全面认识 InnoDB:从架构到 Buffer Pool 深入解析
1. 前言:为什么了解 InnoDB 很重要
在使用 MySQL 的过程中,InnoDB 是我们最常接触、也是最核心的存储引擎。它不仅仅决定了数据如何被保存到磁盘上,更影响着数据库的事务一致性、并发性能以及系统的稳定性。想要深入理解 MySQL 的性能调优、事务隔离或锁竞争等问题,离不开对 InnoDB 的透彻认识。
与早期的 MyISAM 等存储引擎相比,InnoDB 最大的优势在于它支持事务(Transaction),并通过 行级锁(Row-level Locking) 实现了更高的并发性能。
更重要的是,InnoDB 在锁管理上采用了细粒度锁机制,包括行锁与**间隙锁(Gap Lock)**的组合,这种设计使它能够在高并发环境下既保持数据一致性,又最大限度地减少锁冲突。
InnoDB 的核心思想是将数据分为两个世界:
内存中的结构(In-Memory Structures):用于高速访问和缓存。
磁盘上的结构(On-Disk Structures):持久化存储数据和日志。
两者通过操作系统缓存(Operating System Cache)进行交互,实现高性能与高可靠性的平衡。
正因为如此,InnoDB 已成为 MySQL 的默认存储引擎,也是企业级数据库系统的首选方案。
理解 InnoDB 的架构与原理,不仅能帮助我们更高效地使用 MySQL,更能在出现性能瓶颈或数据一致性问题时,快速定位并解决问题。
2. InnoDB 架构全景
下图MySQL8.0官方架构图(MySQL8.0官方参考手册地址:https://dev.mysql.com/doc/refman/8.0/en)
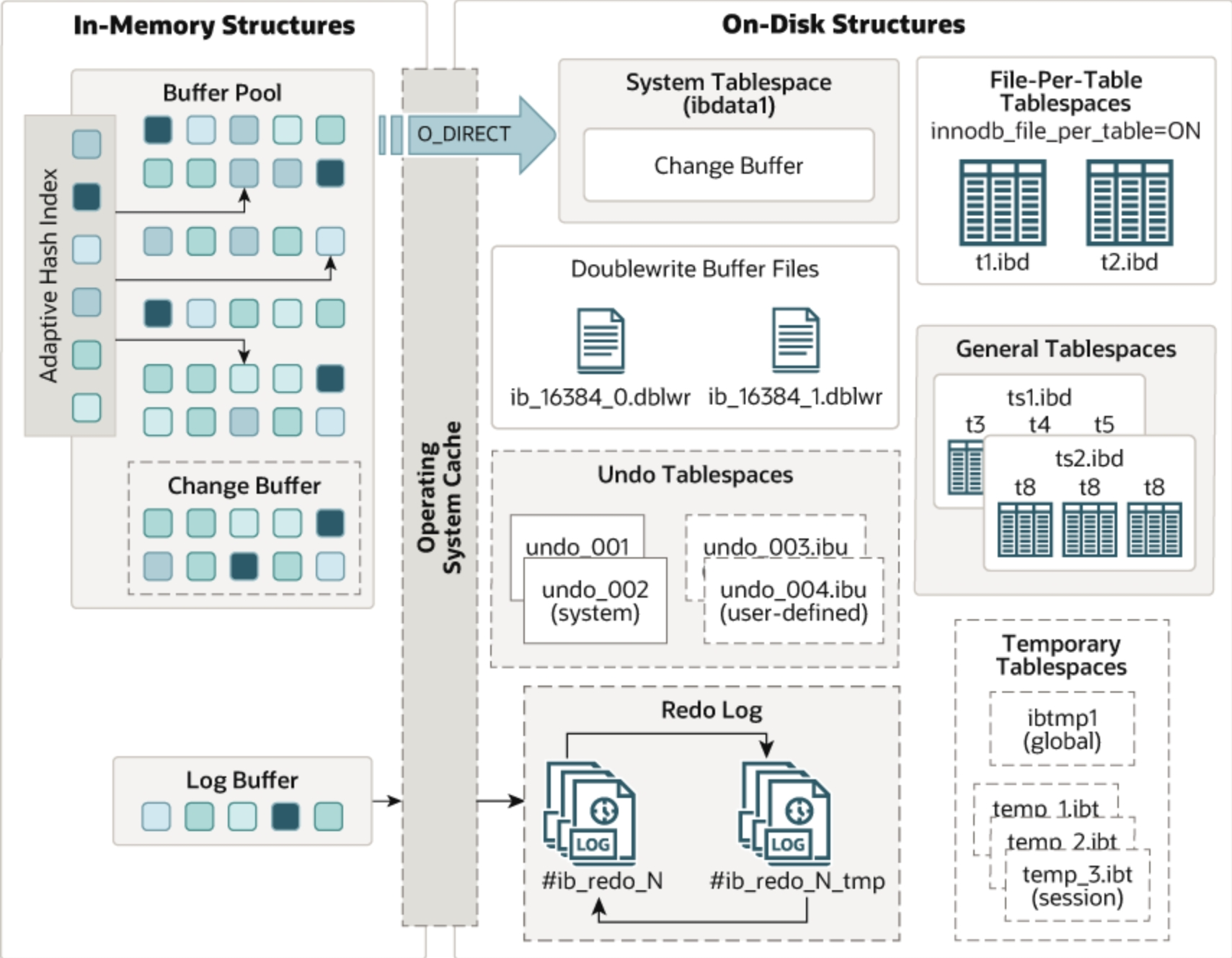
2.1 InnoDB存储引擎的工作流程
InnoDB 的内部结构看似复杂,但可以概括为三大模块:内存层(Buffer Pool 等)、日志层(Redo/Undo Log) 与 存储层(Tablespace 文件)。下面从宏观到细节说明它们如何协同工作。
我们把整个 InnoDB 看作一个“智能图书馆系统”,它既要快速借阅书籍(查询),又要保证书不会丢失(持久性),还要支持多人同时阅读、修改(并发控制)。
1️⃣ 📚 图书馆的“阅览室”——Buffer Pool(缓冲池)
- 想象一下,图书馆里有一个巨大的阅览室,里面摆满了电子屏,每个屏幕显示一本书的内容。
- 当有人想看某本书时,图书管理员先查一下阅览室有没有这本书。如果有,就直接在屏幕上展示(命中缓存);如果没有,就去仓库拿书,放到阅览室里(从磁盘加载到内存)。
