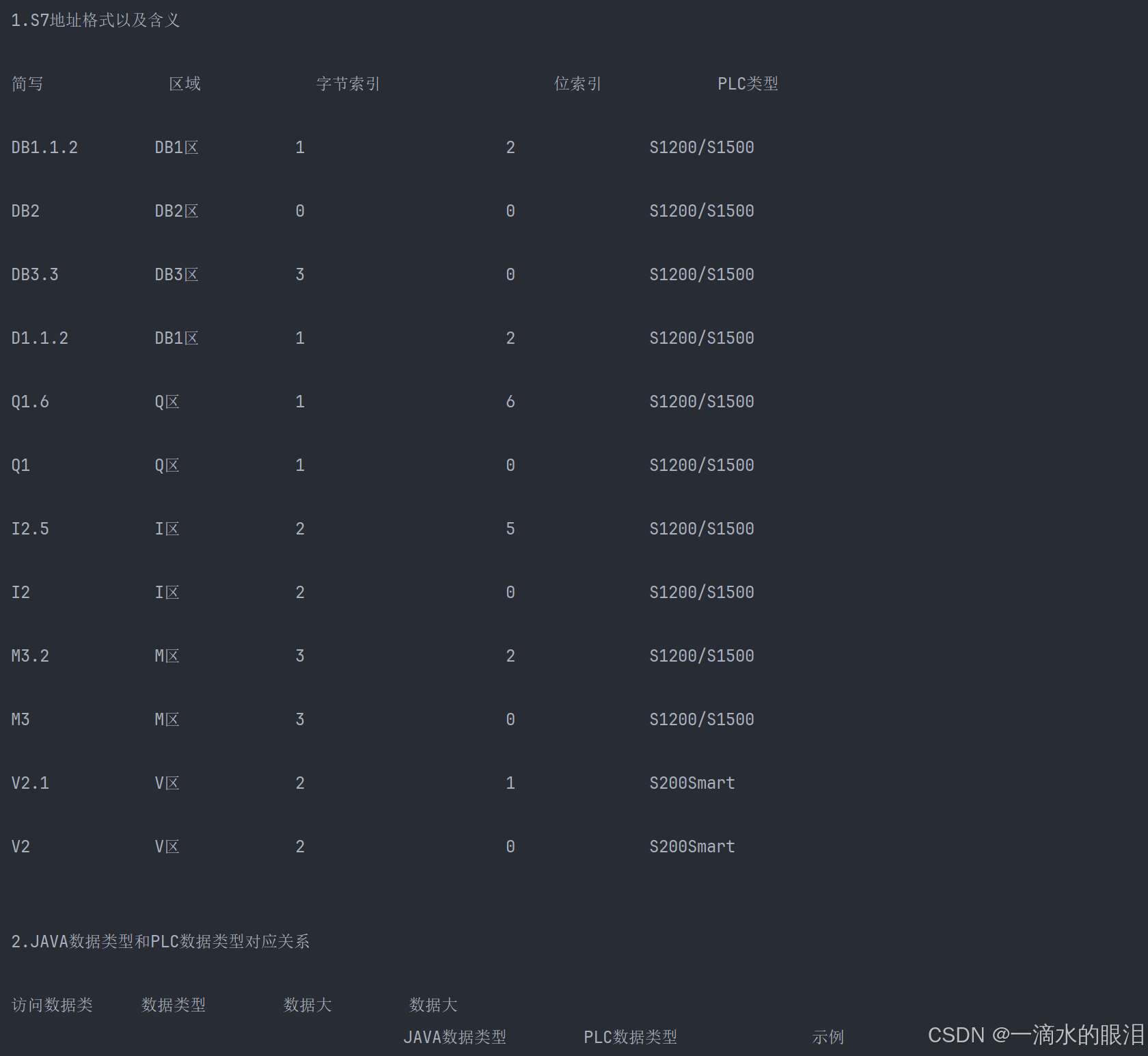
读取实验室原始记录单PDF内容
一.工具选取
1. Apache PDFBox
简介:
Apache PDFBox 是一个开源的纯 Java PDF 库,支持创建、渲染、打印、分割、合并和提取 PDF 内容。
优点:
- 开源免费(Apache 2.0 许可)
- 功能全面:支持文本提取、图像提取、PDF创建、加密/解密、表单处理等
- 纯 Java 实现,无需依赖本地库
- 社区活跃,文档较完善
- 支持 PDF/A 标准
缺点:
- 性能一般,尤其处理大文件时较慢
- 对复杂排版(如多栏、表格)的文本提取效果一般,可能乱序
- 内存占用较高
示例代码(文本提取):
PDDocument document = PDDocument.load(new File("example.pdf"));
PDFTextStripper stripper = new PDFTextStripper();
String text = stripper.getText(document);
document.close();
2. iText
简介:
iText 是一个功能强大的商业级 PDF 库,有开源版(AGPL)和商业授权版。
优点:
- 功能极其强大:支持高级 PDF 操作(数字签名、水印、表单、加密等)
- 性能较好
- 提供对 PDF 结构的精细控制
缺点:
- 开源版本为 AGPL,若用于闭源商业项目需购买商业许可证
- 文本提取功能相对较弱(早期版本),虽然后续版本有所改进
- 学习曲线较陡
示例(文本提取,需使用 iText 7 的 pdfSweep 或 pdfCalligraph 模块):
Java
编辑
PdfDocument pdfDoc = new PdfDocument(new PdfReader(“example.pdf”));
String text = PdfTextExtractor.getTextFromPage(pdfDoc.getPage(1));
pdfDoc.close();
注意:iText 5 的文本提取能力有限,推荐使用 iText 7 + 附加模块。
3. PDF Clown
简介:
PDF Clown 是一个开源(LGPL)的 Java PDF 库,支持读写 PDF。
优点:
- 开源免费(LGPL)
- 支持文本、图像、字体、元数据提取
- 架构清晰,面向对象设计良好
缺点:
- 更新缓慢,最新稳定版停留在 2016 年左右
- 社区小,文档较少
- 性能和稳定性不如 PDFBox 或 iText
- 适用场景:小型项目、学习研究
4. Tess4J + OCR(针对扫描版PDF)
说明:
如果 PDF 是扫描件(图像型),上述工具无法直接提取文本,需结合 OCR(光学字符识别)。
方案:
- 使用 Apache PDFBox 或其他库将 PDF 转为图像
- 调用 Tess4J(Java 封装 Tesseract OCR)识别文字
优点:
- 可处理扫描 PDF
- Tesseract 开源免费
缺点:
- 依赖本地安装 Tesseract
- 识别准确率受图像质量影响大
- 处理速度慢
5. pdftotext(通过 Poppler)
简介:
pdftotext 是 Poppler 项目提供的一个命令行工具,用于从 PDF 中提取文本。Poppler 是一个 C++ 编写的开源 PDF 渲染库,广泛用于 Linux 系统(如 Ubuntu、CentOS)和 macOS。
虽然 pdftotext 本身不是 Java 库,但 Java 程序可以通过 Runtime.exec() 或 ProcessBuilder 调用该命令行工具,从而实现 PDF 文本提取。
优点:
- 文本提取准确率高:尤其对复杂布局、多栏、表格等排版,通常优于 PDFBox
