时间序列数据预测:14种机器学习与深度学习模型
当数据呈现复杂的非线性模式、序列间存在高度互动或数据量巨大时,传统统计模型的假设可能不再成立。此时,机器学习和深度学习模型展现出强大的能力。这些模型通常将时间序列预测问题转化为监督学习问题:使用过去的k个时间步(特征)来预测未来的一个或多个时间步(标签)。
经典机器学习回归模型
这类模型本身并非为时间序列设计,但通过巧妙的特征工程,它们可以非常有效地用于预测任务。
特征工程: 这是应用这些模型的关键。通常包括:
- 滞后特征 (Lag Features): 使用
y(t-1), y(t-2), ...作为预测y(t)的特征。 - 时间特征 (Time-based Features): 从时间戳中提取年、月、日、星期几、小时、是否节假日等作为特征。
- 窗口特征 (Window Features): 计算过去一段时间的统计量,如移动平均、移动标准差等。
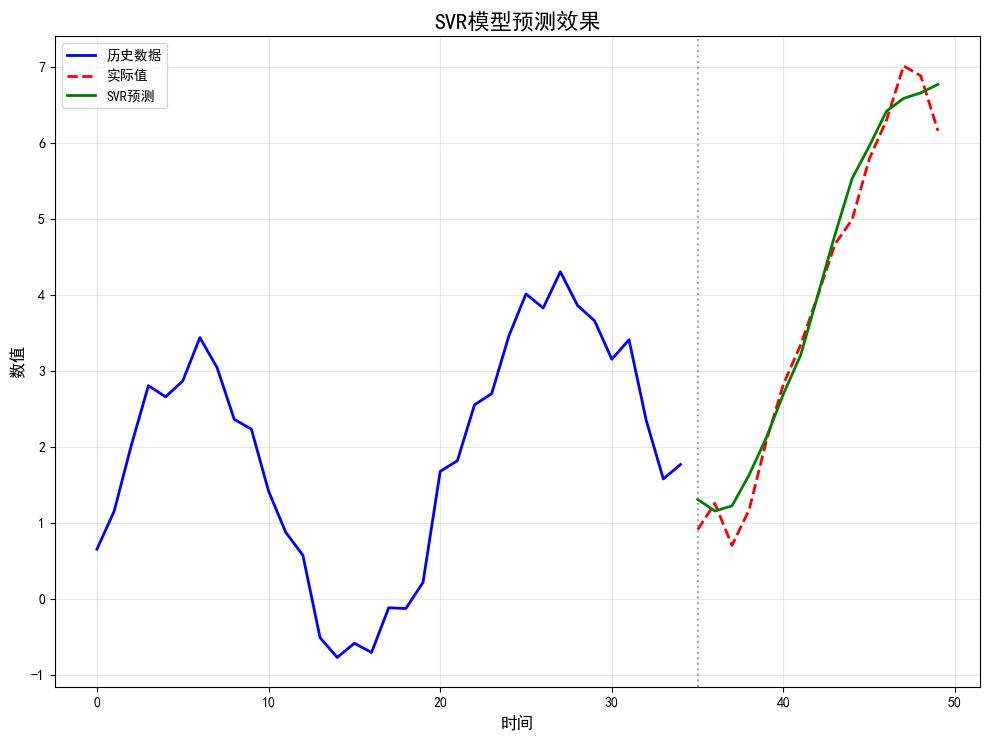
1.支持向量回归 (Support Vector Regression, SVR)
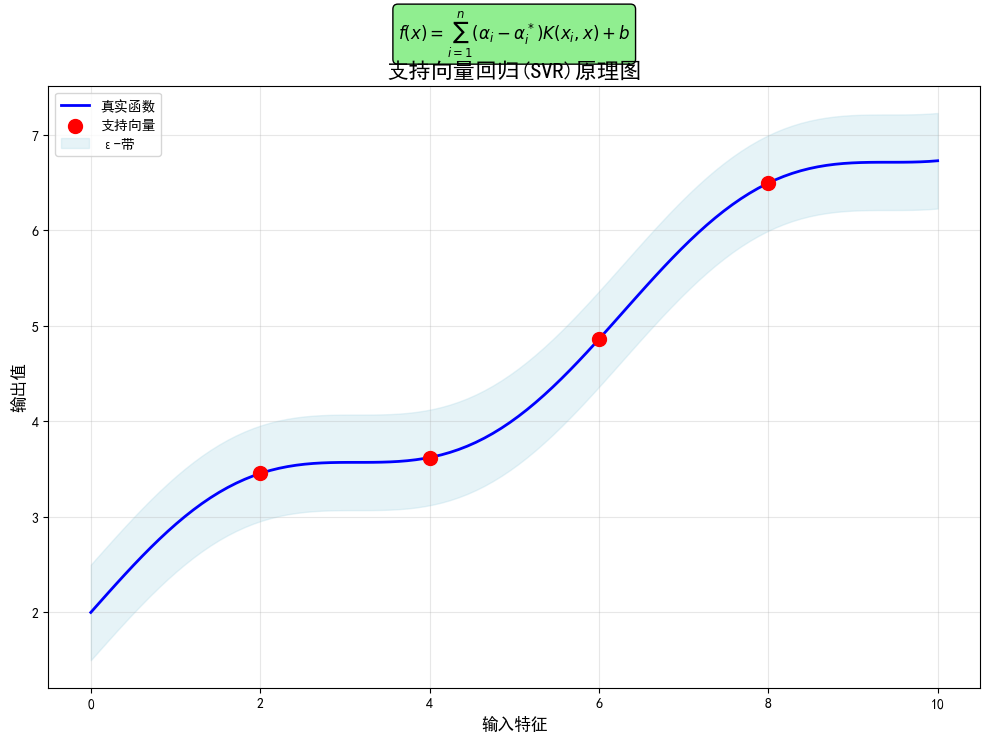
SVR是支持向量机(SVM)在回归任务上的应用。它试图找到一个函数,使得尽可能多的样本点与该函数的偏差不超过一个阈值ε,同时最大化边界(margin)。通过核函数(如RBF核),SVR能有效捕捉非线性关系。
- 劣势与限制: 对大规模数据处理效率低;对缺失值和离群点敏感;参数选择对结果影响巨大 。
- 优势: 在小样本和非线性问题上表现良好 ;模型具有较好的泛化能力。
