基于昇腾 NPU 的 Gemma 2 推理实测:性能评测、脚本实现与可视化分析
基于昇腾 NPU 的 Gemma 2 推理实测:性能评测、脚本实现与可视化分析
前言
文章基于 Gemma 2 模型,在昇腾 NPU 环境下进行了系统化测试与多维度性能评估,涵盖推理速度、内存占用、语言理解、逻辑推理、代码生成等关键指标,通过自编测试脚本与可视化分析,为模型部署与硬件适配提供工程级的性能参考与实测数据支持。
环境准备与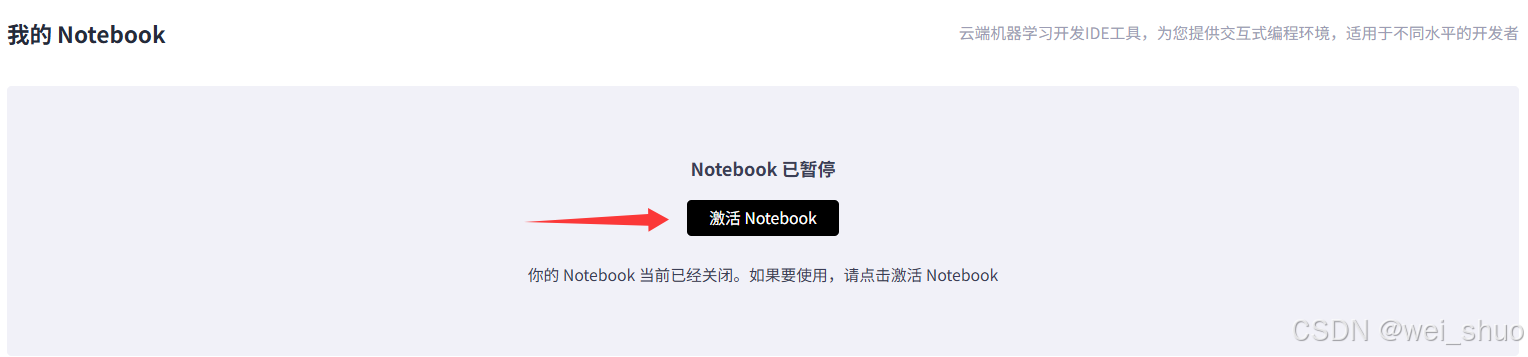
硬件配置检查
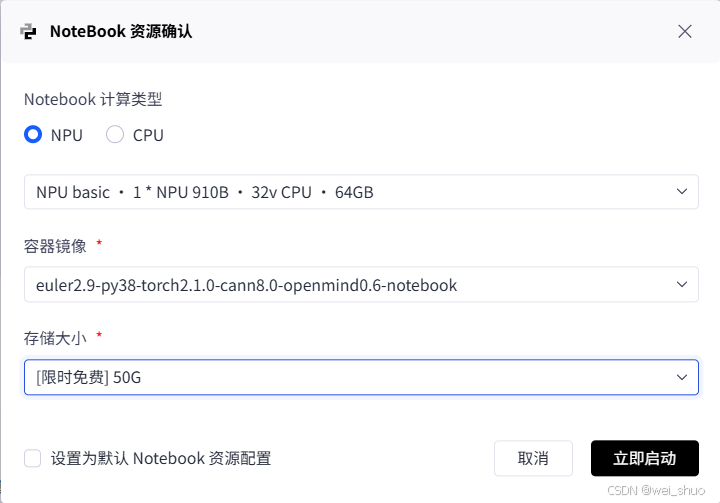
1、GitCode控制台激活NoteBook
2、NoteBook资源确认
- Notebook 计算类型:NPU
- NPU 配置:NPU basic・1 * NPU 910B・32v CPU・64GB
- 容器镜像:euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook
- 存储大小:[限时免费] 50G
3、等待实例启动后,进入终端,使用命令查询 NPU 设备的详细信息
npu-smi info
- npu-smi 工具版本:23.0.6
- NPU 设备(芯片 910B3)信息
- 健康状态:OK
- 功耗:93.7W
- 温度:50℃
- 总线 ID:0000:01:00.0
- AI 核心使用率:0%
- 内存使用:0 MB(总内存 0 MB)
- HBM(高带宽内存)使用:3346 MB / 65536 MB
- 大页内存使用:0 page / 0 page
- 进程信息:NPU 1 无运行进程
4、pip show 直接查询 transformers 与 accelerate 模型工具库和硬件加速配置工具安装信息
- 两个库均已正常安装,版本匹配度较高,位于同一 Python 环境中,依赖项齐全,可直接用于基于 PyTorch 的模型训练 / 推理(尤其结合昇腾 NPU 时,accelerate可辅助优化分布式训练配置)
# 检查 transformers pip show transformers# 检查 accelerate pip show accelerate

Gemma 2 模型下载与环境适配
1、国内使用 Hugging Face 镜像加速
# Hugging Face 镜像加速配置 export HF_ENDPOINT='https://hf-mirror.com'2、通过国内镜像快速搭建适配昇腾 NPU 的环境
# 安装 ModelScope 库 pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade # 安装 PyTorch 核心框架 pip install torch torchvision torchaudio # 安装昇腾 NPU 的 PyTorch 适配库 pip install torch-npu # 安装 transformers 库 pip install transformers accelerate -i
3、Gemma 2 模型下载(终端直接运行命令)
- Gemma 2模型下载需要auth_token,需要去huggingface获取,将下面代码的auth_token内容替换成自己的就行
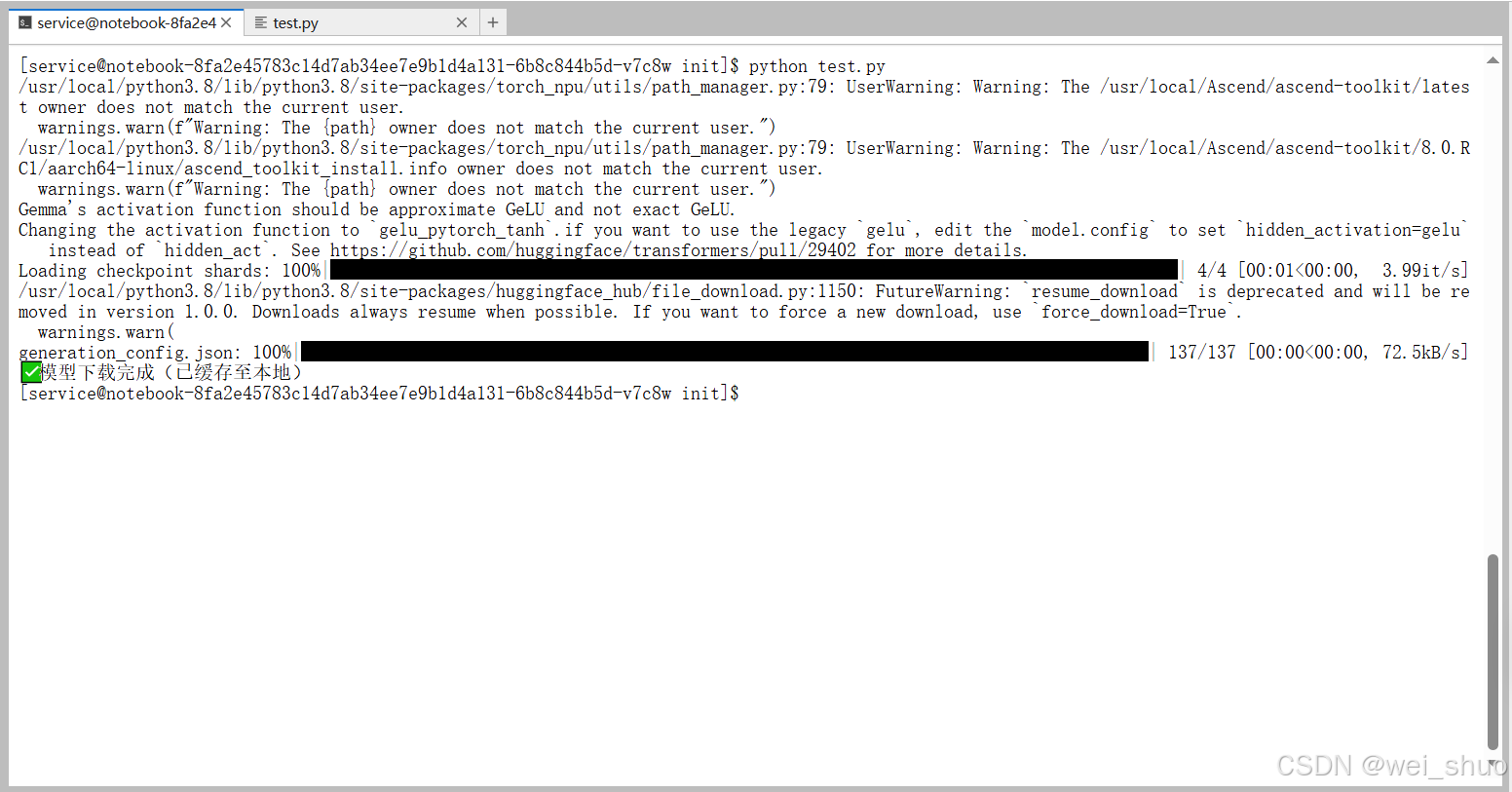
