基于NodeJs实现一个MCP客户端(会话模式和无会话模式)
0 前言
前几天使用NodeJs对照官网文档实现了MCP服务端的开发(文章地址)最近尝试使用NodeJs实现一下MCP的客户端,感觉官网的示例代码对Client端描述得很少,以及对streamableHttp方式的传输的示例代码也很少,后面通过摸索以及对ai的询问终于走通并弄明白了Client 的会话模式和无会话模式。
1 搭建基本环境
1.1 创建项目文件,安装包管理工具,下载依赖
# Create project directory
mkdir mcp-client-demo
cd mcp-client-demo# Initialize npm project
npm init -y# Install dependencies
npm install @modelcontextprotocol/sdk# Install dev dependencies
npm install -D @types/node typescript
1.2 更新package.json文件
用于使用ES模块规范引入
"type": "module"
1.3 下载nodemon
-g 任何项目直接使用
npm i nodemon -g
新增nodemon.json
//nodemon.json
{"watch": ["src"],"ext": "ts","exec": "node --import 'data:text/javascript,import { register } from \"node:module\"; import { pathToFileURL } from \"node:url\"; register(\"ts-node/esm\", pathToFileURL(\"./\"));' ./src/index.ts"
}
1.4 新增tsconfig.json文件
//tsconfig.json
{"compilerOptions": {"target": "ES2022","module": "Node16","moduleResolution": "Node16","strict": true,"esModuleInterop": true,"skipLibCheck": true,"forceConsistentCasingInFileNames": true},"include": ["src"],
}
2 创建 mcpClient 类
2.1 带会话模式的 mcpClient 类
2.1.1 对于MCP会话的相关解释
原文:Session Management
翻译:
MCP “会话”(session)指客户端与服务器之间存在逻辑关联的交互过程,该过程始于初始化阶段。为支持服务器建立有状态会话,需遵循以下规则:
使用流式 HTTP(Streamable HTTP)传输的服务器,可在初始化阶段分配会话 ID(session ID),并将其包含在承载 “初始化结果”(InitializeResult)的 HTTP 响应头Mcp-Session-Id中。
会话 ID 应具备全局唯一性且满足加密安全性要求(例如,通过安全方式生成的 UUID、JWT 令牌或加密哈希值)。
会话 ID 必须仅包含可见 ASCII 字符(字符编码范围为 0x21 至 0x7E)。
若服务器在初始化阶段返回了Mcp-Session-Id,则使用流式 HTTP 传输的客户端,必须在后续所有 HTTP 请求的Mcp-Session-Id头中携带该会话 ID。
要求客户端提供会话 ID 的服务器,对于未携带Mcp-Session-Id头的请求(初始化请求除外),应返回 HTTP 400 “错误请求”(Bad Request)响应。
服务器可在任意时间终止会话,会话终止后,对于携带该会话 ID 的请求,服务器必须返回 HTTP 404 “未找到”(Not Found)响应。
若客户端在发送携带Mcp-Session-Id的请求后收到 HTTP 404 响应,则必须通过发送不带会话 ID 的新 “初始化请求”(InitializeRequest)来启动新会话。
当客户端不再需要某个特定会话时(例如,用户退出客户端应用),应向 MCP 端点发送 HTTP DELETE 请求,并在请求头Mcp-Session-Id中携带该会话 ID,以显式终止会话。
服务器可对该 DELETE 请求返回 HTTP 405 “方法不允许”(Method Not Allowed)响应,表明服务器不支持客户端主动终止会话。
总结一下,就是通过sessionId来作为一组对话上下文数据的唯一标识,后续只要携带这个标识,服务器就可以根据该标识查找到对应的上下文数据进行进一步的对话处理
2.1.2 总体逻辑解释
mcpClient类中需要包含一个Client实例、mcp服务端url、一个transport(不知道应该翻译成啥,觉得应该叫传输器)、工具列表(类型需要参考自己所需大模型的工具类型,这里使用Qwen系列)、sessionId
接着需要实现一个connectToServer函数用于连接mcp服务器,首先需要new 一个 transport,参数传入mcp服务器url。接着client实例使用connect方法连接这个transport,连接成功后即可通过transport实例获取sessionId。拿到sessionId后即可创建重连的相关函数,本例就不再创建
接着client通过listTools方法获取到工具列表,然后遍历组装成自己所需的格式存入tools属性中,以便后续大模型进行调用。本例使用Qwen大模型,其官方示例代码地址如下:Qwen3工具调用
最后封装一个调用工具的方法callTool,即让client调用callTool方法传入调用工具名和工具参数即可调用工具返回结果
2.1.3 完整代码
// With Session Management
import { Client } from '@modelcontextprotocol/sdk/client/index.js';
import { StreamableHTTPClientTransport } from '@modelcontextprotocol/sdk/client/streamableHttp.js';
import { ChatCompletionTool } from 'openai/resources/chat/completions'