- 速度快:C++ 实现,性能优异,适合批量处理
- 开源免费(GPL 许可)
- 保留原始布局(可通过 -layout 参数)
- 支持加密 PDF(如果未设权限限制)
缺点:
- 非纯 Java 方案:需在目标系统预装 Poppler(Linux/macOS 原生支持较好,Windows 需手动安装)
- 跨平台部署复杂:需确保每台服务器都安装了 pdftotext
- 无法直接操作 PDF 对象(如元数据、图像、表单等)
- 错误处理和日志较难集成到 Java 应用中
- GPL 许可:若将 pdftotext 作为程序一部分分发,可能触发 GPL 传染性(但仅调用命令行通常不构成衍生作品,法律上存在争议,建议咨询法务)
Java 调用示例:
public String extractTextWithPdftotext(String pdfPath) throws IOException {ProcessBuilder pb = new ProcessBuilder("pdftotext", "-layout", "-enc", "UTF-8", pdfPath, "-");Process process = pb.start();try (BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream(), StandardCharsets.UTF_8))) {return reader.lines().collect(Collectors.joining("\n"));}
}
参数说明:
- -layout:尽量保留原始文本布局
- -enc UTF-8:指定输出编码
- -:表示输出到 stdout
对比总结表:
| 工具 | 开源许可 | 文本提取能力 | 性能 | 易用性 | 商业友好 | 适合场景 |
|---|---|---|---|---|---|---|
| PDFBox | Apache 2.0 | ★★★★☆ | ★★☆ | ★★★★ | ✅ | 通用文本提取、开源项目 |
| iText | AGPL / 商业授权 | ★★★☆☆(需额外模块) | ★★★★ | ★★★ | ❌(闭源需购买授权) | 高级PDF操作、商业应用 |
| PDF Clown | LGPL | ★★★☆☆ | ★★ | ★★★ | ✅(注意LGPL条款) | 小型项目、教学研究 |
| Tess4J + OCR | Apache 2.0 | ★★★★(仅适用于图像型PDF) | ★☆ | ★★ | ✅ | 扫描版PDF、图像转文本 |
| pdftotext (Poppler) | GPL | ★★★★★(布局保留好,准确率高) | ★★★★★ | ★★☆ | ⚠️(GPL传染性,需评估合规) | 高精度文本提取、服务端批量处理 |
推荐选择:
- 普通文本PDF提取(开源项目) → Apache PDFBox
- 需要高级PDF功能(如签名、表单)且可付费 → iText(商业版)
- 处理扫描PDF → PDFBox + Tess4J
- 轻量级或学习用途 → PDF Clown(谨慎使用,因维护停滞)
- 如果你追求高精度文本提取(尤其是学术论文、财报、多栏文档) → 优先考虑 pdftotext,前提是部署环境可控(如 Linux 服务器)。
- 避免在无法控制部署环境的 SaaS 或客户端应用中使用 pdftotext,因其依赖外部二进制文件。
本人测试过如果是实验室仪器到处的PDF文件使用PDFBox识别内容会出现错乱现象无法准确识别,并且有数据丢失现象,使用付费的OCR识别接口不会出现数据错乱但是识别错误比较明显,最终采用了pdftotext (Poppler)识别方法,准确度高,格式保留较好。
二.安装pdftotext
