网站开发常用的谷歌插件企业首次建设网站的策划流程
上一篇《Docker部署Spark大数据组件》中,日志是输出到console的,如果有将日志输出到文件的需要,需要进一步配置。
配置将日志同时输出到console和file
1、停止spark集群
docker-compose down -v2、使用自带log4j日志配置模板配置
cp -f log4j2.properties.template log4j2.properties编辑log4j2.properties,进行如下修改;但是,如下方案,日志无法轮转,也就是说日志一直会写到spark.log中。
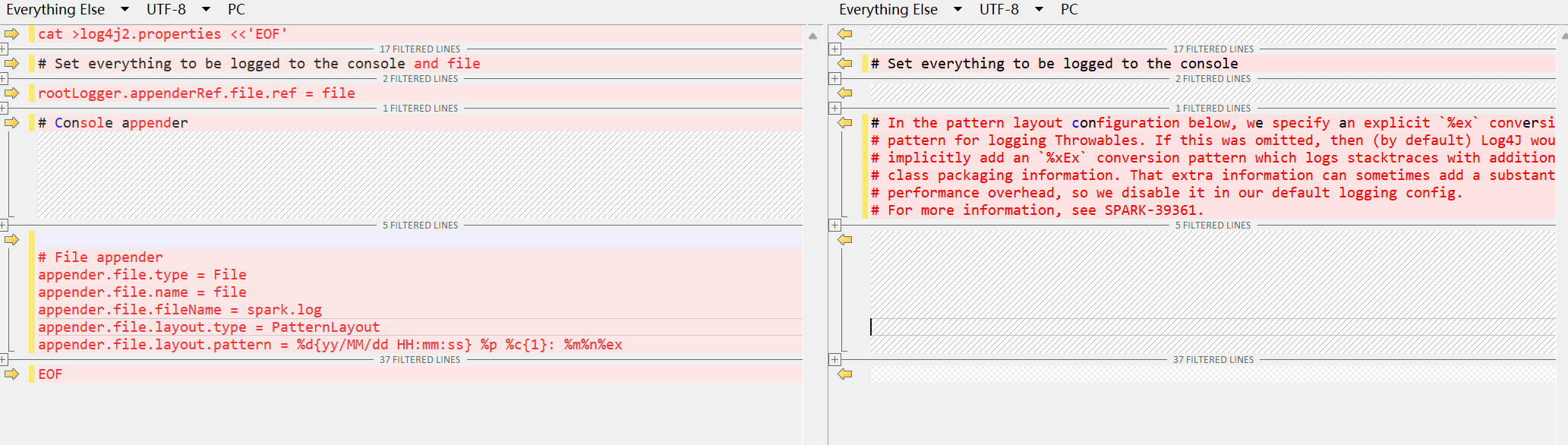
# Set everything to be logged to the console and file
……
rootLogger.appenderRef.file.ref = file
# File appender
appender.file.type = File
appender.file.name = file
appender.file.fileName = spark.log
appender.file.layout.type = PatternLayout
appender.file.layout.pattern = %d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n%ex
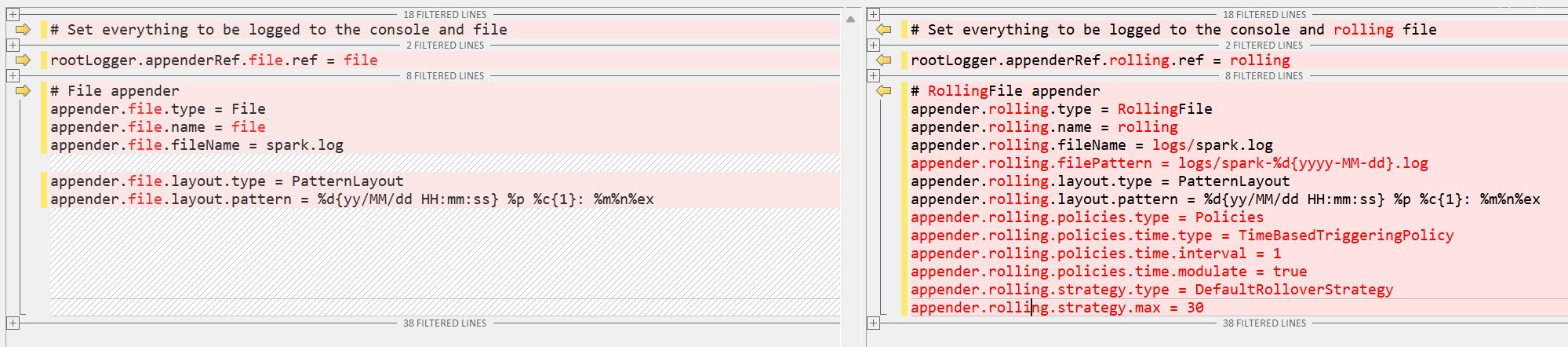
3、配置支持日志轮转
rootLogger.appenderRef.file.ref = file
改为
rootLogger.appenderRef.rolling.ref = rolling
# File appender 下的配置删掉,增加如下配置:
# RollingFile appender
appender.rolling.type = RollingFile
appender.rolling.name = rolling
appender.rolling.fileName = logs/spark.log
appender.rolling.filePattern = logs/spark-%d{yyyy-MM-dd}.log
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n%ex
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 1
appender.rolling.policies.time.modulate = true
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 30
可以直接使用如下配置模板:
cat >log4j2.properties <<'EOF'
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
## Set everything to be logged to the console and rolling file
rootLogger.level = info
rootLogger.appenderRef.stdout.ref = console
rootLogger.appenderRef.rolling.ref = rolling# Console appender
appender.console.type = Console
appender.console.name = console
appender.console.target = SYSTEM_ERR
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n%ex# RollingFile appender
appender.rolling.type = RollingFile
appender.rolling.name = rolling
appender.rolling.fileName = logs/spark.log
appender.rolling.filePattern = logs/spark-%d{yyyy-MM-dd}.log
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n%ex