- 调参复杂度: 复杂。需要仔细调整核函数类型、正则化参数
C、核系数gamma和不敏感区域epsilon。 - 算法类型: 监督学习。
- 适用范围: 单变量或多变量(通过特征工程)。
2.随机森林回归 (Random Forest Regression)
随机森林是一种集成学习方法,它构建大量的决策树,每棵树都在随机抽样的样本子集和特征子集上训练。最终的预测结果是所有决策树预测值的平均值 。
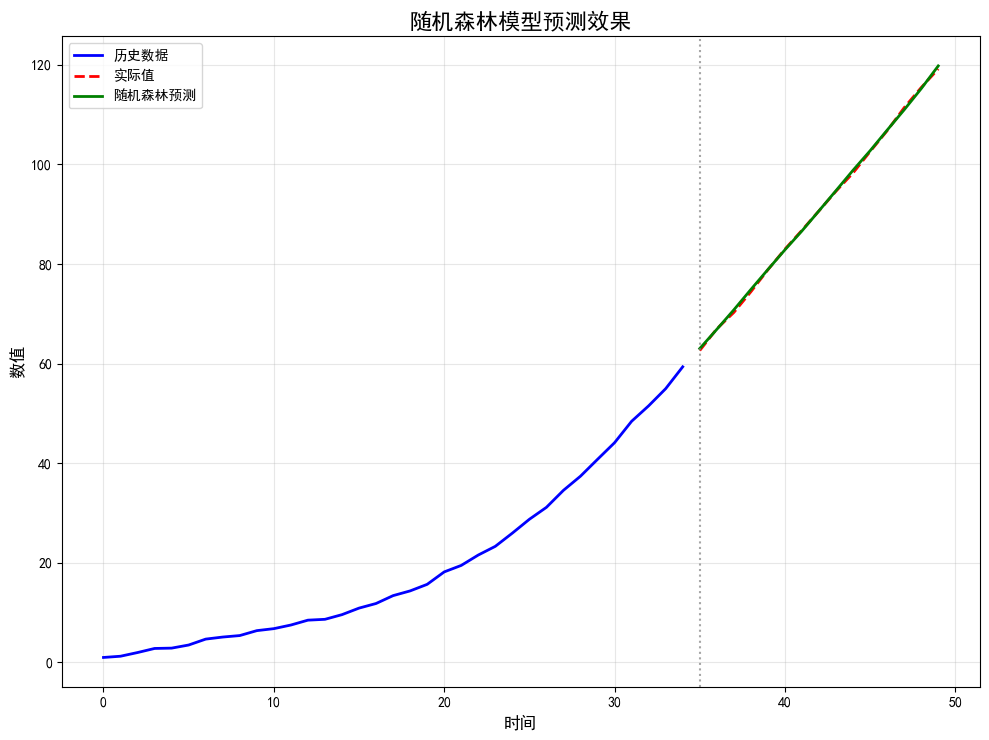
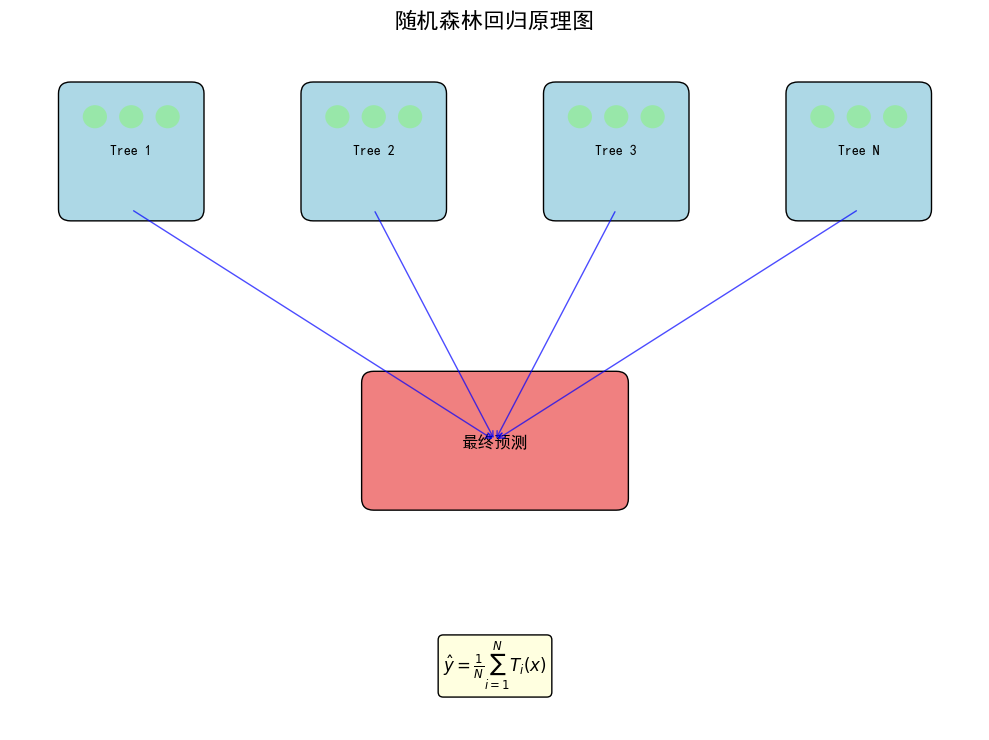
- 劣势与限制: 对于有明显趋势的数据,难以预测超出训练数据范围的值 ;模型可解释性较差(相对于单棵决策树)。
