Faster-Whisper命令和意图识别程序设计调优:上下文感知和领域词汇增强
相干视频教程:
《Faster-whisper热词详解与程序设计教程》
《Faster-Whisper唤醒词检测程序设计实战》
《Faster-Whisper命令和意图识别程序设计实战》
一、概念定义
"上下文感知"和"领域词汇增强"是优化Faster-Whisper在实际应用中表现的两个重要技术思路,它们分别从理解整体语义和识别关键术语两个不同角度提升语音识别的准确率。

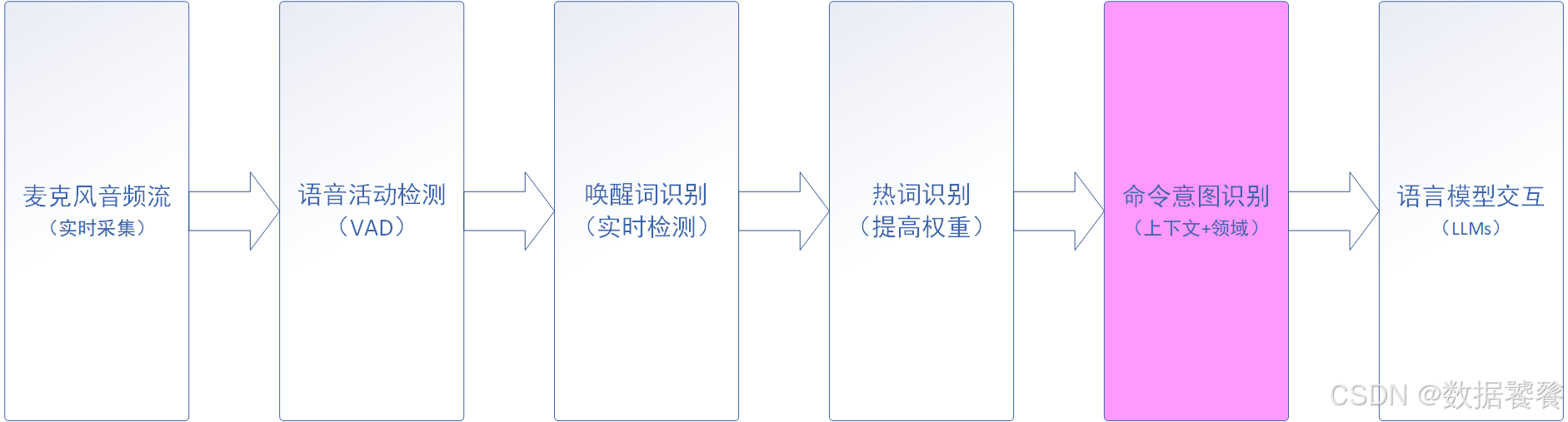
下面的表格清晰地展示了它们的核心区别与联系:
| 特性维度 | 上下文感知 | 领域词汇增强 |
|---|---|---|
| 核心目标 | 利用上下文信息,保证语义连贯性 | 提升领域专有词汇的识别准确率 |
| 技术焦点 | 整体句子结构和语言逻辑 | 特定关键词或短语 |
| 实现方式 | - 流式分块处理 - 提示工程( initial_prompt)- 关联前文( condition_on_previous_text) | - 热词增强(hotwords)- 领域自适应提示 |
| 适用场景 | 长音频转录、实时字幕、会议记录 | 医疗、法律、技术支持等专业领域 |
🧠 深入理解上下文感知
你可以把"上下文感知"理解为模型在转录时,不仅听当前的一句话,还会参考前面说过的话,以此来更好地理解当前的语义和语境。
-
工作原理:Faster-Whisper在处理长语音时,会采用流式分块的方式。为了保证块与块之间的连贯,它依赖于Transformer架构的记忆能力,并可以通过
condition_on_previous_text参数(建议设为True)将前文信息作为解码当前文本的参考。 -
关键参数与应用:
-
initial_prompt参数:这是实现上下文感知非常有效的方法。你可以在转录开始时,通过这个参数给模型一些提示。例如,在医疗听写场景下,提示"以下是医生问诊记录",可以引导模型生成更符合医疗对话风格的文本。 -
实际场景:在会议实时转录中,上下文感知能帮助模型正确识别人名、项目名等贯穿全程的实体。
-
🔤 掌握领域词汇增强
这项技术更像是给模型一份"专业词汇表",让它优先识别出你所在行业的特定术语。
-
工作原理:通过提高特定词汇在解码过程中的权重,让模型在遇到发音相近的选项时,更倾向于选择你提供的领域词汇。
-
关键参数与应用:
-
hotwords参数:这是最直接的领域词汇增强方法。你可以将需要重点识别的词汇(如"血小板减少症")以列表形式传入,模型在识别时会对其有所偏重。 -
initial_prompt的复用:这个参数同样可以用于领域增强。在开始转录前,提供一段包含领域关键词的文本作为提示,能引导模型适应特定的语言风格和术语。 -
实际场景:在客服质检系统中,可以通过设置
hotwords = ["投诉", "退款", "预约"]等关键词,确保这些关键动作被准确捕捉,从而触发后续的质检流程。
-
💡 实践与参数调优
将上述两种技术结合使用,并辅以适当的参数调优,可以达到最佳效果。
-
协同工作流:在实际应用中,通常先使用
initial_prompt为整个任务设定领域基调和上下文背景,然后再利用hotwords精准强化核心术语的识别。 -
参数调优建议:
-
对于高质量、清晰的音频,可以降低
temperature(如设为0),让输出更稳定、更确定。 -
在实时处理场景下,可以考虑将
condition_on_previous_text设为False,虽然会损失少量上下文信息,但有助于降低延迟。 -
适当增大
beam_size参数(如5或10),可以在一定程度上提升识别的准确性。
-
希望以上解释能帮助你更好地理解并运用这两项技术。如果你的应用场景涉及某个特定领域,不妨分享一下,或许我可以提供更具针对性的参数设置建议。