Spring AI 搭建 RAG 个人知识库
现在大家对AI大模型又爱又恨,大模型统一的痛点
1、幻觉率比较高,它会无中生有
2、数据有延迟,比如豆包和DeepSeek训练数据只更新到2023
3、大模型没有内部数据,比如公司业务数据或个人数据大模型是拿不到的
基于大模型的局限性,RAG就火起来啦,让我们一起玩转RAG~
RAG (Retrieval-Augmented Generation,检索增强生成)
- 检索 - 从知识库中检索出相关的文档或段落
- 增强生成 - 基于知识库检索到的内容,生成一个更准确、更相关的回答
RAG 可不是知识库哦,它只是查询大模型的一种机制,真正的数据存储在向量库,相当于给大模型外挂一个库,先去知识库查一波,这波数据做上下文,让大模型基于我们给的数据和提示词在去查询,就是唉你没有的知识我给你,我管自己的小库,你管共享的大库,咱俩内外双修~
RAG = prompt+VectorStore->LLM
VectorStore (向量库) - 知识库
- 一个数据库Store
- 数据是向量Vector
- 把你的数据
embedding向量化存储到向量库 - springai支持这么多向量库
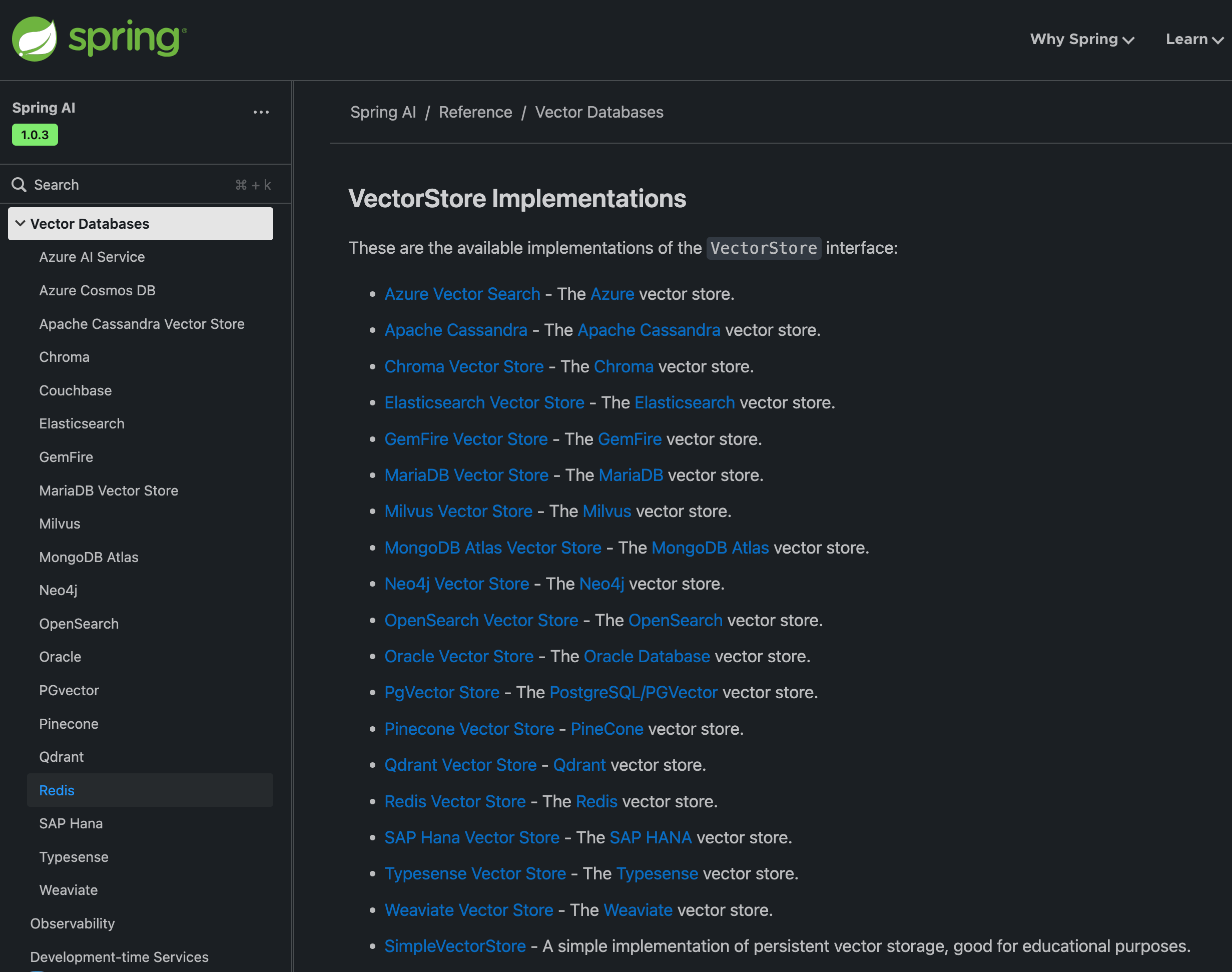
好了,概念了解了,想干啥也明确了,开动~
实战:
-
yml配置一个向量模型 -
定义一个向量库的bean,初始化你的知识库 -
将向量库放到chatClient -
正常使用chatclient
1、yml配置一个向量模型
可以去大模型服务平台百炼控制台模型广场选个喜欢的向量模型
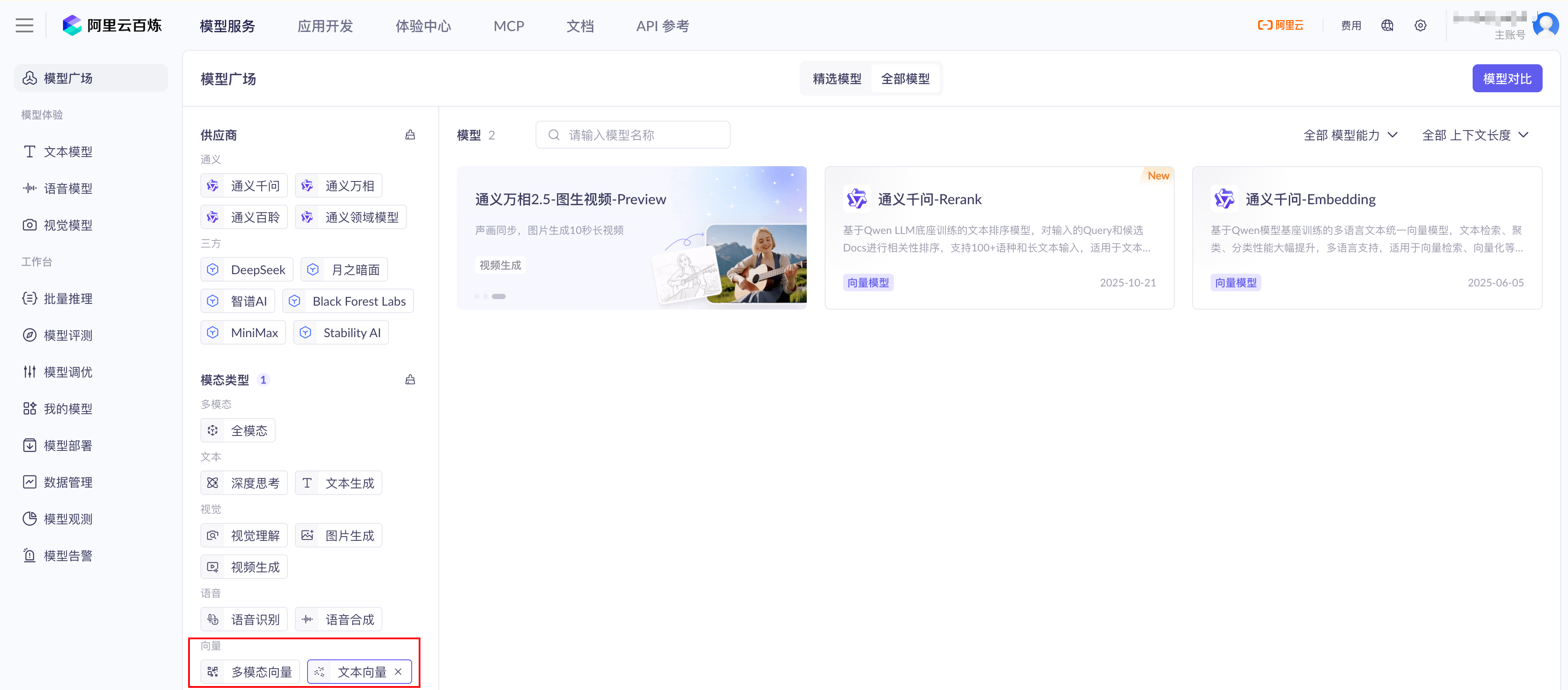
- embedding 向量模型配置 跟会话模型是平级的
- model 模型名
- dimensions 向量维度,可以先不管
spring:application:name: demoai:ollama:base-url: http://localhost:11434chat:model: deepseek-r1:7bopenai:base-url: https://dashscope.aliyuncs.com/compatible-modeapi-key: sk-2887ba54b68548ca9afc423d9edeeb5f#对话模型chat:options:model: qwen-max-latest#向量模型embedding:options:model: text-embedding-v4dimensions: 1024