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 1
appender.rolling.policies.time.modulate = true
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 30# Set the default spark-shell/spark-sql log level to WARN. When running the
# spark-shell/spark-sql, the log level for these classes is used to overwrite
# the root logger's log level, so that the user can have different defaults
# for the shell and regular Spark apps.
logger.repl.name = org.apache.spark.repl.Main
logger.repl.level = warnlogger.thriftserver.name = org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver
logger.thriftserver.level = warn# Settings to quiet third party logs that are too verbose
logger.jetty1.name = org.sparkproject.jetty
logger.jetty1.level = warn
logger.jetty2.name = org.sparkproject.jetty.util.component.AbstractLifeCycle
logger.jetty2.level = error
logger.replexprTyper.name = org.apache.spark.repl.SparkIMain$exprTyper
logger.replexprTyper.level = info
logger.replSparkILoopInterpreter.name = org.apache.spark.repl.SparkILoop$SparkILoopInterpreter
logger.replSparkILoopInterpreter.level = info
logger.parquet1.name = org.apache.parquet
logger.parquet1.level = error
logger.parquet2.name = parquet
logger.parquet2.level = error# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
logger.RetryingHMSHandler.name = org.apache.hadoop.hive.metastore.RetryingHMSHandler
logger.RetryingHMSHandler.level = fatal
logger.FunctionRegistry.name = org.apache.hadoop.hive.ql.exec.FunctionRegistry
logger.FunctionRegistry.level = error# For deploying Spark ThriftServer
# SPARK-34128: Suppress undesirable TTransportException warnings involved in THRIFT-4805
appender.console.filter.1.type = RegexFilter
appender.console.filter.1.regex = .*Thrift error occurred during processing of message.*
appender.console.filter.1.onMatch = deny
appender.console.filter.1.onMismatch = neutral
EOF验证生效
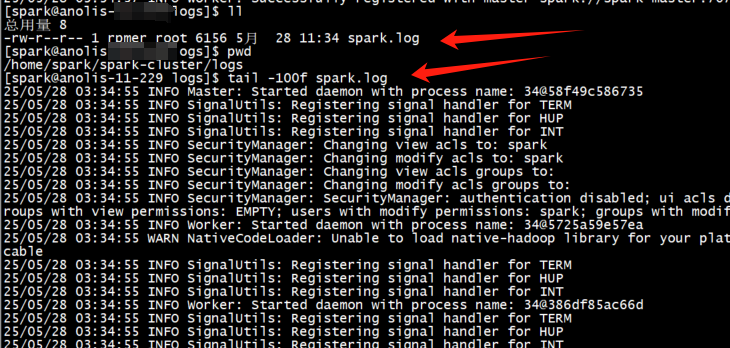
1、启动spark集群
2、查看日志文件