多模态+CLIP | 视觉语言交互的终极形态?CLIP融合AIGC与持续学习,重塑多模态AI边界
随着人工智能的飞速发展,多模态学习正成为突破性的前沿领域,它旨在让机器像人类一样无缝整合视觉和语言信息,实现更深层次的感知与创造。CLIP(Contrastive Language-Image Pre-training) 作为视觉-语言模型,通过大规模图像-文本对训练,开启了零样本推理和跨模态理解的新时代。当前,研究者们正聚焦于如何增强多模态模型的语义对齐和持续学习能力,以释放AI在动态环境中的全部潜力,创新方向层出不穷:一是语义化标记技术,将低层视觉特征转化为高层语义表示,提升图像与文本的精细对齐;二是持续学习框架,通过参数高效的方法如低秩适应(LoRA),使模型在增量任务中保持零样本性能,避免遗忘历史知识。这些进展不仅降低了计算开销,还支持端到端的自适应系统,让AI能灵活应对从自动驾驶到智能创作的多样场景。尽管多模态融合仍存在平衡多任务冲突和确保泛化能力的难题,但CLIP驱动的技术演进正推动着人机交互的边界。未来,随着模型不断进化,我们有望见证更智能、更人性化的AI助手,彻底改变我们的生活和工作方式。
我这边也已经帮同学们整理好了10篇相关文章,不想多花时间找资料的可以直接拿,也欢迎大家分享本文给好友同学~
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/CilTbxg_TB4jqMPmPz1oqA
https://mp.weixin.qq.com/s/CilTbxg_TB4jqMPmPz1oqA
【论文1】《TokLIP: Marry Visual Tokens to CLIP for Multimodal Comprehension and Generation》
研究方法
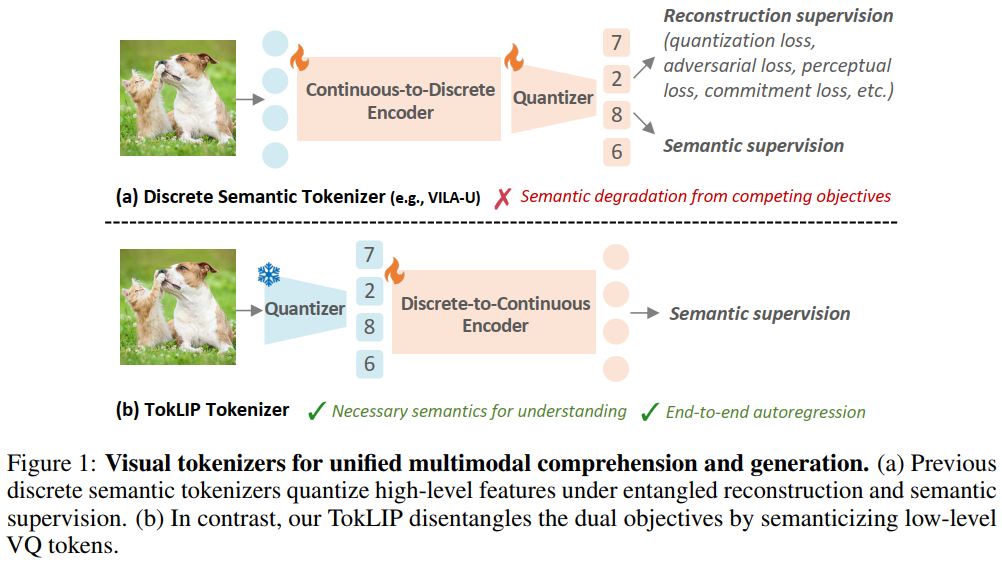