2、 定义一个向量库的bean,初始化你的知识库
向量库都比较大,需要企业版,springai很贴心,给我们内置了一个简易的向量库SimpleVectorStore 本文就用这个
- 通过
SimpleVectorStore工厂创建一个bean SimpleVectorStore向量库其实就是一个map 看下源码就知道啦- 组装两个
Document初始化一下向量库,灌点数据 - 这个simpleVectorStore就是你的知识库啦
- 导入外部文件的工具springai也给封装好了,看官方文档就行了
@Beanpublic VectorStore vectorStore(OpenAiEmbeddingModel openAiEmbeddingModel) {SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(openAiEmbeddingModel).build();List<Document> documents = List.of(new Document("功夫熊猫的自我修养:姓名:阿宝\n" +"自我介绍:我叫李飞,没有脊椎,不以物喜,不以己悲:\n" +"爱好:\n" +"1.吃饭。\n" +"2. 睡觉\n" +"3. 打豆豆\n" +"4. 出去玩\n"),new Document("功夫熊猫的自我修养:姓名:阿宝\n" +"座右铭:天要刮风,天要下雨,天上有太阳\n" +"特长:\n" +"1. 反射弧特长\n" +"2. 梦中梦\n" +"3. 工作时长特长\n"));simpleVectorStore.add(documents);return simpleVectorStore;}
3、将向量库放到chatClient
- 定义会话工具
ChatClient - 定义系统角色
defaultSystem,它将以功夫熊猫的身份跟我会话 - 设置增强器
