北大上海AiLab具身导航最新基准测试!NavSpace: 导航智能体如何遵循空间智能指令
作者:Haolin Yang, Yuxing Long, Zhuoyuan Yu, Zihan Yang, Minghan Wang, Jiapeng Xu, Yihan Wang, Ziyan Yu, Wenzhe Cai, Lei Kang, Hao Dong
单位:北京大学计算机学院CFCS,北京大学Agibot实验室,上海人工智能实验室
论文标题:NavSpace: How Navigation Agents Follow Spatial Intelligence Instructions
论文链接:https://arxiv.org/pdf/2510.08173
项目主页:https://navspace.github.io/
代码链接:https://github.com/TidalHarley/NavSpace
主要贡献
提出首个空间智能导航基准NavSpace:基于问卷调查,NavSpace包含1228个高质量的轨迹-指令对,覆盖垂直感知、精确移动、视角转换、空间关系、环境状态和空间结构等六种空间智能能力,为评估导航智能体的空间智能提供了全面的基准。
全面评估22种导航智能体:在NavSpace基准上,对包括轻量级导航模型、导航大模型、开源多模态大模型和专有大语言模型在内的22种导航智能体进行了综合评估,得出了关于空间智能基准对导航的重要性、多模态大模型在具身导航任务中的局限性、导航大模型相对于轻量级模型的优势以及提升导航智能体空间智能的有希望的方向等关键见解。
提出SNav模型:SNav是一个空间智能导航大模型,它在NavSpace基准和真实机器人测试中超越了现有模型,为未来的研究工作建立了一个强大的基线。
研究背景
具身智能中的导航智能体:构建能够根据人类指令在环境中移动的导航智能体是实现具身智能的关键一步。近年来,视觉语言导航(VLN)等任务得到了广泛研究,但现有的评估任务主要关注多模态语言和视觉语义的理解,没有系统地评估导航智能体的空间感知和推理能力。
空间智能在导航中的重要性:在日常生活中,需要空间智能的导航任务很常见,例如准确感知空间尺度、主体-物体空间关系和环境结构,并正确推断导航动作。然而,之前没有基准广泛评估导航智能体在空间感知和推理方面的能力,导致目前导航模型和多模态大模型在具身导航任务中的空间智能尚不清楚,提升这些能力的方法也未被充分探索。
NAVSPACE基准
任务定义
NavSpace 任务定义遵循经典的指令导航任务。给定 NavSpace 中的语言指令,导航智能体需要在时间步预测下一个导航动作,基于当前的观测。如果智能体选择停止,其与目标的距离必须低于预定义的阈值。
基准构建

问卷调查
为了确定哪些导航指令最能反映空间智能,设计了两部分的问卷。
第一部分:受访者阅读空间智能的详细定义并确认理解。
第二部分:展示17种可能需要空间智能的候选指令类型,要求受访者选择最多6种最符合定义且合理的类型。
收集了512份回应,为确保可靠性,仅保留了完成时间超过3分钟的457份进行分析。最终确定了六个最常被选中的类别:垂直感知(Vertical Perception)、精确移动(Precise Movement)、视角转换(Viewpoint Shifting)、空间关系(Spatial Relationship)、环境状态(Environment State)和空间结构(Space Structure)。
基于这些类别收集了导航轨迹和指令。
轨迹收集
基于 Habitat 3.0 模拟器和 HM3D 场景构建了数据收集平台,包括前端标注网页和后端服务器,后端服务器与模拟器接口并存储数据。
标注者登录后,通过键盘远程操作智能体,在第一人称 RGB 观测下进行导航。在标注者熟悉场景布局后(至少移动200步),开始记录轨迹。
平台指定标注者应遵循的指令类别。标注者点击“开始记录轨迹”按钮后,平台实时记录智能体的第一人称 RGB 帧、导航动作和坐标;标注者点击“停止记录轨迹”按钮时,记录结束。
指令标注
在记录完整的导航轨迹后,标注者可以调用 GPT-5 分析收集到的轨迹。GPT-5 的文本输入包括目标指令类型、离散导航动作和位置坐标,视觉输入包括沿轨迹采样的智能体的第一人称观测。
GPT-5 分析遇到的房间、区域和物体,并生成供标注者审查的候选导航指令。人类标注者必须按照标注规范撰写最终的导航指令。
人工交叉验证
为了确保标注的指令可执行,要求不同的标注者对指令进行交叉验证。
每条指令必须由未见过该指令的标注者远程控制智能体在 Habitat 中导航。如果标注者能成功到达目标位置,则指令有效;否则,指令将被丢弃并重新标注。

NavSpace指令类别

垂直感知
评估模型在室内环境中确定其垂直位置的能力。这些指令可能包括与建筑物结构相关的明确楼层引用,如“Go to the second floor, walk through the corridor, and stop by the bed in the bedroom at the end of the corridor.”