- 优势: 泛化能力强,不易过拟合;能够处理高维数据;能评估特征的重要性;对离群点和噪声有较好的鲁棒性 。
- 调参复杂度: 简单到中等。主要调整树的数量、树的深度、分裂所需最小样本数等,但对默认参数不敏感。
- 算法类型: 监督学习。
- 适用范围: 单变量或多变量(通过特征工程)。
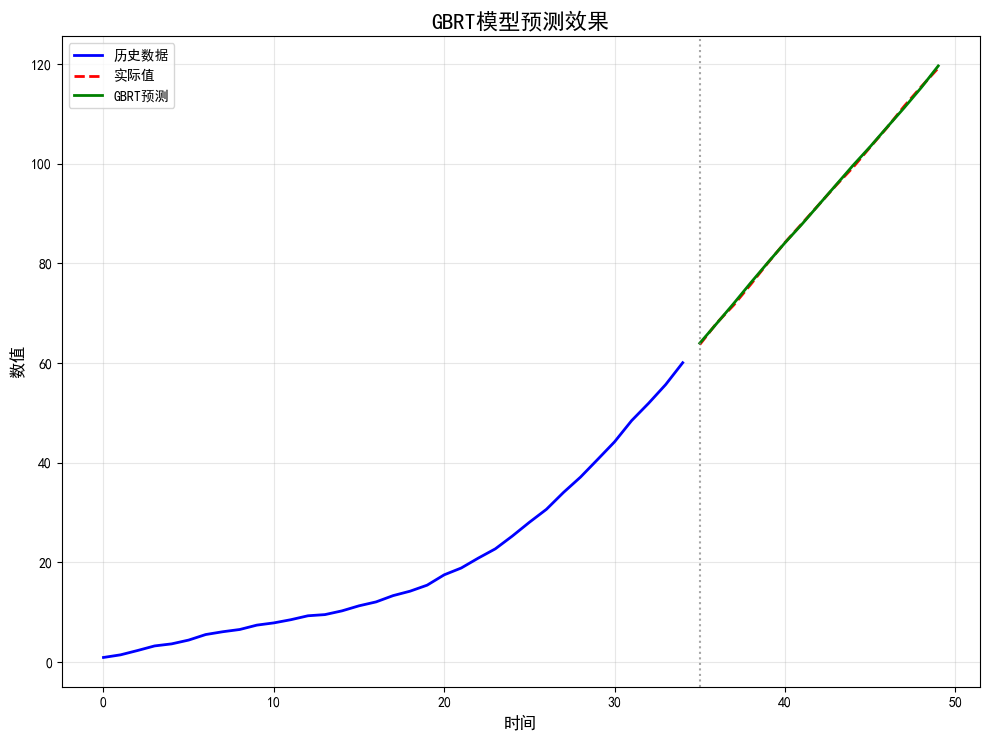
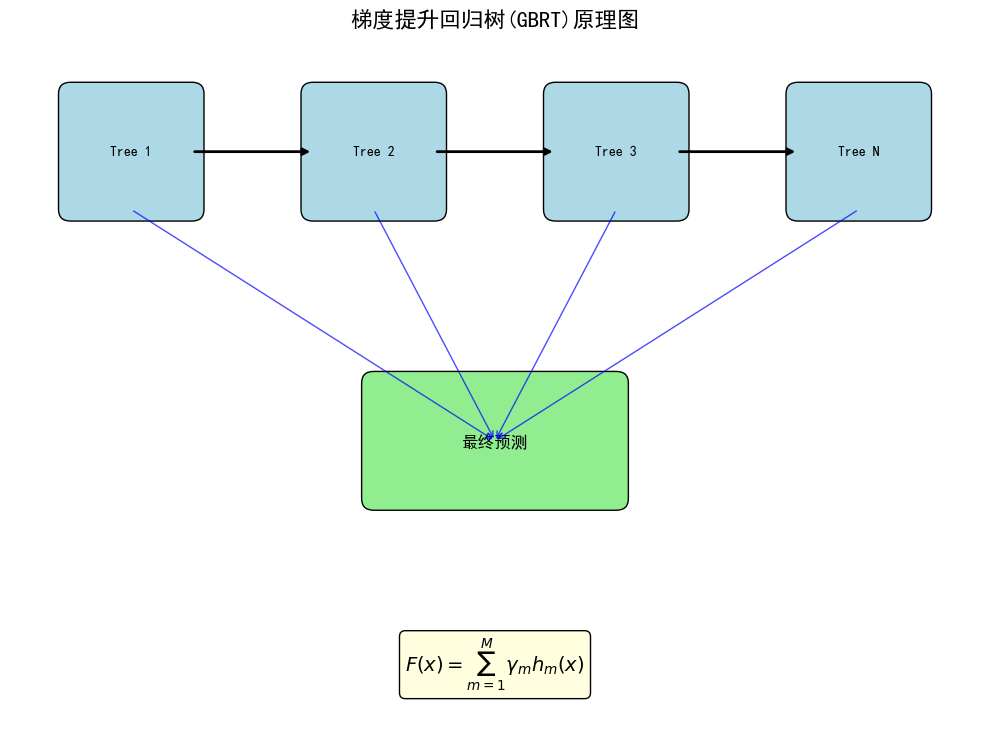
3.梯度提升回归树 (Gradient Boosting Regression Trees, GBRT)
GBRT也是一种集成学习方法,但它采用的是提升(Boosting)策略。它循序地构建决策树,每一棵新树都致力于修正前面所有树的残差(预测误差)。