Stable Mean Teacher ---2025 IEEE
论文名称:Stable Mean Teacher for Semi-supervised Video Action Detection
期刊年份:2025 IEEE
文章链接:https://akash2907.github.io/smt webpage
代码链接:https://github.com/AKASH2907/stable-mean-teacher
视频动作检测任务具有挑战性的是,除了视频级活动分类之外,还需要时空定位
创新点
1.我们提出了稳定均值教师(Stable Mean Teacher)方法,这是一种用于半监督视频动作检测的简单端到端方法。
2.我们提出了一种新的 ErrOr Recovery (EoR) 模块,它可以从学生的错误中学习,并帮助教师在有限的标记样本下提供更好的监督信号。
3.我们提出了像素差 (DoP),这是一种简单而新颖的约束,专注于时间一致性并导致连贯的时空预测
问题
与分类和对象检测相比,视频动作检测给半监督学习带来了额外的挑战。这是一项结合了分类和时空定位的复杂任务,在标签可用性有限的情况下性能会下降。此外,除了空间正确性之外,检测还必须在时间上保持一致。因此,为视频生成高质量的时空伪标签具有挑战性。为了克服这些挑战,我们提出了 Stable Mean Teacher,一个简单的端到端框架。它是 Mean Teacher 的改编版,我们研究分类和时空一致性,以有效地利用为未标记视频生成的伪标签。
解决方法
稳定均值教师模型包含一个新颖的错误恢复(EoR)模块,该模块从学生在有标记样本上的错误中学习,并将这种学习成果传递给教师,以改进在无标记数据集上生成的时空伪标签。EoR 改善了伪标签,但忽略了时间一致性,而这对于动作检测很重要。为克服这一问题,我们引入像素差异(DoP),这是一种简单且新颖的约束条件,专注于时间连贯性,有助于从无标记样本中生成一致的时空伪标签。
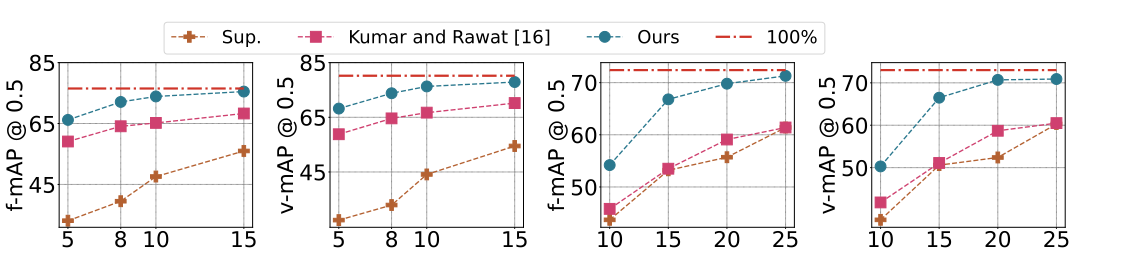
