基于 GEE 的融合 MODIS 地表反射率、MCD12Q1 土地覆盖与 TERRACLIMATE 气候数据的研究区净初级生产力(NPP)计算方法研究
目录
一、代码初始化与基础数据加载
(一)研究区可视化
(二)多源数据集加载(关键数据源拆解)
二、数据预处理模块(函数原理与操作细节)
(一)重投影与裁剪函数(reprojectandclip)
(二)气候数据预处理函数(solar_radiation_qc)
(三)预处理函数应用
三、核心工具函数模块(底层逻辑与应用场景)
(一)位提取函数(bitwiseExtract)—— 质量控制的 “核心引擎”
(二)质量控制函数 —— 剔除污染像素,保障数据可靠性
1. 联合数据质量控制(MOD09GA_QC_FC)—— 处理 TERRA+AQUA 联合数据
2. 单一数据质量控制(MOD09GA_QC)—— 处理 TERRA 上半年数据
(三)数据融合与均值计算函数
1. 内连接函数 —— 匹配同期 TERRA 与 AQUA 数据
2. 均值计算函数(Cal_terra_aqua_average_value)—— 消除单卫星数据缺失
四、MODIS 反射率数据处理流程(从原始数据到植被指数)
(一)数据重命名与内连接
(二)质量控制与均值合成
(三)植被指数计算(Cal_index)
五、土地覆盖参数构建(生态参数与土地类型匹配)
(一)光能利用效率(LUE)分配(generate_LUE)
(二)NDVI/SR 极值分配
(三)参数与植被指数数据匹配
六、NPP 计算核心模块(从环境胁迫到最终 NPP)
(一)环境胁迫因子计算(Calstress)
(二)光合有效辐射吸收比例(FPAR)计算(CalFPAR)
(三)NPP 最终计算(CalAPAR)
七、结果合成与输出
(一)时间尺度合成
(二)可视化与导出
八、代码关键注意事项
九、运行结果

若觉得代码对您的研究 / 项目有帮助,欢迎点击打赏支持!需要完整代码的朋友,打赏后可在后台私信(复制文章标题发给我),我会尽快发您完整可运行代码,感谢支持!
本代码基于 Google Earth Engine(GEE)平台,以 2023 年为时间窗口,融合多源遥感与气候数据,通过 “数据标准化→质量控制→参数计算→模型构建→结果输出” 的完整流程,实现研究区植被净初级生产力(NPP)的精细化估算。以下从代码逐模块逻辑、函数底层原理、数据流转关系等维度展开深度解析。
一、代码初始化与基础数据加载
(一)研究区可视化
Map.addLayer(table,{},'study area')
- 核心作用:将研究区矢量边界(
table,需提前在 GEE 中导入或绘制)添加到地图界面,用于后续数据裁剪与空间范围约束,方便可视化核对研究区位置与范围。 - 参数说明:
table为矢量数据集(如 Shapefile 导入后的 FeatureCollection),第二个参数{}为样式配置(此处默认无样式),第三个参数为图层名称。
(二)多源数据集加载(关键数据源拆解)
代码加载 4 类核心数据集,均限定 2023 年时间范围,各数据集的 “用途 - 波段选择 - 时间拆分逻辑” 如下表:
| 数据集类型 | 数据集 ID | 时间范围 | 选择波段 / 变量 | 核心用途 |
|---|---|---|---|---|
| 气候数据 | IDAHO_EPSCOR/TERRACLIMATE | 2023-01-01 至 2023-12-31 | pr(降水)、tmmn(最低温)、tmmx(最高温)、srad(太阳辐射) | 计算环境胁迫因子(水分、温度)、APAR |
| TERRA 卫星反射率 | MODIS/061/MOD09GA | 分两段:2023-01-01 至 2023-08-08(上半年)、2023-08-08 至 2023-12-31(下半年) | 7 个反射率波段(sur_refl_b01~b07)、质量控制波段(state_1km) | 计算植被指数(NDVI、SR 等) |
| AQUA 卫星反射率 | MODIS/061/MYD09GA | 2023-08-08 至 2023-12-31 | 同 MOD09GA | 与 TERRA 数据互补,提升下半年数据空间连续性 |
| 土地覆盖数据 | MODIS/061/MCD12Q1 | 全时间序列(默认最新) | LC_Type1(土地覆盖分类) | 分配 LUE、NDVI 极值等生态参数 |
时间拆分逻辑:将 TERRA 卫星数据拆分为 “上半年 - 下半年”,下半年数据与 AQUA 卫星数据匹配,是因为 AQUA 与 TERRA 卫星过境时间不同(前者下午、后者上午),联合使用可减少云层遮挡导致的数据缺失,提升下半年数据完整性。
二、数据预处理模块(函数原理与操作细节)
(一)重投影与裁剪函数(reprojectandclip)
function reprojectandclip(image){return image.reproject('EPSG:4326',null,500).clip(table)
}
- 核心目标:统一所有数据的 “坐标系 - 分辨率 - 空间范围”,避免后续计算因格式不兼容导致的错误。
- 函数拆解:
reproject('EPSG:4326',null,500):将影像重投影到 WGS84 坐标系(EPSG:4326),分辨率设为 500 米(第三个参数),第二个参数null表示不指定原点(默认使用影像原生原点)。.clip(table):用研究区矢量边界table裁剪影像,仅保留研究区内的像素,减少计算量并聚焦目标区域。
(二)气候数据预处理函数(solar_radiation_qc)
该函数是气候数据的 “单位转换 - 衍生变量计算 - 时间属性添加” 核心步骤,代码逻辑与物理意义如下:
function solar_radiation_qc(image){// 1. 单位转换:将原始数据换算为实际物理单位var srad = image.select('srad').multiply(0.1).multiply(2.592) // 太阳辐射:原始单位W/m²→MJ/m²(每日)var tmmn = image.select('tmmn').multiply(0.1) // 最低温:原始单位0.1℃→℃var tmmx = image.select('tmmx').multiply(0.1) // 最高温:同上var pr = image.select('pr') // 降水:原生单位mm,无需转换// 2. 衍生变量计算:平均温度、月生长指数var tmean = tmmn.add(tmmx).divide(2).rename('tmean') // 日平均温度 =(最低温+最高温)/2var I_month = tmean.divide(5).pow(1.514).rename('I_month') // 月生长指数:基于平均温度的经验公式// 3. 时间属性添加:为后续时间匹配提供标识var datestr = image.get('system:time_start') // 获取影像时间戳(毫秒级)var year = ee.Date(datestr).get('year') // 提取年份var month = ee.Date(datestr).get('month') // 提取月份var yearmonth = ee.Date(datestr).format('YYYYMM') // 格式化为“年-月”字符串(如202307)// 4. 返回处理后影像:保留原始波段,添加新变量与时间属性return image.addBands(srad,null,true).addBands(tmmn,null,true).addBands(tmmx,null,true).addBands(pr,null,true).addBands(tmean).addBands(I_month).set('year',year).set('month',month).set('yearmonth',yearmonth)
}
- 关键单位转换原理:TERRACLIMATE 数据集的太阳辐射原始单位为 “每日平均 W/m²”,需先乘以 0.1(数据集缩放系数),再乘以 2.592(1 W/m² = 2.592 MJ/m²/ 天,基于 1 天 = 86400 秒换算),最终得到 “每日太阳辐射总量(MJ/m²)”,用于后续 APAR 计算。
- 生长指数
I_month意义:该指数是基于温度的经验指标,反映植被生长的温度适宜性,数值越高表示温度越利于植被生长,后续用于水分胁迫因子计算。
(三)预处理函数应用
所有加载的数据集均通过map函数批量应用上述预处理函数,确保数据格式统一:
var Climate_collection = Climate_collection.map(solar_radiation_qc).map(reprojectandclip)
var MOD09GA_collection_fir2y = MOD09GA_collection_fir2y.map(reprojectandclip)
// 其余数据集(MOD09GA_collection_lateryears、MYD09GA_collection、Landcover_collection)同理
执行顺序:气候数据集先执行 solar_radiation_qc(单位转换与变量衍生),再执行reprojectandclip(重投影与裁剪);反射率、土地覆盖数据集仅需重投影与裁剪,因此直接执行reprojectandclip。
三、核心工具函数模块(底层逻辑与应用场景)
(一)位提取函数(bitwiseExtract)—— 质量控制的 “核心引擎”
MODIS 数据的质量控制波段(如state_1km)采用 “位编码” 存储(1 个字节 8 位,每 1-2 位代表一种质量信息),需通过位运算提取目标信息,该函数是质量控制的基础:
var bitwiseExtract = function(input, fromBit, toBit) {var maskSize = ee.Number(1).add(toBit).subtract(fromBit) // 计算需提取的“位长度”(如从0到1位,长度为2)var mask = ee.Number(1).leftShift(maskSize).subtract(1) // 构建掩码(如长度2时,掩码为11,二进制)return input.rightShift(fromBit).bitwiseAnd(mask) // 右移+与运算,提取目标位
