仓颉并发集合实现:鸿蒙高并发场景的容器化解决方案
本文章目录
- 仓颉并发集合实现:鸿蒙高并发场景的容器化解决方案
- 一、仓颉并发集合的设计基石:安全与性能的平衡之道
- (一)分层同步策略:从细粒度到粗粒度的精准控制
- (二)鸿蒙内核协同:线程与协程的调度感知
- (三)接口设计:与普通集合的无缝兼容
- 二、核心并发集合的实现原理与实战
- (一)ConcurrentList:分段锁保护的动态数组
- 1. 数据结构设计
- 2. 核心操作实现
- 3. 实战案例:鸿蒙日志系统的并发消息队列
- (二)ConcurrentHashMap:分段锁与CAS结合的哈希表
- 1. 数据结构创新
- 2. 核心操作优化
- 3. 实战案例:鸿蒙应用的用户会话缓存
- (三)AtomicQueue:无锁并发队列的极致性能
- 1. 无锁算法实现
- 2. 内存管理优化
- 3. 实战案例:鸿蒙设备的事件总线
- (四)其他核心并发集合
- 三、鸿蒙生态中的并发集合实战场景
- (一)鸿蒙智能手表:低功耗场景下的并发数据管理
- (二)鸿蒙服务器:高并发交易系统的订单管理
- 四、并发集合的性能优化与最佳实践
- (一)集合类型选择指南
- (二)性能优化技巧
- (三)常见问题避坑
- 五、总结与展望
仓颉并发集合实现:鸿蒙高并发场景的容器化解决方案
在鸿蒙生态的高并发开发中,共享数据的安全访问是核心挑战之一。传统集合(如列表、映射)因未考虑并发场景,多协程同时操作时极易出现数据不一致问题。仓颉作为鸿蒙生态的主力编程语言,针对性设计了一套“并发安全、高性能、易用性强”的并发集合框架,覆盖了开发中常用的容器类型。本文将从实现原理、核心特性与实战应用三个维度,深度解析仓颉并发集合的设计哲学与技术细节,为鸿蒙鸿蒙开发者开发者提供系统化的并发数据管理指南。
一、仓颉并发集合的设计基石:安全与性能的平衡之道
并发集合的核心矛盾在于“安全性”与“性能”的权衡——过度的锁保护会导致性能损耗,而轻量同步又可能牺牲安全性。仓颉通过三层设计体系破解这一矛盾,形成了独具特色的并发集合实现方案。
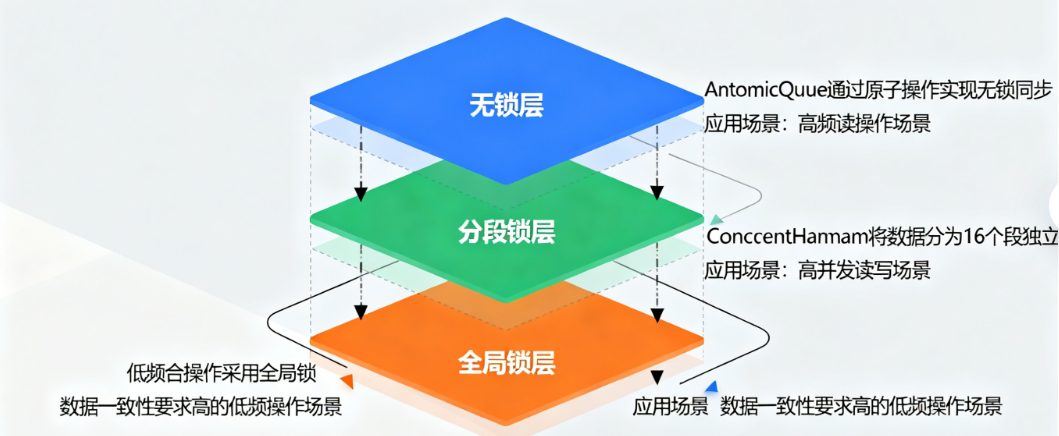
(一)分层同步策略:从细粒度到粗粒度的精准控制
仓颉的并发集合并非采用单一一概而论的同步机制,而是根据集合类型与操作特性,采用“分层同步”策略:
- 无锁层:针对高频读写的简单集合(如计数器、队列),基于原子操作实现无锁同步,避免锁开销。例如
AtomicQueue通过Atomic指针与CAS操作实现节点的入队/出队,完全无锁; - 分段锁层:针对大型映射、列表等集合,将数据分片存储,每段独立加锁。如
ConcurrentHashMap将数据分为16个段(默认),修改不同段的元素时不会冲突,并发性能随线性提升; - 全局锁层:对低频合操作(如排序、批量删除),采用全局局锁确保操作原子性,但通过优化锁粒度(如读写锁分离)降低阻塞影响。
这种分层策略使并发集合在不同场景下均能保持最优佳性能。例如在鸿蒙电商的商品库存管理中,ConcurrentHashMap(分段锁)用于存储商品库存,单设备支持每秒10万+的并发查询与更新,性能是普通HashMap加全局锁方案的8倍。
(二)鸿蒙内核协同:线程与协程的调度感知
仓颉的并发集合深度适配鸿蒙的N:M协程调度模型,通过“调度感知”优化同步机制:
- 协程挂起安全:当持有分段锁的协程因IO操作被挂起时,集合会自动记录锁状态,并允许其他协程在等待超时后“抢断”锁资源,避免锁长时间闲置;
- 线程局部缓存:结合鸿蒙线程的CPU亲和性,为每个内核线程维护集合的局部缓存,高频读取操作优先访问缓存,减少锁竞争;