TokLIP的研究目标是构建一个强大的视觉标记器(Tokenizer),将图像转换为富含语义的表示,从而支撑单一的自回归Transformer模型同时支持多模态理解(如视觉问答)和生成(如文本到图像生成)任务。其方法核心是将低层离散标记语义化,而非将高层连续特征离散化。
-
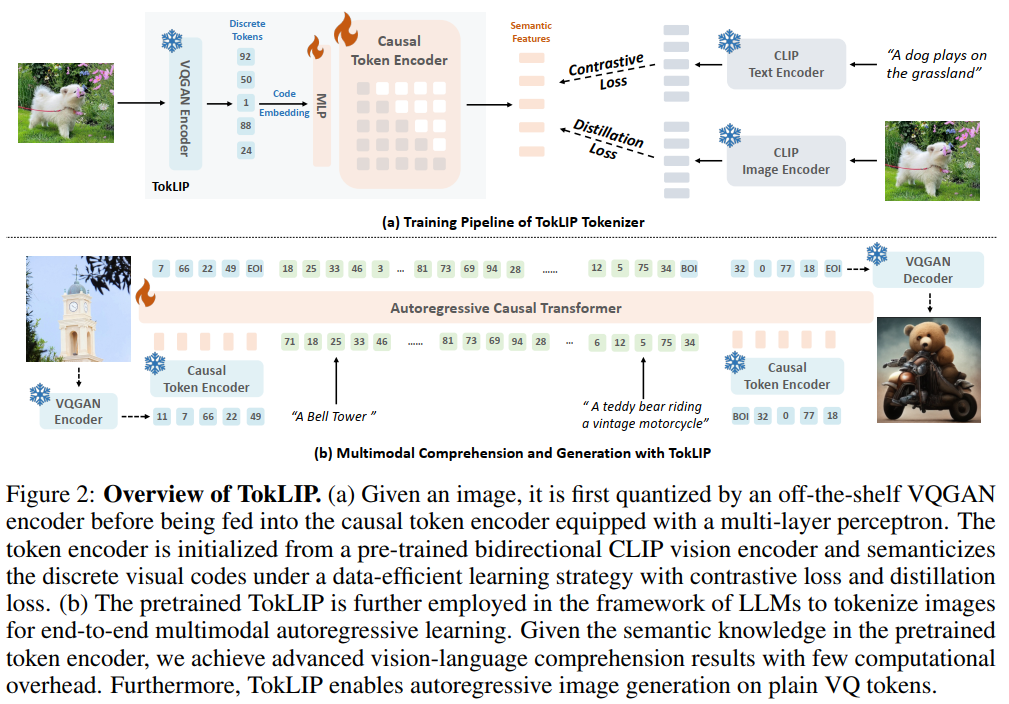
离散到连续的标记器架构 TokLIP由一个离线的低层VQ标记器(如VQGAN)和一个基于ViT的因果标记编码器(Token Encoder)组成。给定输入图像 ,首先通过VQGAN编码器 将其量化为离散标记的代码嵌入 。随后,通过一个多层感知机(MLP)将 映射到CLIP特征维度,并输入到标记编码器 中,最终输出富含高层连续语义的特征:
标记编码器采用因果注意力机制,以确保在后续与LLM结合进行自回归生成时,图像标记的生成符合自回归特性。
-
数据高效的训练目标 标记编码器从预训练的双向CLIP视觉编码器初始化,以继承其强大的语义理解能力。训练过程中,仅优化MLP和标记编码器,VQGAN编码器保持冻结,从而解耦了生成能力(由VQGAN保证)和理解能力(由标记编码器学习)的优化。训练使用两种监督信号:
-
对比损失():促使TokLIP输出的[CLS] token特征 与配对文本的特征 对齐。
-
蒸馏损失():最小化TokLIP输出的[CLS] token特征与教师CLIP模型输出的图像特征 之间的均方误差(MSE)。 总损失为:
这种设计使TokLIP能够高效地利用图像-文本对数据,将CLIP级别的语义注入到离散标记中。
-
-
在多模态自回归模型中的应用 预训练好的TokLIP被嵌入到大型语言模型(LLM)中。图像被TokLIP tokenizer转换为一系列视觉标记,与文本标记拼接后形成多模态序列,输入到一个单一的因果Transformer中。模型通过标准的下一个标记预测目标进行端到端训练,统一处理理解和生成任务。对于生成任务,TokLIP输出的高层语义特征与VQGAN的低层代码嵌入进行融合(如拼接),以同时保证生成质量和高层语义一致性。

