(论文速读)YOLA:学习照明不变特征的低光目标检测
论文题目:You Only Look Around: Learning Illumination Invariant Feature for Low-light Object Detection(你只看周围:学习照明不变特征的低光目标检测)
会议:NIPS2024
摘要:本文介绍了一种新的微光物体检测框架YOLA。与以往的工作不同,我们建议从特征学习的角度来解决这个具有挑战性的问题。具体来说,我们提出通过Lambertian图像形成模型来学习光照不变特征。我们观察到,在Lambertian假设下,利用相邻颜色通道和空间相邻像素之间的相互关系来近似光照不变特征映射是可行的。通过合并额外的约束,这些关系可以以卷积核的形式进行表征,卷积核可以在网络中以检测驱动的方式进行训练。为此,我们引入了一个新的模块,专门用于从低光图像中提取光照不变特征,该模块可以很容易地集成到现有的物体检测框架中。我们的实证研究结果表明,在低光物体检测任务中有显著的改进,在光线充足和光线过亮的情况下也有很好的结果。
代码可从https://github.com/MingboHong/YOLA获得。
YOLA:从物理模型到深度学习的低光照目标检测新范式
论文解读:You Only Look Around - Learning Illumination Invariant Feature for Low-light Object Detection (NeurIPS 2024)
引言
在计算机视觉领域,目标检测技术已经取得了令人瞩目的进展。然而,当夜幕降临,或是在光线不足的环境中,即便是最先进的检测算法也会"力不从心"。夜间监控、黄昏驾驶等场景下的目标检测,仍然是一个充满挑战的难题。
今天要介绍的这篇发表在NeurIPS 2024的论文,提出了一个名为YOLA(You Only Look Around)的创新框架,从全新的角度——光照不变特征学习——来解决低光照目标检测问题。
一、问题的本质:为什么低光照检测这么难?
1.1 传统方法的困境
目前主流的低光照目标检测方法主要分为两类:
第一类:图像增强 + 检测
- 先使用KIND、SMG、NeRCo等方法增强图像
- 再输入到检测器进行检测
- 问题:增强的目标是让人眼看着舒服,但机器"看"到的可能并不利于检测
作者在实验中发现了一个有趣的现象:最先进的图像增强方法NeRCo,在图像恢复任务上表现优异,但应用到检测任务时,性能反而不如其他方法。这说明视觉质量 ≠ 检测性能。

第二类:端到端训练
- MAET、IA-YOLO等方法试图在训练中同时优化增强和检测
- 问题:依赖大量合成数据,泛化能力受限;解空间大,优化困难
1.2 一个关键洞察
论文作者提出了一个核心观点:
低光照并没有改变物体的本质属性,改变的只是光照条件。如果能提取出与光照无关的特征,检测问题就迎刃而解了。
这个思想虽然简单,但实现起来却需要巧妙的设计。
二、YOLA的核心创新:从物理到深度学习
2.1 理论基础:朗伯反射模型
YOLA的理论基础来自经典的朗伯反射模型。在该模型下,图像中某个像素点在颜色通道C的值可以表示为:
C_p = m(n, l) × e_C(λ) × ρ_C(λ)
其中:
- m(n, l):表面法向量与光照方向的交互(仅与位置相关)
- e_C(λ):光照的光谱功率分布(illumination)
- ρ_C(λ):物体的反射率(物体固有属性)
关键观察:
- 项m只与位置有关,与颜色通道无关
- 相邻像素的光照e可以认为是相似的
2.2 从理论到实践:Cross Color Ratio
基于上述观察,作者推导出跨颜色比率(Cross Color Ratio, CCR):
考虑两个相邻像素p₁和p₂,以及红色(R)和蓝色(B)通道:
M_rb = (R_p1 × B_p2) / (R_p2 × B_p1)
取对数并利用朗伯模型展开,在满足以下假设时:
- 相邻像素光照相似:e_C_p1 ≈ e_C_p2
- 通过零均值约束消除位置项
最终得到光照不变特征:
log(M_rb) = log(ρ_R_p1) - log(ρ_R_p2) + log(ρ_B_p2) - log(ρ_B_p1)
这个特征只包含物体的固有反射率信息,与光照条件无关!