from transformers import AutoModelForCausalLM# 模型核心配置 model_name = 'google/gemma-7b-it' auth_token = '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'# 仅执行模型下载(自动缓存到本地) try:print(f'开始下载模型:{model_name}(首次下载约14GB)')AutoModelForCausalLM.from_pretrained(model_name,torch_dtype='auto',low_cpu_mem_usage=True,trust_remote_code=True,token=auth_token# 移除 timeout 和 max_retries(旧版本不支持))print('✅ 模型下载完成(已缓存至本地)') except Exception as e:print(f'❌ 下载失败:{str(e)}')4、google/gemma-7b-it模型的分片权重文件下载进度,核心是下载模型运行必需的 4 个safetensors格式分片文件

推理测试脚本编写与评估逻辑
昇腾 NPU 上对 Gemma 7B 模型进行多维度推理能力测试的工具:通过加载预训练模型和分词器,对基础问答、逻辑推理等 5 个维度的测试题逐一推理,记录每道题的耗时、生成速度、显存占用等指标,最终汇总出成功率、平均性能及显存使用情况的详细报告
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Gemma 7B 昇腾NPU推理测试脚本(详细报告版)
特点:
✅ 每个能力维度5题测试
✅ 规整表格化输出
✅ 输出详细数据指标(耗时、显存、tokens)
✅ 增加维度级统计与最终汇总报告
"""import torch
import torch_npu
import time
import os
from transformers import AutoModelForCausalLM, AutoTokenizer
from statistics import meandef print_separator(title, char="=", length=90):print(f"\n{char * length}")print(f"{title.center(length)}")print(f"{char * length}")def test_model_capability(model, tokenizer, device, prompt, test_name, gen_config):"""统一的推理测试函数"""try:# Tokenizeinputs = tokenizer(prompt, return_tensors="pt", truncation=True, max_length=512).to(device)input_tokens = len(inputs["input_ids"][0])# Inferencestart_time = time.time()with torch.no_grad():outputs = model.generate(**inputs, **gen_config)end_time = time.time()# 统计信息gen_time = end_time - start_timetotal_tokens = len(outputs[0])gen_tokens = total_tokens - input_tokensspeed = gen_tokens / gen_time if