创新点
-
离散到连续的标记器架构: TokLIP提出了一种新颖的标记器范式:语义化低层VQ标记(如VQGAN输出),而不是离散化高层CLIP特征(如VILA-U)。它使用现成的VQ tokenizer捕获低层纹理信息,然后通过一个ViT-based因果标记编码器(初始化为CLIP权重)和MLP投影器,将离散标记映射到连续语义空间。这种设计解耦了理解(高层语义)和生成(低层细节)的目标,避免了量化信息损失和训练冲突,支持端到端的多模态自回归训练。
-
创新性的训练策略与因果注意力机制: TokLIP的创新在于其训练策略:仅优化标记编码器和MLP,使用对比损失(图像-文本对齐)和蒸馏损失(与CLIP教师特征对齐)进行监督,无需复杂量化训练。这使得TokLIP在少量数据(如80M图像-文本对)上就能达到高性能,数据效率远高于现有方法(如VILA-U需要数百M数据)。同时,标记编码器采用因果注意力,确保与LLM结合时支持自回归生成,实现了真正统一的序列预测。
-
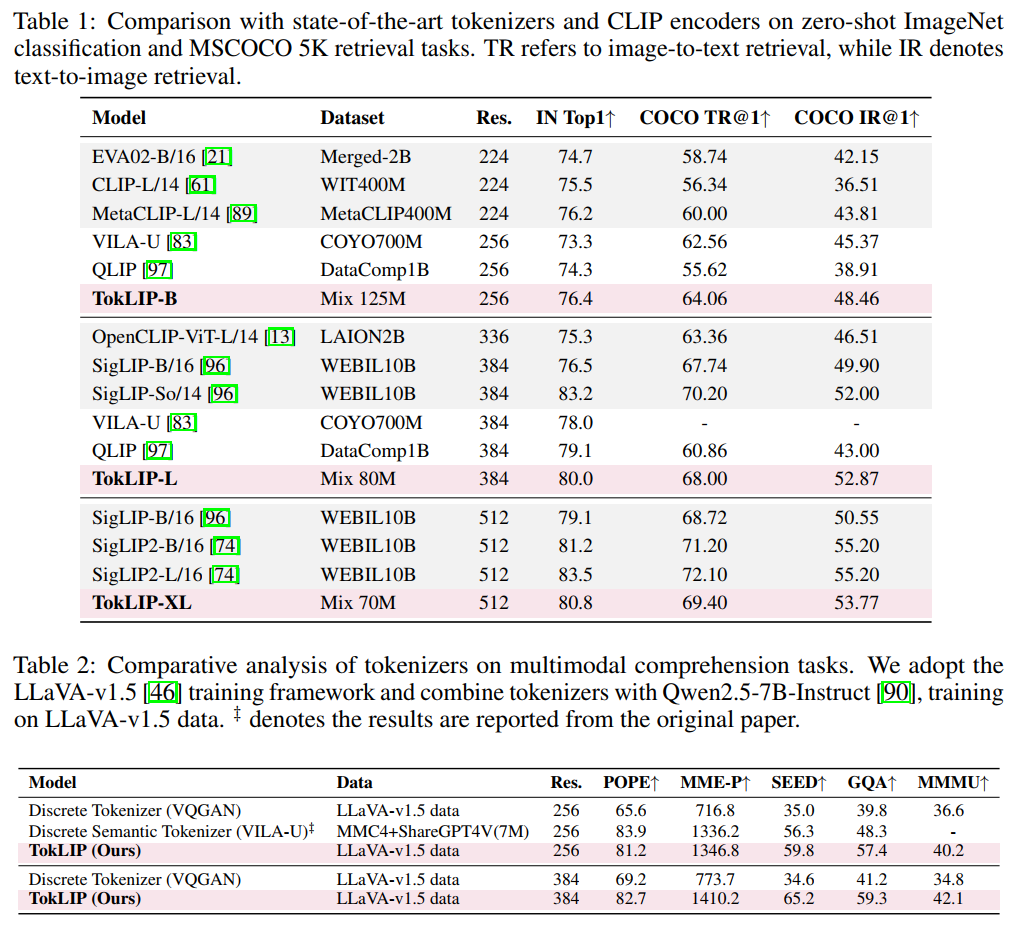
多模态理解与生成的协同增强: TokLIP首次实现了在单一因果Transformer中同时处理理解(如视觉问答)和生成(如文本到图像)任务,且性能协同提升。实验表明,TokLIP在零样本ImageNet分类和COCO检索上超越CLIP基线和现有标记器,并在图像生成中通过特征融合(如拼接低层和高层特征)提升质量。这一创新解决了多模态统一模型中理解与生成的任务冲突,为构建通用多模态AI提供了可行路径。
论文链接:https://arxiv.org/abs/2505.05422
【论文2】《C-Clip: Multimodal Continual Learning For Vision-Language Model》
