电商或游戏平台基于大数据引入AI智能体

为电商或游戏平台引入AI智能体(特别是RAG技术)能显著提升用户体验和运营效率。为了帮助你快速进行技术储备,我为你整合了一套从概念到实战的学习路径和资源。
下面的表格梳理了构建RAG智能体的核心环节及对应的实用工具与平台,你可以根据自身情况灵活选择。
| 核心环节 | 目标 | 推荐工具与平台 |
|---|---|---|
| 💡 快速体验与原型构建 | 零代码或低代码验证想法,快速搭建可演示的雏形 | 阿里云百炼、PAI LangStudio、n8n、京东云言犀 |
| 🛠️ 开发框架与核心组件 | 提供开发骨架,处理知识检索、智能体推理等核心逻辑 | LangChain、MuAgent框架 |
| 📚 向量数据库与检索 | 存储和快速查询处理后的知识数据 | Pinecone、Milvus、FAISS |
| 🧠 大模型服务 | 提供核心的语义理解和内容生成能力 | 通义千问、DeepSeek、OpenAI、言犀大模型 |
从理论到实践:四步构建你的知识体系
拥有工具只是第一步,如何正确使用它们更为关键。你可以遵循以下路径进行学习和实践。
1. 理解核心概念:RAG是什么?
基本原理:RAG的全称是检索增强生成。它的工作流程很像一个专业的顾问:当你提问时,它会先去自己的资料库(知识库)里快速查找相关信息(检索),然后结合找到的资料和自身的学识,组织成一段完整、准确的回答(增强生成)。
解决什么问题:它主要解决大模型在处理专业、实时或私有数据时可能出现的“胡言乱语”或信息滞后问题,让AI的回答更精准、可靠。
2. 参考成功案例:看看别人怎么做?
了解行业内的成熟应用能给你带来直观感受和设计灵感。
电商平台:
用户行为分析:结合AI智能体与大数据技术(如Flink、Spark),可以实现对海量用户行为(浏览、加购等)的实时分析和决策,比如在用户加购未下单时自动触发优惠券发放。
智能购物顾问:像NVIDIA推出的零售购物顾问参考架构,可以让AI助手准确回答关于商品的问题,并提供个性化推荐。
游戏平台:
智能客服与问答:盛趣游戏在《云海之下》中部署的“知链”系统,能在0.3秒内扫描百万级知识库,为玩家解答关卡难题、账号安全等问题。
智能NPC:《传奇世界》中的智能NPC“玄玄老人”可以通过自然语言对话,为玩家提供实时、精准的游戏情报和攻略。
3. 掌握关键技术:如何优化你的智能体?
一个基础的RAG系统搭建起来不难,但要让它表现优异,你需要关注以下优化技术:
高效的检索策略:不要只依赖单一的检索方式。可以尝试混合检索,即结合基于语义的向量检索和基于关键词的检索(如BM25),让检索结果更全面、准确。
检索结果精炼:使用上下文压缩等技术,对检索到的大量文档进行摘要和提炼,只保留最相关的信息,这能显著提升大模型处理效率和质量。
复杂任务处理:对于需要多步骤推理的复杂任务(如分析数据趋势并撰写报告),可以引入智能体(Agent)工作流,让AI具备规划、执行和调试的能力。
4. 动手实践:选择一个路径开始
理论结合实践是学习的最佳方式,你可以根据自身技术背景选择起点。
如果你是零代码爱好者:
使用阿里云百炼,可以在10分钟内通过拖拽和配置,为一个网站添加具备私有知识库的AI助手。
使用n8n这类自动化工具,可以通过可视化的工作流来构建一个简单的RAG智能体,例如用于回答关于特定文档(如游戏规则)的问题。
如果你是开发者或希望深入定制:
从框架入手:学习使用 LangChain 这样的流行框架,它用代码将文档加载、文本分割、向量化存储和检索集成为完整的链条,是构建复杂应用的基础。
研究开源项目:在GitHub等平台上有许多MCP-RAG之类的开源项目,通过阅读和运行别人的代码,你能更深入地理解系统如何运作。
大数据背景如何转AI智能体
大数据背景是构建AI智能体的巨大优势。你们团队的数据处理能力和对游戏用户行为的理解,正是智能体成功的核心基础。
基于你们的情况,我为你设计了一个从数据价值最大化出发的实战路径:
大数据团队的独特优势与目标场景
你的核心资产是数据——用户行为日志、游戏数据、运营数据等。智能体是你的“价值放大器”。
高价值应用场景:
实时个性化推荐智能体:结合实时用户行为(如刚浏览了某类装备),动态调整推荐内容。
玩家流失预警与干预智能体:识别有流失风险的玩家,并自动触发个性化的召回任务(如推送专属福利或他们可能感兴趣的新内容)。
游戏平衡与经济系统分析智能体:让智能体分析道具产出/消耗、玩家战力分布等,为策划提供数据洞察和调整建议。
智能客服与游戏问答助手:基于游戏Wiki、版本更新公告、平衡性调整日志等构建,为玩家提供精准问答。
技术架构与选型建议
对于大数据团队,建议采用更灵活、可控的技术栈,以便与现有数据管道无缝集成。
组件选型建议:
数据预处理与ETL:继续使用你熟悉的Spark。利用
spark-nlp等库进行大规模的文本清洗和预处理。向量数据库:推荐 Milvus 或 Chroma。
Milvus:性能强劲,适合大规模、高并发的生产环境,与大数据生态结合好。
Chroma:轻量、开源,易于上手和调试,适合快速原型验证。
开发框架:
LangChain/LlamaIndex:依然是首选。它们提供了丰富的模块,能快速构建起RAG管道。
MuAgent:一个专门为智能体设计的框架,对行为规划、工具调用支持得很好,如果你要构建能执行复杂任务(如“为A玩家群体生成一个运营活动并评估其风险”)的智能体,值得关注。
大模型:
云端API(快速启动):DeepSeek、通义千问。成本可控,性能强大,适合初期验证。
本地微调(长期发展):如果有敏感数据或需要定制化,可以考虑在后期使用 Qwen、 Baichuan 等开源模型,用你们自己的游戏数据做微调。
四阶段实战路线图
阶段一:快速验证(2-4周)- 构建一个“游戏问答助手”
目标:选择一个具体场景,跑通端到端的流程,获得正反馈。
行动:
数据准备:选取一份结构清晰的游戏知识文档,如“游戏玩法说明”或“客服QA文档”。