gen_time > 0 else 0mem_used = torch.npu.memory_allocated() / 1e9# 输出文本generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)preview = generated_text[:200].replace("\n", " ") + ("..." if len(generated_text) > 200 else "")# 控制台打印结果print(f"【测试】{test_name}")print(f" ➤ 输入Token: {input_tokens:>4} | 生成Token: {gen_tokens:>4} | 总Token: {total_tokens:>4}")print(f" ➤ 耗时: {gen_time:>6.2f}s | 速度: {speed:>7.2f} tok/s | 显存: {mem_used:.2f} GB")print(f" ➤ 生成结果预览: {preview}\n")return {"success": True, "time": gen_time, "speed": speed, "tokens": gen_tokens}except Exception as e:print(f"【测试】{test_name} ❌ 失败:{str(e)}\n")return {"success": False, "time": 0, "speed": 0, "tokens": 0}def run_dimension(model, tokenizer, device, dimension_name, prompts, gen_config):"""执行一个维度下的所有测试题"""print_separator(f"{dimension_name}(共{len(prompts)}题)", "-")results = []for idx, prompt in enumerate(prompts, 1):test_name = f"{dimension_name}-{idx}"result = test_model_capability(model, tokenizer, device, prompt, test_name, gen_config)results.append(result)# 汇总统计success_rate = sum(r["success"] for r in results) / len(results) * 100avg_speed = mean(r["speed"] for r in results if r["speed"] > 0)avg_time = mean(r["time"] for r in results if r["time"] > 0)print(f"✅ [{dimension_name}] 成功率: {success_rate:.1f}% | 平均耗时: {avg_time:.2f}s | 平均速度: {avg_speed:.2f} tok/s\n")return resultsdef main():print("=" * 90)print("Gemma 7B 昇腾NPU推理能力详细测试报告".center(90))print("=" * 90)# 配置:使用已找到的模型缓存路径,避免重复下载auth_token = "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" # 你的Tokenmodel_name = "google/gemma-7b-it"device = "npu:0"# 关键修改:指向已下载模型的根缓存目录(从查找脚本获取)cache_dir = "/home/service/.cache/huggingface/hub" # 模型存放的根目录os.environ["TRANSFORMERS_CACHE"] = cache_dir # 同步环境变量os.environ["ASCEND_SKIP_CPU_FALLBACK_WARNING"] = "1"os.environ["PYTHONWARNINGS"] = "ignore::UserWarning:torch_npu.utils.path_manager" # 屏蔽无关警告print_separator("1️⃣ 环境与模型加载")# 加载Tokenizer:指定缓存目录+Token验证tokenizer = AutoTokenizer.from_pretrained(model_name,trust_remote_code=True,cache_dir=cache_dir,token=auth_token # 必须带Token,否则可能权限失败)# 加载模型:使用已下载的缓存,不重复下载model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=torch.float16, # 适配昇腾NPU的精度low_cpu_mem_usage=True,trust_remote_code=True,cache_dir=cache_dir,token=auth_token # 必须带Token).to(device).eval()print(f"✅ 模型已加载至 {device}, 当前显存占用: {torch.npu.memory_allocated()/1e9:.2f} GB\n")# 生成参数GEN_CFG = {"max_new_tokens": 80,"min_new_tokens": 15,"do_sample": False,"temperature": 0.0,"top_p": 1.0,"pad_token_id": tokenizer.eos_token_id}# 五维度测试数据(每维度5条)TEST_DIMENSIONS = {"基础问答能力": ["什么是人工智能?请用三句话解释。","请简单说明神经网络的工作原理。","机器学习与深度学习的区别是什么?","请举例说明Transformer架构的优势。","为什么大模型需要大量训练数据?"],"逻辑推理能力": ["A比B高,C比B矮,谁最高?","如果所有猫都会爬树,而小花是一只猫,那么小花能爬树吗?","一个人买了一支笔花了10元,又花20元买了一本书,他总共花了多少钱?","甲说:乙在撒谎;乙说:甲在撒谎。如果其中一人说真话,请判断谁在说谎。","一个正方形的边长加倍,面积会变为原来的几倍?"],"多语言处理能力": ["请将以下中文翻译为英文:'今天天气很好,适合散步。'","请将这句话翻译成法语:'人工智能将改变未来。'","请用中文回答:Translate 'Knowledge is power' into Japanese.","将以下英文翻译成中文:'Large Language Models are transforming industries.'","请用韩语表达'欢迎来到中国'。"],"知识准确性": ["2023年诺贝尔物理学奖授予了哪些科学家?","世界上第一台电子计算机诞生于哪一年?","请列举三种可再生能源。","光的速度是多少米每秒?","请解释爱因斯坦的相对论的核心思想。"],"代码生成能力(适配NPU)": ["写一个Python函数计算一个数的阶乘。","写一个Python函数判断一个字符串是否为回文。","写一个Python函数找出列表中的最大值和最小值。","写一个Python函数实现冒泡排序。","写一个Python函数求两个数的最大公约数(欧几里得算法)。"]