Algorithm refinement: Mini-batch and Soft Update|算法改进:小批量和软更新
-----------------------------------------------------------------------------------------------
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
----------------------------------------------------------------------------------------------
一、从全量到小批量——训练思路的转变

在传统的神经网络或线性回归训练中,我们通常定义一个代价函数:
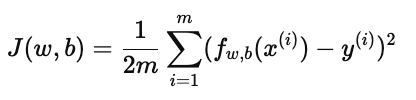
其中 m 是训练样本总数。理想情况下,我们希望每次梯度下降都基于全部样本计算,以获得最精确的更新方向。
然而——当 m 达到上亿级(如图中写的 100,000,000)时,
每次完整遍历数据集(称为 Batch Gradient Descent)会变得极其缓慢,
并且需要巨大的显存和计算资源。
Mini-batch 的引入
为了解决这一问题,我们引入了 Mini-batch Gradient Descent。
其核心思想是:
每次从全部样本中随机抽取一个小批量 m′(例如 1000 个样本),
用它们近似整体梯度进行一次参数更新。
公式变为: