论文学习_Unleashing the power of pseudo-code for binary code similarity analysis
标题: Unleashing the power of pseudo-code for binary code similarity analysis (Weiwei Zhang,2022)
作者: Weiwei Zhang, Zhengzi Xu, Yang Xiao, Yinxing Xue
期刊: Cybersecurity
摘要
代码相似性分析因其在漏洞检测、恶意软件检测和补丁分析等领域的重要应用而受到广泛关注。由于多数情况下难以获取软件源代码,二进制级代码相似性分析成为研究重点。近年来,许多结合人工智能技术的BCSA研究致力于从二进制函数中提取语义信息,通过汇编代码、中间表示或控制流图等代码表征形式来衡量相似性。然而,由于编译器、目标架构及代码混淆技术的差异,同一源代码编译生成的二进制文件可能呈现显著不同,这成为现有方法获取鲁棒特征的主要障碍。本文提出名为UPPC的解决方案,通过利用二进制函数对应的伪代码作为输入应对这一挑战。伪代码具有更高抽象层级和平台无关性,能有效克服底层指令差异。UPPC采用选择性函数内联以捕捉跨编译器优化级别的完整函数语义,并利用深度金字塔卷积神经网络生成函数语义嵌入。在包含已知漏洞的数据集,以及涵盖X86/ARM架构、O0-O3优化级别、GCC/Clang编译器与四种混淆策略的多样化数据集上进行测试,结果表明UPPC在函数搜索任务中的准确率较现有方法提升33.2%。
UPPC采用选择性函数内联以捕捉跨编译器优化级别的完整函数语义,解决函数内联
引言
开源库在软件开发过程中的广泛应用显著提升了开发效率并降低了成本,但同时也导致大量代码重复和克隆现象出现在不同软件中。为此,研究者开发了多种源代码级别的代码审计与克隆检测工具,以识别软件中开源组件的使用情况。然而,实际场景中软件源代码往往难以获取,使得此类工具无法直接用于分析闭源软件。针对此问题,二进制代码相似性分析技术应运而生。该技术通过直接分析二进制程序,成为在二进制层面解决开源组件相关安全问题的关键技术,其应用范围涵盖补丁分析、漏洞搜索、代码抄袭检测等多个重要领域。
回顾已有研究,针对二进制代码相似性分析的不同应用需求与技术挑战,研究者提出了基于多种代码表示形式的BSCA工具,包括基于文本特征、程序逻辑、控制流图等不同类型的方法。近年来,随着机器学习技术的发展,最新研究成果通过引入机器学习方法显著提升了BSCA的分析能力,使其在准确性和适用性方面得到实质性增强。
然而,直接基于汇编代码特征或控制流图进行二进制语义分析面临挑战:不同指令集架构的汇编代码存在固有差异,而代码混淆技术会改变函数的控制流结构,这些因素均阻碍深度学习模型对程序语义的准确理解。为消除架构差异,现有研究转而采用中间表示作为分析基础,因其具备平台无关性且比汇编代码更具抽象优势。另有研究表明,将特定编译器与优化选项组合编译源代码后提取的二进制伪代码,在代码分类与克隆检测任务中表现优异,这得益于伪代码与源代码的相似性,以及深度学习在源代码克隆检测中的成功经验。但据我们观察,目前尚未有研究将伪代码特征应用于二进制代码相似性分析中的函数匹配任务。