2.3 IIM模块:让物理模型"深度"起来
虽然CCR提供了一个优雅的理论解决方案,但固定的公式缺乏灵活性。作者的巧妙之处在于将其转化为可学习的卷积操作:
核心设计
1. 可学习卷积核
- 不是使用固定的差分核,而是学习一组卷积核 W₁, W₂, ..., Wₙ
- 核的权重可以根据下游任务自适应调整
- 能够捕捉比简单边缘更丰富的特征
2. 零均值约束
mean(W_n) = 0
这个约束确保了:
- 相邻像素相减能够消除光照项
- 保持光照不变性的同时允许学习更复杂的模式
3. 特征提取公式
f_W(I) = [W ⊛ log(R) - W ⊛ log(B),W ⊛ log(R) - W ⊛ log(G),W ⊛ log(G) - W ⊛ log(B)]
其中⊛表示卷积操作。
IIM的优势
- 初始化即保证光照不变性:零均值约束确保解空间起点正确
- 任务驱动学习:通过检测损失端到端优化,学习最适合检测的特征
- 轻量级:参数量仅0.008M,远小于其他方法(KIND 8.21M,MAET 40M)
2.4 整体架构
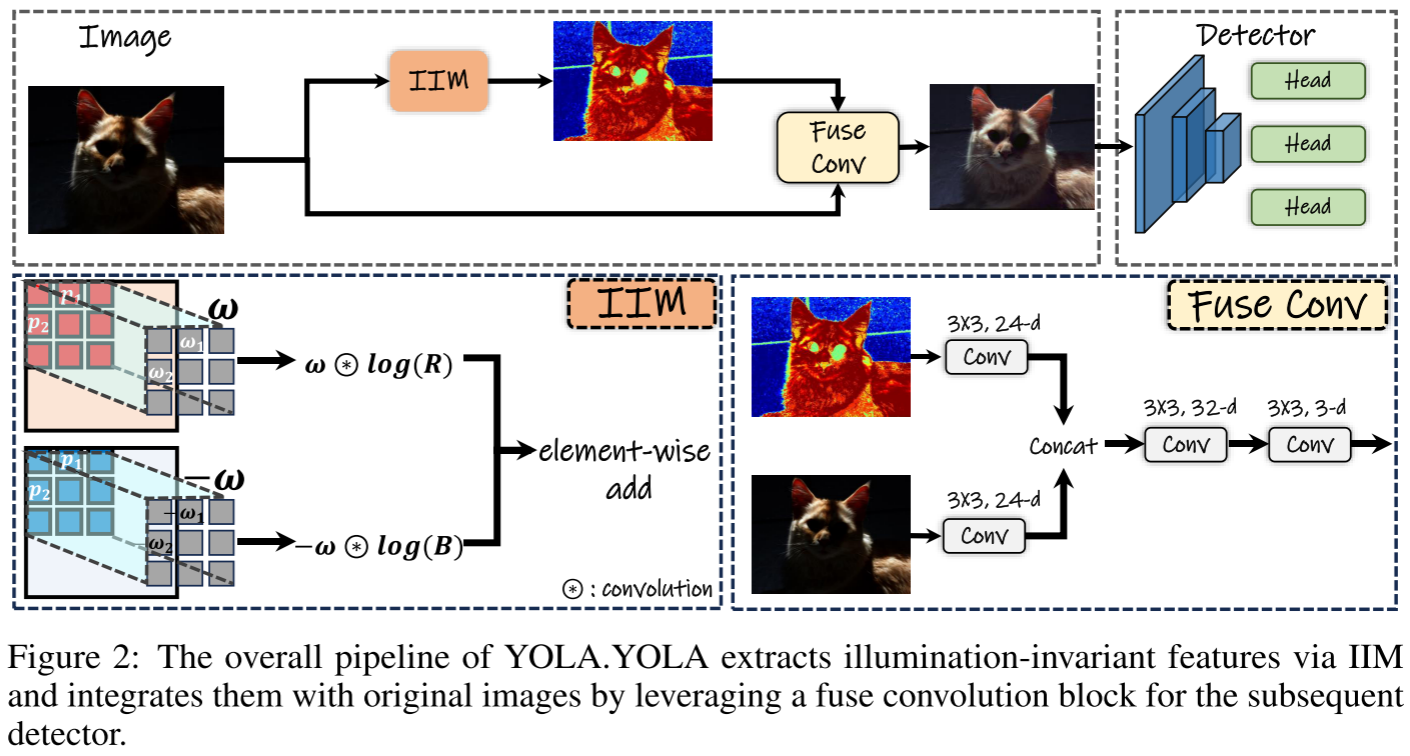
YOLA的pipeline非常简洁:
输入图像 → IIM提取光照不变特征 → 融合卷积 → 检测器
融合模块设计:
- IIM提取的特征通过一系列卷积处理
- 与原始RGB图像concat
- 送入标准检测器(YOLOv3、TOOD等)
这种设计的美妙之处在于:
- 即插即用:可以无缝集成到任何现有检测框架
- 端到端训练:整个系统联合优化
- 无需额外数据:不依赖配对的增强数据或合成数据
三、实验结果:理论的力量
3.1 在标准数据集上的表现

ExDark数据集(12类,7363张低光照图像)
| 方法 | YOLOv3 mAP₅₀ | TOOD mAP₅₀ |
|---|---|---|
| Baseline | 71.0 | 72.5 |
| KIND (增强) | 69.4 | 72.6 |