- 这个“阅览室”就是 Buffer Pool,它是 InnoDB 最重要的内存结构,用来缓存数据页(data pages)和索引页。
✅ 作用:
- 减少磁盘 I/O,提升读写性能。
- 支持多用户并发访问。
🔹 Adaptive Hash Index(自适应哈希索引)
- 类似于图书馆里的“快速检索卡”。当你知道书名或作者,可以直接跳到对应的屏幕。
- 是 InnoDB 自动为频繁访问的索引键构建的哈希表,加速查找。
2️⃣ ✍️ 修改前的“草稿本”——Change Buffer(变更缓冲)
- 假设你在图书馆里要修改一本很重的书,但不能立刻搬走整本书去改。
- 所以你先在一张纸上写下你要改的内容(比如:“第5页,把‘苹果’改成‘香蕉’”),这张纸就是 Change Buffer。
- 等到没人用这本书了,或者系统空闲时,再把这张纸上的修改应用到原书上。
✅ 作用:
- 优化对非唯一索引的插入、更新、删除操作(尤其是随机写入)。
- 避免频繁磁盘写入,提高写性能。
📌 只有当页面被读取进 Buffer Pool 后,才会触发 Change Buffer 的合并(merge)。
3️⃣ 🧾 日志记录员——Log Buffer 和 Redo Log
📝 Log Buffer(日志缓冲区)
- 就像你写日记前先把想法记在便签上。
- 所有对数据库的修改(INSERT/UPDATE/DELETE)都会先写入这个“便签”区域。
📄 Redo Log(重做日志)
- 就像你把每天的日记本放在保险柜里,即使电脑崩溃也能恢复。
- 当事务提交时,InnoDB 会先把日志写入 Redo Log 文件(如 #ib_redo_N),然后才慢慢把数据刷到磁盘。
- 使用WAL(Write-Ahead Logging) 原则:先写日志,再写数据。
✅ 优点:
- 即使宕机,也能通过 Redo Log 恢复未写入磁盘的数据。
- 提升写入性能,因为日志是顺序写入的,比随机写数据快得多。
4️⃣ 💾 数据库的“硬盘仓库”——On-Disk Structures
🗄️ System Tablespace(系统表空间)
- 类似于图书馆的“总务办公室”,存放系统元数据(如表结构、全局信息)。
- 默认文件是 ibdata1。
- 包含 Change Buffer 的磁盘部分(当 Change Buffer 刷盘时)。
📁 File-Per-Table Tablespaces(每表独立表空间)
如果启用了 innodb_file_per_table=ON,每个表都有自己的 .ibd 文件(如 t1.ibd, t2.ibd)。