Linux 系统(Ubuntu / CentOS / Debian 等)
1. 安装 Poppler(含 pdftotext)
Ubuntu / Debian:
sudo apt update
sudo apt install poppler-utils
CentOS / RHEL / Fedora:
# CentOS 7/8 或 RHEL(需启用 EPEL)
sudo yum install epel-release
sudo yum install poppler-utils# 或 Fedora
sudo dnf install poppler-utils
2. 验证安装
pdftotext -v
输出类似:
pdftotext version 22.08.0
Copyright 2005-2022 The Poppler Developers - http://poppler.freedesktop.org
如果安装版本过于老旧如:poppler-utils-0.26.5-24.el7.x86_64 ,我们可以卸载之后下载源码手动安装
安装最新版本
2.1 删除旧版本
# 查看已安装的 poppler 相关包
rpm -qa | grep poppler# 卸载 poppler-utils 及依赖(谨慎:可能影响其他软件)
sudo yum remove poppler-utils poppler-glib poppler-qt4 poppler-qt5#更新动态链接库缓存
sudo ldconfig
2.2 下载最新源码
前往 https://poppler.freedesktop.org/ 获取最新版(如 poppler-23.08.0.tar.xz)
cd /home
wget https://poppler.freedesktop.org/poppler-23.08.0.tar.xz
tar -xf poppler-25.10.0.tar.xz
cd poppler-25.10.0
2.3 配置编译选项(使用 CMake)
2.3.1 安装CMake
# 1. 卸载旧版 cmake(可选,避免混淆)
sudo yum remove cmake# 2. 下载 CMake 3.28.3(或最新 LTS 版)Linux x86_64 二进制包
cd /tmp
wget https://github.com/Kitware/CMake/releases/download/v3.28.3/cmake-3.28.3-linux-x86_64.tar.gz# 3. 解压到 /opt
sudo tar -zxvf cmake-3.28.3-linux-x86_64.tar.gz -C /opt#4.将 CMake 目录加入 PATH
echo 'export PATH="/opt/cmake-3.28.3-linux-x86_64/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc#验证
cmake --version
安装脚本
#!/bin/bash# CentOS 7 安装 Poppler 23.08.0 脚本
# 作者:AI助手
# 功能:修复 EOL 仓库问题 + 安装 devtoolset-7 + 编译 Poppler 23.08.0set -e # 遇到错误立即退出echo "=== CentOS 7 Poppler 23.08.0 安装脚本 ==="# 1. 清理所有 SCL 相关仓库(解决重复定义问题)
echo "1. 清理 SCL 仓库配置..."
sudo rm -f /etc/yum.repos.d/*sclo*
sudo rm -f /etc/yum.repos.d/*scl*# 2. 创建 Vault 源(主仓库)
echo "2. 配置 CentOS Vault 源..."
