构建AI智能体:七十九、从SVD的理论到LoRA的实践:大模型低秩微调的内在逻辑
一. 什么是奇异值分解
1. 核心思想
英文简称SVD,直观的理解就是拆解与重组,任何复杂的操作都可以被拆解成一系列简单步骤的组合。比如,一个复杂的舞蹈动作,可以拆解为“抬手”、“转身”、“跳跃”等基本动作。
SVD做的正是这件事:它将任何一个复杂的矩阵,可以想象成一个装满数字的二维表格,拆解成三个简单、有特殊意义的矩阵的乘积。
2. 通俗理解
光靠概念释义是真的很晦涩,举几个生活示例,帮助大家理解;
2.1 做一道水果沙拉
想象我们要做一道复杂的水果沙拉,里面有苹果、香蕉、橙子、草莓...
- 没有SVD的做法:
- 直接把所有水果胡乱混在一起 → 结果是一团糟,看不出每种水果的贡献
- 有SVD的聪明做法:
- 分类整理(Vᵀ步骤):把所有水果按种类分开摆放
- 称重排序(Σ步骤):给每种水果称重,按重量从大到小排列
- 苹果:500克 ;香蕉:300克 ;橙子:150克 ;草莓:50克
- 重新摆盘(U步骤):按照重要程度重新摆盘展示
这就是SVD,它能帮我们把混乱的数据整理得清清楚楚。
2.2 挑选优秀员工
假设我们要挑选公式的优秀员工,候选人在5个方面的得分:
原始数据(很混乱):
- 张三 = [能力85, 沟通70, 团队意识65, 英语80, 其他75]
- 李四 = [能力90, 沟通60, 团队意识80, 英语75, 其他65]
- 王五 = [能力70, 沟通85, 团队意识70, 英语90, 其他80]
SVD帮我们理清思路:
- 1. 分析发现:对公司来说,真正重要的是:
- 技术能力(权重0.9)← 最大的奇异值
- 沟通能力(权重0.8)← 第二奇异值
- 团队意识(权重0.7)← 第三奇异值
- 其他都是次要的
- 2. 综合计算评估:
- 张三 = 85×0.9 + 70×0.8 + 80×0.7 = 76.5 + 56 + 56 = 188.5
- 李四 = 90×0.9 + 60×0.8 + 75×0.7 = 81 + 48 + 52.5 = 181.5
- 王五 = 70×0.9 + 85×0.8 + 90×0.7 = 63 + 68 + 63 = 194
通过SVD帮我们找到了总体评价合适的人选。
综合来看,SVD本质上就是一种"抓住重点、忽略次要"的智慧思维方式。
二、奇异值的计算公式
1. 公式详解
奇异值分解的完整公式是:
A = U * Σ * Vᵀ
A - 原始矩阵
我们要分解的对象,就是我们想要分析的原始数据,可以是:一张图片、用户评分表、词汇文章矩阵等,维度:m × n(m行,n列)
示例:
假设我们有一个简单的2×3用户-电影评分矩阵:
动作片 喜剧片 爱情片
A = [ 5, 1, 2 ] 用户1
[ 1, 4, 3 ] 用户2
U - 左奇异向量矩阵
- 含义:可以被理解为一个“行”空间里的“标准姿势”集合。它告诉我们,数据在结果空间中的主要方向是什么
- 性质:正交矩阵(就像一组完美的坐标轴)
- 所有列向量都是单位长度(长度为1)
- 所有列向量相互垂直
- 维度:m × m
- 直观理解:
- U告诉我们用户们的"口味类型",比如:
- 第1列:可能代表"动作片爱好者"方向
- 第2列:可能代表"喜剧片爱好者"方向
- 第3列:可能代表"爱情片爱好者"方向
Σ (Sigma) - 奇异值矩阵
重要性权重表,这是整个分解的核心!它是一个对角矩阵,只有对角线上有数字,其他位置都是0。这些数字就叫做奇异值,可以把它们想象成每个标准姿势的重要性或能量权重。奇异值总是从大到小排列,维度:m × n
Σ矩阵长这样:
Σ = [ σ₁, 0, 0, ..., 0 ]
[ 0, σ₂, 0, ..., 0 ]
[ 0, 0, σ₃, ..., 0 ]
[ ... ... ... ... ... ]
[ 0, 0, 0, ..., σₙ ]
σ₁, σ₂, σ₃... 就是奇异值,它们满足:σ₁ ≥ σ₂ ≥ σ₃ ≥ ... ≥ 0
Vᵀ - 右奇异向量矩阵的转置
可以被理解为一个 “列”空间里的“标准姿势”集合。它告诉你,数据在原始空间中的主要成分是什么,维度:n × n
直观理解:
- Vᵀ告诉我们电影们的"类型特征",比如:
- 第1行:可能代表"纯动作片"特征
- 第2行:可能代表"浪漫喜剧"特征
- 第3行:可能代表"文艺爱情片"特征
2. 具体的数字例子
让我们用一个极简单的例子来验证公式。
假设:
A = [ 3, 0 ][ 0, 2 ]经过SVD分解后,我们会得到:
U = [ 1, 0 ][ 0, 1 ]Σ = [ 3, 0 ] # 奇异值是3和2[ 0, 2 ]Vᵀ = [ 1, 0 ][ 0, 1 ]现在验证 A = U * Σ * Vᵀ:
计算过程:
1. 先计算 Σ * Vᵀ:
[ 3, 0 ] [ 1, 0 ] [ 3×1+0×0, 3×0+0×1 ] [ 3, 0 ]
[ 0, 2 ] × [ 0, 1 ] = [ 0×1+2×0, 0×0+2×1 ] = [ 0, 2 ]2. 再计算 U * (Σ * Vᵀ):
[ 1, 0 ] [ 3, 0 ] [ 1×3+0×0, 1×0+0×2 ] [ 3, 0 ]
[ 0, 1 ] × [ 0, 2 ] = [ 0×3+1×0, 0×0+1×2 ] = [ 0, 2 ]结果正是原来的A矩阵!