研究方法
C-CLIP的核心研究目标是实现视觉-语言模型(如CLIP)在多个下游任务上的持续学习,即在适应新任务的同时,有效防止对旧任务的灾难性遗忘。其研究方法主要由两个核心组件构成:
-
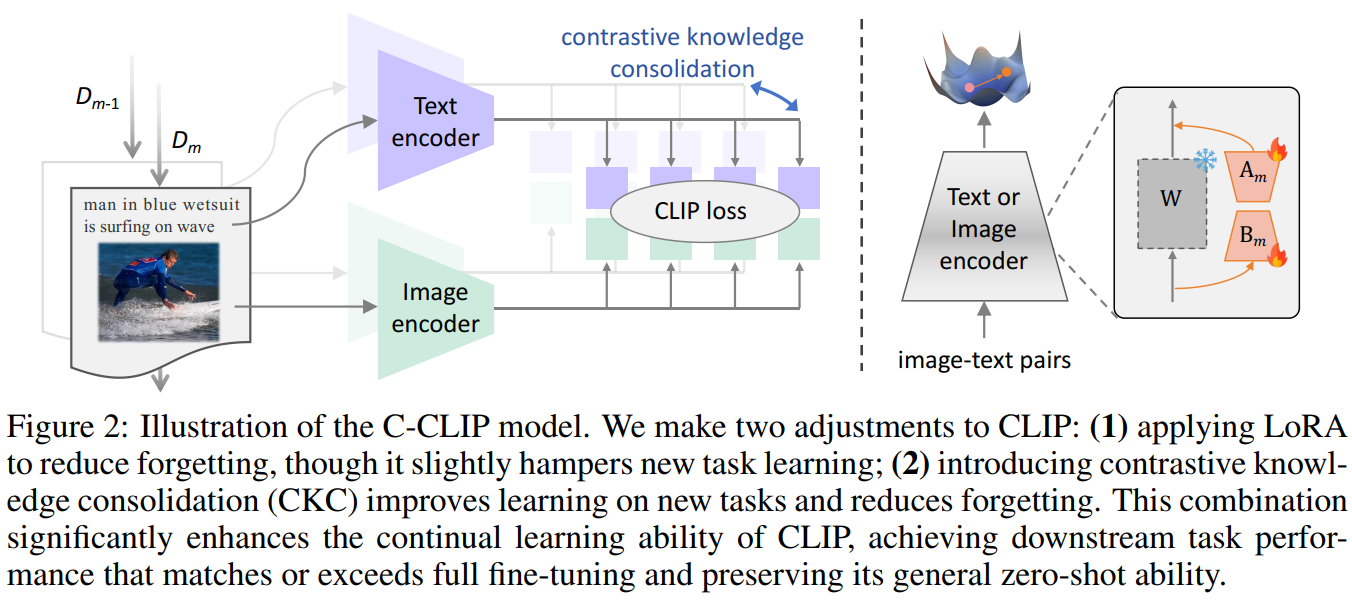
多模态低秩适应(LoRA)集成 此方法旨在减少模型微调过程中的可训练参数量,以作为避免遗忘的一种约束策略。具体而言,在视觉编码器 和文本编码器 的线性层中引入低秩分解矩阵 和 (其中秩 )。在持续学习的每个阶段,上一阶段的模型参数 被冻结,仅训练新添加的LoRA适配器。在每个阶段训练结束后,将LoRA参数以一定的缩放系数 集成到主干网络参数中:
理论分析表明,此操作等价于约束新模型参数与旧模型参数的变化范围,从而满足减少遗忘的优化目标。
在这里插入图片描述
-
对比知识巩固(Contrastive Knowledge Consolidation, CKC) 为了解决LoRA等方法在约束下学习新任务能力下降的问题,CKC被提出以同时增强学习能力和减少遗忘。其核心思想不是让新模型的特征空间简单地向旧模型对齐,而是通过对比学习使其变得更好。具体实现包含两个关键设计:
-
投影器(Projector):在编码器后引入一个可学习的投影头 ,将新、旧模型的特征映射到一个新的空间,以增加模型学习新任务的塑性。
-
对比学习策略:对于一个图像-文本对,将其在当前模型投影空间中的特征 与在旧模型特征空间中的特征 视为正样本对,而与其他样本的特征视为负样本对。通过InfoNCE损失函数进行对比学习,最大化正样本对的相似度,最小化负样本对的相似度。该损失与原始的CLIP对比损失共同构成训练目标:
-
创新点
-
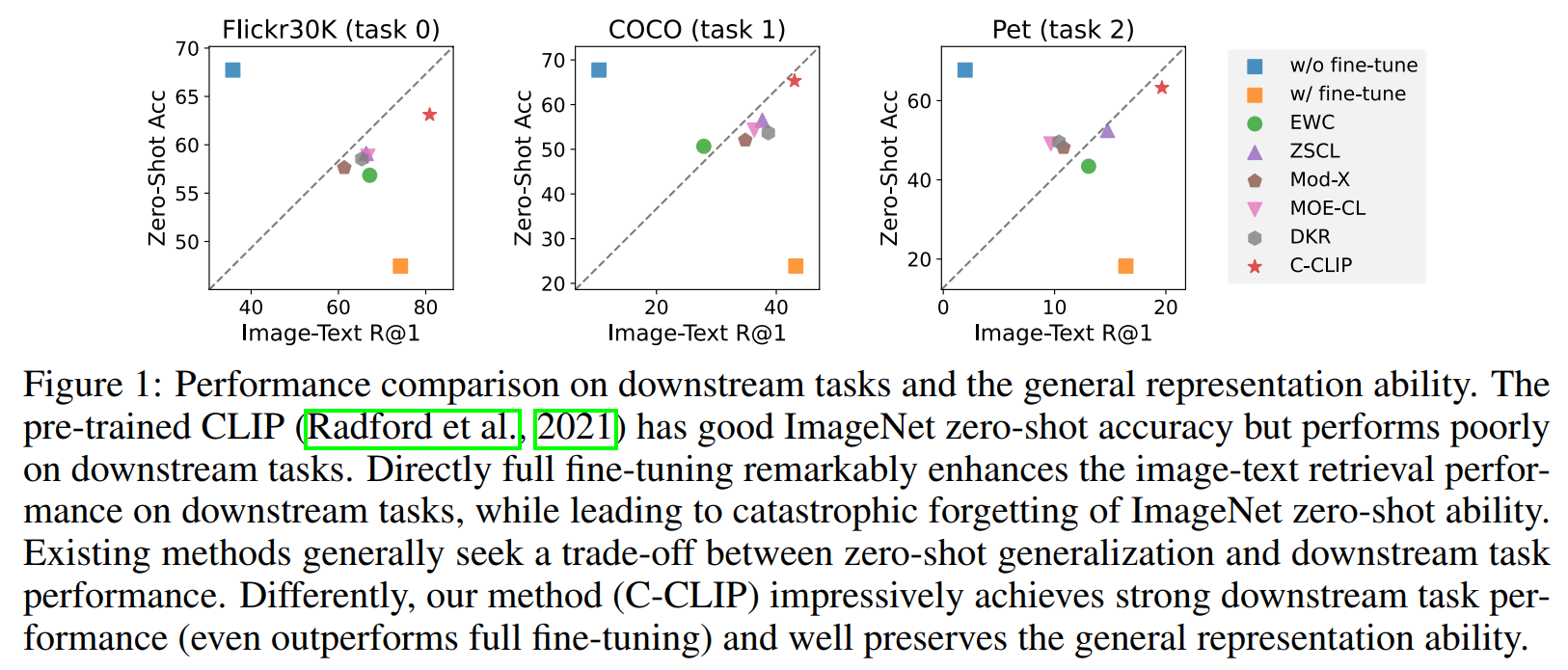
