【CVPR 2025】即插即用GBC模块:小体积,大能量,重塑特征提取新范式
01 前言
针对结构裂缝像素级分割任务中,现有方法难以在分割质量与计算资源消耗之间取得平衡的挑战,本文提出了一种名为SCSegamba的轻量级结构感知视觉Mamba网络。传统CNN方法因感受野受限,难以建模大范围不规则依赖;而Transformer方法虽能捕捉长程依赖,但其二次方计算复杂度导致模型庞大,难以部署。为解决这些问题,SCSegamba利用选择性状态空间模型 (Selective State Space Models, SSMs) 的线性计算复杂度优势,并进行针对性优化。本文的核心创新在于设计了结构感知视觉状态空间模块 (Structure-Aware Visual State Space, SAVSS),其内部包含轻量化的门控瓶颈卷积 (Gated Bottleneck Convolution, GBC) 和一种结构感知扫描策略 (Structure-Aware Scanning Strategy, SASS)。GBC旨在高效捕捉裂缝的形态信息,而SASS通过独特的对角线与平行蛇形扫描路径,增强了对裂缝不规则拓扑和纹理的连续性感知。实验证明,SCSegamba在仅有2.8M参数量的情况下,性能超越了多种现有SOTA方法,实现了高精度与轻量化的统一。
阅读原文,获取论文详细解读
02 论文基本信息

- 标题: SCSegamba: Lightweight Structure-Aware Vision Mamba for Crack Segmentation in Structures
- 核心模块:
- 轻量化门控瓶颈卷积 (Gated Bottleneck Convolution, GBC)
- 结构感知视觉状态空间模块 (Structure-Aware Visual State Space, SAVSS)
- 结构感知扫描策略 (Structure-Aware Scanning Strategy, SASS)
- 多尺度特征分割头 (Multi-scale Feature Segmentation Head, MFS)
03 算法框架与核心模块
3.1 算法框架
SCSegamba采用编码器-解码器架构。编码器由四个级联的SAVSS模块构成,通过逐级下采样提取多尺度特征。这些特征图(F1, F2, F3, F4)随后被送入MFS解码器。在MFS中,特征图经过MLP处理和动态上采样后被拼接,最终通过GBC和MLP生成高精度的像素级分割图。
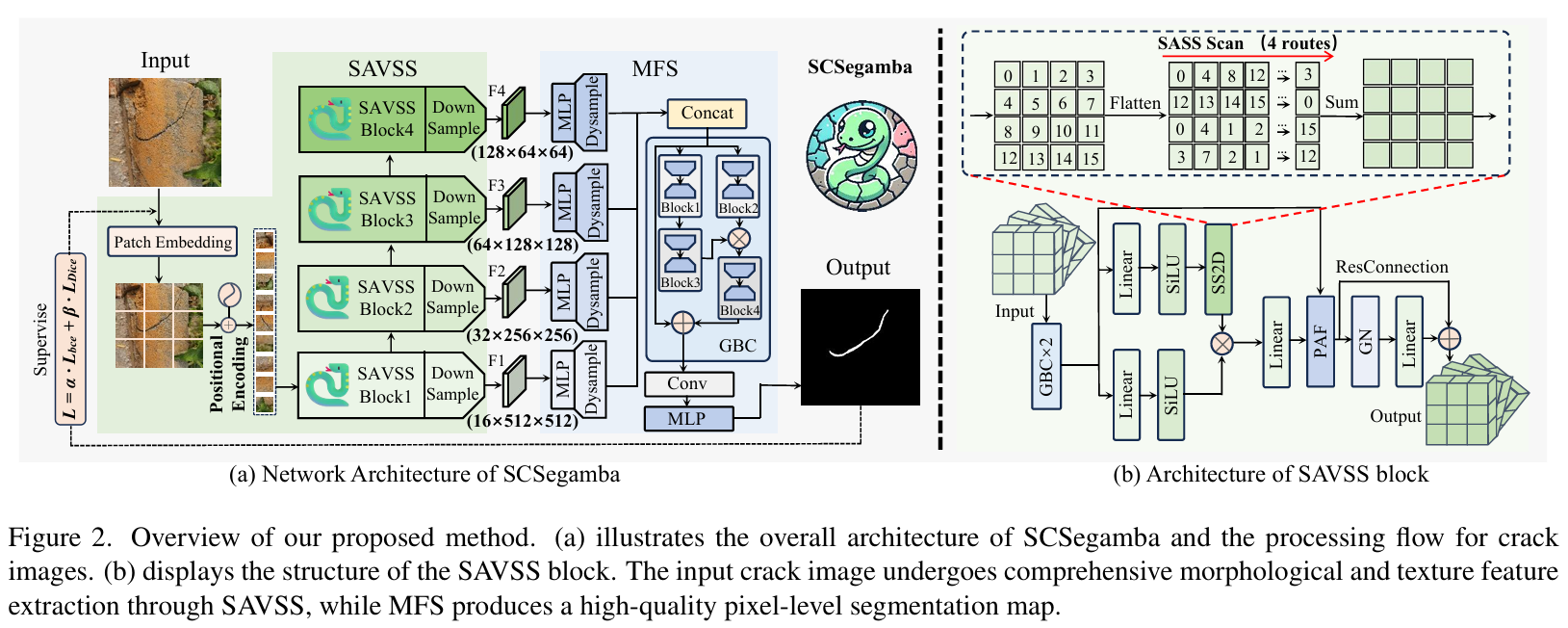
3.2 核心模块