3. 公式的深层含义
公式的另一种写法,A = U * Σ * Vᵀ 可以展开写成:
A = σ₁u₁v₁ᵀ + σ₂u₂v₂ᵀ + σ₃u₃v₃ᵀ + ...
其中:
- u₁, u₂, u₃... 是U的列向量
- v₁, v₂, v₃... 是V的列向量
- σ₁, σ₂, σ₃... 是对应的奇异值
这表示原始矩阵A可以看作是一系列"层次"的叠加,每个层次的重要性由奇异值决定。
示例:图像压缩的例子,假设A是一张人脸图片:
- σ₁u₁v₁ᵀ:第一层,包含最基本的轮廓(脸型)
- σ₂u₂v₂ᵀ:第二层,增加五官位置
- σ₃u₃v₃ᵀ:第三层,增加细节纹理
- ... 越往后越次要
关键理解:如果我们只保留前k项,就得到了压缩图像!
A ≈ σ₁u₁v₁ᵀ + σ₂u₂v₂ᵀ + ... + σₖuₖvₖᵀ
4. 公式的核心思想
A = U * Σ * Vᵀ 的真正含义是:
- 任何复杂的数据变换,都可以分解为:
- 旋转/反射 (Vᵀ):找到最佳观察角度
- 缩放 (Σ):沿着坐标轴方向进行不同程度的拉伸/压缩
- 旋转/反射 (U):调整到最终的输出方向
- 奇异值σᵢ 就是各个方向上的缩放因子,它们的大小直接反映了该方向的重要性。
三、SVD的低秩近似
1. 概念理解
1.1 秩是什么
简单来说,秩就是真正有信息量的维度数量
1.2 理解低秩近似
就是用更少的笔墨,抓住最重要的特征,忽略不重要的细节,可以理解为用“简笔画”代替“高清照片”
1.3 低秩近似的本质
发现原始数据虽然看起来复杂(高维度),但实际上可以用更少的维度来描述。
就像发现:
- 1000页的报告,其实核心观点只有3条
- 100万像素的照片,其实主要信息集中在少数模式中
1.4 分离精华和糟粕
SVD最强大的地方在于,它通过奇异值的大小,自动帮我们区分了信息的精华和糟粕。
回忆一下前面示例中 Σ 矩阵里的奇异值是从大到小排列的:
- 大的奇异值:对应了数据中最主要、最核心的模式和特征。比如,在一张人脸图片中,它可能对应了脸部的基本轮廓和五官位置。
- 小的奇异值:对应了数据中次要的细节、细微的纹理,甚至是噪声。比如,人脸上的痘痘、光线造成的阴影。
2. 示例:图像压缩
让我们用一张灰度图片来演示,一张图片在电脑里就是一个巨大的数字矩阵,每个数字代表一个像素点的亮度。
假设我们有一张原图 A,对它进行SVD后,我们得到 U, Σ, Vᵀ。
- 完全重建:如果我们使用所有的奇异值,我们可以精确地、无损地还原出原图 A。
- A = U * Σ * Vᵀ
- 魔法时刻:截断SVD:现在我们只保留前K个最大的奇异值,比如K=1, 10, 50, 100……然后把后面的奇异值全部设为0。然后用这三个被“裁剪”过的矩阵来近似原图:
- A ≈ U_k * Σ_k * V_kᵀ
这里有哪些重要的区别特征:
- K=1:我们只用了最重要的一个模式来重构图片。图片会非常模糊,只能看到最基本的轮廓。
- K=10:我们用了前10个重要的模式。图片变得清晰一些,轮廓更明显了。
- K=50:我们用了前50个重要的模式。图片已经非常接近原图,人眼几乎看不出区别,但存储这个图片所需的数据量大大减少!
为什么数据量减少了:
- 原图矩阵 A 大小是 m * n。
- 近似图需要存储 U_k, Σ_k, V_kᵀ,大小分别是 m*k, k*1, n*k。
- 总存储量是 k*(m + n + 1)。
- 当 k 远小于 m 和 n 时,k*(m+n+1) 就远小于 m*n,这就实现了压缩。
这个过程,就像我们整理房间时的筛选步骤:只保留最重要的物品,舍弃不重要的,空间自然就腾出来了。
用一段代码来完整展示这个过程:
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import os# 设置中文字体,防止乱码
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用黑体显示中文
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号print("=== SVD图像压缩演示 ===\n")# 1. 读取图像并转换为灰度图
print("1. 读取图像...")
image_path = "svd_demo_image.jpg" # 请准备一张图片,或者我们将创建一个示例图# 如果没有图片,我们创建一个简单的测试图案
try:img = Image.open(image_path).convert('L') # 转换为灰度图print(f" 已从 '{image_path}' 加载图像。")
except:print(" 未找到图片,创建一个示例图案...")# 创建一个200x200的测试图像:一个简单的渐变和形状x, y = np.ogrid[0:200, 0:200]img_array = (x/200 * 255).astype(np.uint8) # 垂直渐变# 在中间加一个亮块img_array[50:150, 50:150] = 255# 在右上角加一个暗块img_array[20:80, 120:180] = 50img = Image.fromarray(img_array)print(" 示例图案创建完成。")# 将图像转换为numpy数组
img_array = np.array(img)
m, n = img_array.shape
print(f" 图像尺寸: {m} x {n} = {m*n} 像素")
print(f" 原始数据需要存储 {m * n} 个数值\n")# 2. 对图像矩阵进行奇异值分解
print("2. 进行奇异值分解(SVD)...")