defaultAdvisors就是spring的aop QuestionAnswerAdvisor在调大模型前先调知识库就是它实现的SearchRequest它是查知识库的入参,有很多配置很重要,本文先不加,自己玩就行了
@Beanpublic ChatClient openAiClient(OpenAiChatModel model,VectorStore vectorStore,ChatMemory chatMemory) {return ChatClient.builder(model).defaultSystem("你是一只功夫熊猫,请以功夫熊猫的身份回答问题").defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory),new QuestionAnswerAdvisor(vectorStore,SearchRequest.builder().build())).build();}
4、正常使用chatclient
chatClient 啥也不用动
@Resourceprivate ChatClient openAiClient;@RequestMapping(value = "/chat",produces = "text/html;charset=utf-8")public Flux<String> chat(String prompt,String chatId) {return openAiClient.prompt().user(prompt).stream().content();}
5、开始会话
聊天窗口源码在上一篇SpringAI + DeepSeek本地大模型应用开发-聊天机器人,啥也不用动,直接运行
好啦,它已经读到了我的知识库内容,没有我的知识库,任何大模型不会跟你说功夫熊猫的特长是反射弧特长的哈哈,

下面就可以
- 安装可以持久化的数据库,
- 导入真实的数据充实你的知识库
那么,
- 知识库为什么叫向量库?
- 我们灌到知识库的数据是怎么存储的呢?
- 我们上面配置的
dimensions: 1024是什么意思呢? - 用户输入问题怎么在向量库检索的呢?
继续学习吧。。。fighting fighting fighting