export class MCPClient {private client: Clientprivate mcpServerURL: URL// private anthropic: Anthropic;private transport: StreamableHTTPClientTransport | null = nullprivate tools: ChatCompletionTool[] = []private sessionId?: stringconstructor(mcpServerURL: string) {// this.anthropic = new Anthropic({// apiKey: ANTHROPIC_API_KEY,// });this.client = new Client({ name: "mcp-client-cli", version: "1.0.0" })this.mcpServerURL = new URL(mcpServerURL)}// methods will go hereconnectToServer = async () => {try {this.transport = new StreamableHTTPClientTransport(this.mcpServerURL)await this.client.connect(this.transport)// 连接成功后,从 transport 中获取服务端生成的 sessionIdthis.sessionId = this.transport.sessionId;console.log('服务端生成的 sessionId:', this.sessionId);console.log('Connected using Streamable HTTP transport');//获取的工具列表const toolsResult = await this.client.listTools();//遍历列表,组装成大模型需要的工具格式this.tools = toolsResult.tools.map((tool) => ({"type": "function","function": {"name": tool.name,"description": tool.description,"parameters": tool.inputSchema,},}));console.log("Connected to server with tools:",JSON.stringify(this.tools));} catch (error) {console.error("连接失败:", error);}}getTools = () => {return this.tools}callTool = async (toolName: string, toolCallArgsStr: string) => {if (!this.sessionId) {throw new Error("未连接到服务端,请先调用 connectToServer()");}const result = await this.client.callTool({name: toolName,arguments: JSON.parse(toolCallArgsStr),})return result}// 获取当前 sessionId 的方法getSessionId = (): string | undefined => {return this.sessionId;};
}2.2 会话模式对应的服务端
服务端核心代码是生成transport时,设置sessionIdGenerator,通过uuid生成一个sessionId,即
transport = new StreamableHTTPServerTransport({sessionIdGenerator: () => crypto.randomUUID(),onsessioninitialized: sessionId => {// Store the transport by session IDtransports[sessionId] = transport;}
2.2.1 完整代码
此服务端代码参考了官方示例代码,很多时候直接拉下来,然后改成自己需要的逻辑即可
import { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js';
import { StreamableHTTPServerTransport } from '@modelcontextprotocol/sdk/server/streamableHttp.js';
import express from 'express';
import { z } from 'zod';
import { crawlWebFn } from './crawlWeb.js';
import { isInitializeRequest } from '@modelcontextprotocol/sdk/types.js';// Set up Express and HTTP transport
const app = express();
app.use(express.json());// Map to store transports by session ID
const transports: { [sessionId: string]: StreamableHTTPServerTransport } = {};// Handle POST requests for client-to-server communication