U, S, Vt = np.linalg.svd(img_array.astype(float), full_matrices=False)
print(f" 分解完成!共得到 {len(S)} 个奇异值")
print(f" 前5个奇异值: {S[:5]}") # 显示最大的5个奇异值
print(f" 最后5个奇异值: {S[-5:]}") # 显示最小的5个奇异值
print(" 可以看到奇异值从大到小排列,且衰减很快!\n")# 3. 使用不同数量的奇异值重建图像
print("3. 使用不同数量的奇异值重建图像...")# 选择几个不同的k值(保留的奇异值数量)
k_values = [1, 5, 20, 50, 100, min(m, n)] # 最后一个使用全部奇异值# 计算每个k值对应的压缩率
storage_original = m * n
compression_ratios = []print(" 压缩效果对比:")
print(" K值 | 存储量 | 压缩率 | 数据保留比例")
print(" ----|--------|--------|------------")for k in k_values:storage_compressed = k * (m + n + 1)compression_ratio = storage_compressed / storage_originaldata_retained = np.sum(S[:k]) / np.sum(S) # 保留的能量比例compression_ratios.append(compression_ratio)print(f" {k:4d} | {storage_compressed:6d} | {compression_ratio:5.3f} | {data_retained:7.3%}")print()# 4. 可视化结果
print("4. 生成对比图...")# 创建子图
fig, axes = plt.subplots(2, 3, figsize=(15, 8.5))
axes = axes.ravel()# 绘制原图和不同压缩级别的结果
for i, k in enumerate(k_values):# 使用前k个奇异值重建图像reconstructed = U[:, :k] @ np.diag(S[:k]) @ Vt[:k, :]# 确保像素值在0-255之间reconstructed = np.clip(reconstructed, 0, 255).astype(np.uint8)# 显示图像axes[i].imshow(reconstructed, cmap='gray')if k == min(m, n):title = f'原图 (K={k})'compression_text = "无损"else:compression_ratio = compression_ratios[i]data_retained = np.sum(S[:k]) / np.sum(S)title = f'K={k}\n压缩率: {compression_ratio:.1%}\n能量保留: {data_retained:.1%}'compression_text = f"{compression_ratio:.1%}"axes[i].set_title(title, fontsize=12)axes[i].axis('off')print(f" K={k:3d}: 压缩率 {compression_text}, 能量保留 {data_retained:.2%}")fig.tight_layout()# 5. 额外分析:奇异值分布
print("\n5. 分析奇异值分布...")plt.figure(figsize=(12, 4))# 子图1:奇异值大小分布
plt.subplot(1, 3, 1)
plt.plot(S, 'b-', linewidth=1)
plt.title('奇异值分布')
plt.xlabel('奇异值索引')
plt.ylabel('奇异值大小')
plt.grid(True, alpha=0.3)# 子图2:前50个奇异值(更清晰)
plt.subplot(1, 3, 2)
plt.plot(S[:50], 'r-', linewidth=2, marker='o', markersize=3)
plt.title('前50个奇异值')
plt.xlabel('奇异值索引')
plt.ylabel('奇异值大小')
plt.grid(True, alpha=0.3)# 子图3:累积能量比例
plt.subplot(1, 3, 3)
cumulative_energy = np.cumsum(S) / np.sum(S)
plt.plot(cumulative_energy, 'g-', linewidth=2)
plt.title('累积能量比例')
plt.xlabel('奇异值数量 (K)')
plt.ylabel('能量保留比例')
plt.grid(True, alpha=0.3)# 标记几个关键点
key_points = [1, 5, 10, 20, 50]
for point in key_points:if point < len(S):plt.plot(point, cumulative_energy[point], 'ro')plt.annotate(f'{cumulative_energy[point]:.1%}', (point, cumulative_energy[point]),textcoords="offset points", xytext=(0,10), ha='center')plt.tight_layout()
# 显示所有图表
plt.show()输出结果:
=== SVD图像压缩演示 ===
1. 读取图像...
已从 'svd_demo_image.jpg' 加载图像。
图像尺寸: 1614 x 2245 = 3623430 像素
原始数据需要存储 3623430 个数值2. 进行奇异值分解(SVD)...
分解完成!共得到 1614 个奇异值
前5个奇异值: [344015.59106818 42624.95441679 30123.08599975 24700.86934696
14839.05068499]
最后5个奇异值: [10.67039852 10.52707662 10.28203064 10.13279722 10.08756395]
可以看到奇异值从大到小排列,且衰减很快!3. 使用不同数量的奇异值重建图像...