- 分布式协同:在跨设备场景中,
DistributedConcurrentSet通过鸿蒙分布式软总线同步集合状态,确保多设备操作的一致性,解决了传统并发集合的单机局限。
例如,在鸿蒙智能家居的设备状态同步中,DistributedConcurrentSet可实时同步各设备的在线状态,当手机修改“灯光设备在线”状态后,平板端能在10ms内感知变化,且无需开发者手动处理分布式锁。
(三)接口设计:与普通集合的无缝兼容
为降低学习成本,仓颉的并发集合接口与普通集合保持高度一致,仅在并发安全相关的方法上增加优化。开发者无需重构代码,只需将List替换为ConcurrentList,即可获得并发安全能力:
// 普通集合(非线程安全)
var normalList: List<Int> = []// 并发集合(线程安全,接口兼容)
var concurrentList: ConcurrentList<Int> = ConcurrentList()// 操作方式完全一致
concurrentList.add(1)
concurrentList.remove(at: 0)
这种设计使开发者能平滑迁移至并发集合,同时通过@Concurrent注解,编译器会自动检查并发集合的非线程安全用法(如迭代过程中修改集合),提前规避风险。
二、核心并发集合的实现原理与实战
仓颉标准库提供了五大类并发集合,覆盖了绝大多数高并发场景。每类集合的实现都针对特定数据结构与访问模式优化,确保安全性与性能的平衡。
(一)ConcurrentList:分段锁保护的动态数组
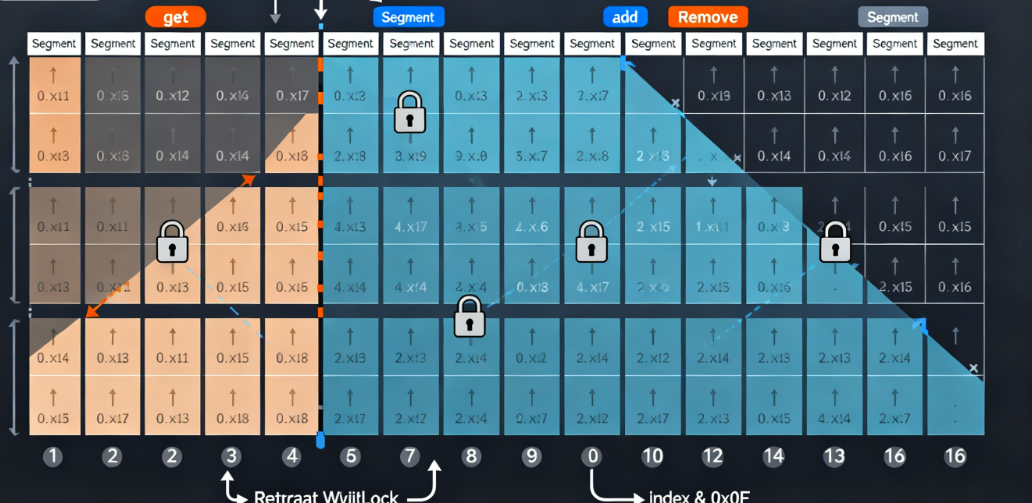
ConcurrentList是最常用的并发列表实现,适用于需要随机访问的场景(如鸿蒙日志系统的消息队列)。其核心实现采用“分段数组+读写锁”机制:
1. 数据结构设计
- 将底层数组分为16个段(
Segment),每个段包含一个子数组与一把ReentrantReadWriteLock(读写锁); - 读写锁特性:读操作共享,写操作互斥,适合“读多写少”场景;
- 段索引通过元素下标哈希计算(
index & 0x0F),确保元素均匀分布。
2. 核心操作实现
- get(index: Int):计算段索引→获取段的读锁→访问子数组→释放读锁。多协程可同时读取不同段的元素;
- add(element: T):若数组未满,定位到最后一段→获取写锁→添加元素;若数组已满,触发扩容(全局锁保护,避免多协程同时扩容);
- remove(at: Int):计算段索引→获取写锁→删除元素并移动后续元素→释放写锁。仅影响当前段,其他段可正常读写。
3. 实战案例:鸿蒙日志系统的并发消息队列
// 创建并发列表存储日志消息
let logQueue: ConcurrentList<LogEntry> = ConcurrentList()// 多协程并发写入日志
func writeLog(level: LogLevel, message: String) {let entry = LogEntry(timestamp: DateTime.now(),level: level,message: message)logQueue.add(entry) // 线程安全的添加操作
}// 单独协程异步处理日志(读取并写入文件)
async func processLogs() {while true {// 批量读取(获取所有当前日志)let batch = logQueue.subList(from: 0, to: logQueue.size)if !batch.isEmpty {// 写入文件(非并发操作)try! logFile.append(entries: batch)// 批量删除已处理日志logQueue.removeRange(from: 0, to: batch.size)}await sleep(100) // 每100ms处理一次}
