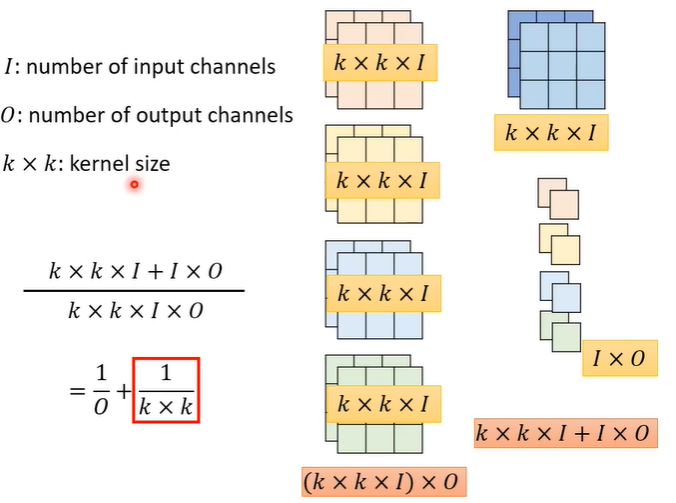
对比一下depthwise separable convolution和普通的CNN参数量,假设输入I个channel,输出O个channel,kernel的大小为k*k。普通的CNN参数量为(k*k*I)*O,depthwise separable convolution中,depthwise convolution的参数量为k*k*I,pointwise convolution的参数量为I*O,相加即为depthwise separable convolution总参数量。相除可得出两种方法的参数比例关系为1/(k*k),通常O较大,故1/O忽略不计。
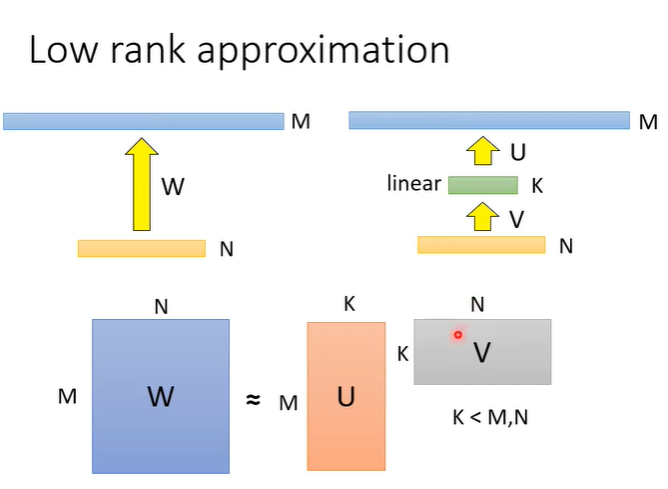
原理如下,假设某个layer输入有N个neural,输出有M个neural,假设M非常大,那么参数量W就会非常可观(W=N*M);如果在N和M之间插一层,这层有K个neural,那么第一层参数量V=N*K,第二层参数量U=K*M,如果K远小于N,M,那么U+V就会比W更小。
再看一般的CNN是18个输入变为一个,拆成depthwise convolution加pointwise convolution后变为两个9个输入的结合变为一个,把一层拆成两层,与上面的原理相对应。
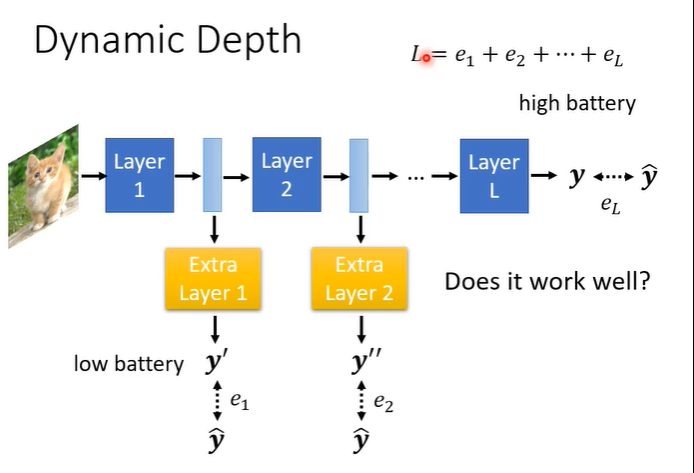
3.dynamic computation
dynamic computation是想要自由的调整运算量,一种方法是自由的调整深度,可以在layer中间插入额外的layer,额外的layer是决定现在的分类结果是什么,在运算资源充足时可以跑过所有的layer,得到最终的结果,当资源不足时,可以让network在哪个layer自行输出。训练方法也很简单,额外layer的输出与正确答案的cross entropy也增加到loss中。
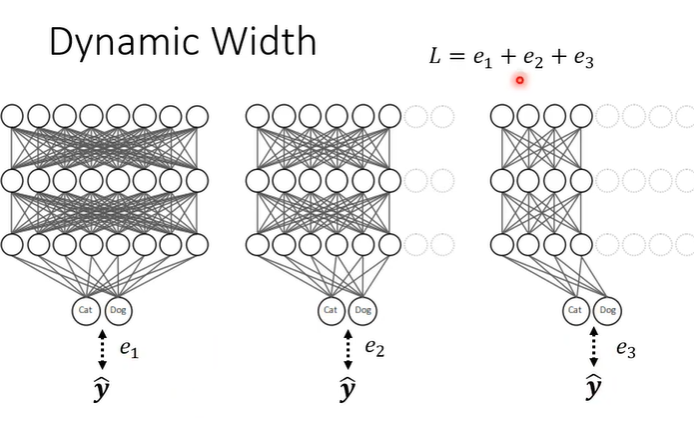
也可以让network自由决定宽度,设定好不同的宽度,训练方法同上,每个network的输出与正确答案越接近越好。