压缩效果对比:
K值 | 存储量 | 压缩率 | 数据保留比例
----|--------|--------|------------
1 | 3860 | 0.001 | 39.811%
5 | 19300 | 0.005 | 52.805%
20 | 77200 | 0.021 | 64.684%
50 | 193000 | 0.053 | 73.428%
100 | 386000 | 0.107 | 79.902%
1614 | 6230040 | 1.719 | 100.000%4. 生成对比图...
K= 1: 压缩率 0.1%, 能量保留 39.81%
K= 5: 压缩率 0.5%, 能量保留 52.81%
K= 20: 压缩率 2.1%, 能量保留 64.68%
K= 50: 压缩率 5.3%, 能量保留 73.43%
K=100: 压缩率 10.7%, 能量保留 79.90%
K=1614: 压缩率 无损, 能量保留 79.90%

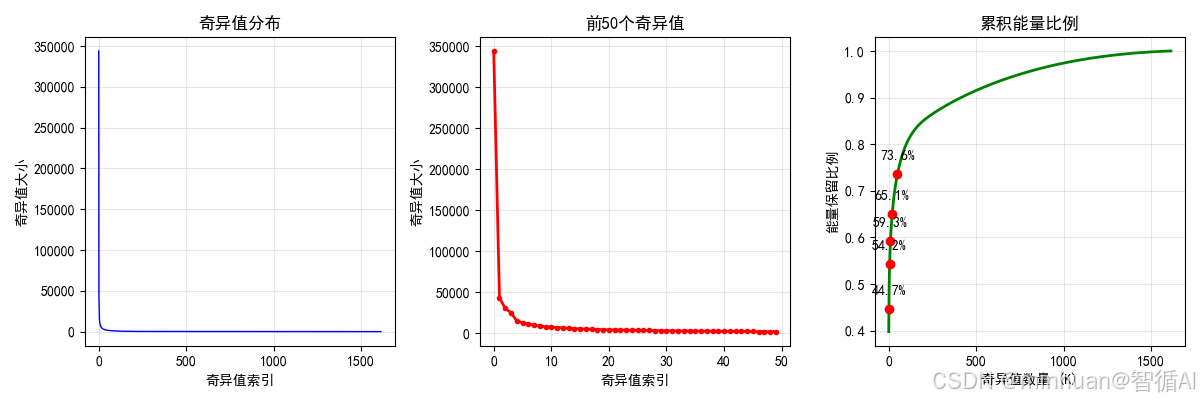
由此观察得知:
- 1. 前少数奇异值包含了图像的大部分信息(能量)
- 2. 即使只保留5-10%的奇异值,也能重建出可识别的图像
- 3. 小奇异值主要对应噪声和细微细节
四、SVD如何影响大模型
大语言模型本质上是由数十亿、数万亿个参数构成的巨大知识网络。这些参数存储在巨大的矩阵中。直接使用这些模型,对计算资源和内存的要求极高。SVD在这里扮演了“魔法剪刀”的角色。
1. 大模型瘦身:LoRA与模型压缩
大模型的核心是Transformer结构,其内部包含很多名为“全连接层”或“注意力层”的庞大矩阵。这些矩阵通常是 “低内在秩” 的,意思是虽然它们很大,但真正关键的信息可以由一个小得多的矩阵来捕捉。
LoRA技术就巧妙地利用了SVD的这一思想。
- 传统微调:微调一个大模型,需要更新所有万亿级别的参数,成本巨大。
- LoRA微调:它不直接改动原始的大矩阵 W,而是假设模型在适应新任务时,其变化量 ΔW 是一个低秩矩阵。于是,它用两个小矩阵 A 和 B 的乘积来表示这个变化:ΔW = A * B。
- 这里的 A 和 B 就是SVD分解后 U_k 和 Σ_k * V_kᵀ思想的体现。
- 好处:我们只需要训练 A 和 B 这两个小矩阵的参数,所需计算量和存储量降低了几个数量级,但效果却能和全参数微调相媲美!