| SMG (增强) | 68.5 | 71.5 |
| NeRCo (增强) | 68.5 | 71.8 |
| DENet | 71.3 | 73.5 |
| MAET | 72.5 | 74.3 |
| YOLA | 72.7 | 75.2 |
UG²+DARK FACE数据集(6000张低光照人脸图像)
| 方法 | YOLOv3 mAP₅₀ | TOOD mAP₅₀ |
|---|---|---|
| Baseline | 60.0 | 62.1 |
| DENet | 60.0 | 66.2 |
| MAET | 59.9 | 64.8 |
| YOLA | 61.5 | 67.4 |
3.2 关键发现
增强方法的悖论:先进的图像增强方法(如NeRCo)在小目标检测上甚至降低了性能,因为增强过程可能损失关键细节
跨检测器的泛化:YOLA在anchor-based(YOLOv3)和anchor-free(TOOD)检测器上都取得了一致的提升
意外的惊喜:在COCO2017的正常光照和过曝场景下,YOLA也带来了性能提升,说明光照不变特征对一般场景也有益
3.3 消融实验的启示
IIM-Edge vs. 完整IIM
| 配置 | ExDark mAP₅₀ | DarkFace mAP₅₀ |
|---|---|---|
| Baseline | 72.5 | 62.1 |
| IIM-Edge (固定核) | 73.8 | 64.5 |
| IIM (可学习核) | 74.7 | 66.9 |
| IIM + 零均值约束 | 75.2 | 67.4 |
从数据可以看出:
- 即使是简单的边缘特征也能带来1.3-2.4个点的提升
- 可学习核进一步提升1.4-2.9个点
- 零均值约束确保了光照不变性,带来额外增益
特征可视化:
- IIM-Edge提取的特征相对单一,主要是边缘信息
- 完整IIM学到的特征更加丰富多样,包含更多对检测有用的模式
四、深入分析:为什么YOLA有效?