cat > /etc/yum.repos.d/CentOS-Base.repo <<'EOF'
[base]
name=CentOS-$releasever - Base
baseurl=https://vault.centos.org/7.9.2009/os/$basearch/
gpgcheck=1
gpgkey=https://vault.centos.org/7.9.2009/os/x86_64/RPM-GPG-KEY-CentOS-7
enabled=1[updates]
name=CentOS-$releasever - Updates
baseurl=https://vault.centos.org/7.9.2009/updates/$basearch/
gpgcheck=1
gpgkey=https://vault.centos.org/7.9.2009/updates/x86_64/RPM-GPG-KEY-CentOS-7
enabled=1[extras]
name=CentOS-$releasever - Extras
baseurl=https://vault.centos.org/7.9.2009/extras/$basearch/
gpgcheck=1
gpgkey=https://vault.centos.org/7.9.2009/extras/x86_64/RPM-GPG-KEY-CentOS-7
enabled=1
EOF# 3. 创建 SCL 仓库(仅 rh,不含 sclo)
cat > /etc/yum.repos.d/CentOS-SCL.repo <<'EOF'
[centos-sclo-rh]
name=CentOS-7 - SCLo rh
baseurl=https://vault.centos.org/7.9.2009/sclo/$basearch/rh/
enabled=1
gpgcheck=0
EOF# 4. 清理 yum 缓存
echo "3. 清理 yum 缓存..."
sudo yum clean all
sudo rm -rf /var/cache/yum# 5. 测试 yum 是否正常
echo "4. 测试 yum 配置..."
sudo yum makecache# 6. 安装编译依赖
echo "5. 安装编译依赖..."
sudo yum install -y \gcc gcc-c++ make cmake \libjpeg-devel libpng-devel libtiff-devel \freetype-devel fontconfig-devel cairo-devel \glib2-devel openjpeg2-devel boost-devel \zlib-devel# 7. 安装 devtoolset-7(GCC 7.3.1,支持 C++17)
echo "6. 安装 devtoolset-7..."
sudo yum install -y devtoolset-7-gcc-c++# 8. 下载并编译 Freetype 2.13.2(Poppler 23.08 要求 ≥2.11)
echo "7. 编译安装 Freetype 2.13.2..."
cd /tmp
wget https://download.savannah.gnu.org/releases/freetype/freetype-2.13.2.tar.xz
tar -xf freetype-2.13.2.tar.xz
cd freetype-2.13.2
./configure --prefix=/usr/local --enable-freetype-config
make -j$(nproc)
sudo make install
export PKG_CONFIG_PATH="/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH"# 9. 下载 Poppler 23.08.0
echo "8. 下载 Poppler 23.08.0..."
cd /tmp
if [ ! -d "poppler-23.08.0" ]; thenwget https://poppler.freedesktop.org/poppler-23.08.0.tar.xztar -xf poppler-23.08.0.tar.xz
fi# 10. 编译 Poppler(在 devtoolset-7 环境下)
echo "9. 编译 Poppler 23.08.0..."
cd poppler-23.08.0# 启用 devtoolset-7 并编译
scl enable devtoolset-7 bash << 'EOF_INNER'
cd /tmp/poppler-23.08.0
rm -rf build
mkdir build && cd buildcmake .. \-DCMAKE_BUILD_TYPE=Release \-DCMAKE_INSTALL_PREFIX=/usr/local \-DENABLE_UNSTABLE_API_ABI_HEADERS=ON \-DENABLE_QT5=OFF \-DENABLE_QT6=OFF \-DENABLE_GLIB=ON \-DENABLE_CPP=ON \-DENABLE_LIBOPENJPEG=openjpeg2 \-DENABLE_NSS3=OFF \-DENABLE_GPGME=OFF \-DENABLE_LIBTIFF=OFF \-DENABLE_BOOST=OFFmake -j$(nproc)
sudo make install
EOF_INNER# 11. 更新动态库缓存
echo "10. 更新动态库缓存..."
sudo ldconfig# 12. 验证安装
echo "11. 验证安装..."
