LoRA个人理解
作为学习LoRA的笔记,方便理解与复习。
1.LoRA是用来干什么的?
LoRA全称Low-Rank Adaptation,中文译为低秩自适应。其本质是通过注入低秩分解矩阵来高效微调大模型,仅训练少量参数即可达到全参数微调的效果。
①全参数微调的含义
全参数微调是什么意思呢,这里假设一个极简的预训练模型,其中某一层的权重矩阵W是一个4×4矩阵,用于将4维输入特征转换为4维输出特征。:
这个矩阵是“满秩”的(秩为4),意味着它的4行(或4列)都是线性无关的,它能够表示4维空间中的任何变换。
现在,有一个新的下游任务(比如,分类猫和狗),传统的全参数微调会直接更新 W,得到一个新的矩阵 W′:
其中可能是另一个4×4的矩阵,它看起来是随机的、稠密的:
全参数微调的逻辑是:我们需要这样一个完整的来捕捉任务所需的所有复杂变化,这个
也是我们自己需要训练的内容。
虽然例子中举的极简模型仅有4×4=16个参数,但是在实际运用中,部分模型的参数量远不止如此,比如CLIP预训练模型的一个变体CLIP (ViT-B/32),其大致参数量约1.5亿,也就是说,如果要对这个模型进行全参数微调,那就要训练整整1.5亿的参数量,要是显卡性能差点,那估计跑冒烟了都跑不出个结果。
而LoRA就是为了解决这个问题产生的,其最直接的目的就是减少了微调模型时的参数量。
②LoRA的低秩假设
继续引用上文提到的权重矩阵W是一个4×4矩阵的极简模型。
LoRA认为:或许我们并不需要一个完整的4×4矩阵来表示更新,真正的有效更新可能存在于一个更简单的子空间中。
用人话说就是,我要用更小的矩阵来表示这个大的矩阵。
让我们设定LoRA的秩 r=2(这是LoRA的其中一个超参数),这意味着我们相信,学习这个新任务所需要的全部知识,可以通过一个秩为2的矩阵来注入。
LoRA将这个更新分解为两个小矩阵B和A的乘积:
其中
(一个“投影器”)
(一个“重建器”)
在训练中,我们随机初始化A和B,然后让模型学习,假设学习收敛后,我们得到了:
计算,得到:
此时就可以用计算得到的代替之前的
对模型进行微调,这一系列步骤就被称之为LoRA,也就是低秩自适应。
然而在这个例子中,需要训练4×4=16个参数,而计算
所用到的矩阵AB加起来也要训练8+8=16个参数,训练参数量并没有减少,这是怎么回事呢?
非常好的问题,实际上这只是因为我们的例子中4×4的权重矩阵太小了,如果我们把它扩大一些,比如是1000×1000的矩阵,那么这个时候需要训练1000×1000=1000000共100万个参数,而计算
需要训练1000×2+1000×2=4000个参数,仅需要前者的千分之四,即使LoRA的秩r再取一个更大的值,比如8,那么需要训练的参数也才增加到1000×8+1000×8=16000个,在全参数中的占比也是很小的。
2.LoRA在代码中如何使用?