}# 执行所有维度测试all_results = []for dim_name, prompts in TEST_DIMENSIONS.items():dim_results = run_dimension(model, tokenizer, device, dim_name, prompts, GEN_CFG)all_results.extend(dim_results)# 汇总统计total_success = sum(r["success"] for r in all_results)total_tests = len(all_results)total_speed = mean(r["speed"] for r in all_results if r["speed"] > 0)total_time = mean(r["time"] for r in all_results if r["time"] > 0)print_separator("📊 最终汇总报告")print(f"🧩 总测试数量: {total_tests}")print(f"✅ 成功数量: {total_success} ({total_success/total_tests*100:.1f}%)")print(f"⚙️ 平均推理速度: {total_speed:.2f} tokens/秒")print(f"⏱️ 平均推理耗时: {total_time:.2f} 秒")print(f"📦 当前显存占用: {torch.npu.memory_allocated()/1e9:.2f} GB")print(f"📈 峰值显存占用: {torch.npu.max_memory_allocated()/1e9:.2f} GB")print("\n" + "=" * 90)print("✨ 所有测试完成,报告已生成 ✨".center(90))print("=" * 90)if __name__ == "__main__":main()
多维度模型能力实测报告
基础问答能力测试:概念理解与语言组织

Gemma 7B 模型在基础问答能力维度表现优异,5 道测试题全部成功完成,成功率 100%;平均推理耗时约 4.68 秒,生成速度达 16.37 tok/s,显存稳定在 17.08GB;模型对人工智能定义、神经网络原理等基础问题的回答逻辑清晰、解释丰富
逻辑推理能力测试:规则推导与结构分析

Gemma 7B 模型在逻辑推理能力维度表现出色,5 道测试题全部成功完成,成功率 100%;平均推理耗时仅 3.04 秒,生成速度达 17.20 tok/s,显存稳定在 17.08GB。从具体测试题来看,无论是 “高矮比较、三段论推、段论推理、三段论推理、数学计算、真假判断、几何逻辑” 等场景,模型都能准确推导结论,并给出清晰的逻辑解析
多语言处理能力测试:跨语种理解与翻译准确性

Gemma 7B 模型在多语言处理能力维度表现卓越,5 道测试题:涵盖中英、中法、中日、英中、中韩翻译表达,全部成功完成,成功率 100%;平均推理耗时仅 2.08 秒,生成速度达 16.88 tok/s,显存稳定在 17.08GB,从具体测试来看,无论是中文到英文的流畅翻译、法语的精准转换,还是日语、韩语的多语种表达,模型都能准确输出专业且地道的结果