图1:性能概述:与在100%注释上训练的完全监督方法相比,稳定平均教师(Stable Mean Teacher)在使用10%标签(UCF101 - 24;左两个图)和20%标签(JHMDB - 21;右两个图)时,能提供相当的性能。在UCF101 - 24和JHMDB - 21数据集上,在所有不同比例的标记集下,它在f - mAP和v - mAP上始终以较大优势超过现有的最先进方法和监督基线。每个图中的x轴表示注释百分比。
f - mAP:帧平均精度 ,是评估视频目标检测等任务性能的指标。反映模型在各帧上检测目标的准确程度,值越高说明模型在帧级别检测性能越好。
v - mAP :视频平均精度 ,从整个视频层面评估模型性能。衡量模型对完整视频中目标检测的能力,能体现模型在处理视频时对目标在时序变化上的检测准确性 。
框架——Stable Mean Teacher
稳定平均教师(Stable Mean Teacher)采用了一种适用于视频动作检测任务的 学生 - 教师方法,其中教师模型使用弱增强为学生生成伪标签,学生则从这些强增强样本上的伪标签中学习。每个视频样本(xi)被增强以生成两个视图:强视图(xs)和弱视图(xw)。我们使用相同的动作检测模型 M 作为教师模型(Mt)和学生模型(Ms)
为了生成更好且更可靠的时空伪标签,借助联合训练的错误恢复(EoR)模块来改进其伪标签。我们将tloc和sloc传递给错误恢复模块(MtEoR)和(MsEoR),该模块生成精炼的定位。
基础模型的性能依赖于由(Mt)生成的伪标签的质量。然而,由于标签有限,且模型同时专注于分类和定位这两项任务,因此它依赖于每个类别可用的样本。这限制了模型(Mt)生成高质量伪标签的泛化能力。为了解决这个问题,我们提出了一个错误恢复模块,以在类别无关学习中改进定位。
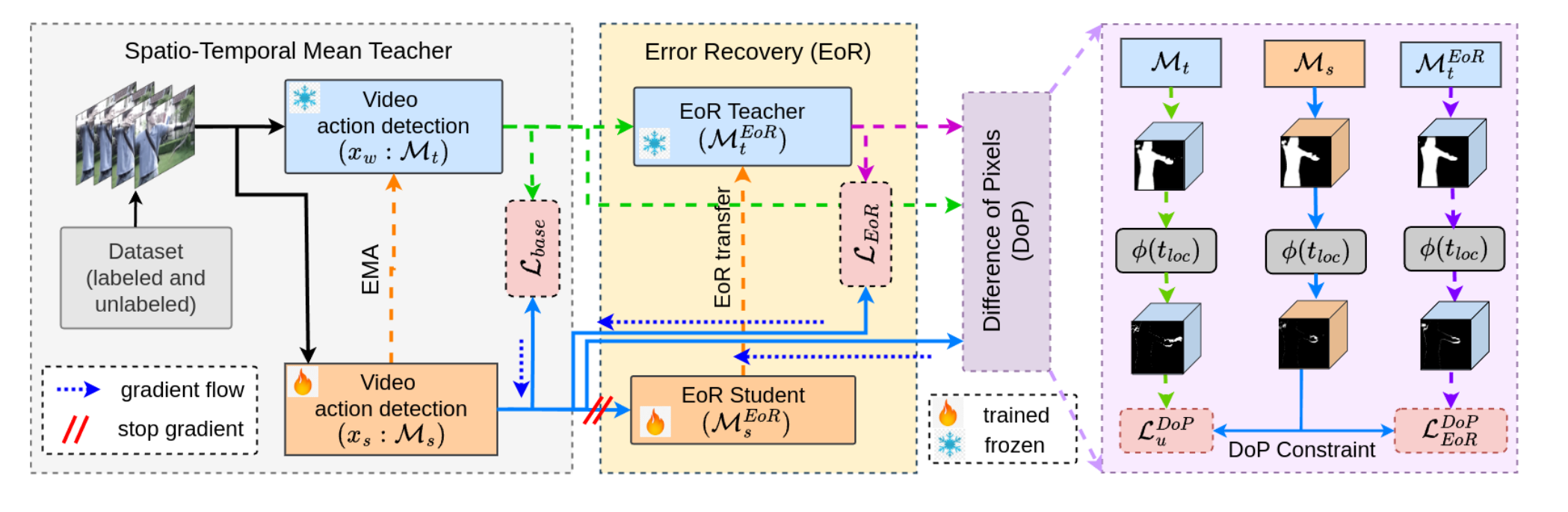
图2:稳定均值教师(Stable Mean Teacher)概述。提升时空伪标签质量的两个关键组成部分:1)错误恢复:优化空间动作边界;2)概率分布约束(DoP constraint):在预测的时空伪标签上引入时间一致性。
基础模型和错误恢复模块是联合训练的,但错误恢复模块的梯度不用于更新基础模型。如果允许这些梯度更新基础模型,那么它也会影响基础模型的预测(在消融研究中讨论过)。这等同于给模型添加更多参数,而这并非我们的目标。另一方面,我们的目的是从基础模型的错误中学习,而非改进基础模型。这也确保了伪标签的改进不依赖于输入视频,并且与类别无关。错误恢复模块将仅能访问基础模型的预测结果,而对输入视频一无所知。这有助于学习一种对未标记样本具有良好泛化能力的变换。