模块一:轻量化门控瓶颈卷积 (Gated Bottleneck Convolution, GBC)
- 核心功能: 在保持低参数量和计算成本的同时,有效捕捉裂缝的形态学信息,并动态适应不同裂缝模式与复杂背景。
- 实现逻辑: 模块核心是瓶颈卷积 (Bottleneck Convolution),它通过低秩近似将特征映射到低维空间再映射回高维,显著降低计算量。同时,引入门控机制,将输入特征分别送入两个并行的瓶颈卷积分支,并将它们的输出通过Hadamard积(
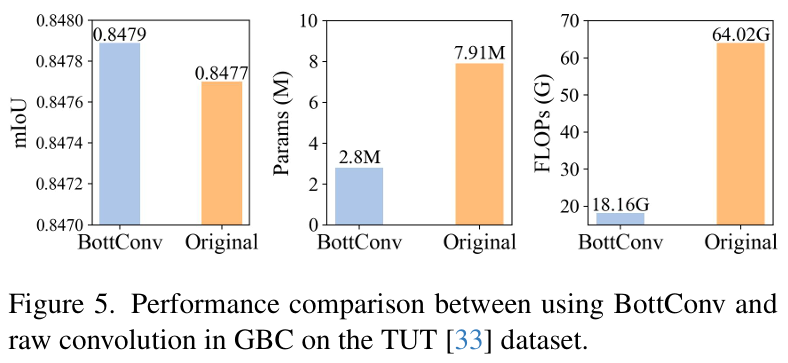
⊙)结合,从而动态地调整和精炼特征。最后通过残差连接保留原始信息。 - 优势: 相比标准卷积,GBC在几乎不损失性能的前提下,大幅减少了模型参数量和计算复杂度,如论文图5所示。门控设计增强了模型对多变裂缝细节的捕捉能力。
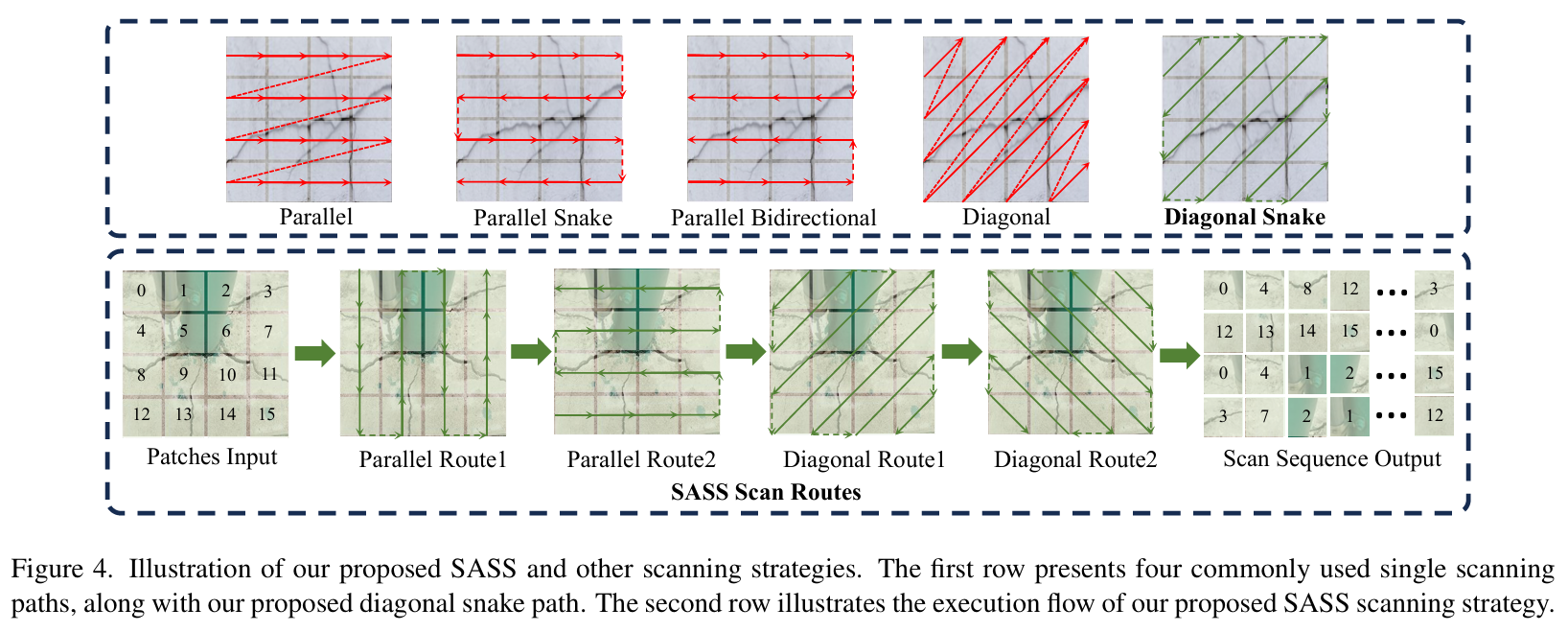
模块二:结构感知扫描策略 (SASS)
- 核心功能: 解决传统Mamba模型扫描策略(如并行扫描、对角扫描)难以捕捉裂缝不规则、多方向延伸拓扑结构的问题。
- 实现逻辑: SASS是一种专为视觉任务设计的二维选择性扫描策略 (SS2D)。它包含四条扫描路径:两条并行的蛇形扫描路径和两条对角线的蛇形扫描路径。这种组合方式使得模型能够同时从横、纵以及对角线方向上连续地捕捉像素间的依赖关系,更贴合裂缝的自然生长形态。这些扫描路径的输出被融合,以构建对裂缝纹理和拓扑更全面的感知。
zk=Pzk−1+Qwkz_k = \mathbf{P}z_{k-1} + \mathbf{Q}w_k zk=Pzk−1+Qwk
uk=Rzk+Swku_k = \mathbf{R}z_k + \mathbf{S}w_k uk=Rzk+Swk
其中,隐藏状态 zkz_kzk 通过SASS扫描策略捕获多方向的拓扑细节,最终得到输出 uku_kuk。 - 优势: 相比其他单一方向或非连续的扫描策略,SASS能够更好地保持裂缝区域的语义连续性,增强了模型对复杂纹理的感知和对背景噪声的抑制能力。
模块三:多尺度特征分割头 (MFS)
- 核心功能: 高效地融合来自编码器不同层级的多尺度特征,生成高质量的分割图。
- 实现逻辑: 该模块接收SAVSS编码器输出的四个不同尺度的特征图
F1, F2, F3, F4。每个特征图首先通过独立的MLP层进行处理,然后利用动态上采样 (Dynamic Upsampling) 恢复至原始分辨率。之后,所有上采样后的特征图被拼接(Concat)在一起,并依次通过一个GBC模块、一个卷积层和一个MLP层,最终生成单通道的分割结果。