这里的代码以Pytorch为例。
①LoRA层的实现
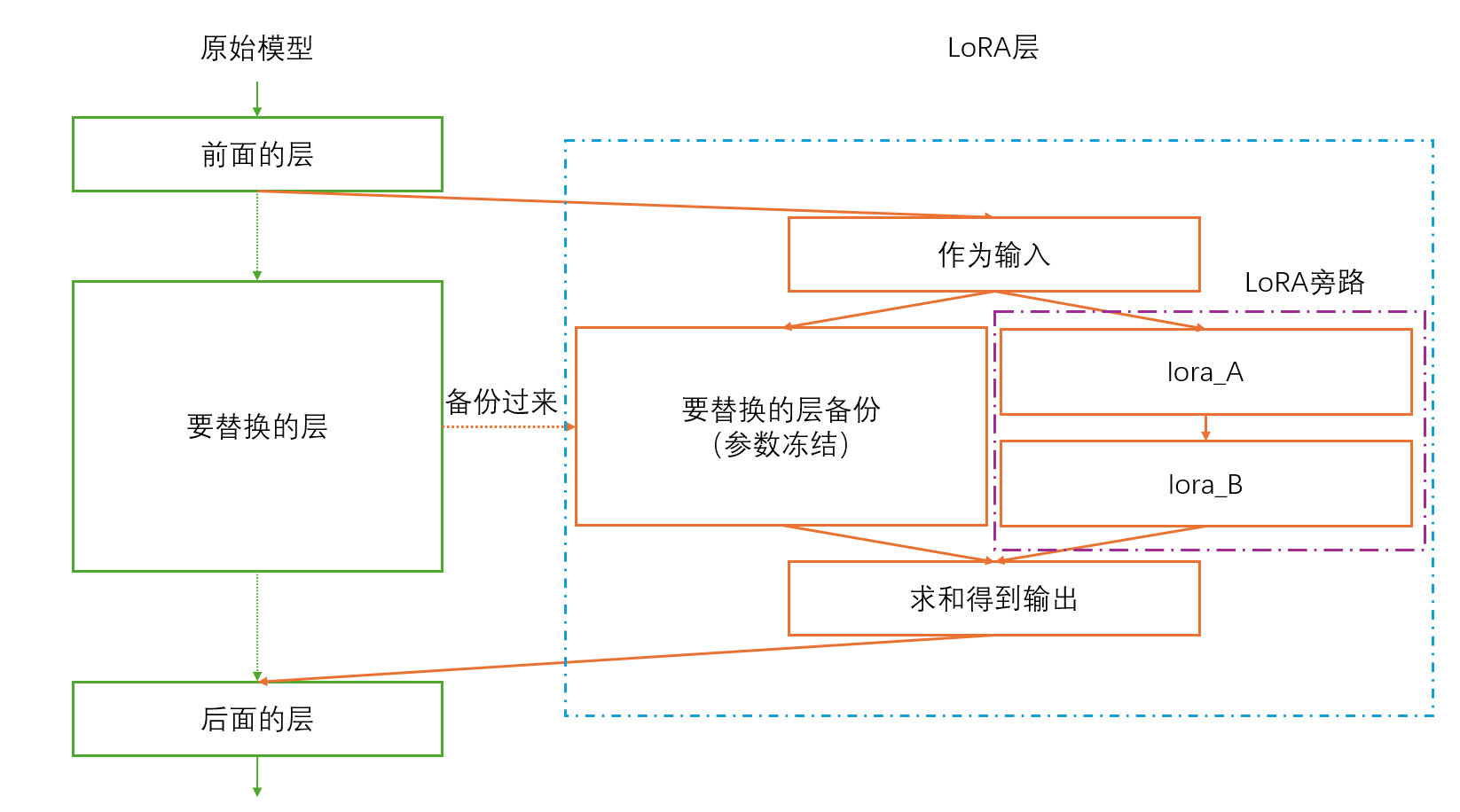
首先,LoRA层具有两个并列的模块,其输入会分别进入这两个模块,其输出是这两个模块输出的和。
第一个模块,是需要替换的模块的备份,在LoRA层中,这个备份的模块的参数不会被更新,仅用来得到需要替换的模块对输入处理后的输出。
第二个模块(也被称为LoRA旁路),就是前文提到的AB两个矩阵(代码里就是前后两个Linear层),A的初始化选择高斯初始化(也可以用其他初始化,但是不能为0),B初始化为0。其原因也很简单,因为LoRA层输出是两个模块输出的和,B初始化为0可以让训练开始时,LoRA层的输出和被替换模块的输出相同(因为第二个模块的输出被经过B后变成0了),而在B初始化为0这个条件下,A再初始化为0,那么第二个模块就一定会出现梯度消失,使LoRA层丧失作用,所以A绝对不能初始化为0。
然后再在原模型中,代替需要替换的模块,插入准备好的LoRA层即可。
大概图像如下图所示:
然后代码部分就很好理解了:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass LoRALayer(nn.Module):def __init__(self, original_layer, rank=8, alpha=16, dropout=0.0):"""Args:original_layer: 要被适配的原始层 (如:nn.Linear)rank: LoRA的秩alpha: 缩放参数,通常与rank相关。在最终输出前会乘以 (alpha / rank)dropout: LoRA路径上的Dropout率"""super().__init__()self.rank = rankself.alpha = alphaself.original_layer = original_layer # 原始层的备份# 冻结原始层的参数for param in self.original_layer.parameters():param.requires_grad = False# 获取原始层的维度(用于创建AB矩阵)in_features = original_layer.in_featuresout_features = original_layer.out_features# 初始化LoRA矩阵 A 和 B# 矩阵A (降维): 从 in_features 降到 rankself.lora_A = nn.Linear(in_features, rank, bias=False)# 矩阵B (升维): 从 rank 升到 out_featuresself.lora_B = nn.Linear(rank, out_features, bias=False)# 初始化LoRA权重# 通常A用随机高斯初始化,B初始化为0,这样训练开始时LoRA旁路输出为0。nn.init.normal_(self.lora_A.weight, std=0.02)nn.init.zeros_(self.lora_B.weight)# LoRA路径上的Dropoutself.dropout = nn.Dropout(dropout)# 缩放因子self.scaling = alpha / rankdef forward(self, x):# 原始层的输出 (冻结)original_output = self.original_layer(x)# LoRA旁路的输出lora_output = self.lora_B(self.lora_A(self.dropout(x)))# 合并输出: 原始输出 + 缩放后的LoRA旁路输出return original_output + lora_output * self.scalingDropout层的作用是通过随机屏蔽部分输入特征,LoRA适配器在微调过程中过拟合训练数据。dropout参数是丢弃率,代表的是一个输入特征被屏蔽的概率,而屏蔽的方法就是将该输入特征的值重置为0。