就像每个学生有自己的笔记本,互不干扰。
🧩 General Tablespaces(通用表空间)
多个表可以共享一个表空间(如 ts1.ibd),适合管理大量小表。
类似于“共享教室”,多个班级共用一个教室。
⏳ Undo Tablespaces(撤销表空间)
记录事务执行前的状态,用于:
- 回滚(Rollback)
- MVCC(多版本并发控制)
比如你修改了一行数据,Undo 表空间会保存旧值,让其他事务看到“历史版本”。
🛠️ Doublewrite Buffer Files(双写缓冲)
- 为了防止写入过程中断电导致数据页损坏,InnoDB 先把数据写入一个“双写缓冲区”(ib_*.dblwr),然后再写入实际表空间。
就像复印一份文件后才撕掉原件,防止出错。
🧺 Temporary Tablespaces(临时表空间)
- 用于临时表或中间结果集(如排序、JOIN)。
- 分为全局(ibtmp1)和会话级(temp_*.ibt)。
| 模块 | 类型 | 主要作用 |
|---|---|---|
| Buffer Pool | 内存结构 | 缓存数据页与索引页,减少磁盘 IO |
| Change Buffer | 内存+磁盘 | 缓存二级索引的修改操作 |
| Log Buffer | 内存 | 缓存 redo log,提升写性能 |
| Redo Log | 磁盘 | 保证事务持久性 |
| Undo Tablespace | 磁盘 | 保存旧版本,用于回滚与 MVCC |
| Doublewrite Buffer | 磁盘 | 防止页损坏,保障写入安全 |
2.2 InnoDB 增删改查流程
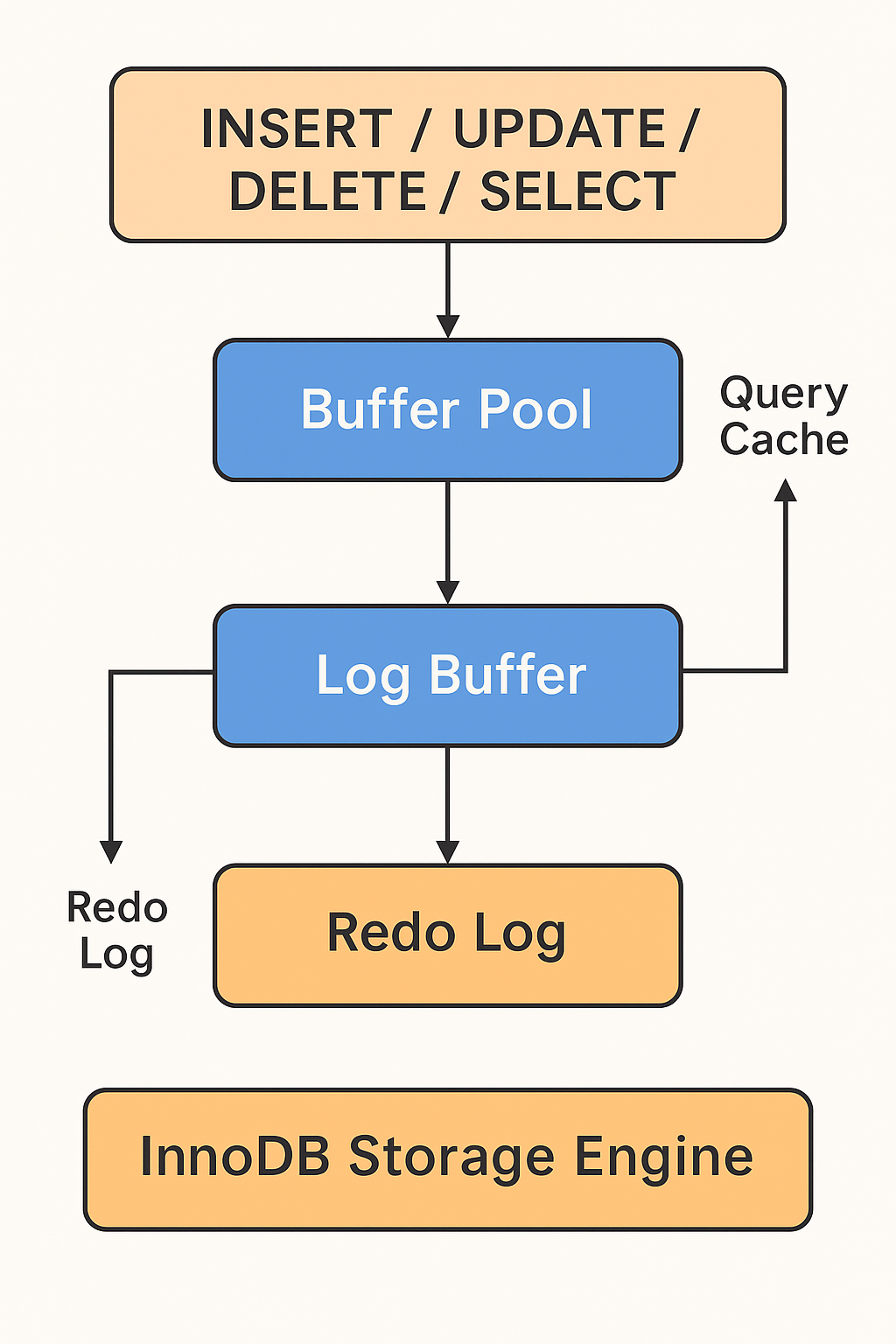
图文解释:
① SQL 请求阶段
用户通过 SQL 层发出 INSERT、UPDATE、DELETE 或 SELECT 请求。
MySQL 负责解析、优化、生成执行计划后,将具体的数据操作交由 InnoDB 存储引擎 处理。
② Buffer Pool —— 数据操作的核心缓冲区
InnoDB 首先会在 Buffer Pool(缓冲池) 中查找所需的数据页:
- 若命中缓存,直接在内存中完成数据读取或修改;
- 若未命中,则从磁盘加载相应页进入 Buffer Pool。
当执行写操作(插入、更新、删除)时,数据会先修改缓冲池中的页,并被标记为“脏页(Dirty Page)”,等待异步刷新到磁盘。
③ Log Buffer —— 日志的暂存区