o1=GBC(Concat(F1up,F2up,F3up,F4up))o_1 = \text{GBC}(\text{Concat}(F^{\text{up}}_1, F^{\text{up}}_2, F^{\text{up}}_3, F^{\text{up}}_4)) o1=GBC(Concat(F1up,F2up,F3up,F4up)) - 优势: 结合了MLP的轻量高效和GBC的强特征提取能力,在保持较低计算开销的同时,实现了对多尺度信息的有效聚合,显著提升了分割性能。
阅读原文,获取论文详细解读
04 模块适用任务
- 核心应用场景: 面向多场景(如沥青、混凝土、金属、砖块等)的像素级裂缝分割任务,尤其擅长处理具有复杂背景干扰、不规则形态和精细纹理的裂缝图像。
- 方法论核心: 本质思想是 将状态空间模型(Mamba)的序列建模能力与针对裂缝特性的结构化设计相结合。通过定制化的扫描策略(SASS)增强对空间拓扑的感知,并通过轻量化卷积模块(GBC)强化对局部形态的捕捉,从而实现性能与效率的平衡。
- 启发性拓展:
- 多模态融合: 可将该方法拓展至多模态输入(如结合红外、深度信息),利用SCSegamba强大的特征提取能力来处理更复杂的检测场景,进一步提升分割鲁棒性。
- 扫描策略的自适应优化: 未来的工作可以研究如何让模型根据输入图像的特征(如裂缝的主要走向)自适应地选择或加权不同的SASS扫描路径,实现更加动态和高效的特征提取。
05 实验结果与可视化分析
5.1 实验设置
- 数据集: Crack500, DeepCrack, CrackMap, 以及包含8种场景的多样化数据集TUT。
- 评估指标: ODS (Optimal Dataset Scale F-score), OIS (Optimal Image Scale F-score), Precision, Recall, F1 Score, mIoU。
- 对比基线:
- CNN/Transformer : RIND, SFIAN, CTCrackSeg, DTrCNet, Crackmer, SimCrack。
- Mamba : CSMamba, PlainMamba, MambaIR。
- 关键超参: 优化器 AdamW, 初始学习率 5e-4, 损失函数为BCE Loss和Dice Loss的加权和(权重比5:1),训练周期50 epochs, 输入尺寸512x512。
5.2 核心实验与结论
-
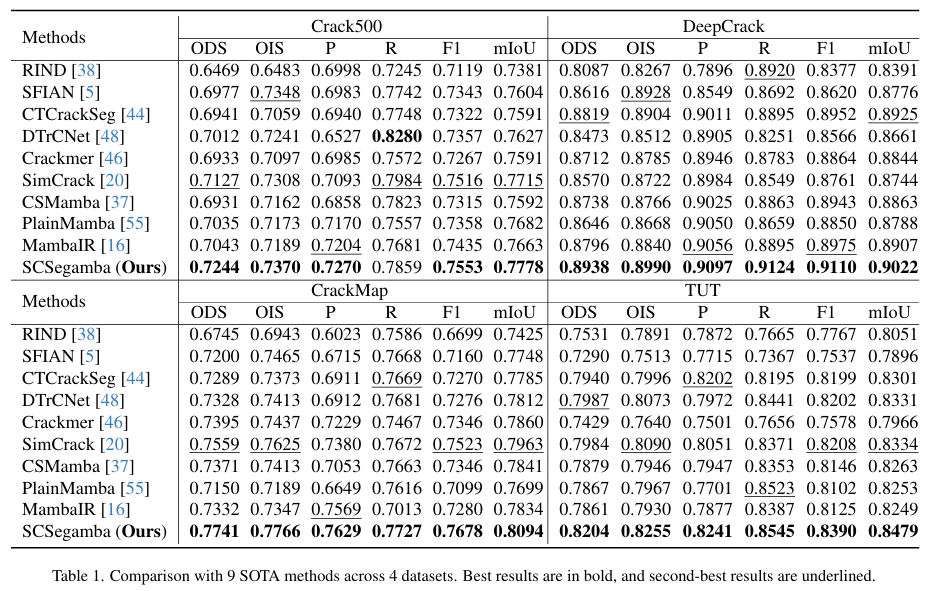
