音画同步革命:IndexTTS2深度解析——B站开源的情感化+时长可控TTS新标杆
在视频配音、虚拟主播、影视后期等核心场景中,音画不同步和情感表达生硬一直是 TTS 技术的两大痛点。传统自回归 TTS 模型虽能生成连贯语音,却难以精准控制时长,导致配音与画面节奏错位;而情感与音色的强绑定,又让个性化语音生成陷入千人一声的困境。由哔哩哔哩 IndexTTS 团队开源的 IndexTTS2,以情感表达 + 时长可控双核心突破,重新定义了零样本 TTS 的工业级标准。本文将从技术原理、核心特性、快速上手到落地场景,全面拆解这款专为音画协同设计的 TTS 利器。
一、技术突破:解构 IndexTTS2 的核心创新
IndexTTS2 之所以能实现时长精准控 + 情感高保真,源于其对自回归 TTS 架构的深度重构 —— 通过三大核心技术,解决了传统模型的结构性缺陷。
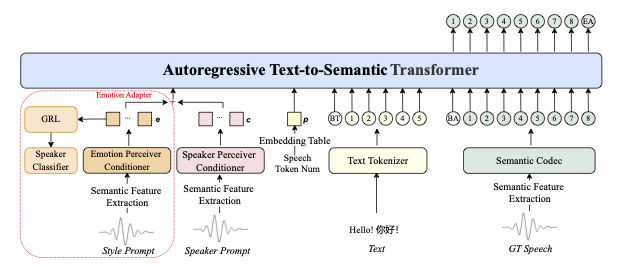
时长可控的底层逻辑:时间编码机制
传统自回归 TTS 的逐 token 生成模式,天然缺乏时间维度约束,导致时长不可控。IndexTTS2 创新性地引入时间编码向量,给每个语音生成单元打上时间戳,从根源上实现毫秒级时长控制:
-
反向计算机制:根据用户指定的目标时长或时长比例(0.75x-1.25x),自动换算所需生成的 token 数量;
-
动态节奏调整:通过时间编码调控每个 token 的发音时长,避免强行拉长 / 压缩导致的语音失真;
-
实测精度:在 SeedTTS 测试集上,时长误差率低于 0.07%,10 秒目标时长的生成结果偏差不超过 7 毫秒,完美匹配演员口型与画面节奏。
情感与音色的解耦魔法
IndexTTS2 通过双特征分离 + 软指令控制,实现情感与音色的独立调控,打破了传统模型的绑定限制:
-
特征解耦架构:将说话人音色特征(来自参考音频)与情感基调特征(来自文本描述或参考音频)进行隐式分离,支持同一音色 + 不同情感/同一情感 + 不同音色的自由组合;
-
Qwen3 驱动的软指令机制:无需复杂参数配置,通过自然语言描述即可控制情感(如温柔亲切,激昂有力,悲伤舒缓),降低非技术用户使用门槛;
-
情感保真度:在专属情感测试集上,情感相似度(ES)达 0.887,情感 MOS 评分 4.22±0.12,显著超越 MaskGCT、F5-TTS 等主流模型。
三阶段训练范式:稳定性与表现力双提升
为兼顾生成质量与稳定性,IndexTTS2 采用创新的三阶段训练流程:
-
预训练阶段:基于 55K 双语数据构建基础语音生成能力,涵盖 135 小时情感语料;
-
融合微调阶段:引入 GPT 潜在表示,增强文本语义理解与语音清晰度,使词错误率(WER)低至 1.136%;
-
解耦优化阶段:针对情感与音色特征进行专项训练,提升零样本场景下的特征迁移能力。
二、核心特性:重新定义零样本 TTS 的使用体验
IndexTTS2 的特性围绕精准控制、高表现力、低门槛使用三大维度设计,完美适配工业级应用需求。
双生成模式:精准控时与自然韵律自由切换
-
可控模式:支持通过指定 token 数量或时长比例(0.75x-1.25x)精确控制语音时长,适配影视配音、课程讲解等对节奏要求严苛的场景。例如:为 10 秒动画台词配音时,选择 1.0x 模式可精准生成 10±0.07 秒语音,完全匹配演员口型;
-
自由模式:无需手动设定时长,自动复刻参考音频的韵律特征(停顿、重音、语速变化),适合演讲、播客等追求自然表达的场景。
零样本能力:低资源下的高保真生成
-
音色克隆:仅需短参考音频(5 秒以上),即可精准复刻说话人的音色、口音甚至微语气,说话人相似度(SS)在 LibriSpeech 测试集上达 0.887;
-
跨语言支持:原生支持中英文双语生成,中文自然度与英文发音准确性均处于行业领先水平;
-
低资源适配:对参考音频质量要求宽松,轻微背景噪声可通过内置预处理模块优化。
工业化部署友好:高性能与高兼容并存
-
多平台支持:兼容 Windows、macOS、Linux 系统,支持 CPU/GPU(CUDA)运行,GPU 显存要求≥16GB(推荐 24GB 以上);
-
加速方案:支持 FP16 推理、DeepSpeed 分布式加速,推理效率满足批量生产需求;
-
灵活集成:提供 Python API、WebUI、命令行三种使用方式,支持与视频编辑工具、虚拟主播平台无缝对接。
三、快速上手:3 分钟启动情感化 + 时长可控语音生成
IndexTTS2 采用 uv 包管理器简化依赖配置,支持国内镜像加速,新手可快速搭建开发环境。
环境准备(支持 Windows/macOS/Linux)
安装依赖工具
# 安装git、git-lfs(用于拉取大文件)
# Windows:通过官网下载安装;macOS:brew install git git-lfs;Linux:apt install git git-lfs# 安装uv包管理器(推荐方式)
curl -LsSf https://astral.sh/uv/install.sh | sh# 或通过pip安装
pip install uv --upgrade
克隆仓库并拉取资源
# 克隆仓库
git clone https://github.com/index-tts/index-tts.git && cd index-tts# 初始化git-lfs并拉取大文件