首创多模态持续学习基准(VLCL Benchmark): C-CLIP引入了Vision-Language Continual Learning (VLCL) benchmark,这是一个全面的评估框架,涵盖了多个图像-文本数据集(如Flickr30K、COCO、Pets等),并定义了三个评估轨道:多模态持续学习、零样本检索和零样本分类。该基准强调在持续学习过程中同时评估下游任务性能和模型的原生零样本泛化能力,填补了现有研究在多模态场景下评估标准不足的空白。与传统的类增量学习(CIL)或多任务增量学习(MTIL)不同,VLCL专注于图像-文本对的跨模态学习,更贴合实际应用需求。
-
创新性的框架设计: C-CLIP的核心创新在于其框架设计,它首次在持续学习中实现了同时优化新任务学习和旧知识保留,避免了传统方法(如EWC或LwF)中学习与遗忘的权衡。通过结合多模态低秩适应(LoRA)和对比知识巩固(CKC),C-CLIP不仅减少了灾难性遗忘,还显著增强了新任务的学习能力,甚至在某些下游任务上超越全微调性能。这一创新解决了多模态持续学习中的塑性-稳定性困境,为模型在开放世界中的持续适应提供了新思路。
-
泛化性好: C-CLIP通过大量实验证明了其在多个维度上的优势:在下游任务(如图像-文本检索)上表现卓越,在零样本检索和分类上保持接近原始CLIP的性能,且训练效率高。创新点还包括对零样本泛化能力的重点关注,这在以往持续学习工作中常被忽视。实验显示,C-CLIP在8个任务连续学习后,ImageNet零样本准确率下降最小(仅7.42%),显著优于现有方法。
论文链接:https://openreview.net/forum?id=sb7qHFYwBc
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/CilTbxg_TB4jqMPmPz1oqA
https://mp.weixin.qq.com/s/CilTbxg_TB4jqMPmPz1oqA