同时,事务的修改操作会生成 Redo Log 记录,并先写入 Log Buffer(日志缓冲区),周期性地刷新到磁盘上的 redo log 文件。
这一步是 InnoDB 实现 事务持久性(Durability) 的关键:即使系统宕机,也能通过日志恢复未落盘的数据。
④ Redo Log —— 保证持久性的守护者
Redo Log(重做日志) 记录了“页被修改的物理操作”,它与事务提交的顺序强相关。
在崩溃恢复时,InnoDB 会根据 redo log 重放数据,确保所有提交事务的数据都能恢复。
⑤ 磁盘存储层 —— 持久化落盘
最终,后台线程(如 flush 线程)会周期性地将脏页从 Buffer Pool 写回到磁盘表空间(Tablespace)。
这一阶段的数据写入受到 checkpoint 策略 控制,以平衡性能与安全。
🔁 ⑥ 查询缓存(Query Cache)
注:MySQL 8.0 之后已完全移除 Query Cache,该功能仅适用于 MySQL 5.x 系列。
对于 SELECT 查询,如果结果已被缓存,则可直接命中 Query Cache(MySQL 8.0 已默认移除该功能,但在老版本中常见)。
2.3 后台线程:默默支撑性能的“守夜人”
InnoDB 背后运行着多个后台线程,负责维持系统的稳定与高效运行:
- IO 线程(Read/Write):异步处理磁盘读写请求;
- Purge 线程:清理过期的 undo 日志;
- Flush 线程:周期性地将脏页写回磁盘;
- Checkpoint 线程:控制日志与数据页的一致性,确保系统可恢复。
这些线程的存在,让 InnoDB 在面对大量并发事务时依然能够有条不紊地运行。
3. Buffer Pool:性能的心脏
在 InnoDB 的整体架构中,Buffer Pool(缓冲池) 是最关键的内存组件,它几乎决定了数据库的整体性能。
你可以把它理解为 InnoDB 的“高速缓存”,所有的读写操作都要经过它。
3.1 Buffer Pool 的作用
数据库的瓶颈通常在于 磁盘 IO。
为了避免频繁访问磁盘,InnoDB 设计了 Buffer Pool 来缓存数据页和索引页。
- 当执行 SELECT 时,若命中缓冲池,数据直接从内存中返回;
- 当执行 INSERT、UPDATE、DELETE 时,数据先被修改到缓冲池中,并标记为“脏页(Dirty Page)”;
- 后台线程会定期将脏页刷新回磁盘,从而平衡性能与持久性。
这种机制让 InnoDB 绝大多数请求都能在内存中完成,从而大幅提升吞吐量。
✅ 一句话总结:
Buffer Pool 是 InnoDB 的性能核心,命中率越高,数据库就越快。