EoR,主要功能是细化空间动作边界,提高动作检测在空间维度上的准确性。
在预测的时空伪标签上引入时间连贯性 。确保在视频序列中,相邻帧之间的动作预测具有时间上的一致性,避免出现不合理的动作跳跃 。 基于DoP约束,通过DoP损失函数对预测结果施加时间一致性(temporal coherency)约束 ,确保在时间维度上动作检测结果的连贯性。
我们有两个无监督损失: 分类一致性:它使用 Jenson-Shennon 散度 (JSD) 最大限度地减少教师预测 tcls 和学生预测 scls 之间的差异,以及 定位一致性:使用 MSE 计算教师 (tloc,tlocEoR) 和学生 sloc 定位地图之间每一帧的像素级差异。最后,稳定平均教师的总体损失定义为
![]()
Error Recovery (EoR)
错误恢复(EoR) 错误恢复模块EoR专注于纠正学生模型在时空定位中的错误。这些错误是由一个错误恢复(EoR)模块进行近似,该模块试图在类别无关学习中恢复这些信息。这是有利的,因为模型只专注于定位任务,而不考虑特定的动作类别。这反过来又增强了模型准确地对行为主体进行定位的能力,这有可能为学生模型(Ms)生成更好的伪标签。基础学生模型首先尝试对行为主体进行定位,并将其作为输入传递给 EoR 模块。EoR 模块只专注于优化定位,而无需担心活动的类型。因此,它可以以类别无关的方式进行训练。EoR 模块首先在经过强增强的有标签样本上进行训练,以纠正学生模型在时空上的错误。一旦训练完成,它就用于纠正经过弱增强的无标签样本上的错误,以改进教师模型生成的伪标签。这反过来又改进了学生模型从无标签样本中学习的伪标签。在学生基础模型(Ms)的输出与由MtEOR生成的优化后伪标签之间计算损失(LEoR),![]() ,其中MSE表示均方误差。(用于衡量模型预测结果与真实结果之间的差异程度。MSE的值越小,说明模型的预测效果越好,即预测值与真实值越接近)
,其中MSE表示均方误差。(用于衡量模型预测结果与真实结果之间的差异程度。MSE的值越小,说明模型的预测效果越好,即预测值与真实值越接近)
Difference of Pixels (DoP)