rank参数是前文提到的LoRA的秩,但是缩放因子alpha却在前文中并没有提到,那它为什么会被添加到这里呢?
事实上,在LoRA的实际运用中,LoRA旁路的输出往往不是直接与原始输出相加,而是在相加前乘以一个缩放因子(其值为alpha / rank),以控制LoRA输出对原始输出的影响程度,目的是防止rank过高时,LoRA旁路的输出主导训练,从而破坏预训练知识。毕竟目的是微调参数,要是LoRA旁路主导了训练,那可就不算“微调”了。
所以,对于rank和alpha,我们可以如下理解:
rank控制LoRA的表达能力(能学习多复杂的变化)
alpha控制LoRA的更新强度(学习到的变化有多大影响)
②查找并替换模型中的原始层
创建好LoRA层后,我们就需要遍历模型,找到目标层并用我们自定义的LoRA层替换它们,代码如下所示:
def inject_lora(model, target_layers, rank=8, alpha=16, dropout=0.0):"""将模型中的指定层替换为LoRALayer。Args:model: 要注入LoRA的模型target_layers: 一个列表,指定要替换的层类型,如 [nn.Linear]rank: LoRA秩alpha: 缩放因子dropout: Dropout率"""for name, module in model.named_children():# 如果当前模块是我们要替换的目标类型if isinstance(module, tuple(target_layers)):# 创建一个LoRALayer来包装它lora_layer = LoRALayer(module, rank, alpha, dropout)# 用LoRALayer替换原来的模块setattr(model, name, lora_layer)else:# 递归地遍历子模块inject_lora(module, target_layers, rank, alpha, dropout)代码逻辑上就是遍历一遍模型的子模块,如果当前模块是需要替换的类型,那么就新建LoRA层并替换原来的层,如果不是,那么就便利这个子模块的子模块,执行相同操作,直到将模型内所有需要替换的类型成功替换为LoRA层。
PS:配置优化器
实际上按照以上方式,就可以创建一个包含预训练模型参数并且已经注入了LoRA的模型,但是一般的优化器代码如下定义:
optimizer = optim.Adam(model.parameters(), lr=0.001)这样优化器会为冻结参数分配不必要的状态,不仅浪费内存,还会导致效率降低,实际应用时可以修改为:
trainable_params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.Adam(trainable_params, lr=1e-3)#也可以用filter
optimizer2 = torch.optim.Adam(filter(lambda p: p.requires_grad, large_model.parameters())
)这样就只会为没有冻结的参数分配状态。
3.总结
核心思想:LoRA通过只训练少量新增参数(低秩矩阵),避免更新原始大模型权重,实现高效微调。
实现方式:在原始层旁添加可训练的A、B小矩阵,前向传播时输出为“原始输出 + 缩放后的BA输出”。
关键优势:极大减少训练参数量(通常1-5%),保持预训练知识,支持多任务快速切换。
训练策略:冻结原始模型参数,优化器只更新LoRA参数,常配合早停防止过度训练。
应用价值:让大模型能够快速适应新任务,同时保持轻量化和通用性,是参数高效微调的代表方法。