【IEEE 2025】即插即用 SRMF 突破长尾困境!实现超高分辨率遥感图像的精准分割
01 论文介绍
超高分辨率(UHR)卫星图像的语义分割技术在灾害管理、城市规划和环境监测等领域至关重要。然而,UHR图像普遍存在严重的类别不平衡,即“长尾分布”现象:少数类别(如建筑、农田)占据绝大多数像素,而大部分类别(如池塘、车站)样本稀少。这种分布导致模型训练时梯度更新被头类主导,对尾类特征学习不足,严重影响分割精度。
现有UHR分割方法多聚焦于设计多分支网络以提取和融合多尺度特征,但普遍忽略了从数据层面解决长尾问题。针对这一挑战,SRMF (Semantic Reranking & Resampling with Multimodal Fusion) 框架被提出。该方法创新性地从“数据增强”和“多模态融合”两个维度入手,旨在缓解长尾分布带来的训练偏差,提升模型对稀有类别的识别能力。

论文地址: https://arxiv.org/pdf/2504.19839
代码地址: https://github.com/BinSpa/SRMF.git
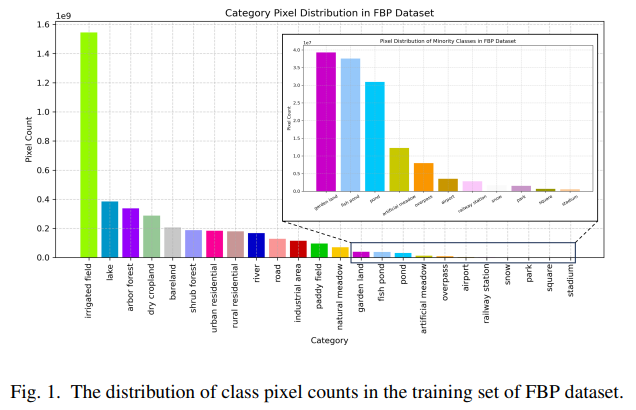
论文首先通过对FBP、URUR等多个数据集的类别像素分布进行可视化,直观地揭示了UHR遥感数据中普遍存在的长尾现象,明确了本研究的核心动机。
点击阅读原文,获取更多论文相关信息
02 SRMF 方法详解
SRMF的整体架构如下图所示,其核心在于一个双路径设计:上游通过精巧的数据采样策略优化训练数据分布,下游则通过注入外部知识增强模型的特征表示。
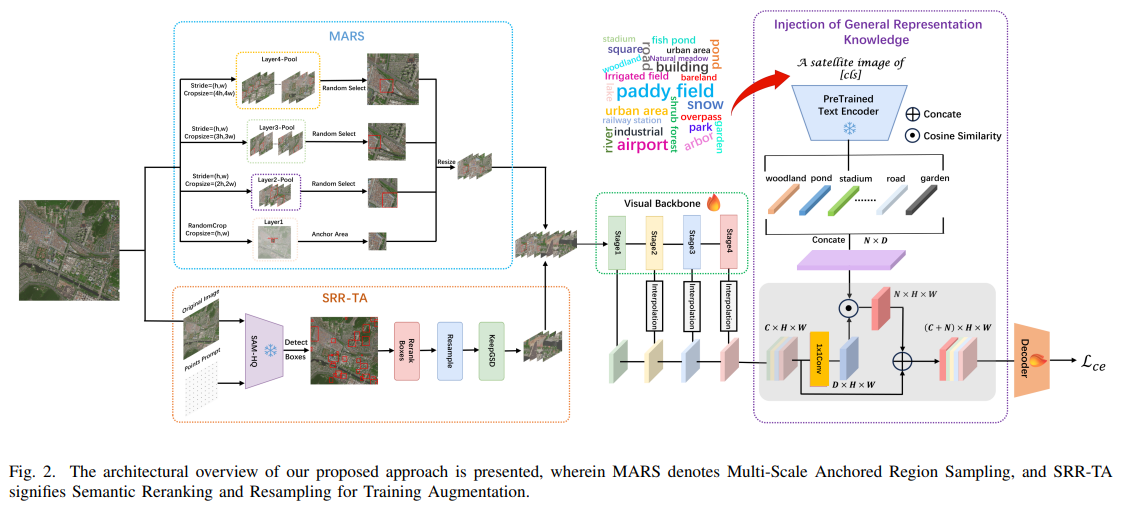
1. 多尺度锚点区域采样
为解决传统随机裁剪可能带来的上下文信息不足和局部特征偏差问题,SRMF设计了MSAR方法。该方法不同于以图像块中心进行多尺度扩展的策略,其具体流程如 Algorithm 1 所述:
- 在原始UHR图像中随机裁剪一个区域作为“锚点区域 (anchor area)”。
- 围绕该锚点区域,在多个更大的尺度(如2x, 3x, 4x)上生成包含锚点的候选裁剪池。
- 从每个尺度的候选池中随机抽取一个图像块,并将其缩放至与锚点区域相同的大小。
- 最终,将锚点区域与从不同尺度采样和缩放后的图像块拼接起来,构成一个包含丰富上下文信息的训练样本。
这种非中心的锚点采样策略,使得模型在训练时能观察到同一目标在不同背景和位置下的多样化表现,增强了模型的空间感知能力。
2. 语义重排与重采样训练增强
为从根本上缓解数据长尾问题,SRR-TA策略首次将类别重采样机制引入UHR图像分割领域。
理论基础:
论文首先从理论上分析了长尾分布对模型梯度更新的影响。对于交叉熵损失函数,其对 logits (z) 的梯度可表示为:
∂L∂zn,i=1B(∑n∈Xi(pn,i−1)+∑n∉Xipn,i)⋯(Eq.2)\frac{\partial L}{\partial z_{n,i}} = \frac{1}{B} \left( \sum_{n \in X_i} (p_{n,i} - 1) + \sum_{n \notin X_i} p_{n,i} \right) \quad \cdots \quad (Eq. 2) ∂zn,i∂L=B1n∈Xi∑(pn,i−1)+n∈/Xi∑pn,i⋯(Eq.2)