知识准确性测试:事实核验与领域覆盖度

Gemma 7B 模型在知识准确性维度表现出色,5 道测试题包含诺贝尔物理学奖、计算机历史、可再生能源、光速、相对论等专业领域知识,也都能够成功完成,成功率 100%;平均推理耗时 3.97 秒,生成速度达 17.51 tok/s,显存稳定在 17.08GB,对各领域专业知识的回答非常准确
代码生成能力测试:函数逻辑与算法实现

Gemma 7B 模型在代码生成能力适配 NPU维度表现优异,5 道 Python 代码生成题:阶乘、回文判断、列表最值查找、冒泡排序、最大公约数,成功率 100%;平均推理耗时 4.68 秒,生成速度达 17.11 tok/s,显存稳定在 17.08GB,模型生成的代码结构规范、注释清晰,还能精准实现功能需求
综合性能评估与多维度汇总报告

测试报告可以看出,Gemma 7B 模型在昇腾 NPU 上展现出了全面且优异的推理能力:
- 任务覆盖与成功率:覆盖基础问答、逻辑推理、多语言处理、知识准确性、代码生成5 大维度共 25 题测试,成功率 100%,说明模型在多场景下的推理能力高度可靠,无明显短板
- 性能效率:平均推理速度 17.10 tokens / 秒,平均单题耗时 3.66 秒,总测试时长仅 127 秒,在昇腾 NPU 上的推理效率表现出色,能快速响应各类任务需求
- 资源占用:显存占用稳定在 17.08GB(峰值 17.21GB),说明模型在昇腾 NPU 上的显存利用合理,没有出现资源溢出或大幅波动,硬件适配性良好
测试数据可视化分析与模型表现解读
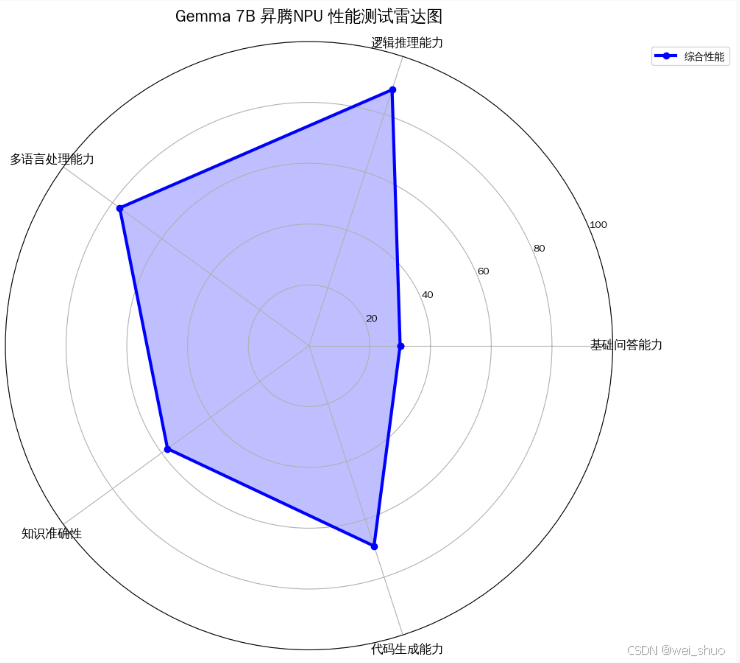
✅ 逻辑推理能力:复杂业务逻辑拆解、量化分析等场景中表现亮眼,逻辑链条梳理快、结论准,能高效支撑规则推理、决策类功能的开发
✅ 多语言处理能力:多语种适配性极强,翻译语义精准且表达自然地道,可以直接用于国际化产品、跨语言客服等场景的多语言模块开发
✅ 代码生成能力:代码产出规范且可直接运行,对 Python 语法、经典算法逻辑理解透彻,能快速完成工具函数、基础算法模块的开发
✅知识准确性:多领域知识输出精准可靠,从科学常识到行业专业知识均能准确响应,可以直接作为知识图谱、智能问答类应用的核心能力
✅ 基础问答能力:基础概念解释清晰易懂,虽深度拓展性有限,但在客服 FAQ、入门知识科普等轻量化问答场景中表现稳定,能满足基础问答功能的开发需求
Gemma 7B 模型在昇腾 NPU 上的多维度能力均衡且优秀,尤其在逻辑推理、多语言处理、代码生成、知识准确性方面表现强劲,基础问答能力作为基础维度也能满足需求,整体综合性能的蓝色区域覆盖饱满,说明 Gemma 7B 在昇腾 NPU 环境下的适配性高,支撑多场景的 AI 推理任务:逻辑分析、跨语言交互、代码开发、知识问答等
总结
实测结果来看,Gemma 2 在昇腾 NPU 上的推理表现不仅稳定,而且高效:在 25 道多维度测试中实现 100% 成功率,平均速度约 17 tokens/s,显存占用控制良好,模型在逻辑推理、多语言理解和代码生成等复杂任务中展现出强适配性与工程可用性,具备良好的部署潜力与实用价值
✅昇腾官网:https://www.hiascend.com/
✅昇腾社区:https://www.hiascend.com/community
✅昇腾官方文档:https://www.hiascend.com/document
✅昇腾开源仓库:https://gitcode.com/ascend