}
举例说明:提取state_1km波段的 “云层状态”(0-1 位):
fromBit=0,toBit=1,maskSize=2,mask=1<<2 -1=3(二进制 11);- 将输入影像右移 0 位(即不移动),再与掩码 3 进行 “与运算”,最终得到 0-3 的数值(对应不同云层状态:0 = 无云,1 = 可能有云,2 = 确定有云,3 = 云覆盖)。
(二)质量控制函数 —— 剔除污染像素,保障数据可靠性
MODIS 反射率数据易受云层、云影、卷云干扰,需通过质量控制函数筛选有效像素,代码分两类函数处理不同数据场景:
1. 联合数据质量控制(MOD09GA_QC_FC)—— 处理 TERRA+AQUA 联合数据
function MOD09GA_QC_FC(image){// 第一步:处理TERRA卫星数据(MOD前缀波段)var qc_500_MOD = image.select('state_1km_MOD') // 提取TERRA质量控制波段// 基于位提取函数,筛选“无云-无云影-无卷云-云算法未触发”的像素var cloud_state_MOD = bitwiseExtract(qc_500_MOD,0,1).eq(0) // 云层状态=无云(0)var cloud_shadow_MOD = bitwiseExtract(qc_500_MOD,2,2).eq(0) // 云影=无(0)var cirrus_MOD = bitwiseExtract(qc_500_MOD,8,9).lte(1) // 卷云=无或可能无(0-1)var cloud_algorithm_MOD = bitwiseExtract(qc_500_MOD,10,10).eq(0) // 云检测算法未触发(0)var mask_MOD = cloud_state_MOD.and(cloud_shadow_MOD).and(cirrus_MOD).and(cloud_algorithm_MOD) // 组合掩码:同时满足所有条件为truevar MODBands = image.select('sur_refl_MOD_b0.').updateMask(mask_MOD).multiply(0.0001) // 应用掩码,反射率单位转换(原始16位整数→0-1浮点数)// 第二步:处理AQUA卫星数据(MYD前缀波段)——逻辑与TERRA完全一致var qc_500_MYD = image.select('state_1km_MYD')var cloud_state_MYD = bitwiseExtract(qc_500_MYD,0,1).eq(0)// ...(中间步骤省略,同TERRA)var MYDBands = image.select('sur_refl_MYD_b0.').updateMask(mask_MYD).multiply(0.0001)// 第三步:返回添加有效反射率波段的影像return image.addBands(MODBands,null,true).addBands(MYDBands,null,true)
}
- 关键掩码逻辑:
and运算确保只有 “无云、无云影、无卷云、云算法未触发” 的像素被保留,updateMask(mask_MOD)会将不满足条件的像素设为 “无数据”(透明),避免污染后续计算。 - 反射率单位转换:MOD09GA/MYD09GA 的反射率原始数据为 16 位整数,缩放系数为 0.0001,因此乘以 0.0001 后得到实际反射率(0-1 范围,0 = 无反射,1 = 全反射)。
2. 单一数据质量控制(MOD09GA_QC)—— 处理 TERRA 上半年数据
逻辑与MOD09GA_QC_FC一致,仅针对 TERRA 卫星的state_1km波段(无 MYD 前缀),最终输出筛选后的反射率波段(sur_refl_b0.),此处不再展开代码细节。
(三)数据融合与均值计算函数
1. 内连接函数 —— 匹配同期 TERRA 与 AQUA 数据
var innerJoin = ee.Join.inner() // 定义内连接(仅保留两边都有的记录)
var filterTimeEq = ee.Filter.equals({'leftField':'system:time_start','rightField':'system:time_start'
}) // 筛选条件:左右数据集的时间戳(system:time_start)相等
- 应用场景:将 TERRA 下半年数据(
MOD09GA_collection_lateryears)与 AQUA 数据(MYD09GA_collection)通过时间戳匹配,形成 “1 景 TERRA+1 景 AQUA” 的联合数据,后续计算均值以提升数据完整性。 - 连接结果:返回
FeatureCollection,每个 Feature 包含primary(TERRA 数据)和secondary(AQUA 数据)两个属性,需通过ee.Image.cat合并为单景影像。
2. 均值计算函数(Cal_terra_aqua_average_value)—— 消除单卫星数据缺失