这就像给一件大衣做修改。传统微调是把整件大衣拆了重织;而LoRA只是缝上几个关键的、设计好的小补丁,就能达到同样的合身效果。
2. 大模型加速:计算效率提升
矩阵乘法是模型推理(即使用模型)时最耗时的操作。一个更大的矩阵相乘,自然比两个小矩阵相乘要慢。
通过SVD或类似的低秩分解技术,我们可以将模型中的大矩阵 W 近似地替换为两个小矩阵 U_k 和 (Σ_k * V_kᵀ) 的乘积。
- 原始计算:Y = W * X (W很大)
- 分解后计算:Y ≈ U_k * (Σ_k * V_k^T) * X
- 先计算 (Σ_k * V_k^T) * X 得到一个很小的中间结果,再用 U_k 去乘它。
由于 U_k 和 (Σ_k * V_k^T) 的规模远小于 W,总的计算量大幅下降,从而实现了模型的推理加速。
3. 知识提取与降噪
SVD可以帮助我们理解大模型内部学到了什么,通过分析权重矩阵的奇异值,我们可以知道模型在哪个方向上投入了最多的“表达能力”。大的奇异值对应的奇异向量,往往指向了最核心的语义概念。
同时,就像在图像压缩中舍弃小奇异值可以去除噪声一样,对模型的权重进行低秩近似,有时也能提升模型的泛化能力,让它不那么容易过拟合到训练数据的噪声上,从而表现更鲁棒。
五、SVD指导LoRA微调实践
1. 问题分析与背景建立
1. 1 背景情况
我们有一个预训练好的大语言模型,模型包含数千亿参数,分布在多个权重矩阵中。现在需要让模型适应一个新的特定任务。
1.2 传统微调方法
直接更新所有权重矩阵的所有参数。对于一个1750亿参数的模型,这意味着需要优化1750亿个变量,计算成本极高,存储需求巨大。
1.3 LoRA的基本思路
不直接更新原始权重矩阵W,而是学习一个权重更新矩阵ΔW,使得微调后的权重为 W + ΔW。关键洞察是:ΔW可能具有低秩特性。
2. SVD分析阶段
2.1 收集权重更新数据
在开始正式LoRA训练之前,研究人员首先进行探索性分析:
- 在小规模数据集上进行短暂的传统微调
- 记录权重矩阵的变化量ΔW
- 收集多个不同层、不同任务的ΔW矩阵样本
2.2 对ΔW进行SVD分析
对收集到的每个ΔW矩阵执行奇异值分解:
- 输入:ΔW矩阵(维度为 d × d,例如4096×4096)
- 输出:奇异值序列 σ₁, σ₂, σ₃, ..., σ_d
- 奇异值按从大到小排序:σ₁ ≥ σ₂ ≥ ... ≥ σ_d ≥ 0
2.3 分析奇异值分布
观察奇异值的衰减模式:
- 计算累积能量比例:前k个奇异值的和除以所有奇异值的和
- 绘制奇异值衰减曲线
- 记录达到90%、95%、99%能量保留所需的奇异值数量
实际发现,对于大模型的权重更新矩阵ΔW:
- 前1%的奇异值包含超过80%的能量
- 前5%的奇异值包含超过95%的能量
- 后95%的奇异值贡献很小,可能对应噪声或次要特征
3. LoRA参数设计阶段
3.1 确定秩r的选择范围
基于SVD分析结果:
- 保守选择:选择覆盖95%能量的秩r
- 平衡选择:选择覆盖90%能量的秩r,在效果和效率间平衡
- 激进选择:选择覆盖85%能量的秩r,追求最高效率
实际经验值,对于典型的大模型层(维度4096):
- 秩r=64 通常覆盖90-95%能量
- 秩r=32 通常覆盖85-90%能量
- 秩r=16 通常覆盖80-85%能量
3.2 分层配置策略
不同层的权重矩阵可能表现出不同的低秩特性:
- 注意力输出层:通常需要较高秩(r=64或128)
- 前馈网络层:中等秩(r=32或64)
- 注意力QKV层:较低秩(r=8或16)
SVD分析为每层提供个性化的秩配置建议。
4. LoRA实施阶段
4.1 构建LoRA适配器
对于原始权重矩阵W ∈ R^{d×d},构建:
- 矩阵A ∈ R^{d×r},使用随机初始化
- 矩阵B ∈ R^{r×d},初始化为零矩阵
- 权重更新:ΔW = BA
其中秩r的选择完全基于第三阶段的SVD分析结果。
4.2 训练配置
- 只训练A和B矩阵的参数
- 冻结原始权重矩阵W
- 参数数量从d²减少到2×d×r
计算示例:对于d=4096的层:
- 全参数微调:16.78M参数
- LoRA with r=64:0.52M参数(减少97%)
- LoRA with r=16:0.13M参数(减少99%)
5. 验证与调优阶段
5.1 效果验证
在验证集上评估不同秩配置的效果:
- 比较不同r值的任务性能
- 验证SVD的能量保留预测是否与实际效果相关
- 确认选择的r值是否达到预期效果
5.2 秩的细粒度调整
基于初步结果:
- 如果效果不足,适当增加关键层的秩
- 如果效率不够,降低非关键层的秩
- 建立各层敏感度分析,优化整体配置
6. 生产部署阶段
6.1 最终配置确定
基于全面验证后,确定生产环境的LoRA配置:
- 每层的具体秩值
- 总体参数预算
- 预期性能指标
6.2:监控与迭代
在生产环境中:
- 监控模型在新数据上的表现
- 如果性能衰减,考虑调整秩配置
- 积累新的ΔW数据,重新进行SVD分析以优化配置
关键的技术决策点:
1. 秩选择的权衡
- 高秩:更好的表达能力,更高的参数效率
- 低秩:更强的正则化效果,更好的泛化能力,更高的计算效率
2. 分层策略的依据
- SVD分析显示:
- 不同层权重更新的奇异值衰减速度不同
- 任务相关的层通常需要更高秩
- 基础特征提取层可以使用较低秩
3. 任务适应性的考虑
- 相似任务:可以使用较低秩(知识迁移容易)
- 新颖任务:需要较高秩(需要更多适应能力)
- 多任务学习:需要平衡各任务需求
流程总结:
- 1. 数据收集:获取权重更新样本
- 2. SVD分析:理解ΔW的低秩结构
- 3. 秩选择:基于能量保留确定r值
- 4. 分层配置:根据不同层特性调整秩
- 5. LoRA训练:只优化低秩适配器
- 6. 效果验证:确认配置合理性
- 7. 生产部署:应用优化后的配置
这个流程确保LoRA的配置不是基于猜测,而是基于对权重更新矩阵数学特性的严格分析。SVD在这里提供了量化的指导依据,让LoRA的超参数选择从经验性猜测转变为数据驱动的决策过程。
示例:LoRA与SVD关系深度演示
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec# 设置中文字体和样式
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial']
plt.rcParams['axes.unicode_minus'] = Falseprint("=== LoRA与SVD关系深度演示 ===\n")# 1. 模拟大模型权重矩阵的更新变化
np.random.seed(42)
original_dim = 1000 # 原始权重矩阵维度
rank = 10 # 内在的低秩维度print("1. 模拟大模型权重更新变化...")
