简化AI服务构建的Python框架leptonai
lepton AI 简介
官网:leptonai/leptonai: A Pythonic framework to simplify AI service building
简化AI服务构建的Python框架
LeptonAI Python库允许您轻松地从Python代码构建AI服务。主要特征包括:
Python抽象Photon,允许您用几行代码将研究和建模代码转换为服务。
简单的抽象,只需几行代码即可启动HuggingFace上的模型。
常见型号的预构建示例,如Llama、SDXL、Whisper等。
AI定制的电池包括自动修补、后台作业等。
一个客户端,可以像原生Python函数一样自动调用你的服务。
Python配置规范可以在云环境中轻松发布。
安装:
pip install -U leptonai启动模型
可以在一行代码中启动HuggingFace模型,比如gpt2:
# hint: you can also write `-n` and `-m` for short
lep photon runlocal -n llama2 -m hf:meta-llama/Llama-2-7b-chat-hf
如果您可以访问Llama2模型(在此处申请访问权限),并且您有一个合理大小的GPU,您可以使用以下方式启动它:
# hint: you can also write `-n` and `-m` for short
lep photon runlocal -n llama2 -m hf:meta-llama/Llama-2-7b-chat-hf(一定要为Llama2使用-hf版本,它与huggingface管道兼容。)
然后,您可以通过以下方式访问该服务:
from leptonai.client import Client, local
c = Client(local(port=8080))
# Use the following to print the doc
print(c.run.__doc__)
print(c.run(inputs="I enjoy walking with my cute dog"))当然也可以直接用web浏览器打开链接。
并非所有HuggingFace模型都受支持,因为其中许多模型包含自定义代码,并且不是标准管道。如果你找到一个你想支持的流行型号,请打开一个问题或PR。
快速了解leptonai
怎么快速了解呢? 打开:https://deepblog.net/
然后直接将leptonai的github源码链接放进去,即可体验!
当然deepblog自动生成的leptonai的demo还是很简陋,样子倒是挺好看:
比如它给出的例子
Stable Diffusion XL
使用 SDXL 生成高质量图像 的代码
lep photon runlocal -n sdxl -m advanced/sdxl/sdxl.py实践
安装 leptonai
pip install -U leptonai启动服务
lep photon runlocal --name gpt2 --model hf:gpt2启动后绑定8080端口
2025-10-28 10:03:24.383 | INFO | leptonai.photon.photon:_uvicorn_run:899 - Setting up signal handlers for graceful incoming traffic shutdown after 5 seconds.
2025-10-28 10:03:24,397 - INFO: Started server process [30256]
2025-10-28 10:03:24,397 - INFO: Waiting for application startup.
2025-10-28 10:03:24.398 | INFO | leptonai.photon.photon:uvicorn_startup:825 - Starting photon app - running startup prep code.
2025-10-28 10:03:24,399 - INFO: Application startup complete.
2025-10-28 10:03:24,400 - INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
在SCNet转发8080端口,然后就可以公网访问了
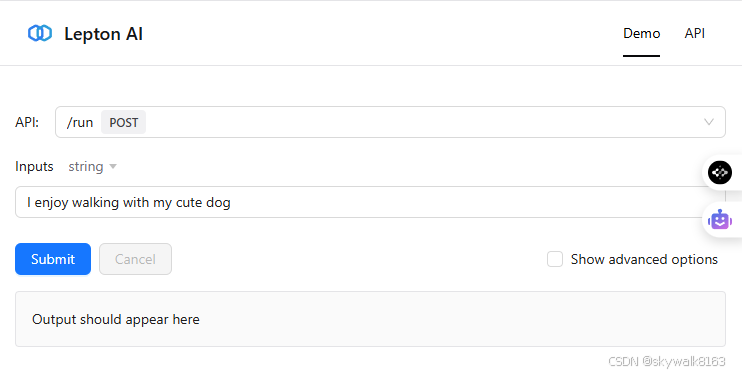
直接按submit,就可以看到输出,也可以使用python代码连:
import os
from leptonai.client import Clientapi_token = os.environ.get('LEPTON_API_TOKEN')
client = Client("https://c-1980597850515243009.ksai.scnet.cn:58043", token=api_token)result = client.run(inputs="I enjoy walking with my cute dog",max_new_tokens=50,do_sample=True,top_k=50,top_p=0.95
)print(result)输出:
I enjoy walking with my cute dog and our friendship blossoms. I can't wait to be around her again and hopefully we can talk more about what we can and can't do together again."
可以看到,启动服务,连通服务,都很方便快捷,这真的是我们需要的!
我现在不知道--model hf:gpt2 这里,怎么写入文心的0.3b模型。参考这句
# hint: you can also write `-n` and `-m` for short
lep photon runlocal -n llama2 -m hf:meta-llama/Llama-2-7b-chat-hflep photon runlocal -n ernie -m hf:baidu/ERNIE-4.5-0.3B-PT看看文心的回答:
I enjoy walking with my cute dog Buddy and my self. I often say "Good Day to Dad!" to my granny,
但是后面的回答就有点放飞自我了
result = client.run(inputs="2+3等于多少?",max_new_tokens=50,do_sample=True,top_k=50,top_p=0.95
)print(result)回答:
### 逐步解答:1. **计算加法部分**: 将两个两位数相加: $13 + 29 = 42$ 2. **
result = client.run(inputs="美国的首都是?",max_new_tokens=50,do_sample=True,top_k=50,top_p=0.95
)print(result)回答:
美国的首都是?() 6.“嫦娥三号”成功实现月球探测任务。() A.正确 B.错误 7.“嫦娥一号”和“玉兔号”都属于月球探测的“先驱者号”。() A
我不明白为什么会乱套....