3.2 Buffer Pool 的内部结构
在 InnoDB 的实现中,缓冲池不仅仅是一个内存区域,而是通过多个链表结构来管理页的生命周期。
常见的有:
- Free List:管理空闲页;
- LRU List:按访问热度管理页的淘汰;
- Flush List:跟踪被修改的脏页,配合 Checkpoint 刷新到磁盘。
3.3 脏页刷新机制(Checkpoint)
脏页(Dirty Page)是修改后尚未落盘的内存页。
当事务提交或后台线程运行时,InnoDB 会把部分脏页写入磁盘,以确保日志和数据的一致性。
这就是所谓的 Checkpoint(检查点)机制。
它的作用是防止:
- Redo Log 被写满;
- 系统崩溃后恢复时间过长;
- IO 写入过于集中造成性能抖动。
Checkpoint 是 InnoDB 持久化与性能平衡的核心点。
Buffer Pool(脏页) → Doublewrite Buffer → 数据文件 ↘ redo log 写盘(保障持久化)
3.4.Doublewrite Buffer:双写机制的安全保障
在 InnoDB 写入磁盘时,为了防止部分页写入失败导致数据损坏,引入了 Doublewrite Buffer(双写缓冲区)。
其原理是:
- InnoDB 先将脏页写入双写缓冲区;
- 再从缓冲区写入真正的数据文件;
- 如果发生宕机,InnoDB 可通过双写区重新恢复未完整写入的页。
虽然这会略微增加 IO 成本,但能显著提高数据安全性。
4. 总结与延伸
从整体架构到 Buffer Pool、再到脏页与双写机制,我们可以看到 InnoDB 是如何在性能与安全性之间取得平衡的。
- Buffer Pool 通过内存缓存减少磁盘 I/O,提升了系统性能;
- Checkpoint 机制则保证了日志与数据页的一致性;
- Doublewrite Buffer 则在最底层为数据安全兜底。
这三个机制共同构成了 InnoDB 的“性能核心”,
让它既能支撑高并发场景,又能在宕机后安全恢复。
5.面试高频题
| 面试问题 | 参考回答 |
|---|---|
| 1️⃣ MySQL 默认使用什么存储引擎?为什么? | MySQL 8.0 默认使用 InnoDB,因为它支持事务、行级锁、崩溃恢复,可靠性和并发性能更好。 |
| 2️⃣ InnoDB 和 MyISAM 有什么区别? | InnoDB 支持事务(ACID)、行级锁、MVCC,能防止数据丢失;MyISAM 不支持事务,只支持表锁,性能简单但不安全。 |