为此,我们提出名为UPPC的二进制代码相似性度量工具,该工具基于深度学习技术,利用伪代码提取函数的语义表示。受现有研究启发,UPPC通过选择性内联关键函数以恢复完整函数语义,随后从伪代码中提取代码特征与字符串特征,并结合深度金字塔卷积神经网络捕获全局函数语义并生成语义嵌入向量。该嵌入向量可有效用于漏洞检测、函数搜索等任务中的语义相似性匹配。
选择性函数内联技术保证函数嵌入在跨编译优化级别任务中的鲁棒性
与现有二进制分析方法相比,本方法具有以下优势:(1)平台无关性:伪代码通过更高层次的抽象统一了不同架构(如x86与ARM)的指令差异,消除了架构相关性,为跨架构代码分析提供更准确的基础;(2)语法信息丰富:伪代码近似源代码,保留了变量定义、数据结构、字符串等关键语义特征;(3)语义表达增强:二进制代码转换为伪代码后,能恢复更多逻辑结构信息,其更接近自然语言的特性使程序功能更易于表征。
研究动机
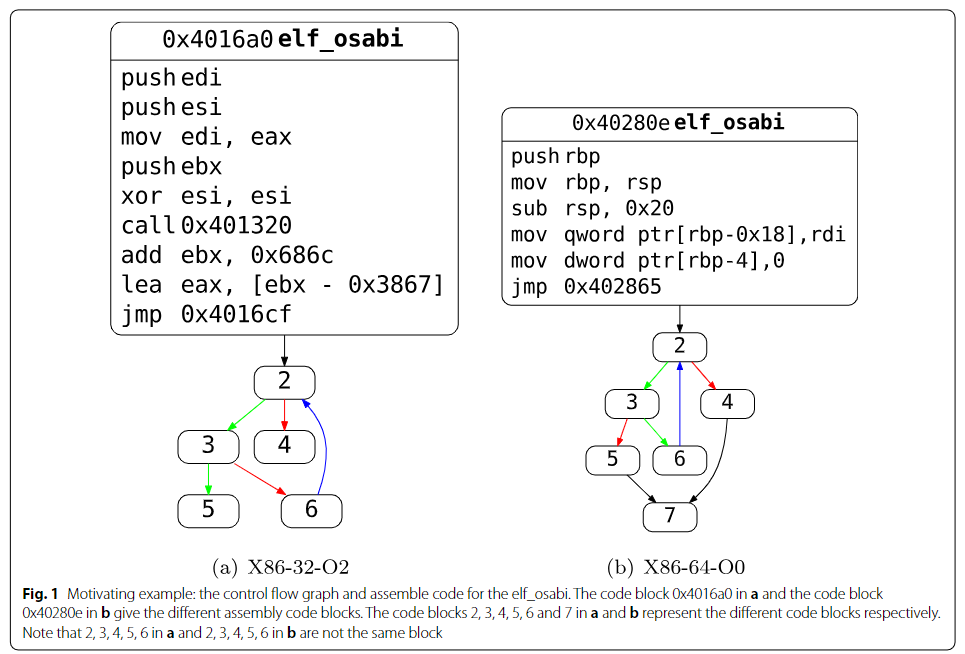
我们通过示例说明现有基于汇编代码与控制流图(CFG)方法面临的挑战,以及伪代码方法的优势。图1展示了Binutils中函数elf_obf分别编译为32位与64位程序(使用相同GCC编译器但不同优化选项O0与O2)的CFG对比。尽管图8a、b显示两者均采用循环结构,但其CFG在基本块数量(分别为6块与7块)及各块内汇编指令数量存在明显差异。Gemini通过提取基本块属性(如数值常量、传输指令数、调用次数等)构建属性控制流图进行相似性检测,此类结构差异对其构成挑战。SAFE则将二进制函数的指令序列视为自然语言进行建模,但如图所示,64位与32位汇编指令在基本寄存器数量(16个与8个)、寄存器命名规范("e"前缀与"r"前缀)及函数传参方式等方面存在根本差异,直接影响以原始指令序列作为文本输入的模型准确性。
现有方法(基于指令序列方法,基于控制流图方法)存在较为严重的语义丢失。

相比之下,通过反编译工具获取的二进制伪代码与源代码高度相似。图2中伪代码片段#2和#3分别对应图8a、b的二进制功能。可以看出,伪代码风格统一且与源代码(图2中#1)结构相近,同时保留了更多语义特征并具有更高的一致性。因此,基于伪代码的分析无需直接应对不同编译器、优化选项及指令架构带来的差异,这促使我们探索利用二进制伪代码进行代码相似性分析的可行性。
研究内容
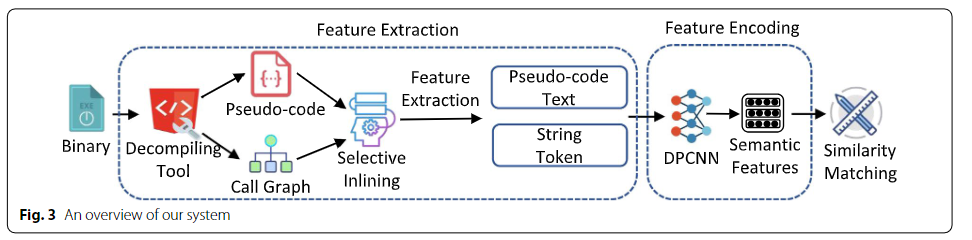
UPPC是一种基于伪代码的二进制相似性检测工具,其核心工作流程分为特征提取与特征编码两个阶段:首先通过反编译工具将二进制文件转化为伪代码与函数调用图,并采用选择性内联策略提取伪代码文本特征及字符串标记特征;随后利用深度神经网络将上述特征编码为函数语义嵌入向量,生成的向量可直接用于函数相似性检测、函数搜索及漏洞匹配等下游任务,实现端到端的二进制代码相似性分析。
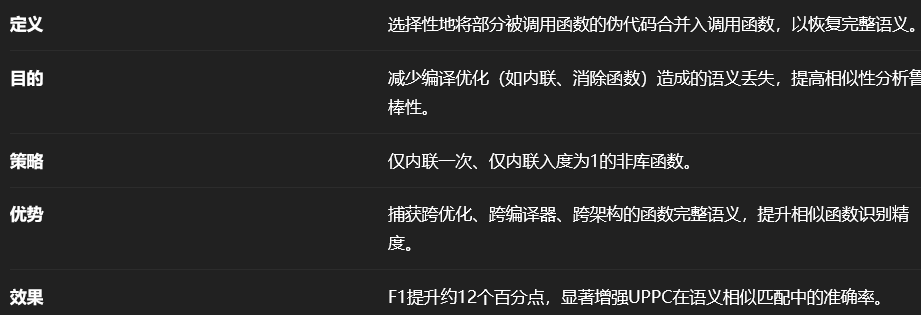
选择性函数内联算法比较具有借鉴意义,用于丰富代码的语义。