4.1 物理约束缩小了解空间
传统的端到端方法需要在巨大的解空间中搜索合适的特征表示。YOLA通过引入物理约束(零均值),将搜索空间限制在光照不变特征的流形上,这大大降低了优化难度。
4.2 任务驱动 + 物理先验的完美结合
- 物理先验确保了起点的正确性
- 任务驱动学习保证了特征对检测任务的适配性
- 二者结合,既有理论保证又有实践效果
4.3 Illumination Invariant Loss的作用
为了防止大卷积核产生平凡解(trivial solution),作者引入了II Loss:
L = {0.5 × (f_W(I) - f_W(σ(I)))², if diff ≤ β|f_W(I) - f_W(σ(I))| - 0.5β, otherwise
}
其中σ是亮度变换函数(如gamma校正)。这个损失鼓励IIM对不同光照下的同一场景提取一致的特征。
实验表明,在5×5卷积核时,II Loss带来的提升尤为明显,证明了其有效性。
五、局限性与未来展望
5.1 当前局限
- 朗伯假设:真实世界的反射可能更复杂(如镜面反射)
- 相邻像素光照一致性:在光照变化剧烈的边界处可能失效
- 可视化效果:增强后的图像可能略显灰暗(因为未限制值域)
5.2 未来方向
- 扩展到其他低层视觉任务:实验表明YOLA也能提升低光照实例分割
- 结合更复杂的反射模型:考虑镜面反射等因素
- 多光源场景:处理更复杂的光照条件
六、实践启示
YOLA的成功给我们带来了几点重要启示:
6.1 物理模型在深度学习时代仍有价值
在深度学习大行其道的今天,物理模型并没有过时。相反,将物理先验巧妙地融入神经网络,可以:
- 减少对数据的依赖
- 提升模型的可解释性
- 获得更好的泛化能力
6.2 任务适配性比视觉质量更重要
对于下游任务(如检测),特征的任务相关性比视觉上的"好看"更重要。这解释了为什么图像增强方法在检测任务上表现不佳。
6.3 简单而优雅的设计往往更有效
YOLA的核心思想可以用几个公式表达,实现也非常简洁(仅0.008M参数),但效果却超越了许多复杂的方法。这再次证明了"Less is More"的设计哲学。
七、代码实现要点
虽然论文提供了开源代码,但这里总结一些关键实现细节:
7.1 零均值约束的实现
# 伪代码示例
class ZeroMeanConv2d(nn.Module):def forward(self, x):# 减去均值确保零均值weight = self.weight - self.weight.mean()return F.conv2d(x, weight, ...)
7.2 IIM模块的实现
# 简化的IIM实现思路
def extract_illumination_invariant_feature(image):# 转换到log域log_image = torch.log(image + epsilon)# 提取各通道log_R, log_G, log_B = log_image.chunk(3, dim=1)# 应用零均值卷积feat_rb = zero_mean_conv(log_R) - zero_mean_conv(log_B)feat_rg = zero_mean_conv(log_R) - zero_mean_conv(log_G)feat_gb = zero_mean_conv(log_G) - zero_mean_conv(log_B)return torch.cat([feat_rb, feat_rg, feat_gb], dim=1)
八、总结
YOLA论文展示了如何将经典的物理模型与现代深度学习技术优雅地结合,解决低光照目标检测这一长期存在的挑战。其核心贡献包括:
- 理论创新:首次将光照不变特征系统地应用于低光照目标检测
- 方法创新:设计了轻量级的IIM模块,可即插即用
- 实验验证:在多个数据集和检测器上证明了方法的有效性和泛化能力
更重要的是,YOLA提醒我们:在追求复杂模型和大规模数据的同时,不要忘记利用领域知识和物理先验。有时候,一个简单而深刻的物理洞察,胜过千万参数的盲目堆砌。
希望这篇博客能帮助你理解YOLA的核心思想和技术细节。如果你对低光照视觉或物理驱动的深度学习感兴趣,这篇论文绝对值得深入研读!