var Cal_terra_aqua_average_value = function(terra,aqua){var data = terra.unmask(0).add(aqua.unmask(0)) // 无数据像素设为0后求和var mask = terra.mask().add(aqua.mask()) // 计算掩码求和(0=双无数据,1=单有数据,2=双有数据)var mask_for_multiply = mask.where(mask.eq(0),10).pow(-1) // 无数据像素设为0.1(避免除以0),其他设为1/maskvar mask_for_update = mask.where(mask.gt(0),1) // 有数据像素保留,无数据像素屏蔽var average_value = data.multiply(mask_for_multiply) // 求和后除以有效数据个数(实现均值计算)var average_value = average_value.updateMask(mask_for_update) // 应用最终掩码return average_value
}
- 核心逻辑:解决 “单卫星数据缺失” 问题,例如某像素 TERRA 有数据、AQUA 无数据,则均值为 TERRA 数据;双卫星均有数据则取算术平均;双无数据则设为无数据。
- 举例说明:若
terra某像素值为 0.6(有数据,掩码 1),aqua该像素无数据(掩码 0):data=0.6+0=0.6,mask=1+0=1;mask_for_multiply=1/1=1,average_value=0.6*1=0.6(保留 TERRA 数据)。
四、MODIS 反射率数据处理流程(从原始数据到植被指数)
(一)数据重命名与内连接
// TERRA下半年数据重命名:添加MOD前缀,与AQUA数据区分
var MOD09GA = MOD09GA_collection_lateryears.select(['sur_refl_b01','sur_refl_b02',...,'state_1km'],['sur_refl_MOD_b01','sur_refl_MOD_b02',...,'state_1km_MOD'])
// AQUA数据重命名:添加MYD前缀
var MYD09GA = MYD09GA_collection.select(['sur_refl_b01',...,'state_1km'],['sur_refl_MYD_b01',...,'state_1km_MYD'])
// 内连接匹配同期数据
var innerJoinedMOD09 = innerJoin.apply(MOD09GA, MYD09GA, filterTimeEq)
// 合并为单景影像集合
var MODIS_09 = ee.ImageCollection(innerJoinedMOD09.map(function(feature){return ee.Image.cat(feature.get('primary'), feature.get('secondary'))
}))
重命名意义:避免 TERRA 与 AQUA 数据的波段名称冲突(如均为sur_refl_b01),后续质量控制可通过前缀快速区分。
(二)质量控制与均值合成
// 应用联合数据质量控制函数
var MODIS09GA_qc = MODIS_09.map(MOD09GA_QC_FC).select(['sur_refl_MOD_b01',...,'sur_refl_MYD_b07'])
// TERRA上半年数据质量控制
var MOD09GA_collection_fir2y_qc = MOD09GA_collection_fir2y.map(MOD09GA_QC).select(['sur_refl_b01',...,'sur_refl_b07'],['MODIS_Band1',...,'MODIS_Band7'])
// 下半年数据均值合成:计算TERRA与AQUA同期波段均值
var MODIS09GA_average = MODIS09GA_qc.map(sameday_average).select(['MODIS_Band1',...,'MODIS_Band7'])
// 合并上半年与下半年数据,形成2023年完整反射率数据集
var MODIS09GA_Daily_averaged = MOD09GA_collection_fir2y_qc.merge(MODIS09GA_average)
sameday_average函数逻辑:对 TERRA 与 AQUA 的 7 个反射率波段(如sur_refl_MOD_b01与sur_refl_MYD_b01)分别调用Cal_terra_aqua_average_value计算均值,并重命名为MODIS_Band1~MODIS_Band7,确保与上半年数据波段名称一致。- 数据合并意义:
merge函数将上半年(仅 TERRA)与下半年(TERRA+AQUA 均值)数据合并,形成 2023 年完整的 “日尺度” 反射率数据集(MODIS09GA_Daily_averaged),为后续月尺度植被指数计算提供基础。