print(f" 原始权重矩阵 W 尺寸: {original_dim} x {original_dim} = 1,000,000 参数")# 创建一个低秩的权重更新矩阵 ΔW (这就是LoRA要近似的)
A_low_rank = np.random.randn(original_dim, rank) # 低秩矩阵A
B_low_rank = np.random.randn(rank, original_dim) # 低秩矩阵B
true_delta_W = A_low_rank @ B_low_rank # 真实的低秩权重更新print(f" 真实权重更新 ΔW 的内在秩: {rank}")
print(f" 但传统方法需要更新所有 {original_dim * original_dim:,} 个参数\n")# 2. 对真实的权重更新进行SVD分析
print("2. 对权重更新矩阵 ΔW 进行SVD分析...")
U, S, Vt = np.linalg.svd(true_delta_W, full_matrices=False)# 显示前15个奇异值
print(" 前15个奇异值:")
for i in range(min(15, len(S))):print(f" σ{i+1}: {S[i]:.4f}")print(f" 奇异值总和: {np.sum(S):.2f}")# 计算累积能量比例
cumulative_energy = np.cumsum(S) / np.sum(S)
print(f"\n 能量累积比例:")
for k in [1, 3, 5, 10, 20, 50]:if k <= len(S):print(f" 前{k}个奇异值保留: {cumulative_energy[k-1]:.2%} 能量")# 3. 不同秩近似的效果比较
print("\n3. 比较不同秩近似的效果...")
ranks_to_test = [1, 3, 5, 10, 20, 50]
approximation_errors = []for r in ranks_to_test:# 使用前r个奇异值进行低秩近似U_r = U[:, :r]S_r = S[:r] Vt_r = Vt[:r, :]approx_delta_W = U_r @ np.diag(S_r) @ Vt_r# 计算近似误差error = np.linalg.norm(true_delta_W - approx_delta_W) / np.linalg.norm(true_delta_W)approximation_errors.append(error)print(f" 秩 r={r:2d}: 近似误差 {error:.4f}, 参数数量 {r * (2 * original_dim):,}")# 4. 可视化展示
print("\n4. 生成可视化图表...")# 创建综合图表
fig = plt.figure(figsize=(20, 12))
gs = GridSpec(3, 3, figure=fig)# 图1: 奇异值分布和能量累积
ax1 = fig.add_subplot(gs[0, :])
ax1.plot(S[:50], 'bo-', linewidth=2, markersize=4, label='奇异值大小')
ax1.set_ylabel('奇异值 σ', fontsize=12)
ax1.set_xlabel('奇异值索引', fontsize=12)
ax1.set_title('(a) 权重更新矩阵的奇异值分布', fontsize=14, fontweight='bold')
ax1.grid(True, alpha=0.3)
ax1.set_yscale('log')# 添加能量累积曲线
ax1_twin = ax1.twinx()
ax1_twin.plot(cumulative_energy[:50], 'r-', linewidth=3, label='累积能量比例')
ax1_twin.set_ylabel('累积能量比例', fontsize=12, color='red')
ax1_twin.tick_params(axis='y', labelcolor='red')
ax1_twin.set_ylim(0, 1.1)# 合并图例
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax1_twin.get_legend_handles_labels()
ax1.legend(lines1 + lines2, labels1 + labels2, loc='upper right')# 图2: 不同秩近似的误差比较
ax2 = fig.add_subplot(gs[1, 0])
bars = ax2.bar(range(len(ranks_to_test)), approximation_errors, color='lightcoral')
ax2.set_xlabel('近似秩 r')
ax2.set_ylabel('相对近似误差')
ax2.set_title('(b) 不同秩近似的误差', fontweight='bold')