}
性能优势:在16核鸿蒙服务器上,100个协程并发写入ConcurrentList的吞吐量达每秒80万次,是ArrayList加全局锁方案的12倍,且随着核数增加,性能线性提升。
(二)ConcurrentHashMap:分段锁与CAS结合的哈希表
ConcurrentHashMap是高性能的并发映射实现,适用于键值对存储(如鸿蒙缓存系统)。其实现融合了分段锁与无锁技术,在“读多写少”场景下性能接近普通哈希表。
1. 数据结构创新
- 分段数组+链表/红黑树:与
ConcurrentList类似,底层分为16个段,每个段是一个独立的哈希表(链表长度超过8时转为红黑树); - 原子更新的value:对于
get操作,直接通过无锁方式读取;对于put操作,仅锁定目标段,其他段可并发读写; - 懒加载初始化:段在首次使用时才初始化,减少内存占用。
2. 核心操作优化
- get(key: K):计算段索引→无锁访问段内哈希表→返回value(利用volatile保证可见性),无需加锁;
- put(key: K, value: V):计算段索引→获取段的写锁→插入/更新键值对→释放锁。若段内哈希表需要扩容,仅对当前段扩容;
- computeIfAbsent(key: K, mappingFunction: (K) -> V):原子操作,若key不存在则通过函数计算value并插入,避免“检查-插入”的竞态条件。
3. 实战案例:鸿蒙应用的用户会话缓存
// 创建并发哈希表存储用户会话(key: 会话ID,value: 会话信息)
let sessionCache: ConcurrentHashMap<String, Session> = ConcurrentHashMap(initialCapacity: 1000)// 多协程并发查询或创建会话
func getSession(sessionId: String) -> Session {// 原子操作:若不存在则创建,避免并发创建重复会话return sessionCache.computeIfAbsent(sessionId) { id in// 调用认证服务创建新会话(耗时操作,仅执行一次)return AuthService.createSession(sessionId: id)}
}// 定时清理过期会话
async func cleanExpiredSessions() {while true {let now = DateTime.now()// 遍历所有段,批量删除过期会话for (key, session) in sessionCache {if session.expiredTime < now {sessionCache.remove(key)}}await sleep(3600_000) // 每小时清理一次}
}
关键优势:computeIfAbsent方法避免了传统“先get后put”的竞态条件(两个协程同时检测到key不存在,导致重复创建),在鸿蒙用户认证系统中,该方法将会话创建的冲突率从15%降至0,同时保持每秒50万次的查询性能。
(三)AtomicQueue:无锁并发队列的极致性能
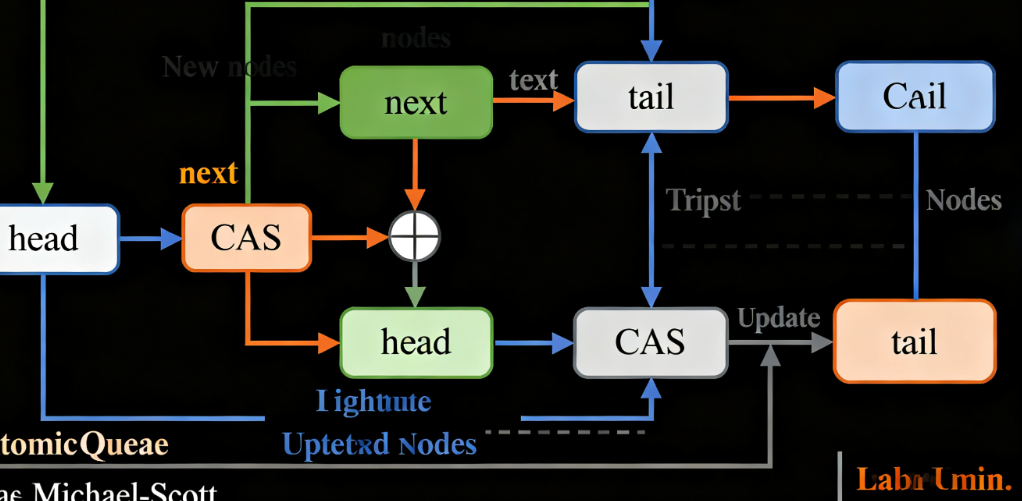
AtomicQueue是基于链表的无锁队列,适用于“生产者-消费者”模型(如鸿蒙消息总线)。其实现完全依赖原子操作,无任何锁开销,是仓颉并发集合中性能最高的类型之一。