(三)植被指数计算(Cal_index)
基于反射率波段计算 5 类核心植被指数,用于表征植被生长状态,代码逻辑与物理意义如下:
function Cal_index(image){// 1. 提取所需波段(根据MOD09GA波段含义匹配)var red = image.select('MODIS_Band1') // Band1:红波段(620-670nm)——植被叶绿素吸收峰var Nir = image.select('MODIS_Band2') // Band2:近红外波段(841-876nm)——植被叶片散射峰var Blue = image.select('MODIS_Band3') // Band3:蓝波段(459-479nm)——大气校正辅助var Green = image.select('MODIS_Band4') // Band4:绿波段(545-565nm)——植被反射次峰var Swir = image.select('MODIS_Band6') // Band6:短波红外波段(1628-1652nm)——植被水分敏感波段// 2. 计算植被指数var NDVI = Nir.subtract(red).divide(Nir.add(red)) // 归一化植被指数:(NIR-R)/(NIR+R)——反映植被覆盖度与活力var NDVI = NDVI.where(NDVI.gt(1),1).where(NDVI.lt(-1),-1) // 限定范围:理论上NDVI为-1~1,超出部分截断var NDWI = Green.subtract(Nir).divide(Green.add(Nir)) // 归一化水体指数:(G-NIR)/(G+NIR)——区分水体与植被var NDWI = NDWI.where(NDWI.gt(1),1).where(NDWI.lt(-1),-1)var NDBI = Swir.subtract(Nir).divide(Swir.add(Nir)) // 归一化建筑指数:(SWIR-NIR)/(SWIR+NIR)——区分建筑与植被var NDBI = NDBI.where(NDBI.gt(1),1).where(NDBI.lt(-1),-1)var NIRV = NDVI.multiply(Nir) // 近红外植被指数:NDVI*NIR——同时反映植被覆盖与生物量var SR = ee.Image(1).add(NDVI).divide(ee.Image(1).subtract(NDVI)) // 简单比值指数:(1+NDVI)/(1-NDVI)——放大植被差异// 3. 返回添加指数波段的影像return image.addBands(NDVI.rename('NDVI')).addBands(NDWI.rename('NDWI')).addBands(NDBI.rename('NDBI')).addBands(NIRV.rename('NIRV')).addBands(SR.rename('SR'))
}
- 关键指数意义:NDVI 是 NPP 计算的核心输入(用于计算 FPAR),SR 是 NDVI 的衍生指数(避免 NDVI 在高植被覆盖区饱和),其他指数用于辅助筛选植被区域(如 NDWI 剔除水体、NDBI 剔除建筑)。
- 范围限定原因:由于大气噪声或数据误差,部分像素 NDVI 可能超出 - 1~1 范围,需通过
where函数截断,避免后续 FPAR 计算出现异常值。
五、土地覆盖参数构建(生态参数与土地类型匹配)
基于 MODIS 土地覆盖数据(LC_Type1),为不同土地覆盖类型分配 “光能利用效率(LUE)-NDVI 极值 - SR 极值”,这些参数是 NPP 计算的关键常数,代码通过 5 个函数实现:
(一)光能利用效率(LUE)分配(generate_LUE)
LUE 是植被将光合有效辐射转化为有机碳的效率(单位:gC/MJ),不同植被类型 LUE 差异显著:
function generate_LUE(image){var image = image.where(image.eq(3),0.485) // 3=落叶阔叶林→LUE=0.485.where(image.eq(1),0.389) // 1=常绿针叶林→LUE=0.389.where(image.eq(4),0.692) // 4=落叶针叶林→LUE=0.692.where(image.eq(2),0.985) // 2=常绿阔叶林→LUE=0.985// ...(中间13类土地覆盖类型省略,如草地、农田等,LUE均设为0.542左右).where(image.eq(17),0.542) // 17=岩石/裸地→LUE=0.542(极低)return image.toFloat()
}
参数来源:LUE 数值参考已有文献(如 MODIS NPP 产品算法),常绿阔叶林 LUE 最高(0.985),裸地最低(0.542),符合植被生理特性。
(二)NDVI/SR 极值分配
NDVI 极值(NDVImin/NDVImax)和 SR 极值(SRmin/SRmax)用于计算 FPAR,反映不同植被类型的 “最小 - 最大” 生长状态:
set_NDVImin:所有土地覆盖类型的NDVImin统一设为 0.023(参考裸地最小 NDVI 值,代表无植被生长的基线)。set_NDVImax:随植被类型变化,如常绿阔叶林(2)为 0.676,落叶阔叶林(3)为 0.738,裸地(17)为 0.634(低于植被类型)。set_SRmin:所有类型统一设为 1.05(SR=1 对应 NDVI=0,1.05 为轻微正植被覆盖的基线)。set_SRmax:与NDVImax趋势一致,如常绿阔叶林(2)为 5.17,落叶阔叶林(3)为 6.63,裸地(17)为 4.44。
(三)参数与植被指数数据匹配
通过 5 次内连接,将植被指数数据(MODIS09_indices)与 LUE、NDVImin、NDVImax、SRmin、SRmax 按 “年份” 匹配(确保同一年份的参数与数据对应),最终形成包含 “植被指数 - 生态参数” 的综合数据集(Indices_LLM),代码逻辑如下:
// 1. 为所有参数数据集添加年份属性(与植被指数数据的年份匹配)
var LUE = LUE.map(setyear) // setyear函数:提取影像时间戳,添加year属性
var NDVImin = NDVImin.map(setyear)
// ...(NDVImax、SRmin、SRmax同理)
var MODIS09_indices = MODIS09_indices.map(setyear)// 2. 定义年份匹配筛选条件
var filterTimeEqminmax = ee.Filter.equals({'leftField':'year','rightField':'year'
})// 3. 多次内连接:逐步添加参数
var innerJoinedIL_LUE = innerJoin.apply(MODIS09_indices, LUE, filterTimeEqminmax)
var Indices_LUE = ee.ImageCollection(innerJoinedIL_LUE.map(function(feature){return ee.Image.cat(feature.get('primary'), feature.get('secondary'))
}))
// ...(后续4次内连接省略,依次添加NDVImin、NDVImax、SRmin、SRmax)
var Indices_LLM = ee.ImageCollection(innerJoinedILL_NNSR.map(function(feature){return ee.Image.cat(feature.get('primary'), feature.get('secondary'))
}))
连接必要性:土地覆盖数据可能为多年份(如Landcover_collection包含 2001-2023 年数据),通过年份匹配确保 2023 年的植被指数数据仅与 2023 年的土地覆盖参数结合,避免跨年份误差。
六、NPP 计算核心模块(从环境胁迫到最终 NPP)
NPP 计算遵循 “环境胁迫因子→FPAR→APAR→实际 LUE→NPP” 的逻辑链,代码通过 3 个函数实现:
(一)环境胁迫因子计算(Calstress)
环境胁迫因子包括水分胁迫(Wstress)和温度胁迫(Tstress1/Tstress2),量化环境条件对植被光合的抑制程度(取值 0~1,1 = 无胁迫,0 = 完全抑制):
function Calstress(image){// 1. 提取所需输入变量var I = image.select('I') // 年生长指数(由月I_month求和得到)var tmean = image.select('tmean') // 月平均温度var pre = image.select('pr') // 月降水var Topt = image.select('Topt') // 最适温度(7月平均温度,提前计算)// 2. 计算水分胁迫因子(Wstress)// 2.1 计算系数a:基于年生长指数的经验公式,反映温度对蒸散的影响var a = ee.Image().expression('(0.6751 * I ** 3 - 77.1 * I ** 2 + 17920 * I + 482390) / 1000000',{I:I}).rename('a')// 2.2 计算潜在蒸散(Ep0):Penman-Monteith简化公式,反映潜在水分消耗var Ep0 = ee.Image().expression('16 * (10 * d / b) ** c',{d:tmean,b:I,c:a}).rename('Ep0')// 2.3 计算净辐射(Rn):基于降水与潜在蒸散的比值,反映实际水分可利用性var Rn = ee.Image().expression('((a * b) ** 0.5) * (0.369 + 0.598 * (a / b) ** 0.5)',{a:Ep0,b:pre})// 2.4 计算实际蒸散(EET):反映植被实际水分消耗var EET = ee.Image().expression('a * b * (a ** 2 + b ** 2 + a + b) / ((a + b) * (a ** 2 + b ** 2))',{a:pre,b:Rn})// 2.5 计算可能蒸散(PET):潜在与实际蒸散的平均值var PET = ee.Image().expression('(a + b) / 2',{a:EET,b:Ep0})// 2.6 水分胁迫因子:EET/PET的线性变换,取值0.5~1(水分充足时接近1)var Wstress = ee.Image().expression('0.5 + 0.5 * (a / b)',{a:EET,b:PET}).rename('Wstress')// 3. 