指令也可能使用相对术语而不是具体数字,如“Go to a higher floor, pass the sofa next to the staircase, and stop beside the television in the bedroom ahead.”
在某些情况下,可能完全省略明确的数字或相对术语,如“Go to the topmost floor and stop at the bedroom doorway next to the picture frame.”或“Stop halfway up the stairs beside the picture frame.”
挑战在于模型能够从上下文中推断垂直位置(例如,“最高层”或“一半”)。成功标准是到达目标点3.0米范围内。
精确移动
测试智能体精确理解指令中指定的详细距离和角度,并准确将其转化为导航动作的能力。智能体需要感知空间尺度。例如,“From the door, turn right 180°, go straight 1m, turn left 90° and go 5m, then turn 90° clockwise and go 7.5m, then stop.”
智能体必须正确执行每个指定的旋转和平移。由于控制器没有后退动作原语,任何“向后走”的指令都必须通过旋转180°然后向前移动来实现。成功半径定义为1.0米。
视角转换
主要测试导航智能体在主体和物体之间切换视角的能力。要求智能体具备空间想象力和空间转换能力。与之前的工作不同,NavSpace 更加注重长期记忆和历史感知推理:智能体必须正确推理其整个运动历史,即使经过多次重新定位。
一个典型的指令是:“Imagine you are the television in front of you. Move toward your front-left, follow the hallway to the end, and stop at the white door.”
智能体必须采用电视机的视角,意识到电视机的左前方对应于智能体自己的右侧,然后相应地导航到目标。成功半径定义为1.0米。
空间关系
关注感知多个物体或房间之间的顺序和相对空间关系。可能涉及跨房间导航,如“Walk down the hallway, turn left at the third door on your left, and stop next to the chair in the bedroom.”这测试计数和排序技能。
也评估涉及多个物体的空间推理,如“Go downstairs to the living room and stop between the two brown sofas.”这要求识别物体位置并理解物体之间的空间关系,以确定移动或停止的位置。成功标准是到达目标点1.0米范围内。
环境状态
要求智能体在导航过程中准确感知环境状态,并根据这些状态做出关于未来行动的正确决策。这一类别的代表性格式是“if...otherwise...”。
例如:“Walk through the hallway to the foyer and wait beside the storage cabinet; if you see the keys, stop, otherwise go to the front door and check.”
成功半径定义为2.0米。
空间结构
要求智能体理解空间布局,并按照指令执行导航行为,如环绕、往返和移动到极端位置。
例如,指令可能要求环绕一个物体转一圈,如“Walk around the eight-person dining table once.”以评估模型对物体尺寸和形状的把握。