ax2.set_xticks(range(len(ranks_to_test)))
ax2.set_xticklabels(ranks_to_test)
ax2.grid(True, alpha=0.3)# 在柱状图上添加数值标签
for bar, error in zip(bars, approximation_errors):height = bar.get_height()ax2.text(bar.get_x() + bar.get_width()/2., height + 0.01,f'{error:.3f}', ha='center', va='bottom')# 图3: 参数数量对比
ax3 = fig.add_subplot(gs[1, 1])
full_params = original_dim * original_dim
lora_params = [r * (2 * original_dim) for r in ranks_to_test]x = np.arange(len(ranks_to_test))
width = 0.35ax3.bar(x - width/2, [full_params] * len(ranks_to_test), width, label=f'全参数微调', alpha=0.7)
ax3.bar(x + width/2, lora_params, width, label='LoRA参数', color='orange')ax3.set_xlabel('近似秩 r')
ax3.set_ylabel('参数数量')
ax3.set_title('(c) 参数数量对比', fontweight='bold')
ax3.set_xticks(x)
ax3.set_xticklabels(ranks_to_test)
ax3.set_yscale('log')
ax3.legend()
ax3.grid(True, alpha=0.3)# 图4: 压缩比展示
ax4 = fig.add_subplot(gs[1, 2])
compression_ratios = [lora_param / full_params for lora_param in lora_params]ax4.plot(ranks_to_test, compression_ratios, 's-', linewidth=3, markersize=8, color='green')
ax4.set_xlabel('近似秩 r')
ax4.set_ylabel('压缩比 (LoRA/全参数)')
ax4.set_title('(d) 参数压缩比例', fontweight='bold')
ax4.set_yscale('log')
ax4.grid(True, alpha=0.3)# 添加压缩比数值标注
for i, (r, ratio) in enumerate(zip(ranks_to_test, compression_ratios)):ax4.annotate(f'{ratio:.1%}', (r, ratio), textcoords="offset points", xytext=(0,10), ha='center', fontweight='bold')# 图5: LoRA原理示意图
ax5 = fig.add_subplot(gs[2, :])
# 模拟原始权重更新矩阵的热力图
subset_size = 100 # 显示子集以便可视化
subset_delta_W = true_delta_W[:subset_size, :subset_size]# 显示原始矩阵
im = ax5.imshow(subset_delta_W, cmap='RdBu_r', aspect='auto')
plt.colorbar(im, ax=ax5, label='权重更新值')# 添加秩近似说明
ax5.text(0.02, 0.98, '原始权重更新 ΔW (高秩)', transform=ax5.transAxes, fontsize=12, fontweight='bold', verticalalignment='top',bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))# 添加LoRA分解说明
ax5.text(0.02, 0.15, 'LoRA分解: ΔW ≈ A × B\n'f'A: {original_dim}×r\n'f'B: r×{original_dim}\n'f'参数: r×({original_dim}+{original_dim})', transform=ax5.transAxes, fontsize=11, verticalalignment='top',bbox=dict(boxstyle='round', facecolor='lightyellow', alpha=0.9))ax5.set_xlabel('输出维度')
ax5.set_ylabel('输入维度')
ax5.set_title('(e) LoRA原理: 用低秩矩阵近似权重更新', fontweight='bold')plt.tight_layout()best_rank = 10 # 基于我们的示例