计算温度胁迫因子(Tstress1、Tstress2)// 3.1 Tstress1:基于最适温度的基础胁迫,反映长期温度适宜性var Tstress1 = ee.Image().expression('0.8 + 0.02 * a - 0.0005 * a ** 2',{a:Topt})var Tstress1 = Tstress1.where(tmean.lt(-10),0).rename('Tstress1') // 温度低于-10℃时完全抑制// 3.2 Tstress2:基于实际温度与最适温度的偏差,反映短期温度波动影响var Tsigma2 = ee.Image().expression('1.184 / (1 + exp(0.2 * (a - 10 - b))) * 1 / (1 + exp(0.3 * (b - a - 10)))',{a:Topt,b:tmean})var Tsigma3 = ee.Image(1.184).divide(ee.Image(1).add(ee.Image(-2).exp())).multiply(ee.Image(1).divide(ee.Image(1).add(ee.Image(-3).exp())))var diff = tmean.subtract(Topt) // 实际温度与最适温度的差值var diff1 = diff.where(diff.lt(-13),0).where(diff.gte(-13).and(diff.lte(10)),1).where(diff.gt(10),0) // 温度偏差筛选var diff2 = diff.where(diff.gte(-13).and(diff.lte(10)),1).where(diff.gt(10),0).where(diff.lt(-13),0)var Tstress2 = Tsigma2.multiply(diff1).add(Tsigma3.multiply(diff2)).rename('Tstress2')// 4. 返回添加胁迫因子的影像return image.addBands(Wstress).addBands(Tstress1).addBands(Tstress2).clip(table)
}
胁迫因子逻辑:Wstress反映水分供需平衡(降水充足时接近 1,干旱时接近 0.5);Tstress1反映最适温度的基础影响(如热带植被最适温度高,Tstress1接近 1);Tstress2反映短期温度偏离的影响(如夏季高温或冬季低温导致Tstress2下降)。
(二)光合有效辐射吸收比例(FPAR)计算(CalFPAR)
FPAR 是植被吸收的光合有效辐射(PAR)占总 PAR 的比例(取值 0~1),基于 NDVI 和 SR 的极值模型计算:
function CalFPAR(image){// 1. 提取所需变量var NDVI = image.select('NDVI')var SR = image.select('SR')var NDVImin = image.select('NDVI_min')var NDVImax = image.select('NDVI_max')var SRmin = image.select('SR_min')var SRmax = image.select('SR_max')// 2. 基于NDVI和SR分别计算FPARvar FPAR1 = NDVI.subtract(NDVImin).divide(NDVImax.subtract(NDVImin)).multiply(ee.Image(0.949)).add(0.001) // NDVI-based FPARvar FPAR2 = SR.subtract(SRmin).divide(SRmax.subtract(SRmin)).multiply(ee.Image(0.949)).add(0.001) // SR-based FPAR// 3. 融合两类FPAR,限定范围var FPAR = FPAR1.multiply(0.5).add(FPAR2.multiply(0.5)) // 等权重平均,避免单一指数误差var FPAR = FPAR.where(FPAR.gt(0.95),0.95).where(FPAR.lt(0.05),0.05).rename('FPAR') // 限定0.05~0.95(排除极端值)return image.addBands(FPAR).toFloat()
}