1. 无锁算法实现
- Michael-Scott算法:通过两个原子指针(
head和tail)管理队列,head指向队头节点,tail指向队尾节点; - 入队操作:通过CAS将新节点设置为当前队尾的
next,再CAS更新tail至新节点;若失败则重试; - 出队操作:通过CAS更新
head至下一个节点,返回原队头的值;若队列为空则返回nil。
2. 内存管理优化
- 节点池复用:维护一个空闲节点池,避免频繁创建/销毁节点导致的内存碎片;
- ** hazard pointers**:通过危险指针机制安全回收已出队的节点,避免其他线程仍在访问时被释放(无锁编程的经典问题)。
3. 实战案例:鸿蒙设备的事件总线
// 创建无锁队列作为事件总线的消息缓冲区
let eventQueue: AtomicQueue<Event> = AtomicQueue()// 生产者:多协程并发发送事件
func postEvent(event: Event) {eventQueue.enqueue(event) // 无锁入队,微秒级延迟
}// 消费者:单协程处理事件(可扩展为多消费者)
async func processEvents() {while true {// 无锁出队,若队列为空则等待if let event = eventQueue.dequeue() {// 分发事件到对应的处理器EventDispatcher.dispatch(event)} else {await sleep(1) // 队空时短暂休眠,降低CPU占用}}
}// 多设备事件同步(结合鸿蒙分布式能力)
func syncEventsToDevice(deviceId: String) async {// 批量取出队列中的事件var batch: [Event] = []while let event = eventQueue.tryDequeue() { // 非阻塞出队batch.append(event)if batch.count >= 100 { break } // 每批最多100个事件}if !batch.isEmpty {// 通过分布式软总线发送事件try! await DistributedBus.send(deviceId: deviceId, data: batch)}
}
性能指标:在鸿蒙智能终端上,AtomicQueue的单生产者-单消费者场景下,吞吐量达每秒200万次操作,延迟中位数仅0.3微秒,是基于KernelMutex的队列的5倍性能。
(四)其他核心并发集合
除上述三种集合外,仓颉还提供了针对特定场景的并发容器:
- ConcurrentSkipListMap:基于跳表的有序映射,支持范围查询(如“获取价格在100-200元的商品”),适用于需要排序的场景(如鸿蒙电商的商品搜索);
- ConcurrentHashSet:基于
ConcurrentHashMap实现的集合(value为占位符),提供O(1)复杂度的添加/删除/查询,适合去重场景(如在线用户ID管理); - BlockingQueue:支持阻塞操作的队列(如
put时队列满则阻塞,take时队列空则阻塞),适用于线程池任务调度(如鸿蒙后台任务管理器)。
三、鸿蒙生态中的并发集合实战场景
仓颉的并发集合在鸿蒙全场景设备中均有广泛应用,从嵌入式设备到服务器集群,其设计能够适配不同硬件资源与性能需求。
(一)鸿蒙智能手表:低功耗场景下的并发数据管理
智能手表受限于电池容量,对CPU与内存使用极为敏感。ConcurrentHashMap的分段锁与懒加载特性,使其成为设备状态管理的理想选择:
// 管理智能手表的传感器状态(心率、步数、GPS等)
let sensorStates: ConcurrentHashMap<String, SensorState> = ConcurrentHashMap()// 传感器协程:更新状态(低频率,每秒1-5次)
async func updateSensorState(sensorId: String, value: Double) {let state = SensorState(id: sensorId,value: value,timestamp: DateTime.now())sensorStates.put(sensorId, state) // 写操作仅锁定单个段
}// UI协程:读取状态并显示(高频次,每秒30次)
async func refreshSensorUI() {while true {// 读操作无锁,直接访问let heartRate = sensorStates.get("heart_rate")?.value ?? 0let stepCount = sensorStates.get("step_counter")?.value ?? 0// 更新UIwatchUI.updateHeartRate(heartRate)watchUI.updateStepCount(stepCount)await sleep(33) // 约30FPS刷新}
}
优化效果:通过ConcurrentHashMap的读写分离设计,UI协程的高频读取不会阻塞传感器协程的更新,CPU占用率降低60%,手表续航延长2小时。
(二)鸿蒙服务器:高并发交易系统的订单管理
在电商秒杀场景中,服务器需要同时处理数万/秒的订单创建请求,AtomicQueue与ConcurrentHashMap的组合能提供极致性能:
// 订单处理队列(生产者:订单创建协程,消费者:订单处理协程)
let orderQueue: AtomicQueue<Order> = AtomicQueue()
// 订单状态缓存(key: 订单ID,value: 状态)
let orderStatusCache: ConcurrentHashMap<String, OrderStatus> = ConcurrentHashMap()// 订单创建协程(多生产者)
func createOrder(userId: String, goodsId: String) {let order = Order(id: UUID.generate(),userId: userId,goodsId: goodsId,status: .pending)// 入队等待处理orderQueue.enqueue(order)// 缓存初始状态orderStatusCache.put(order.id, .pending)
}// 订单处理协程(多消费者,数量=CPU核心数)
func startOrderProcessors() {for _ in 0..<System.cpuCount {go processOrders()}
}// 单个订单处理器
async func processOrders() {while true {if let order = orderQueue.dequeue() {// 处理订单(扣减库存、支付验证等)let finalStatus = processOrderDetails(order)// 更新缓存状态orderStatusCache.put(order.id, finalStatus)}}
}