git lfs installgit lfs pull
安装项目依赖
# 安装全部功能(含WebUI、DeepSpeed等)
uv sync --all-extras --default-index "https://mirrors.aliyun.com/pypi/simple"
模型下载(二选一,国内推荐 ModelScope)
HuggingFace 下载
# 安装huggingface-hub工具
uv tool install "huggingface-hub[cli,hf_xet]"# 下载模型到checkpoints目录
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
ModelScope 下载
# 安装modelscope工具
uv tool install "modelscope"# 下载模型(自动适配国内网络)
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
启动 WebUI
# 基础启动(默认端口7860)
uv run webui.py# 高级启动(FP16推理+DeepSpeed加速)
uv run webui.py --fp16 --deepspeed# 查看所有可选参数
uv run webui.py -h
启动后访问 http://127.0.0.1:7860,即可通过可视化界面实现:
-
文本→语音生成(支持时长比例调节:0.75x-1.25x);
-
零样本语音克隆(上传参考音频 + 输入文本);
-
情感控制(选择预设情感或输入文本描述);
-
音频导出(支持 WAV/MP3 格式)。
核心 API 调用示例(Python)
from indextts.infer_v2 import IndexTTS2# 初始化模型
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)# 1. 使用单个参考音频文件合成新语音(声音克隆):
text = "Translate for me, what is a surprise!"
tts.infer(spk_audio_prompt='examples/voice_01.wav', text=text, output_path="gen.wav", verbose=True)# 2. 使用一个单独的、带有情感的参考音频文件来调节语音合成:
text = "酒楼丧尽天良,开始借机竞拍房间,哎,一群蠢货。"
tts.infer(spk_audio_prompt='examples/voice_07.wav', text=text, output_path="gen.wav", emo_audio_prompt="examples/emo_sad.wav", verbose=True)# 3. 当指定了情感参考音频文件时,你可以选择性地设置 emo_alpha 来调整它对输出的影响程度。有效范围是 0.0 - 1.0</b1,默认值为 1.0</b2(100%):
text = "酒楼丧尽天良,开始借机竞拍房间,哎,一群蠢货。"
tts.infer(spk_audio_prompt='examples/voice_07.wav', text=text, output_path="gen.wav", emo_audio_prompt="examples/emo_sad.wav", emo_alpha=0.9, verbose=True)# 4. 也可以省略情感参考音频,而是提供一个包含 8 个浮点数的列表,用于指定每种情感的强度,顺序如下:[happy, angry, sad, afraid, disgusted, melancholic, surprised, calm]。此外,你可以使用use_random参数在推理过程中引入随机性;默认值为False,将其设置为True即可启用随机性:
text = "哇塞!这个爆率也太高了!欧皇附体了!"
tts.infer(spk_audio_prompt='examples/voice_10.wav', text=text, output_path="gen.wav", emo_vector=[0, 0, 0, 0, 0, 0, 0.45, 0], use_random=False, verbose=True)# 5. 启用use_emo_text,根据你提供的text脚本引导情感。你的文本脚本随后会自动转换为情感向量。在使用文本情感模式时,建议将emo_alpha设置为 0.6 左右(或更低),以获得更自然的语音效果。你可以通过use_random引入随机性(默认值:False;True启用随机性):
text = "快躲起来!是他要来了!他要来抓我们了!"
tts.infer(spk_audio_prompt='examples/voice_12.wav', text=text, output_path="gen.wav", emo_alpha=0.6, use_emo_text=True, use_random=False, verbose=True)# 6. 可以通过emo_text参数直接提供特定的文本情感描述。你的情感文本会自动转换为情感向量。这让你可以分别控制文本脚本和文本情感描述:
text = "快躲起来!是他要来了!他要来抓我们了!"