构建管道:使用 LangChain + Chroma,写一个Python脚本,将文档切块、向量化后存入Chroma。
搭建服务:创建一个简单的Web界面(如用Gradio),让团队成员可以提问并得到基于文档的准确回答。
成果:一个可演示的智能客服原型。
阶段二:数据驱动(1-2个月)- 开发“玩家流失预警智能体”
目标:将智能体与你们的实时数据流结合,解决业务痛点。
行动:
定义规则:与运营同学合作,明确流失玩家的数据特征(如“连续3天未登录”且“等级>10”)。
构建智能体:
检索:当系统识别出风险玩家时,智能体自动检索该玩家的历史行为(付费记录、常用英雄、最近副本失败次数等)。
分析与决策:让大模型根据检索到的玩家画像,生成个性化的干预建议。例如:“该玩家是付费玩家,主玩‘法师’,最近副本失败5次。建议:推送一条包含‘法师高级符文试用券’的登录激励信息。”
系统集成:将这个智能体作为API服务,集成到你们的用户运营平台或消息推送系统中。
成果:一个能自动识别风险并给出智能干预策略的AI智能体。
阶段三:能力扩展(1-2个月)- 引入复杂任务处理能力
目标:让智能体能够使用工具,执行更复杂的任务。
行动:
为智能体赋予工具调用能力。例如,它可以调用:
内部数据API:查询实时在线人数、某个道具的销售数据。
执行API:发送邮件、创建JIRA工单、触发一个推送任务。
场景:构建一个“运营日报智能体”,它每天自动检索关键数据,调用大模型生成一份包含数据解读和趋势分析的报告,并通过邮件发送给相关负责人。
阶段四:模型优化(长期)- 领域模型微调
目标:让模型更懂你的游戏,回答更专业。
行动:收集智能体运行中的高质量QA对话,以及游戏内的专有名词、技能描述等数据,对开源大模型进行领域适配微调。
给大数据工程师的特别提示
从“批处理”思维转向“实时服务”思维:智能体往往需要低延迟的响应。关注向量检索的性能和服务的稳定性。