其他指令要求往返路径,如“Go to the sofa in the room at the end of the hallway and then return.”测试往返导航。
还有一些指令标识极端位置(例如,最近或最远),如“Go upstairs to the room on your right and stop by the farthest sofa.”
成功标准是到达目标点1.0米范围内。
SNAV 模型
模型架构
视觉编码器
功能:视觉编码器负责从输入的 RGB 视频帧中提取视觉特征表示。它接收一系列采样帧,并生成视觉特征。
实现:使用 SigLIP 作为视觉编码器,它是一个预训练的视觉模型,能够有效地提取图像中的语义信息。
映射器
功能:映射器的作用是将视觉编码器生成的视觉特征转换到大语言模型的语义空间中,生成视觉标记。
实现:使用一个两层的多层感知机(MLP)作为映射器,将视觉特征映射到语言模型的输入空间。
大语言模型
功能:大语言模型负责将视觉标记和从任务指令中提取的文本标记结合起来,进行自回归预测,生成导航动作。
实现:使用 Qwen2 作为大语言模型,这是一个预训练的多模态语言模型,能够处理视觉和语言信息。
模型初始化
SNav 模型从 LLaVA-Video 7B 初始化,这是一个预训练的多模态模型,专门用于视频理解和生成任务。
在初始化后,模型通过共训练(co-training)三种任务进行微调:导航动作预测(Navigation Action Prediction)、基于轨迹的指令生成(Trajectory-based Instruction Generation)和一般多模态数据回忆(General Multimodal Data Recall)。通过这些任务的训练,模型能够更好地理解和生成导航指令。
空间智能增强
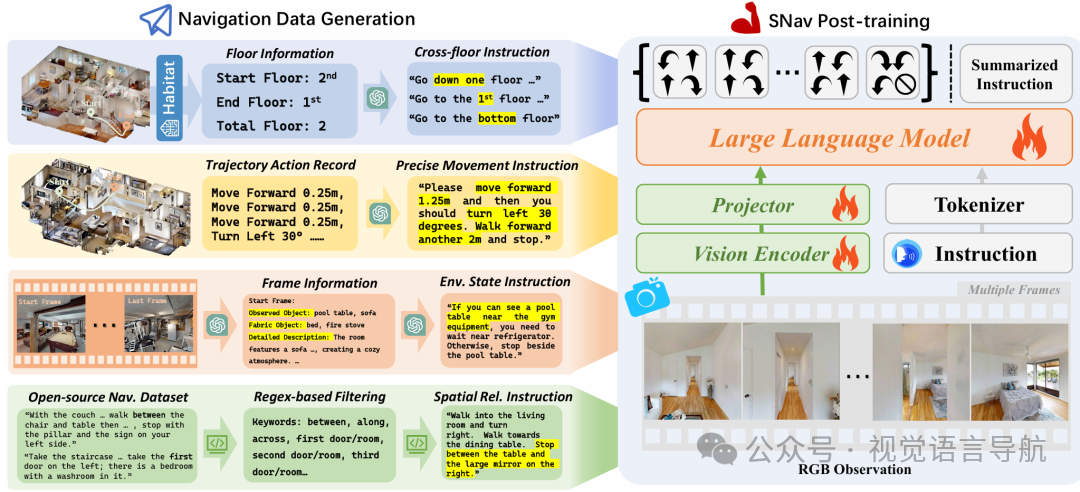
为了提升 SNav 模型的空间智能,设计了一套从现有数据中生成需要空间感知和推理的导航数据的流程,并用这些数据对模型进行微调。
跨楼层导航
数据生成:从 R2R 数据集中选择可能跨越楼层的轨迹,通过 Habitat 模拟器生成轨迹并记录 RGB 观测。使用 GPT-5 检测楼梯,为轨迹标注楼层信息。例如,将“Walk up the stairs ...”改写为“Walk up to the top floor ...”。
目标:增强模型对垂直空间的理解和导航能力。
精确移动
数据生成:在 MP3D 场景中随机采样起点和终点,使用 Habitat 模拟器的最短路径规划器生成轨迹。记录离散的导航动作(如左转30°、右转30°、前进0.25米等),并生成简洁的移动描述。例如,“Move forward 3m, turn right 60°, move forward 2m”。
目标:提升模型对精确距离和角度的理解和执行能力。
环境状态推断
数据生成:从 R2R 数据集中提取起点-终点对及其对应的导航指令,使用最短路径规划器生成轨迹并保存路径上的 RGB 帧。查询 GPT-5 以推断可观察对象、不可观察对象和详细描述。结合这些信息和原始指令设计模板,生成新的指令。例如,“If you see the keys, stop; otherwise go to the front door and check.”。
目标:增强模型对环境状态的感知和决策能力。
空间关系
数据生成:对 R2R 数据集中的指令应用正则表达式,选择包含序数短语(如“first room”、“second door”)和多对象关系(如“between”、“along”)的指令。
目标:提升模型对多个物体或房间之间空间关系的理解和推理能力。
实验
评估设置
环境和指标
模拟器:使用 Habitat 3.0 模拟器进行评估,评估场景来自 HM3D 数据集。
动作:智能体在每一步可以选择以下动作之一:向前移动 0.25 米、左转 30°、右转 30° 或停止。