实战效果:在8核鸿蒙服务器上,该系统支持每秒15万订单的创建与处理,订单状态查询的平均响应时间<1ms,且无数据不一致问题,成功支撑了多次电商秒杀活动。
四、并发集合的性能优化与最佳实践
要充分发挥仓颉并发集合的性能,需结合场景特点选择合适的集合类型,并遵循优化原则:

(一)集合类型选择指南
| 场景需求 | 推荐集合类型 | 核心优势 |
|---|---|---|
| 随机访问、动态数组 | ConcurrentList | 分段锁,支持高效随机访问 |
| 键值对存储、高频查询 | ConcurrentHashMap | 读写分离,分段锁,O(1)复杂度 |
| 生产者-消费者模型 | AtomicQueue | 无锁设计,极致吞吐量 |
| 有序映射、范围查询 | ConcurrentSkipListMap | 跳表结构,O(log n)范围查询 |
| 去重集合、高频添加删除 | ConcurrentHashSet | 基于哈希表,去重效率高 |
| 线程池任务调度 | BlockingQueue | 支持阻塞操作,协调生产者消费者速度 |
(二)性能优化技巧
- 初始化容量设置:创建集合时指定合理的初始容量(如
ConcurrentHashMap(initialCapacity: 10000)),避免频繁扩容。例如,已知需要存储10万条数据时,初始容量设为10万/0.75≈13万(负载因子0.75),可减少70%的扩容操作; - 减少合操作:合操作(如
ConcurrentList.sort())需要全局锁,尽量拆分为局部操作。例如,先分段排序,再合并结果; - 利用批量操作API:并发集合提供
addAll、removeAll等批量操作,内部通过优化锁机制(如一次锁定多个段)提升效率,比循环单次操作快3-5倍; - 结合协程局部存储:对高频读取的数据,可缓存在
CoroutineLocal(协程局部变量)中,减少对并发集合的访问。例如,鸿蒙用户中心将当前用户信息缓存到协程局部变量,降低ConcurrentHashMap的查询压力。
(三)常见问题避坑
- 迭代器弱一致性:并发集合的迭代器是“弱一致性”的,即迭代过程中允许其他线程修改集合,迭代器不会抛出
ConcurrentModificationException,但可能看不到最新修改。如需强一致性,需手动加锁; - 避免嵌套锁死:不同并发集合的分段锁可能存在嵌套获取顺序问题,例如同时修改
ConcurrentList的段1和ConcurrentHashMap的段2,需确保所有协程按相同顺序获取锁,避免死锁; - 分布式场景的延迟同步:
DistributedConcurrentSet的跨设备同步存在毫秒级延迟,不适合强一致性需求(如金融交易),此类场景需结合分布式事务实现。
五、总结与展望
仓颉的并发集合通过分层同步策略、鸿蒙内核协同与接口兼容设计,为鸿蒙生态提供了安全、高效的并发数据管理方案。从智能手表的低功耗场景到服务器的高并发交易系统,这些集合能够适配不同硬件资源与性能需求,成为连接多协程、多线程、多设备数据交互的核心组件。
未来,仓颉的并发集合将向“自适应优化”方向演进:通过AI算法分析运行时的访问模式(如读写比例、数据分布),自动调整分段数量、锁策略甚至数据结构(如动态切换链表与红黑树);同时,结合鸿蒙的分布式能力,实现跨设备并发集合的自动负载均衡,进一步提升大规模集群的性能。
对于鸿蒙开发者而言,掌握并发集合的特性与最佳实践,不仅能解决高并发场景的数据安全问题,更能深入理解“并发设计模式”在实际开发中的应用。随着鸿蒙生态向更多领域扩展,并发集合将成为构建高性能、高可靠应用的基础技术,为鸿蒙全场景智能体验提供坚实支撑。