数据质量是天花板:你比任何人都清楚“垃圾进,垃圾出”。用于检索的知识库(无论是文档还是用户行为数据)的清洗和结构化质量,直接决定了智能体的上限。
评估体系:建立一套评估指标,如检索准确率、回答满意度、问题解决率等,用数据驱动智能体的迭代优化。
四阶段执行方法
你的技术背景使得你无需从零学习数据处理,可以直接切入最核心的“如何用AI让数据产生智能”这一环节。从一个小而美的场景开始,快速交付价值,然后逐步扩展,这是大数据团队构建AI智能体最顺畅的路径。
如果需要,我可以就第一阶段“游戏问答助手”的具体技术实现,提供更详细的代码示例和步骤。
阶段一:快速验证 - 游戏智能问答助手原型
目标:在2-4周内,利用静态文档数据,构建一个可演示的RAG原型,验证技术可行性。
架构图:
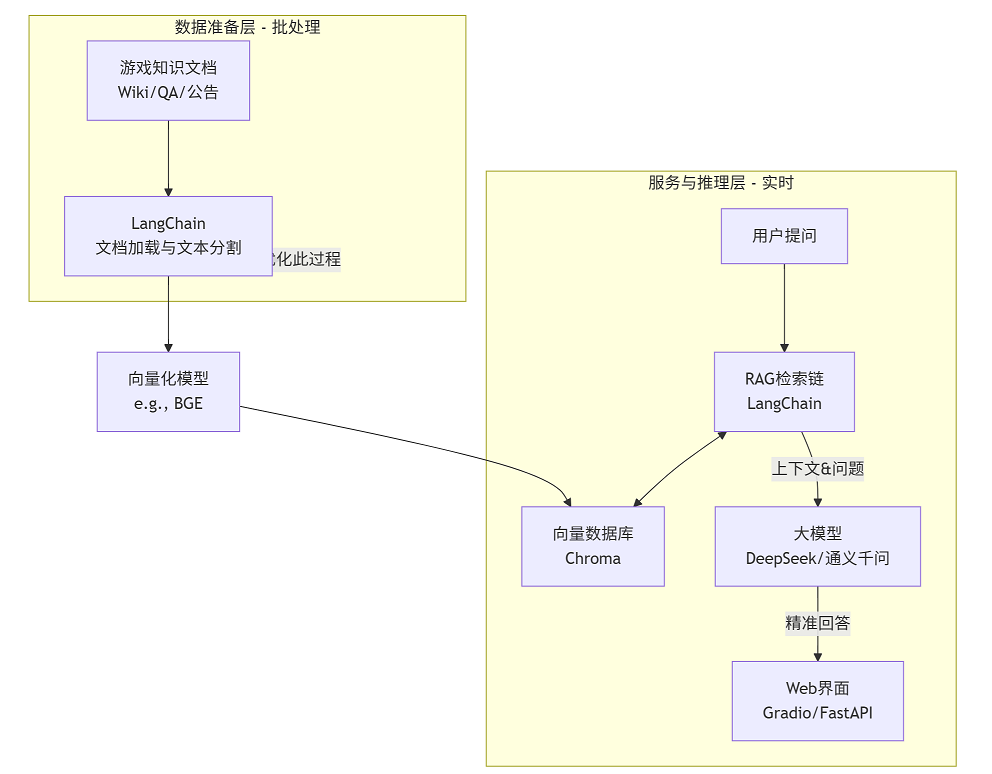
核心数据流与技术栈:
数据加载与分割:使用
LangChain的TextLoader、MarkdownLoader和RecursiveCharacterTextSplitter处理文档。向量化与存储:采用轻量级开源向量模型(如
BGE)和向量数据库(Chroma),便于快速部署。检索与生成:
LangChain组建检索链,从Chroma查询相似片段,连同用户问题发送给大模型生成答案。交付:通过
Gradio快速构建前端界面,或使用FastAPI提供后端接口。
阶段二:数据驱动 - 玩家流失预警与干预智能体
目标:将智能体与实时数据流结合,实现从风险识别到智能干预的闭环。
架构图:
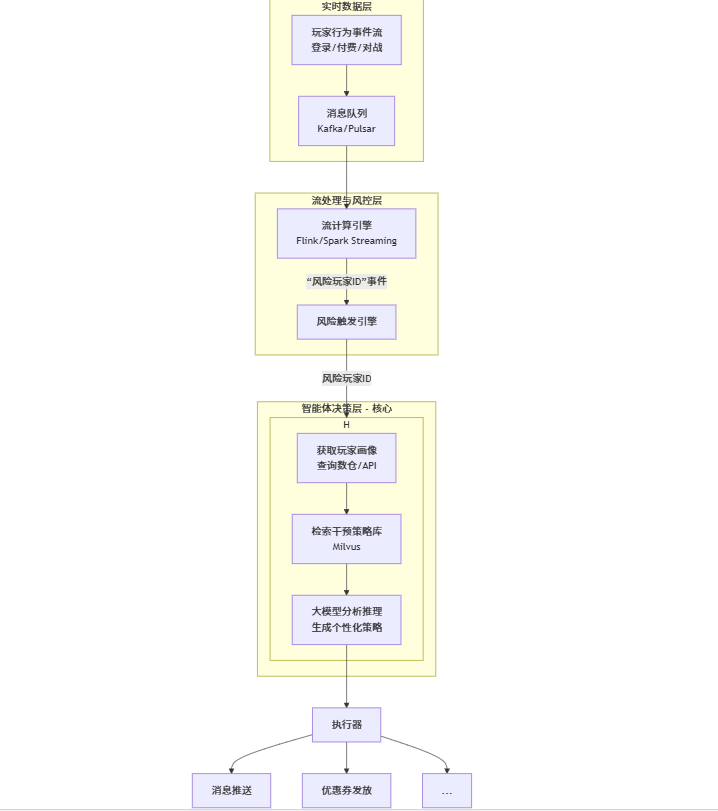
核心数据流与技术栈:
实时风控:
Flink消费Kafka数据,通过预定义的规则(如“连续3天未登录”)实时生成风险事件。智能体决策:
数据检索:智能体接收风险玩家ID后,首先查询 数据仓库(如ClickHouse)或 用户画像系统,获取该玩家的详细画像(付费、装备、活跃度)。
策略检索:同时,从