其中,XiX_iXi 是属于类别 iii 的像素集,pn,ip_{n,i}pn,i 是模型预测第 nnn 个像素属于类别 iii 的概率。此公式表明,所有不属于类别 iii 的像素(尤其是头类的大量像素)都会对类别 iii 的梯度更新产生负向影响。若批次内类别分布均衡,则梯度更新更为稳定。
实现流程:
- 区域预分割: 利用高性能的实例分割模型 SAM-HQ 对UHR图像进行预处理,自动分割出图像中不同尺度的地物掩码(Masks)。

- 区域采样与优先级分配:
- 为每个分割出的地物区域(以边界框形式存在)赋予类别标签。
- 根据全局类别分布频率,为每个区域分配采样优先级。尾类(少数类)区域获得更高的采样权重。
- 生成均衡批次: 在构建每个训练批次(Batch)时,一部分数据来自MSAR以保留原始分布,另一部分则根据上述优先级从地物区域池中进行重采样,确保尾类区域被更频繁地选中,从而在数据层面直接提升了尾类样本的比例。
3. 通用表征知识注入
为了解决由样本稀少引起的类内方差大(如不同风格的建筑)和类间方差小(如河流与池塘)的问题,SRMF首次引入遥感领域的视觉-语言模型(GeoRSCLIP)进行跨模态知识增强。
实现流程:
- 文本特征提取:
- 构建一个包含54个常见遥感地物类别的词汇表(如 “A satellite image of a river”)。
- 利用预训练好的 GeoRSCLIP 的文本编码器,将这些类别描述转化为具有丰富语义信息的文本特征向量 RtR_tRt。此过程无需任何人工的逐区域文本标注。
- 视觉与文本特征融合:
- 语义分割主干网络(如 SegFormer-MiT-B5)提取输入图像的像素级视觉特征 RiR_iRi。
- 将视觉特征 RiR_iRi 通过一个线性层映射到与文本特征 RtR_tRt 相同的维度,得到 R^i\hat{R}_iR^i。
R^h×w×di=Rh×w×ci⋅Wc×d⋯(Eq.4)\hat{R}_{h \times w \times d}^{i} = R_{h \times w \times c}^{i} \cdot W_{c \times d} \quad \cdots \quad (Eq. 4) R^h×w×di=Rh×w×ci⋅Wc×d⋯(Eq.4) - 计算每个像素的视觉特征与所有类别文本特征之间的余弦相似度,得到一个相似度图 FFF。
Fi,j,k=R^i(i,j,:)⋅Rt(k,:)∥R^i(i,j,:)∥⋅∥Rt(k,:)∥⋯(Eq.5)F_{i,j,k} = \frac{\hat{R}_i(i, j, :) \cdot R_t(k, :)}{\|\hat{R}_i(i, j, :)\| \cdot \|R_t(k, :)\|} \quad \cdots \quad (Eq. 5) Fi,j,k=∥R^i(i,j,:)∥⋅∥Rt(k,:)∥R^i(i,j,:)⋅Rt(k,:)⋯(Eq.5) - 将此相似度图 FFF 与原视觉特征 RiR_iRi 拼接 (concatenate) 起来,形成融合后的特征图 FfF_fFf。
Ff=concat(F,Ri)⋯(Eq.6)F_f = \text{concat}(F, R_i) \quad \cdots \quad (Eq. 6) Ff=concat(F,Ri)⋯(Eq.6)
- 最终分类: 融合特征 FfF_fFf 经过一个1x1卷积层和Softmax函数,得到最终的像素级分类结果。整个网络通过标准的交叉熵损失进行端到端优化。
点击阅读原文,获取更多论文相关信息
03 实验结果与分析
核心消融实验
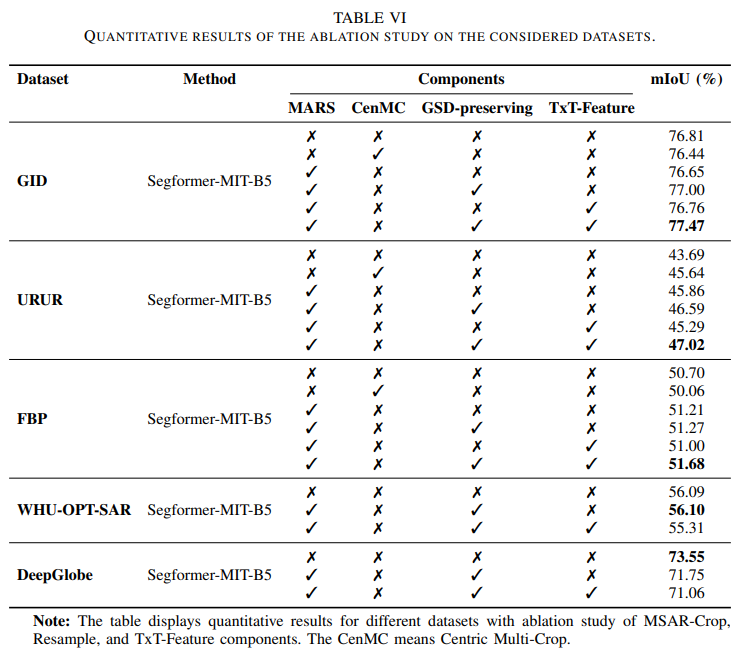
