关键词解释:梯度消失(Vanishing Gradient)与 梯度爆炸(Exploding Gradient)
“训练一个深层网络,就像在暴风雨中掌舵一艘没有罗盘的船——稍有不慎,就会迷失方向。”
在深度学习的黄金时代,我们能轻松构建上百层的神经网络,但在不到十年前,这几乎是天方夜谭。阻碍这一切的,不是算力,也不是数据,而是两个看似微小却致命的问题:梯度消失(Vanishing Gradient) 与 梯度爆炸(Exploding Gradient)。
它们像幽灵一样潜伏在网络深处,悄无声息地扼杀训练过程。本文将带你揭开它们的面纱,理解其根源,并掌握现代深度学习中应对它们的“武器库”。
🧠 一、问题的本质:反向传播中的“连锁反应”
神经网络通过反向传播更新参数。对于一个 L 层网络,第 l 层的梯度大致为:
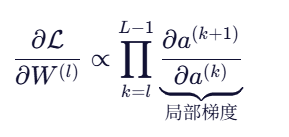
这个连乘项,就是问题的核心。
- 如果每项都 < 1 → 乘积指数级趋近于 0 → 梯度消失
- 如果每项都 > 1 → 乘积指数级膨胀 → 梯度爆炸
想象一下:你站在高楼顶层往下扔纸片(梯度),风太小(<1),纸片还没到一楼就停了;风太大(>1),纸片变成炮弹,把一楼炸飞了。
🔍 二、罪魁祸首是谁?
1️⃣ 激活函数:温柔的陷阱
早期网络偏爱 Sigmoid 和 Tanh,但它们的导数“天生娇弱”:
- Sigmoid 导数最大值仅为 0.25
- Tanh 导数最大为 1,但大部分区域远小于1
# Sigmoid 导数可视化(最大值仅 0.25!)
import numpy as np
x = np.linspace(-5, 5, 100)
sig_prime = lambda x: np.exp(-x) / (1 + np.exp(-x))**2
print("Sigmoid 导数峰值:", sig_prime(0)) # 输出:0.25
10 层网络?梯度可能只剩 —— 几乎为零!
2️⃣ 权重初始化:起点决定命运
- 权重太大 → 激活值爆炸 → 激活函数饱和 → 梯度≈0
- 权重太小 → 信号在前向传播中就衰减 → 反向梯度更弱
3️⃣ 网络深度:越深,风险越高
每增加一层,就多一次“乘法赌博”。20层?50层?100层?没有防护措施,训练注定失败。
💡 RNN 是重灾区:时间步展开后相当于超深网络,梯度问题尤为严重。
⚠️ 三、症状诊断:你的模型“病”了吗?
| 现象 | 可能问题 |
|---|---|
| 训练 loss 几乎不动,准确率卡在随机水平 | 梯度消失(浅层学不到东西) |
loss 突然飙升、出现 NaN、参数剧烈震荡 | 梯度爆炸 |
| 浅层权重几乎不变,深层变化剧烈 | 典型梯度消失 |
实用技巧:在训练时监控各层梯度的 L2 范数:
for name, param in model.named_parameters():if param.grad is not None:print(f"{name}: {param.grad.norm().item():.6f}")
若浅层梯度 < 1e-5,警惕梯度消失;若某层 > 100,小心爆炸。
🛠️ 四、现代解决方案:深度学习的“免疫系统”
✅ 1. 激活函数升级:告别 Sigmoid,拥抱 ReLU
ReLU()在正区间导数恒为 1,彻底避开小梯度陷阱。
缺点?“死神经元”问题。
解法?用 Leaky ReLU、ELU 或 GELU(Transformer 中常用)。
✅ 2. 智能初始化:让信号“稳稳传递”
| 激活函数 | 推荐初始化 |
|---|---|
| Sigmoid / Tanh | Xavier / Glorot |
| ReLU 及其变体 | He 初始化 |
# PyTorch 示例
nn.init.kaiming_normal_(layer.weight, nonlinearity='relu') # He 初始化
原理:让每一层的输出方差 ≈ 输入方差,避免信号衰减或爆炸。
✅ 3. 残差连接(ResNet):给梯度开“高速公路”
ResNet 的核心思想:
反向传播时,梯度可直接通过 恒等映射(+x) 回传,绕过非线性变换:
那个 +1,就是救命稻草!即使 ,梯度也不会消失。
🎯 这是 ResNet 能训练 1000+ 层网络的关键!
✅ 4. Batch Normalization:稳定每一层的“气候”
BN 通过标准化每层输入,使其均值为 0、方差为 1,带来两大好处:
- 缓解内部协变量偏移(Internal Covariate Shift)
- 间接抑制梯度异常,使训练更平稳
✅ 5. 梯度裁剪(Gradient Clipping):给爆炸“踩刹车”
尤其适用于 RNN/LSTM:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
将梯度整体缩放到安全范围,防止参数更新“一步登天”。
✅ 6. 优化器进化:Adam、RMSProp 的自适应智慧
这些优化器能根据历史梯度动态调整学习率,对梯度波动更具鲁棒性。
📌 五、一张表总结对策
| 问题 | 根源 | 解决方案 |
|---|---|---|
| 梯度消失 | 激活函数导数小、深度大 | ReLU / 残差连接 / He 初始化 / BN |
| 梯度爆炸 | 权重过大、深度大 | 梯度裁剪 / Xavier 初始化 / BN / 小学习率 |
🌟 六、结语:从“不可训练”到“百层如一日”
梯度消失与爆炸,曾是深度学习发展的最大拦路虎。但今天,凭借合理的架构设计、初始化策略与训练技巧,我们不仅能驯服它们,还能构建出前所未有的深层模型。
下次当你轻松训练一个 50 层 CNN 或 Transformer 时,请记住:背后是无数研究者与工程师,为对抗这两个“幽灵”与“风暴”所付出的智慧。
深度学习不是魔法,而是对细节的极致掌控。
📚 延伸阅读
- He et al., Deep Residual Learning for Image Recognition, CVPR 2016
- Glorot & Bengio, Understanding the difficulty of training deep feedforward neural networks, AISTATS 2010
- Pascanu et al., On the difficulty of training Recurrent Neural Networks, ICML 2013