EOR模块增强了伪标签的空间定位。然而,在视频场景中,预测需要随时间保持一致性。为确保各帧之间的这种时间连贯性,我们引入了一种名为像素差异(DoP)的新型训练约束。这种方法的提出是由于传统损失函数存在局限性,它们主要强调帧或像素的准确性,常常忽略了时间连贯性。DoP 通过关注视频内的像素移动来弥补这一差距(图 3),并利用(LDoP)优化跨帧像素差异的准确性,ϕ表示时间差
并且,xlocf表示第f帧的定位图。这种策略在时空预测中增强了时间一致性,并提高了网络生成的伪标签质量。

图3:像素差异(DoP)可视化。第一行展示RGB帧,第二行展示沿时间维度的地面真值像素差异图。我们展示两种场景:左侧:静态:背景恒定;主体运动;右侧:动态:背景变化;主体运动。时间差异突出了连续帧之间边界像素的变化。
EoR 和 DoP 的作用
基础模型提供活动区域的粗略估计。(EoR)能够识别空间边界中的细粒度错误,并作为增强的类别无关监督,帮助提升学生模型((Ms) )的时空定位能力(图 4 左)。然而,(EoR)损失函数专注于时空定位,却没有考虑对动作检测至关重要的时间连贯性。这正是位置差异(DoP)发挥作用之处,它有助于实现跨帧定位的时间连贯性。位置差异(DoP)约束通过强制像素位移的一致性,有助于在时间维度上生成平滑的定位流。
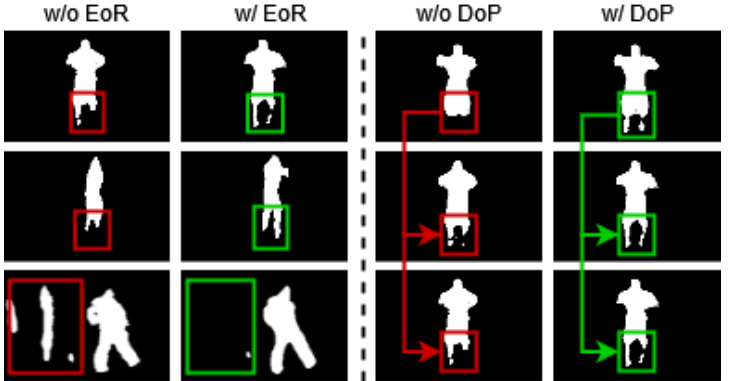
图4:错误恢复(EoR)和预测持续时间(DoP)的定性分析:左侧展示了错误恢复模块在多个样本上的有效性,提高了动作边界精度,还有助于抑制背景噪声。右侧展示了预测持续时间约束如何在视频帧序列预测中诱导时间一致性。
实验
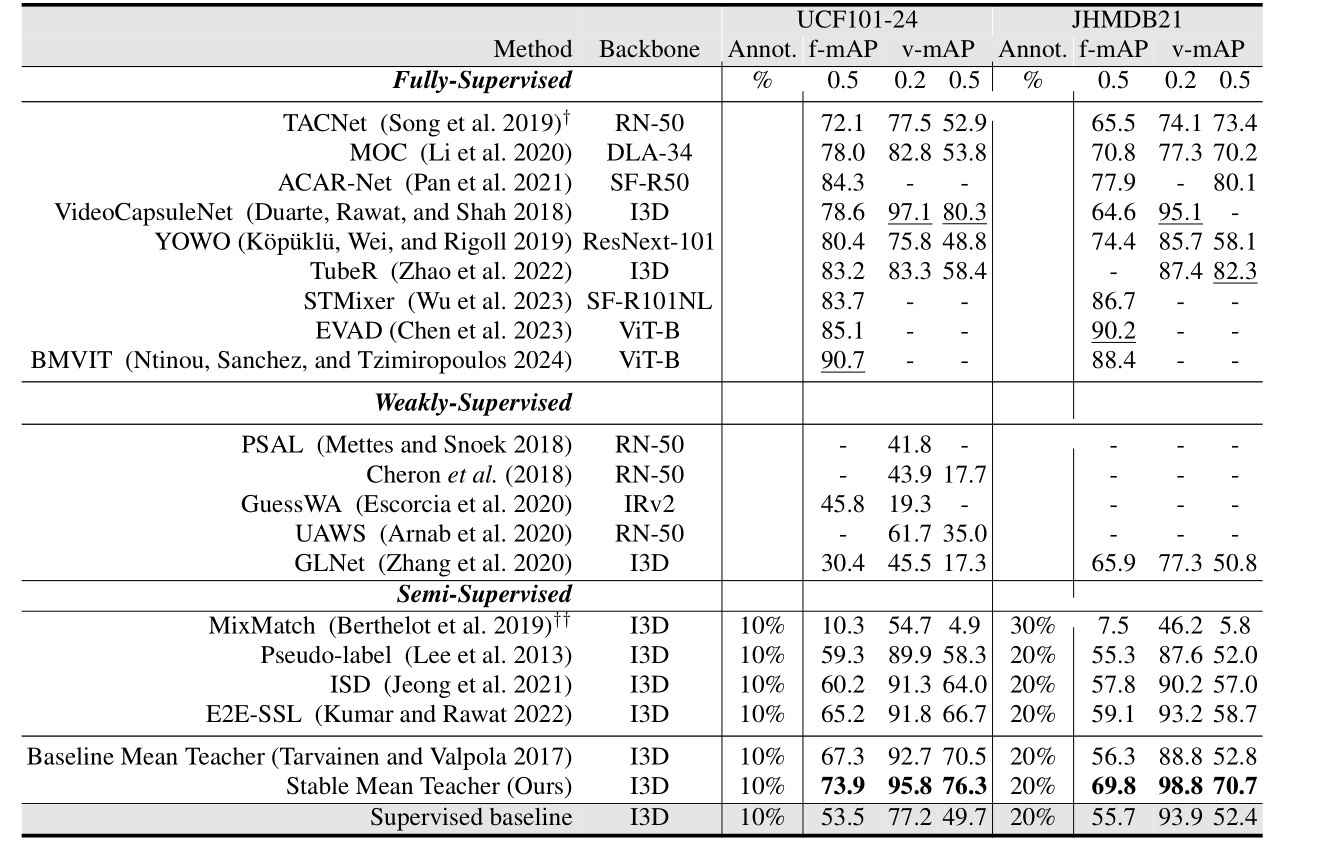
表1:在UCF101 - 24和JHMDB21数据集上,与以往最先进的全监督、弱监督和半监督学习方法的比较。†表示该方法使用光流作为第二种模态。最后一行显示有监督标记子集的分数,UCF101 - 24为10%,JHMDB21为20%。每个指标的最佳分数加下划线。RN - 50、SF - R50/101和IRv2分别是ResNet - 50、SlowFast - R50/101和InceptionResNetV2。( (2019)在JHMDB21上低于30%时存在冷启动问题。(用于衡量模型预测结果与真实结果之间的差异程度。MSE的值越小,说明模型的预测效果越好,即预测值与真实值越接近。)