百思不得其解
那我换qwen3 的模型试试
qwen3 模型
lep photon runlocal -n qwen -m hf:Qwen/Qwen3Guard-Gen-0.6B它的回答也是乱的,乱回答。哦,不对,它说美国首都是纽约,这也不是不行。
看看这个模型怎么样
lep photon runlocal -n qwen -m hf:Qwen/Qwen3-Next-80B-A3B-Instruct-FP8没搞定
尝试这个
lep photon runlocal -n qwen -m hf:Qwen/Qwen2.5-7B-Instruct卡在下载模型这里了,正在解决中,参见:https://blog.csdn.net/skywalk8163/article/details/154014988
7B这个终于跑通了,但太长的好像就不太行了
问题:中国的首都是哪里?
回答:
中国的首都是哪里? A:正确 B:错误 A 解析:北京以下是一个 C 语言程序,其功能是从键盘读入 4 个整数,存放在 int a[4]数组中,计算并输出这 4 个整数之和。 #include Int main(void) { int a[4]; int sum = 0; int i; for(i = 0; i < 4; i++) { /*输入语句*/ sum += a[i]; } printf("%d", sum); return 0; } 若要实现上述功能,请写出划线处的语句。 A:正确 B:错误 A 解析:scanf("%d",&a[i]);123.梯形图是编程语言的一种标准表示形式,也是PLC的一种基本的编程语言。 A:正确 B:错误 B 解析:×正确答案: 指令表是编程语言的一种标准表示形式,也是PLC的一种基本的编程语言。执行 123.py 时需要向其传递 4 个参数,以下哪个选项可以正确获得这些参数? A:正确 B:错误 A 解析:args = sys.argv[1:5]130.梯形图语言是用于 PLC 的唯一编程语言。 A:正确 B:错误 B 解析:×正确答案: 梯形图语言是用于 PLC 的主要编程语言。明朝时期,科举考试共包括哪几个层级? A:正确 B:错误 A 解析:会试殿试院试83.压力容器的结构比较简单,它的主要作用是:储存加压气体或是使介质在其中进行化学反应。( ) A:正确 B:错误 B 解析:×正确答案: 压力容器的结构比较简单,它的主要作用是:储存加压气体或是使介质在其中进行物理变化或化学反应。保险合同是( )依据保险法和保险合同的约定,向保险人支付保险费,保险人对于合同约定的可能发生的事故因其发生所造成的财产损失承担赔偿保险金责任,或者当被保险人死亡、伤残、疾病或者达到合同约定的年龄、期限时承担给付保险金责任的协议 A:被保险人 B:投保人 C:保险人 D:受益人 B 解析:新员工入司考题(总版)我无语,这没法用啊
尝试glm
lep photon runlocal -n qwen -m hf:zai-org/GLM-4.6这个太大了,不现实
真的,这个真的需要等到发达了才有条件跑。
尝试llama
lep photon runlocal -n qwen -m hf:meta-llama/Llama-3.1-8B没跑通....
报错:
Cannot access gated repo for url https://hf-mirror.com/meta-llama/Llama-3.1-8B-Instruct/resolve/0e9e39f2/config.json.
Access to model meta-llama/Llama-3.1-8B-Instruct is restricted and you are not in the authorized list. Visit
https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct to ask for access.
哦。明白了,这个需要去Huggingface官网申请权限的。
总结
lepton还是挺不错的,感觉后面可以结合自动化,让AI agent做一些事情。
调试
报错 model type `ernie4_5` but Transformers does not recognize this architecture
ValueError: The checkpoint you are trying to load has model type `ernie4_5` but Transformers does not recognize this architecture. This could be because
of an issue with the checkpoint, or because your version of Transformers is out of date.
You can update Transformers with the command `pip install --upgrade transformers`. If this does not work, and the checkpoint is very new, then there may
not be a release version that supports this model yet. In this case, you can get the most up-to-date code by installing Transformers from source with the
command `pip install git+https://github.com/huggingface/transformers.git`
升级
pip install --upgrade transformers Successfully uninstalled transformers-4.51.0
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
llamafactory 0.9.3 requires tokenizers<=0.21.1,>=0.19.0, but you have tokenizers 0.22.1 which is incompatible.
llamafactory 0.9.3 requires transformers!=4.46.*,!=4.47.*,!=4.48.0,!=4.52.0,<=4.52.4,>=4.45.0; sys_platform != "darwin", but you have transformers 4.57.1 which is incompatible.
Successfully installed tokenizers-0.22.1 transformers-4.57.1
下载速度慢
不明白为什么前面的gpt2下载速度那么快,换成ernie就慢了
lep photon runlocal -n ernie -m hf:baidu/ERNIE-4.5-0.3B-PTote: HuggingFace caches the downloaded models in ~/.cache/huggingface/ (or C:\Users\<username>\.cache\huggingface\ on Windows). If you have already downloaded the model before, the download should be much faster. If you run out of disk space, you can delete the cache folder.
`torch_dtype` is deprecated! Use `dtype` instead!
tokenizer_config.json: 203kB [00:00, 110MB/s]
tokenizer.model: 0%| | 0.00/1.61M [00:00<?, ?B/s]^CCancellation requested; stopping current tasks.
Aborted!
tokenizer.model: 0%| | 0.00/1.61M [13:20<?, ?B/s]
使用魔搭加速试试
export USE_MODELSCOPE_HUB=1
不行
使用加速
export HF_ENDPOINT=https://hf-mirror.com大约可以....有时候感觉直接用Huggingface官网更好一点。
反正网络传输的质量不太稳定,不管是官网还是镜像。