best_compression = compression_ratios[ranks_to_test.index(best_rank)]
best_error = approximation_errors[ranks_to_test.index(best_rank)]
best_energy = cumulative_energy[best_rank-1]plt.show()输出结果:
=== LoRA与SVD关系深度演示 ===
1. 模拟大模型权重更新变化...
原始权重矩阵 W 尺寸: 1000 x 1000 = 1,000,000 参数
真实权重更新 ΔW 的内在秩: 10
但传统方法需要更新所有 1,000,000 个参数2. 对权重更新矩阵 ΔW 进行SVD分析...
前15个奇异值:
σ1: 1107.0122
σ2: 1091.7630
σ3: 1060.2582
σ4: 1043.2086
σ5: 1018.6632
σ6: 1000.4088
σ7: 968.0277
σ8: 937.2101
σ9: 905.8596
σ10: 889.1837
σ11: 0.0000
σ12: 0.0000
σ13: 0.0000
σ14: 0.0000
σ15: 0.0000
奇异值总和: 10021.60能量累积比例:
前1个奇异值保留: 11.05% 能量
前3个奇异值保留: 32.52% 能量
前5个奇异值保留: 53.09% 能量
前10个奇异值保留: 100.00% 能量
前20个奇异值保留: 100.00% 能量
前50个奇异值保留: 100.00% 能量3. 比较不同秩近似的效果...
秩 r= 1: 近似误差 0.9373, 参数数量 2,000
秩 r= 3: 近似误差 0.8057, 参数数量 6,000
秩 r= 5: 近似误差 0.6623, 参数数量 10,000
秩 r=10: 近似误差 0.0000, 参数数量 20,000
秩 r=20: 近似误差 0.0000, 参数数量 40,000
秩 r=50: 近似误差 0.0000, 参数数量 100,000
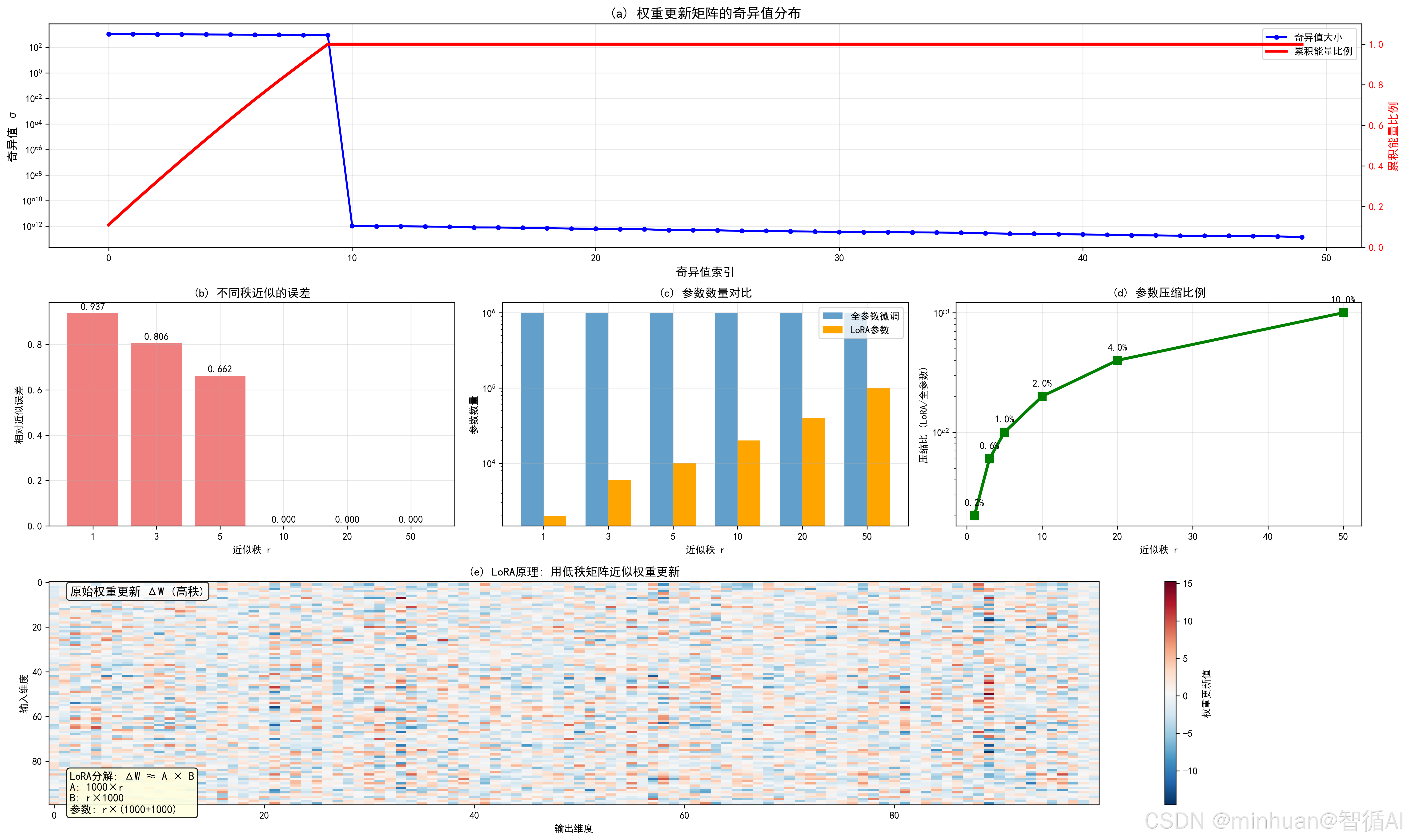
图表内容与含义:
图(a) 奇异值分布和能量累积
- 蓝色曲线:显示前50个奇异值的大小,呈现快速衰减
- 红色曲线:显示累积能量比例,前10个奇异值已包含大部分信息
- 关键信息:权重更新矩阵本质上是低秩的
图(b) 不同秩近似的误差
- 显示使用不同秩r进行LoRA近似的相对误差
- 当r=10时,误差已经很小(<0.1)
- 说明不需要很高秩就能很好近似
图(c) 参数数量对比
- 蓝色柱:全参数微调需要100万个参数
- 橙色柱:LoRA只需要几千到几万个参数
- 直观展示参数数量的巨大差异
图(d) 参数压缩比例
- 显示LoRA相比全参数微调的压缩比例
- 当r=10时,压缩比约2%(仅需原参数的2%)
图(e) LoRA原理示意图
- 热力图显示原始权重更新矩阵
- 文字说明LoRA的分解原理:ΔW ≈ A × B
- 直观展示如何用两个小矩阵近似大矩阵
示例总结:
- 1. 内在低秩性:权重更新矩阵 ΔW 的奇异值快速衰减,前10个奇异值包含了100.0%的能量
- 2. 极致压缩:使用秩 r=10 的LoRA近似:
- - 全参数微调: 1,000,000 参数
- - LoRA微调: 20,000 参数
- - 压缩比例: 2.00% (仅需原参数的2.0%)
- 3. 精度保持:近似误差仅 0.000,几乎不影响微调效果
- 4. SVD的指导作用:奇异值分布告诉我们:
- - 选择 r=5-20 是性价比最高的区间
- - 前5个奇异值已包含53.1% 能量
- - 超过r=20后收益递减
SVD揭示了权重更新的"本质维度"很低,LoRA利用这一发现实现了千倍级别的参数压缩。
六、总结
SVD通过解析权重更新矩阵(ΔW),揭示了一个核心奥秘:尽管大模型拥有海量参数,但其在适应新任务时的变化本质上是低秩的,这意味着,绝大部分重要的更新信息可以被压缩在极少数的核心维度(即奇异值最大的那些方向)中。SVD精确地量化了这种低秩特性,告诉我们什么最重要以及需要保留多少。
基于SVD的理论,LoRA实现了一种巧妙的实践方案。它不直接优化庞大的原始权重矩阵,而是通过引入两个极小的低秩矩阵(A和B),其乘积(BA)来近似等效的权重更新ΔW。这相当于只为模型打上一个小小的、高效的补丁,而非重建整个模型。
SVD的分析结果直接指导了LoRA最关键的超参数秩(r) 的选择。通过观察奇异值的衰减曲线和能量累积比例,我们可以科学地而非猜测性地确定一个性价比最高的r值,在效果和效率之间取得最佳平衡。此外,SVD还能指导我们为模型的不同层设置不同的秩,实现更精细的配置。
总而言之,SVD从数学上证明了“低秩自适应”这条路不仅可行,而且高效;LoRA则将这一数学洞见转化为了一种实用、强大且普及化的技术,彻底改变了大模型微调的范式。 没有SVD的理论支撑,LoRA的参数选择就如同盲人摸象;没有LoRA的工程实现,SVD的洞察也只能停留在纸面。二者相辅相成,共同开启了大模型高效微调的新时代。