- 结论1: 在 GID、URUR 和 FBP 数据集上,同时启用 MSAR、GSD-preserving (SRR-TA中的一种采样策略) 和 TxT-Feature (文本特征注入) 的组合取得了最佳性能,证明了这三个核心模块之间存在相互增益的协同效应。
- 结论2: 对比 MSAR 和 CenMC (中心多尺度裁剪),MSAR 效果更优,验证了其非中心化锚点策略的优越性。
- 结论3: 在 WHU-OPT-SAR 和 DeepGlobe 数据集上,注入文本特征导致性能下降。原因是这些数据集的类别与 GeoRSCLIP 的预训练词汇表不完全匹配。这表明文本先验知识的有效性依赖于其与目标数据集类别的对齐。
与SOTA方法的可视化对比
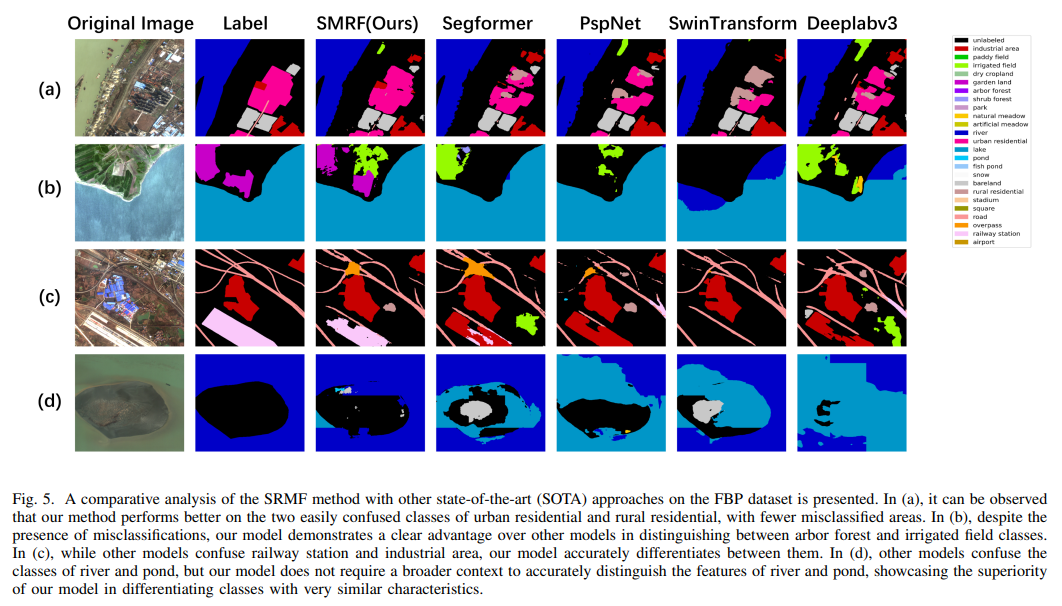
在FBP数据集上的可视化结果表明,SRMF在处理易混淆的尾类时表现出色。
- (a) 城乡住宅区: SRMF 能更好地区分城乡住宅,误分割区域更少。
- (b) 森林与灌溉地: SRMF 能有效区分纹理相似的林地和灌溉田。
- © 工业区与车站: 其它方法易将二者混淆,SRMF 区分准确。
- (d) 河流与池塘: 即便在缺乏广阔上下文的情况下,SRMF 也能准确识别池塘等小型水体,而不会将其误判为河流。
这些结果直观地证明了 SRMF 在提升尾类和易混淆类别分割精度、改善小目标和边界细节方面的显著优势。
04 即插即用模块
# Copyright (c) OpenMMLab. All rights reserved.
import os
import os.path as osp
import platform
import shutil
import sys
import warnings
from setuptools import find_packages, setupdef readme():with open('README.md', encoding='utf-8') as f:content = f.read()return contentversion_file = 'mmseg/version.py'def get_version():with open(version_file) as f:exec(compile(f.read(), version_file, 'exec'))return locals()['__version__']def parse_requirements(fname='requirements.txt', with_version=True):"""Parse the package dependencies listed in a requirements file but stripsspecific versioning information.Args:fname (str): path to requirements filewith_version (bool, default=False): if True include version specsReturns:List[str]: list of requirements itemsCommandLine:python -c "import setup; print(setup.parse_requirements())""""import reimport sysfrom os.path