| 3️⃣ 什么是事务?事务有哪些特性? | 事务是数据库操作的最小单位,具备 ACID 特性:原子性、一致性、隔离性、持久性。 |
| 4️⃣ 什么是 Buffer Pool?它的作用是什么? | Buffer Pool 是 InnoDB 的内存缓存区,用来缓存数据页和索引页,减少磁盘 I/O,提高查询和写入性能。 |
| 5️⃣ 什么是脏页?为什么要有脏页? | 脏页是被修改但还没写入磁盘的页。存在的目的是提升性能,避免每次修改都触发磁盘写操作。 |
| 6️⃣ 什么是 WAL(Write Ahead Logging)? | WAL 指“先写日志再写数据”,确保崩溃后可通过日志恢复未写入磁盘的数据,保证事务持久性。 |
| 7️⃣ Redo Log 和 Undo Log 有什么区别? | Redo Log 负责“重做”已提交事务,保证持久性;Undo Log 用于“回滚”未提交事务,保证原子性和 MVCC。 |
| 8️⃣ 什么是 Checkpoint?为什么要有? | Checkpoint 是定期把脏页写回磁盘的机制,防止 redo log 被写满、缩短崩溃恢复时间、平滑磁盘 I/O。 |
| 9️⃣ 为什么需要 Doublewrite Buffer? | 防止页写入一半时宕机导致数据损坏,先写入双写缓冲,再写入真正表空间,保证写入的完整性。 |
| 🔟 InnoDB 如何保证数据不丢失? | 通过 WAL 原则 + Redo Log + Doublewrite Buffer 机制,即使宕机也能恢复。 |
| 11️⃣ 什么是 MVCC?解决了什么问题? | MVCC 是多版本并发控制,让读写操作互不阻塞,从而提升并发性能。 |
| 12️⃣ InnoDB 的行锁是怎么实现的? | 行锁依赖索引实现,通过锁定索引记录(或间隙)控制并发,避免整表加锁。 |
| 13️⃣ 为什么要有 Checkpoint 而不是实时写盘? | 实时写盘会严重影响性能;Checkpoint 可以批量、平滑地写入磁盘,在性能与安全间取平衡。 |
| 14️⃣ 如何判断 Buffer Pool 是否命中? | 查看 Innodb_buffer_pool_read_requests 和 Innodb_buffer_pool_reads 指标,命中率越高性能越好。 |
| 15️⃣ InnoDB 宕机后如何恢复? | 启动时通过 Redo Log 重做已提交事务,Undo Log 回滚未提交事务,Doublewrite 修复损坏页。 |
| MVCC 的实现依赖什么? | 依赖 Undo Log 保存旧版本 + 隐藏列(trx_id、roll_pointer),快照读不加锁,从而提高并发性能。 |