app.post('/mcp', async (req, res) => {// Check for existing session IDconst sessionId = req.headers['mcp-session-id'] as string | undefined;console.log('sessionId', sessionId)let transport: StreamableHTTPServerTransport;if (sessionId && transports[sessionId]) {// Reuse existing transporttransport = transports[sessionId];} else if (!sessionId && isInitializeRequest(req.body)) {// New initialization requesttransport = new StreamableHTTPServerTransport({sessionIdGenerator: () => crypto.randomUUID(),onsessioninitialized: sessionId => {// Store the transport by session IDtransports[sessionId] = transport;}// DNS rebinding protection is disabled by default for backwards compatibility. If you are running this server// locally, make sure to set:// enableDnsRebindingProtection: true,// allowedHosts: ['127.0.0.1'],});// Clean up transport when closedtransport.onclose = () => {if (transport.sessionId) {delete transports[transport.sessionId];}};const server = new McpServer({name: 'example-server',version: '1.0.0'});// ... set up server resources, tools, and prompts ...// Register weather toolsserver.tool("crawlWeb","爬取获取网页内容",{url: z.string().url().describe('需要被爬取的网页链接')},async ({ url }) => {try {const result = await crawlWebFn(url) as stringreturn {content: [{type: "text",text: result,},],};} catch (error) {return {content: [{type: "text",text: '爬取网页失败',},],};}},);// Connect to the MCP serverawait server.connect(transport);} else {// Invalid requestres.status(400).json({jsonrpc: '2.0',error: {code: -32000,message: 'Bad Request: No valid session ID provided'},id: null});return;}// Handle the requestawait transport.handleRequest(req, res, req.body);
});const port = parseInt(process.env.PORT || '4002');
app.listen(port, () => {console.log(`MCP Server running on http://localhost:${port}/mcp`);
}).on('error', error => {console.error('Server error:', error);process.exit(1);
});
2.3 无会话模式对应的服务端
无会话模式就更简单了,直接设sessionIdGenerator为undefined即可
const transport = new StreamableHTTPServerTransport({sessionIdGenerator: undefined});
2.3.1 完整代码
import { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js';
import { StreamableHTTPServerTransport } from '@modelcontextprotocol/sdk/server/streamableHttp.js';
import express from 'express';
import { z } from 'zod';
import { crawlWebFn } from './crawlWeb.js';// Set up Express and HTTP transport
const app = express();
app.use(express.json());app.post('/mcp', async (req, res) => {console.log(req.headers)// Create a new transport for each request to prevent request ID collisionsconst transport = new StreamableHTTPServerTransport({sessionIdGenerator: undefined});// Create an MCP serverconst server = new McpServer({name: 'mcp-server-crawl',version: '1.0.0'});// Register weather toolsserver.tool("crawlWeb","爬取获取网页内容",{url: z.string().url().describe('需要被爬取的网页链接')},async ({ url }) => {try {const result = await crawlWebFn(url) as stringreturn {content: [{type: "text",text: result,},],};} catch (error) {return {content: [{type: "text",text: '爬取网页失败',},],};}},);res.on('close', () => {transport.close();});await server.connect(transport);await transport.handleRequest(req, res, req.body);req.on('error', () => {console.log('error')});