实验目的: 在包含多种场景和复杂干扰的TUT数据集上,验证SCSegamba模型相较于其他SOTA方法的综合性能、鲁棒性及轻量化优势。
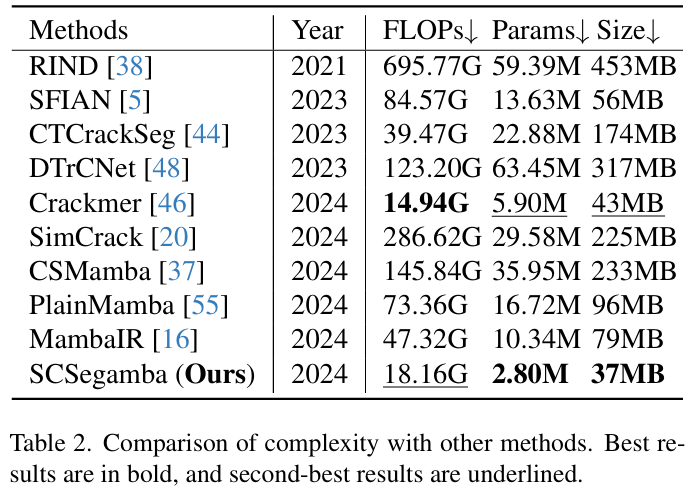
-
关键结果: 如表1所示,在TUT数据集上,SCSegamba在所有评估指标上均达到最优。其F1分数为0.8390,mIoU为0.8479,分别比次优方法高出2.21%和1.74%。同时,表2显示,SCSegamba的模型参数量仅为2.8M,模型大小为37MB,远低于多数高性能模型。图6的可视化结果表明,无论是在低对比度、复杂纹理还是强噪声背景下,SCSegamba都能生成更完整、更精确且噪声更少的分割图。

-
作者结论: 实验结果有力证明,SCSegamba通过其独特的SAVSS模块(结合GBC和SASS)和高效的MFS头,成功地在保持模型极度轻量化的同时,实现了对多场景裂缝形态和纹理的精准捕捉。该模型展现了卓越的分割性能和泛化能力,特别适合部署于资源受限的边缘设备。
06 即插即用模块
import numpy as np
import torch
import argparse
import os
import cv2
from datasets import create_dataset
from models import build_model
from main import get_args_parserparser = argparse.ArgumentParser('SCSEGAMBA FOR CRACK', parents=[get_args_parser()])
args = parser.parse_args()
args.phase = 'test'
args.dataset_path = '../data/TUT'if __name__ == '__main__':args.batch_size = 1t_all = []device = torch.device(args.device)test_dl = create_dataset(args)load_model_file = "./checkpoints/weights/checkpoint_TUT/checkpoint_TUT.pth"data_size = len(test_dl)model, criterion = build_model(args)state_dict = torch.load(load_model_file)model.load_state_dict(state_dict["model"])model.to(device)print("Load Model Successful!")suffix = load_model_file.split('/')[-2]save_root = "./results/results_test/" + suffixif not os.path.isdir(save_root):os.makedirs(save_root)with torch.no_grad():model.eval()for batch_idx, (data) in enumerate(test_dl):x = data["image"]target = data["label"]if device != 'cpu':x, target = x.cuda(), target.to(dtype=torch.int64).cuda()out = model(x)target = target[0, 0, ...].cpu().numpy()out = out[0, 0, ...].cpu().numpy()root_name = data["A_paths"][0].split("/")[-1][0:-4]target = 255 * (target / np.max(target))out = 255 * (out / np.max(out))# out[out >= 0.5] = 255# out[out < 0.5] = 0print('----------------------------------------------------------------------------------------------')print(os.path.join(save_root, "{}_lab.png".format(root_name)))print(os.path.join(save_root, "{}_pre.png".format(root_name)))print('----------------------------------------------------------------------------------------------')cv2.imwrite(os.path.join(save_root, "{}_lab.png".format(root_name)), target)cv2.imwrite(os.path.join(save_root, "{}_pre.png".format(root_name)), out)print("Finished!")
阅读原文,获取论文详细解读