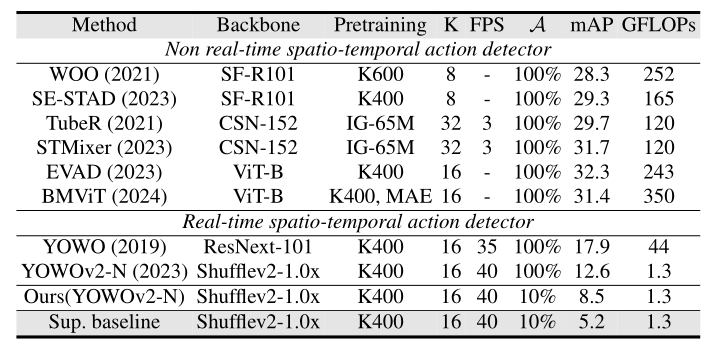 表 2:AVA 数据集的评估。K 是输入视频剪辑的长度。A 表示注释百分比。FPS是每秒传输帧数,FPS数值越高,意味着单位时间内展示的画面越多,动作过渡越自然、流畅 ,能更精准捕捉快速运动细节。mAP 表示 f-mAP@0.5。YOWO2-N 表示纳米版本。
表 2:AVA 数据集的评估。K 是输入视频剪辑的长度。A 表示注释百分比。FPS是每秒传输帧数,FPS数值越高,意味着单位时间内展示的画面越多,动作过渡越自然、流畅 ,能更精准捕捉快速运动细节。mAP 表示 f-mAP@0.5。YOWO2-N 表示纳米版本。
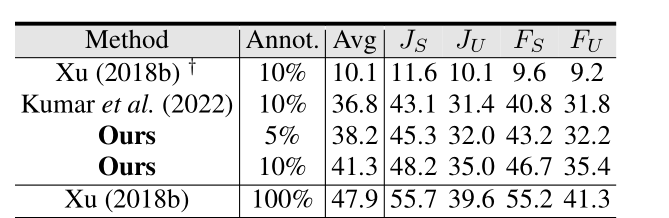
表4:泛化能力:Youtube-VOS上的性能比较。JS和JU分别是已见类别和未见类别的杰卡德系数;FS FU分别是已见类别和未见类别的边界指标。†表示10%监督学习的结果。 JS用来评估模型对已见过类别的预测结果与真实结果的相似程度 ,值越接近1表示相似性越高、模型性能越好.JU反映模型对新类别对象的泛化能力 ,值越大表明模型对新类别识别效果越好。FS用于衡量模型预测的已见类别目标边界与真实边界的契合程度,在涉及目标定位、分割等任务中很关键,数值越高说明模型对已见类别目标边界预测越精准。FU主要评估模型对未见类别目标边界的预测精准度,体现模型对新类别目标在空间位置界定上的能力,分数越高意味着对未见类别目标边界预测越准确。
消融实验
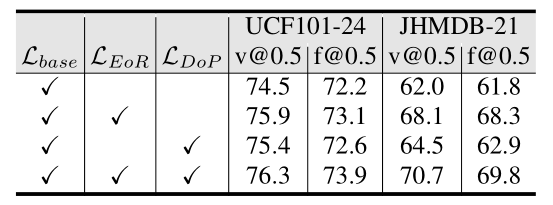
表3:消融实验:错误恢复模块与像素差异的有效性。
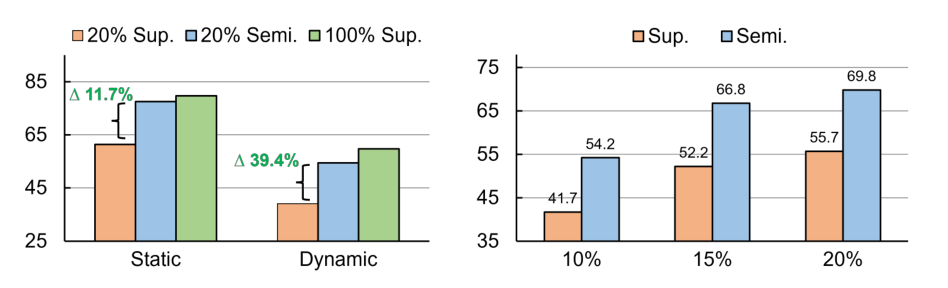
图5:稳定均值教师分析:(左)静态与动态场景:动态场景比静态场景更具挑战性,然而,动态场景下性能的相对提升比静态场景情况高出27.7%。Δ表示v-mAP@0.5的相对变化。(中)标注比例:在x轴上从右向左移动,性能增益(f-mAP@0.5)增加。这表明该方法在低标注数据情况下更有效。