emo_text = "你吓死我了!你是鬼吗?"
tts.infer(spk_audio_prompt='examples/voice_12.wav', text=text, output_path="gen.wav", emo_alpha=0.6, use_emo_text=True, emo_text=emo_text, use_random=False, verbose=True)
四、主流零样本 TTS 模型对比
IndexTTS2 在四大权威测试集(SeedTTS-zh/en、LibriSpeech、AIShell-1)中,核心指标全面领先同类模型:
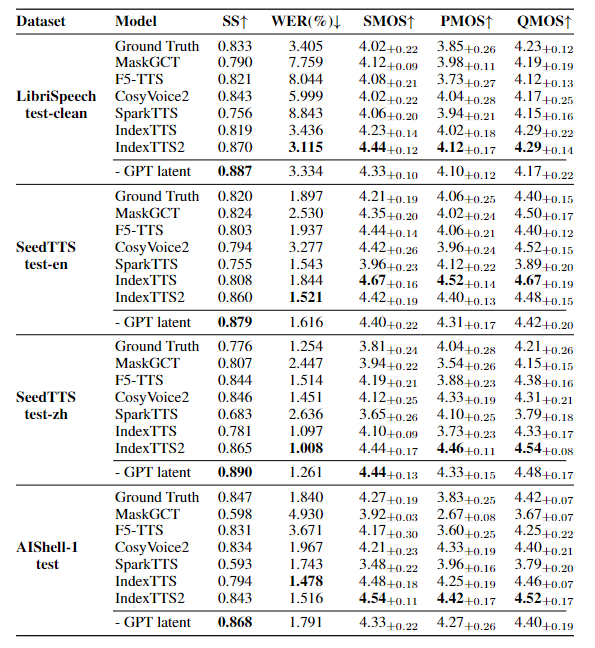
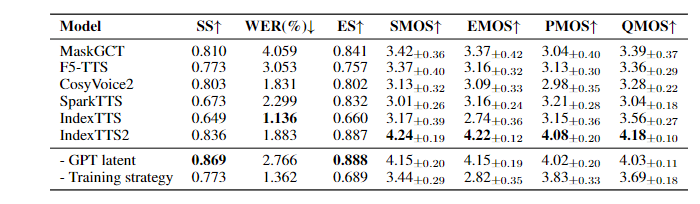
关键结论:
-
时长控制:IndexTTS2 是唯一实现 0.75x-1.25 倍速精准控制的自回归模型,误差率可忽略;
-
情感表达:EMOS 评分 4.22,显著优于其他模型,情感区分度清晰;
-
语音准确性:WER 仅 1.883%,中文多音字、英文连读处理精准。
六、版本迭代与生态资源
版本对比(选择指南)
| 版本 | 核心升级点 | 适用场景 |
|---|---|---|
| IndexTTS2 | 时长控制、情感解耦、Qwen3 增强 | 视频配音、虚拟主播 |
| IndexTTS-1.5 | 基础情感生成、零样本克隆 | 简单语音合成场景 |
| IndexTTS-1.0 | 初代零样本 TTS 架构 | 研究对比、入门学习 |
官方资源(快速直达)
-
代码仓库:GitHub
-
模型下载:HuggingFace / ModelScope
-
在线演示:https://index-tts.github.io/index-tts2.github.io/
-
视频教程:IndexTTS2
-
技术报告:掘金深度解析
-
Discord:IndexTTS Community
-
邮箱:indextts@bilibili.com
七、合规使用与风险提示
IndexTTS2 基于 Apache License 2.0 开源协议,允许商业使用,但需遵守以下规范:
-
禁止用于伪造他人语音进行诈骗、诽谤等违法活动;
-
语音克隆功能仅可用于已获得明确授权的场景,尊重声纹信息隐私;
-
商业应用中需为 AI 生成语音添加可识别标识(如水印、片头提示),避免误导用户;
-
目前主要优化中英文场景,其他语言性能未做保证,长文本生成可能不稳定。
八、总结:IndexTTS2 的行业价值与应用前景
IndexTTS2 的开源,不仅解决了工业级 TTS 的音画同步核心痛点,更通过情感与音色的解耦设计,降低了个性化语音生成的门槛。其典型应用场景包括:
-
视频配音:影视后期、短视频口播、动画解说(精准匹配画面节奏);
-
虚拟主播:直播互动、游戏角色配音(支持多情感切换);
-
智能硬件:智能音箱、车载导航(时长可控,适配交互场景);
-
内容创作:有声书、课程讲解(自由模式还原真人韵律)。
随着 B 站 IndexTTS 团队的持续迭代,未来模型在多语言支持、长文本稳定性、情感精细化控制等方面将进一步升级。对于开发者而言,IndexTTS2 的低门槛部署、灵活集成能力和商业友好的开源协议,使其成为从原型验证到工业落地的首选 TTS 方案。