});const port = parseInt(process.env.PORT || '4002');
app.listen(port, () => {console.log(`MCP Server running on http://localhost:${port}/mcp`);
}).on('error', error => {console.error('Server error:', error);process.exit(1);
});`在这里插入代码片`
3 index.ts
MCP遵循CS架构,其中Client属于BS架构中的Server端,所以Client实际上是与浏览器交互的服务器,所以就需要写一些后端接口,完整代码如下。
核心逻辑:
调用大模型返回的结果
- 如果有思考的内容,拼接思考的内容, 流式输出内容
- 如果出现工具名称,收集工具名称
- 如果出现工具参数,收集工具参数
- 如果出现工具结束标志,就拿之前收集的工具名称和工具参数进行工具调用
- 如果出现大模型回复内容,拼接回复内容,流式输出内容
此逻辑参考Qwen深度思考示例代码
import express from 'express'
import cors from 'cors'
import { MCPClient } from './mcpClient.js'
import { ChatCompletionMessageParam } from 'openai/resources/chat/completions'
import { OpenAI } from "openai";interface ExtendedDelta extends OpenAI.Chat.Completions.ChatCompletionChunk.Choice.Delta {reasoning_content?: string
}interface Qwen3 extends OpenAI.Chat.Completions.ChatCompletionCreateParamsStreaming {enable_thinking?: boolean
}const mcpClient: MCPClient = new MCPClient('http://127.0.0.1:4002/mcp')const openai = new OpenAI({// 若没有配置环境变量,请用百炼API Key将下行替换为:apiKey: "sk-xxx",apiKey: 'your api key',baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"}
);const app = express()
app.use(cors())
app.use(express.urlencoded({ extended: true }))
app.use(express.json())const prompt = `这是一个可以爬取阅读网页文字内容的工具,如果用户提供了一段完整的网页链接并且需求是获取阅读网页,请调用该工具,否则不调用该工具`
const message: ChatCompletionMessageParam[] = [{role: 'system',content: prompt
}]let reasoningContent = ''
let answerContent = ''
let isAnswering = falseapp.post('/chat', async (req, res) => {console.log(req.body)const { userContent } = req.bodymessage.push({ role: 'user', content: userContent })try {const stream = await openai.chat.completions.create({// 您可以按需更换为其它 Qwen3 模型、QwQ模型或DeepSeek-R1 模型model: 'qwen-plus',messages: message,tools: mcpClient.getTools(),stream: true,enable_thinking: true} as Qwen3)//工具名称let toolName = ''//工具调用参数let toolCallArgsStr = ''console.log('\n' + '='.repeat(20) + '思考过程' + '='.repeat(20) + '\n');for await (const chunk of stream) {if (!chunk.choices?.length) {console.log('\nUsage:');console.log(chunk.usage);continue;}// console.log(JSON.stringify(chunk))const delta: ExtendedDelta = chunk.choices[0].delta;// 只收集思考内容if (delta.reasoning_content !== undefined && delta.reasoning_content !