/usr/local/bin/pdftotext -vecho "=== 安装完成! ==="
echo "pdftotext 已安装到 /usr/local/bin/pdftotext"
echo "版本信息如上所示"
echo "如需在脚本中使用,请确保 PATH 包含 /usr/local/bin"
3. 基本使用
# 提取文本到 stdout(终端直接显示)
pdftotext -layout -enc UTF-8 example.pdf -# 提取到文件
pdftotext -layout example.pdf output.txt
常用参数:
- -layout:尽量保留原始布局(多栏、表格对齐更准确)
- -enc UTF-8:指定输出编码(避免中文乱码)
- -:表示输出到标准输出(stdout)
Windows 系统
⚠️ Windows 官方不提供 Poppler,需使用第三方编译版本。
1. 下载 Poppler for Windows
推荐使用社区维护的预编译版本:
🔗 官方 GitHub 发布页(推荐):
https://github.com/oschwartz10612/poppler-windows/releases
👉 下载最新版 .zip 文件(如 poppler-xx.xx.x_x64.7z 或 .zip)
2. 安装步骤
- 解压下载的压缩包(例如到 C:\poppler)
- 进入 bin 目录,确认存在 pdftotext.exe
- 将 C:\poppler\bin 添加到系统环境变量 PATH 中:
- 右键“此电脑” → “属性” → “高级系统设置” → “环境变量”
- 在“系统变量”中找到 Path,点击“编辑”
- 新增一行:C:\poppler\bin(根据你的实际路径修改)
- 重启命令提示符(CMD)或 PowerShell
3. 验证安装
打开 CMD 或 PowerShell,运行:
pdftotext -v
应显示版本信息。
4. 基本使用(CMD / PowerShell)
:: 输出到控制台(注意末尾的 "-")
pdftotext -layout -enc UTF-8 example.pdf -:: 输出到文件
pdftotext -layout example.pdf output.txt
💡 提示:Windows 默认编码为 GBK,若 PDF 含中文,建议始终加上 -enc UTF-8 并用支持 UTF-8 的编辑器(如 VS Code)查看输出。
三、工具类
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;/*** 使用系统 pdftotext 命令提取 PDF 文本内容的工具类* 需要系统已安装 Poppler(包含 pdftotext)*/
public class PdfToTextUtil {/*** 从 PDF 文件中提取文本(保留布局)** @param pdfFile PDF 文件路径* @return 提取的文本内容(UTF-8 字符串)* @throws IOException 当 PDF 文件不存在、pdftotext 未安装或执行失败时抛出*/public static String extractText(String pdfFile) throws IOException {return extractText(new File(pdfFile));}/*** 从 PDF 文件中提取文本(保留布局)** @param pdfFile PDF 文件对象* @return 提取的文本内容(UTF-8 字符串)* @throws IOException 当 PDF 文件不存在、pdftotext 未安装或执行失败时抛出*/public static String extractText(File pdfFile) throws IOException {if (!pdfFile.exists() || !pdfFile.isFile()) {throw new FileNotFoundException("PDF file not found: " + pdfFile.getAbsolutePath());}// 获取 pdftotext 执行路径(优先从系统属性获取)String pdftotextPath = System.getProperty("pdftotext.path", "pdftotext");// 构建命令:pdftotext -layout -enc UTF-8 input.pdf -List<String> command = new ArrayList<>();command.add(pdftotextPath);command.add("-layout"); // 保留原始布局(列、对齐等)command.add("-enc"); // 指定输出编码command.add("UTF-8");command.add(pdfFile.getAbsolutePath());command.add("-"); // 输出到 stdoutProcessBuilder pb = new ProcessBuilder(command);pb.redirectErrorStream(true); // 合并 stderr 到 stdoutProcess process = pb.start();StringBuilder output = new StringBuilder();try (BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream(), StandardCharsets.UTF_8))) {String line;while ((line = reader.readLine()) != null) {output.append(line).append(System.lineSeparator());}}try {boolean finished = process.waitFor(30, TimeUnit.SECONDS); // 设置最大等待时间为30秒if (!finished) {process.destroyForcibly();throw new IOException("pdftotext process timed out and was forcibly terminated.");}int exitCode = process.exitValue();if (exitCode != 0) {// 注意:不要把整个 output 放进异常信息中以防泄露敏感内容throw new IOException("pdftotext failed with exit code " + exitCode);}} catch (InterruptedException e) {Thread.currentThread().interrupt();throw new IOException("pdftotext process interrupted", e);}return output.toString();}// ===== 示例用法 =====public static void main(String[] args) {try {String text = PdfToTextUtil.extractText("D:002.pdf");System.out.println(text);} catch (IOException e) {System.err.println("Error extracting PDF text: " + e.getMessage());e.printStackTrace();}}
}运行截图:
四、常见问题
| 问题 | 解决方案 |
|---|---|
| pdftotext: command not found | Linux:未安装;Windows:未配置 PATH |
| 中文乱码 | 始终使用 -enc UTF-8,Java 读取时指定 UTF-8 编码 |
| 提取结果为空 | PDF 可能是扫描件(图像),需用 OCR(如 Tess4J) |
| GPL 合规担忧 | 仅调用命令行通常不构成“衍生作品”,但建议咨询法务 |