Milvus中检索已有的“干预策略”案例。推理决策:大模型综合 玩家画像 和 策略库,生成个性化干预命令(如:推送“法师专属符文”)。
动作执行:智能体通过调用内部 API(推送、营销平台)完成动作执行。
阶段三:能力扩展 - 运营日报生成智能体
目标:引入智能体(Agent)和工具调用(Tool Use)能力,让AI自动完成复杂、多步骤的任务。
架构图:
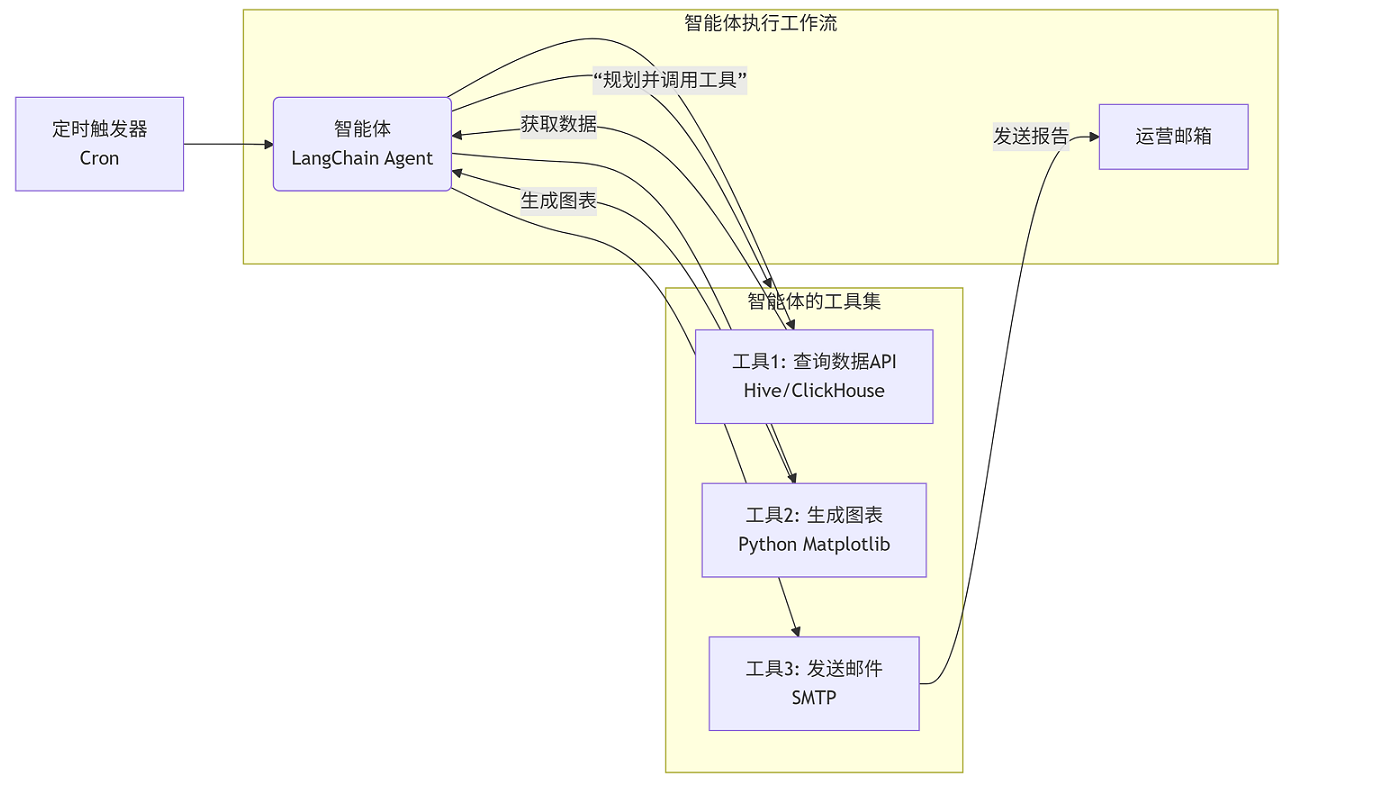
核心数据流与技术栈:
智能体核心:使用
LangChain Agent框架,它具备规划和工具调用能力。工具集:
数据查询工具:封装对数据仓库的查询SQL,返回核心KPI(DAU、收入)。
图表生成工具:调用
Matplotlib或Pyecharts生成趋势图。邮件发送工具:封装
SMTP逻辑。
工作流:智能体接收“生成日报”任务后,会自主规划步骤:调用工具1获取数据 -> 调用工具2生成图表 -> 组织图文报告 -> 调用工具3发送邮件。
阶段四:模型优化 - 领域模型微调
目标:让通用大模型更懂你的游戏,成为领域的“专家”,提升所有上游智能体的表现。
架构图:
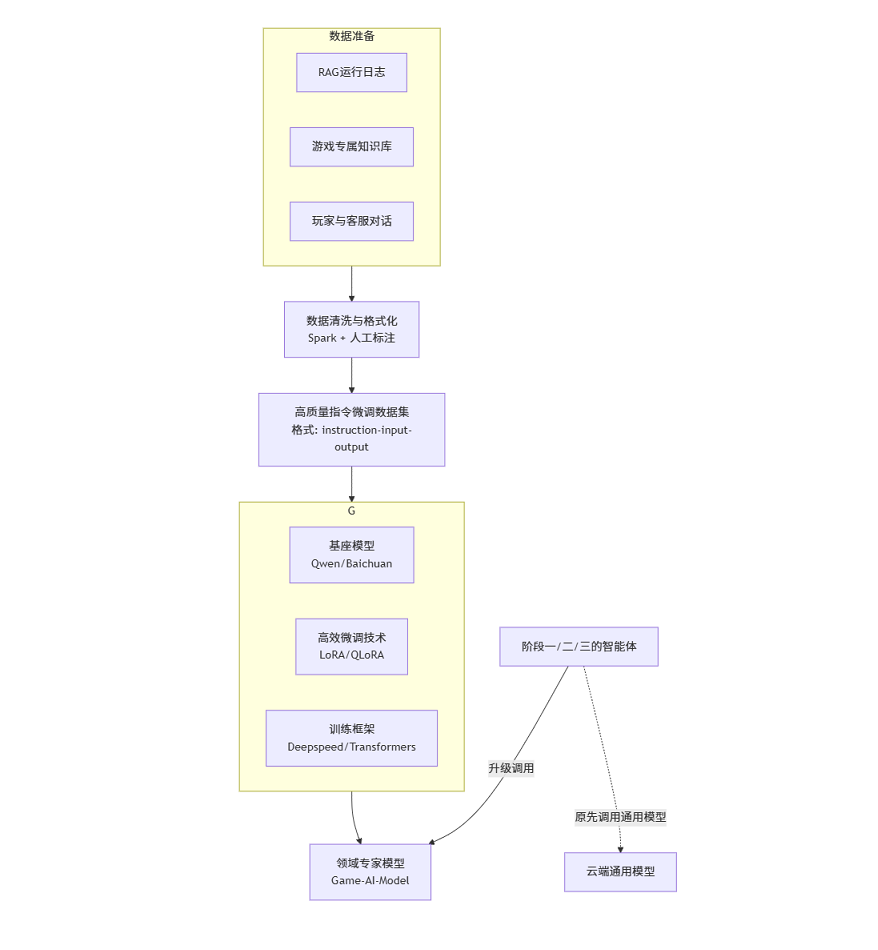
核心数据流与技术栈:
数据构建:从前期智能体的运行日志、游戏Wiki、优质客服对话中提炼高质量的QA对,构建指令微调数据集。
高效微调:
基座模型:选择优秀的开源模型,如
Qwen。微调技术:采用
LoRA/QLoRA等技术,大幅降低计算成本和显存需求,即可在少量A100/A800上完成。
模型部署:将微调后的模型部署为 内部API服务(可使用
vLLM等高性能推理框架)。上游集成:将阶段一、二、三的智能体接入点,从云端通用模型切换至你这个私有的“领域专家模型”,从而获得更精准、更专业的性能提升。
这四张架构图清晰地勾勒出了从技术验证到深度集成的演进路径。建议你从第一阶段开始,快速为团队建立一个直观的认知和信心。