import existsrequire_fpath = fnamedef parse_line(line):"""Parse information from a line in a requirements text file."""if line.startswith('-r '):# Allow specifying requirements in other filestarget = line.split(' ')[1]for info in parse_require_file(target):yield infoelse:info = {'line': line}if line.startswith('-e '):info['package'] = line.split('#egg=')[1]else:# Remove versioning from the packagepat = '(' + '|'.join(['>=', '==', '>']) + ')'parts = re.split(pat, line, maxsplit=1)parts = [p.strip() for p in parts]info['package'] = parts[0]if len(parts) > 1:op, rest = parts[1:]if ';' in rest:# Handle platform specific dependencies# http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependenciesversion, platform_deps = map(str.strip,rest.split(';'))info['platform_deps'] = platform_depselse:version = rest # NOQAinfo['version'] = (op, version)yield infodef parse_require_file(fpath):with open(fpath) as f:for line in f.readlines():line = line.strip()if line and not line.startswith('#'):yield from parse_line(line)def gen_packages_items():if exists(require_fpath):for info in parse_require_file(require_fpath):parts = [info['package']]if with_version and 'version' in info:parts.extend(info['version'])if not sys.version.startswith('3.4'):# apparently package_deps are broken in 3.4platform_deps = info.get('platform_deps')if platform_deps is not None:parts.append(';' + platform_deps)item = ''.join(parts)yield itempackages = list(gen_packages_items())return packages
点击阅读原文,获取更多论文相关信息