== null) {if (!isAnswering) {process.stdout.write(delta.reasoning_content);}reasoningContent += delta.reasoning_content;}//大模型开始思考调用哪个工具,并输出工具和生成参数//收集并拼接工具名称if (delta.tool_calls && delta.tool_calls[0].function?.arguments) {toolCallArgsStr += delta.tool_calls[0].function.arguments}//收集并拼接工具参数if (delta.tool_calls && delta.tool_calls[0].function?.name) {toolName += delta.tool_calls[0].function.name}//判断工具输出结束标志if (chunk.choices[0].finish_reason === 'tool_calls') {//此处可以调用大模型调用工具const result = await mcpClient.callTool(toolName, toolCallArgsStr);console.log('mcp爬取网页内容', JSON.stringify(result))//再次发送给大模型让大模型输出message.push({ role: 'user', content: result.content as string })const toolStream = await openai.chat.completions.create({// 您可以按需更换为其它 Qwen3 模型、QwQ模型或DeepSeek-R1 模型model: 'qwen-plus',messages: message,stream: true,enable_thinking: false} as Qwen3)//流式输出for await (const chunk of toolStream) {if (!chunk.choices?.length) {console.log('\nUsage:');console.log(chunk.usage);continue;}const delta: ExtendedDelta = chunk.choices[0].delta;// 收到content,开始进行回复if (delta.content !== undefined && delta.content) {if (!isAnswering) {console.log('\n' + '='.repeat(20) + '调用工具后的回复' + '='.repeat(20) + '\n');isAnswering = true;}process.stdout.write(delta.content);answerContent += delta.content;}}}// 收到content,开始进行回复if (delta.content !== undefined && delta.content) {if (!isAnswering) {console.log('\n' + '='.repeat(20) + '完整回复' + '='.repeat(20) + '\n');isAnswering = true;}process.stdout.write(delta.content);answerContent += delta.content;}}} catch (error) {console.error('Error:', error);}
})app.listen(5000, async () => {console.log('mcp服务启动成功, 端口是5000')try {await mcpClient.connectToServer()} catch (error) {console.error('mcp服务器连接失败', error)}
})
4 测试效果
4.1 打包并启动项目
//打包服务器ts为js可运行代码
npm run build//启动 mcp 服务器
pnpm run start1//服务器启动
MCP Server running on http://localhost:4002/mcp
//启动客户端
npm run dev
客户端启动成功并打印出工具列表
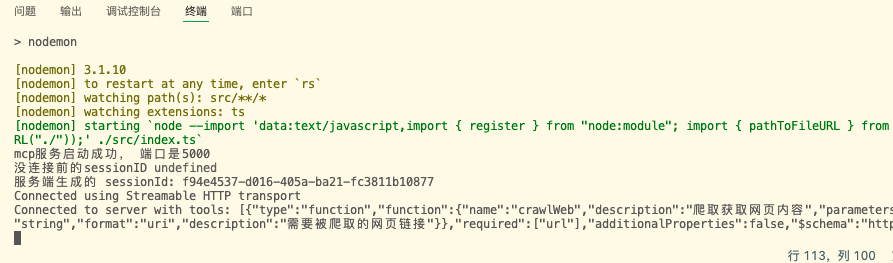
此时服务端生成了sessionId,并存储在服务器中,接着测试一下,重启客户端并携带sessionId
4.2 测试携带与不携带sessionId连接
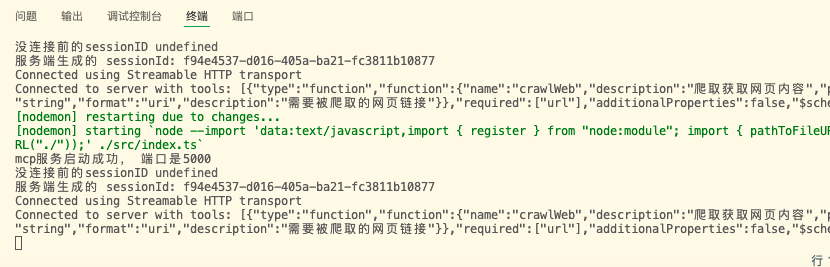
首先测试携带之前在服务端存储的sessionId进行连接
this.transport = new StreamableHTTPClientTransport(this.mcpServerURL, {sessionId: 'f94e4537-d016-405a-ba21-fc3811b10877'})
重启并连接成功
接着尝试输入错误的sessionId尝试连接
this.transport = new StreamableHTTPClientTransport(this.mcpServerURL, {sessionId: 'error sessionId'})
连接失败
打印内容
Error: Error POSTing to endpoint (HTTP 400): {"jsonrpc":"2.0","error":{"code":-32000,"message":"Bad Request: No valid session ID provided"},"id":null}
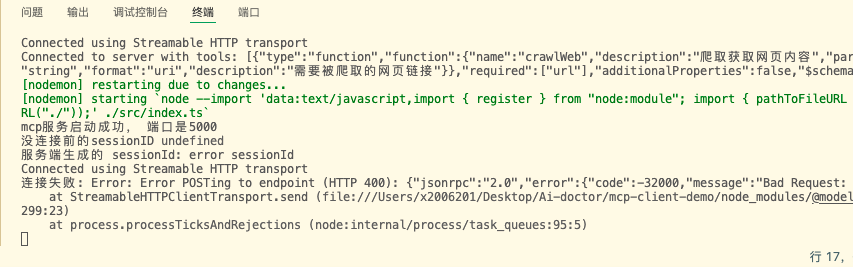
所以session应用成功,接着测试对话和工具调用
4.3 测试简单对话
4.3.1 输入怎么炒鸡蛋
在postman中调用post请求,携带内容问ai怎么炒鸡蛋
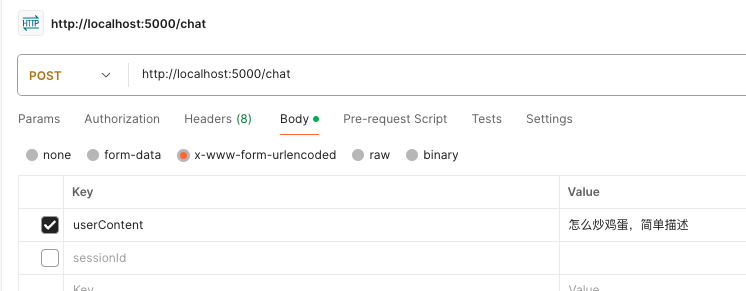
4.3.2 大模型输出
大模型思考得出结论这个问题不需要调用工具并生成了回复

4.4 测试工具调用
4.4.1 输入怎么炒鸡蛋
在postman中调用post请求,内容中包含网页链接,并提问ai
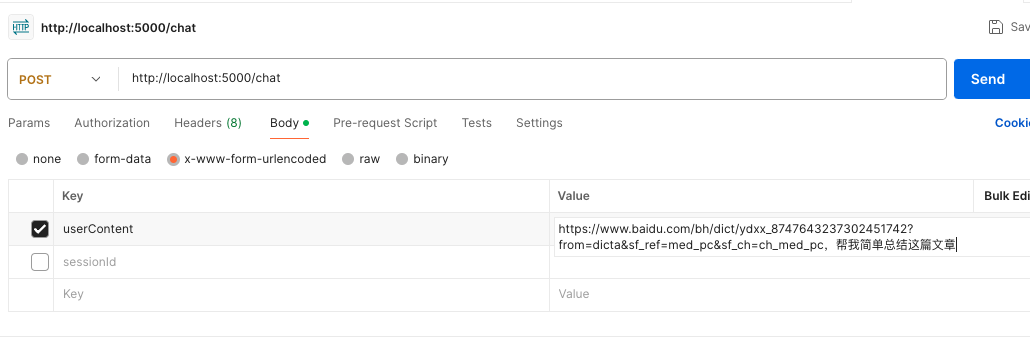
4.4.2 大模型输出
大模型根据代码中写的提示词进行了思考,得出要调用工具的结论,于是,调用crawlWeb函数爬取了链接对应的文章内容

得到爬取的网页内容后将该文本内容继续回复给大模型,大模型根据上下文进行了进一步回复,即对这篇文章进行了总结,至此测试成功,符合预期。

5 小小总结
感觉目前mcp相关的文章以及bug对应的文章很少,自己遇见的问题很难从论坛中得到解决方法,通过提问大模型也经常容易出现幻觉,给出一些不存在的api,不过好在最终简单走通了整个流程,学无止尽。