计算原理:当 NDVI/SR 达到NDVImax/SRmax时,FPAR 达到最大值 0.95(植被完全覆盖,吸收 95% 的 PAR);当 NDVI/SR 为NDVImin/SRmin时,FPAR 为 0.05(裸地或无植被,仅吸收 5% 的 PAR)。
(三)NPP 最终计算(CalAPAR)
NPP 是植被在一定时间内固定的有机碳总量(单位:gC/m²/ 月),计算公式为:NPP = APAR × 实际LUE,代码逻辑如下:
function CalAPAR(image){// 1. 计算光合有效辐射(APAR):植被吸收的PAR总量var FPAR = image.select('FPAR')var Sol = image.select('srad') // 月太阳辐射总量(MJ/m²/月)var APAR = FPAR.multiply(Sol).multiply(ee.Image(0.5)).rename('APAR') // 0.5:总太阳辐射中PAR占比约50%// 2. 计算实际光能利用效率(yupson):考虑环境胁迫的LUEvar LUE = image.select('LUE') // 潜在LUE(土地覆盖类型决定)var Wstress = image.select('Wstress') // 水分胁迫var Tstress1 = image.select('Tstress1') // 温度胁迫1var Tstress2 = image.select('Tstress2') // 温度胁迫2var yupson = Tstress1.multiply(Tstress2).multiply(Wstress).multiply(LUE).rename('yupson') // 实际LUE=潜在LUE×胁迫因子乘积// 3. 计算NPP:APAR(MJ/m²/月)× 实际LUE(gC/MJ)→ gC/m²/月var NPP = APAR.multiply(yupson).rename('NPP')return image.addBands(NPP).addBands(yupson).addBands(APAR).toFloat()
}
单位逻辑:APAR 单位为MJ/m²/月(光合有效辐射总量),实际 LUE 单位为gC/MJ(每吸收 1 MJ PAR 固定的有机碳),两者相乘得到 NPP(gC/m²/月),符合 NPP 的物理定义。
七、结果合成与输出
(一)时间尺度合成
- 月尺度合成:对
Indices_LLM(植被指数 + 生态参数)按月份进行 “最大值合成”(makeMonthlyComposite_MOD09),即每个月保留各像素的最大植被指数值,减少云残留或数据缺失的影响。 - 年尺度合成:对月尺度 NPP 数据按年份进行 “求和合成”(
makeYearlyComposite_NPP),得到年尺度 NPP(NPP_Year),即全年各月 NPP 累加值(单位:gC/m²/ 年)。
(二)可视化与导出
// 1. 可视化参数设置
var nppVis = {min: 0.0,max: 10.0,palette: ['bbe029', '0a9501', '074b03'], // 浅绿色→深绿色:NPP从低到高
};
Map.addLayer(NPP_Year,gppVis,'NPP') // 在地图上显示年尺度NPP// 2. 导出年平均NPP到Google Drive
Export.image.toDrive({image: NPP_Year.mean(), // 计算2023年年平均NPP(若为多年数据则取均值)description: 'lh-NPP', // 导出文件名称region: table, // 导出范围(研究区)scale: 500, // 分辨率500米(与输入数据一致)maxPixels: 1e13, // 最大像素数(支持大范围区域导出,避免超出GEE限制)folder: 'npp_year' // 导出到Google Drive的文件夹名称})
导出说明:NPP_Year.mean()计算 2023 年的年平均 NPP(若代码扩展为多年数据,可计算多年均值);maxPixels:1e13是 GEE 导出影像的最大像素限制,确保研究区较大时仍能正常导出。
八、代码关键注意事项
- 数据格式统一性:所有数据必须统一坐标系(EPSG:4326)、分辨率(500 米)和空间范围(
table),否则会导致叠加计算错误。 - 质量控制严格性:MODIS 数据的云污染是主要误差来源,需确保
cloud_state、cloud_shadow、cirrus等掩码条件正确(参考 MODIS 官方质量控制文档)。 - 参数合理性:LUE、NDVI 极值等参数需根据研究区植被类型调整(如热带地区与温带地区的
Topt不同),直接使用代码默认值可能导致误差。 - 时间匹配准确性:内连接时需确保匹配字段(如
system:time_start、year)正确,避免跨时间尺度的数据混合(如将 2022 年土地覆盖参数与 2023 年植被指数结合)。
九、运行结果
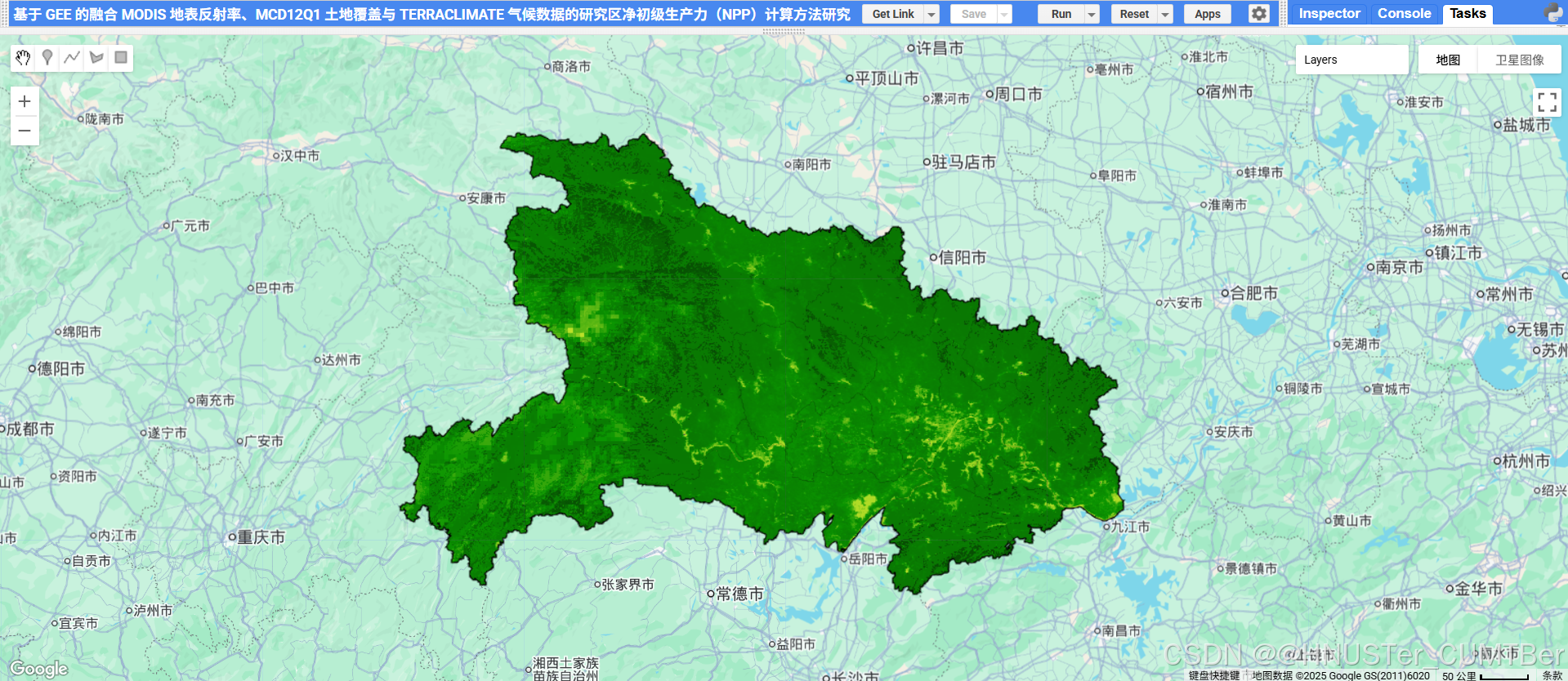
若觉得代码对您的研究 / 项目有帮助,欢迎点击打赏支持!需要完整代码的朋友,打赏后可在后台私信(复制文章标题发给我),我会尽快发您完整可运行代码,感谢支持!