评估指标:
导航误差 (NE):智能体在停止时与目标位置之间的欧几里得距离。
Oracle 成功率 (OS):假设智能体可以选择最优动作,成功到达目标位置的比例。
成功率 (SR):智能体实际执行动作并成功到达目标位置的比例。
基线模型
实验评估了 22 种现有的导航智能体,包括轻量级导航模型、导航大模型、开源多模态大模型(MLLMs)和专有大语言模型。
随机猜测基线:
随机水平:随机选择四个导航动作之一(每个动作的概率为 25%)。
频率水平:根据 NavSpace 中轨迹数据中观察到的动作频率进行导航动作选择。
开源多模态大模型:LLaVA-Video 7B、 GLM-4.1V-Thinking 9B、 GLM-4.5V 106B、 Qwen2.5-VL 7B、 Qwen2.5-VL 72B:一个更大规模的版本。
专有大语言模型: GPT-4o、 GPT-5 Mini、GPT-5、 Gemini 2.5 Flash、Gemini 2.5 Pro。
轻量级导航模型: Seq2Seq、 CMA、 HPN+DN、 VLNBERT、 Sim2Sim、 ETPNav、 BEVBert。
导航大模型: NaVid、NaVILA、StreamVLN,这些模型基于大型多模态数据预训练,并针对指令导航任务进行了微调。
NavSpace 上的性能
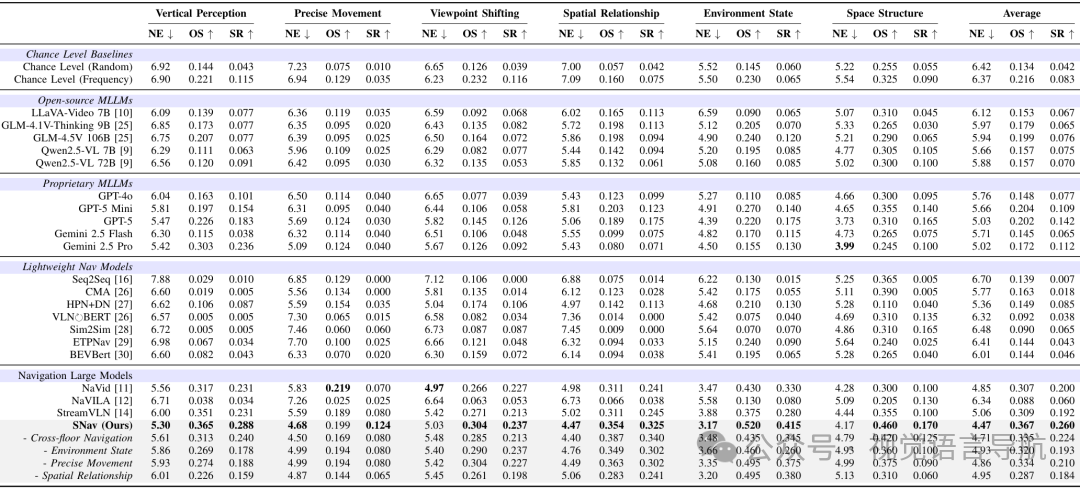
多模态大模型 (MLLMs)
结果:开源多模态大模型在 NavSpace 上的表现较差,其平均成功率低于 10%,与基于频率的随机猜测水平相当。专有大语言模型的性能优于开源模型,其中 GPT-5 表现最好,但所有专有大语言模型的平均成功率仍低于 20%。
结论:现有的大语言模型在具身导航任务中表现出的空间智能能力有限,难以直接作为导航智能体使用。
导航模型
轻量级导航模型:如 BEVBert 和 ETPNav,在需要空间智能的导航指令上表现不佳,成功率极低。
导航大模型:如 NaVid 和 StreamVLN,表现优于轻量级模型,平均成功率超过 GPT-5,展现出一定的空间智能能力。
SNav 模型:SNav 在 NavSpace 上的表现超过了所有现有的导航模型和大语言模型,成为强大的基线模型。消融实验表明,所提出的指令生成流程对提升 SNav 的空间智能有显著帮助。
真实世界测试
测试环境
在真实世界环境中对 SNav 模型进行了测试,包括办公室、校园和户外环境。
测试覆盖了五类空间智能导航指令(不包括垂直感知)。
测试平台
使用 AgiBot Lingxi D1 四足机器人,该机器人配备了单目 RGB 相机和运动控制 API。
机器人接收到导航指令后,将 RGB 观测传输到远程服务器上的导航模型(搭载 NVIDIA A100 GPU),模型预测动作并通过 D1 的运动 API 执行。

结果

SNav 在真实世界测试中的表现优于 NaVid 和 NaVILA,成功率为 32%,远高于 NaVid 的 14% 和 NaVILA 的 6%。
测试结果表明,SNav 在实际应用中具有较好的空间智能和导航能力。


结论与未来工作
结论:
现有的空间智能基准无法真正反映模型在具身导航中的能力,NavSpace作为动态任务基准更能捕捉具身任务的核心需求。
当前的多模态大模型尚未展现出具身导航中出现的空间智能,其在感知到行动的推理、多帧之间感知的一致性等方面存在不足。
轻量级导航模型无法有效执行空间智能导航指令,它们在NavSpace上的表现远低于导航大模型。
导航大模型虽然在某些方面表现出空间智能,但仍需在空间感知和将空间感知转化为行动的推理机制上进行显著改进。
未来工作:
未来的研究应着重于显著提升导航模型的空间感知能力,并增强将空间感知转化为行动的推理机制,以进一步提高导航智能体在具身导航任务中的空间智能。
