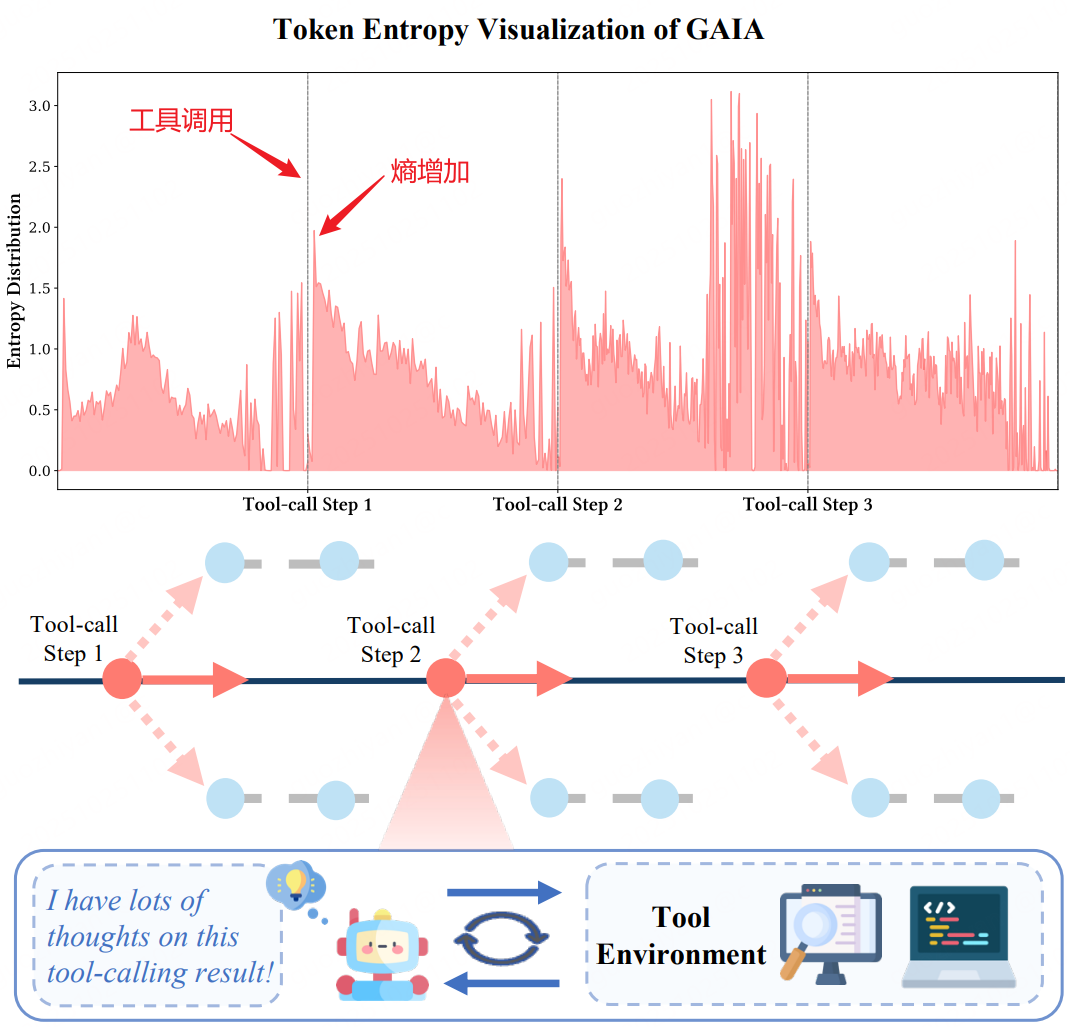
探索Agent工具调用时的高熵时刻
- AGENTIC REINFORCED POLICY OPTIMIZATION
速通这篇论文:
1.Agent 工具调用后的高熵时刻
几个发现:
- 工具调用完拼接工具结果后,继续生成的10-50个token的熵急剧增加
- 在推理的早期熵也会增加,但是仍低于工具调用后的熵
2. 论文动机
-
PPO、GRPO等方法从Trajectory的粒度优化Agent工具调用行为,忽略了关键时刻——工具调用的时刻,存在工具调用次数多、低效等问题。
-
工具调用后不确定性增加
- 工具调用完拼接工具结果后,继续生成的10-50个token的熵急剧增加
- 在推理的早期熵也会增加,但是仍低于工具调用后的熵
-
工具调用后熵增恰是模型推理的关键分叉点。此时模型可以探索多样化的工具路径(如是否继续调用工具、调用哪种工具),找到最优策略。轨迹级采样未针对高熵步骤分配额外探索资源,导致模型无法有效挖掘这一阶段的潜在有效行为。
3. 论文方法
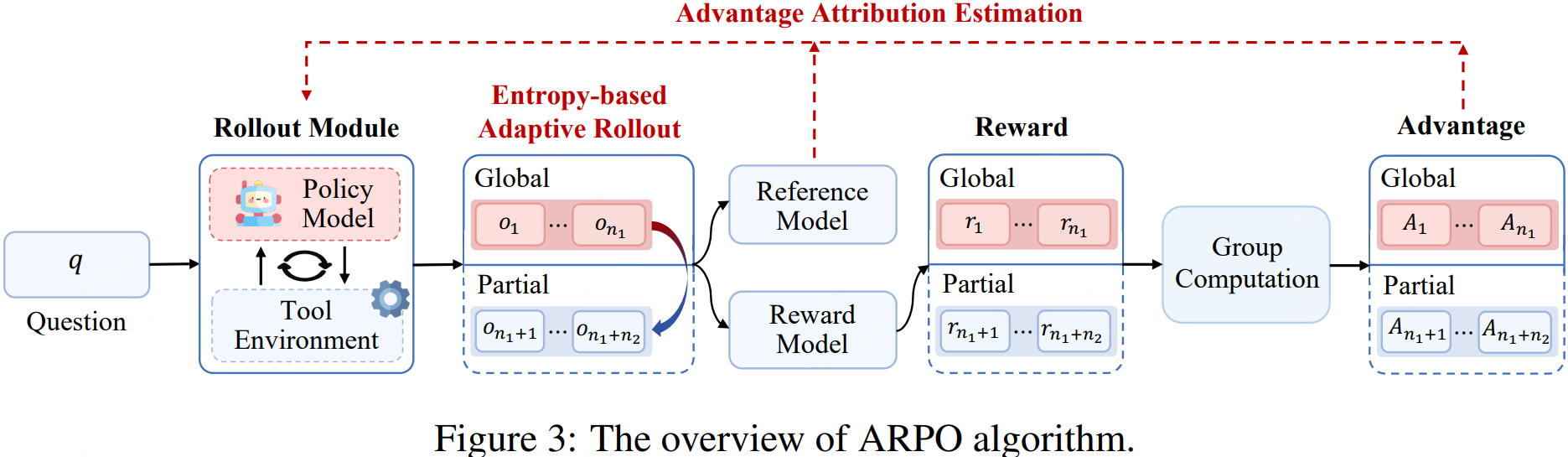
3.1 ENTROPY-BASED ADAPTIVE ROLLOUT
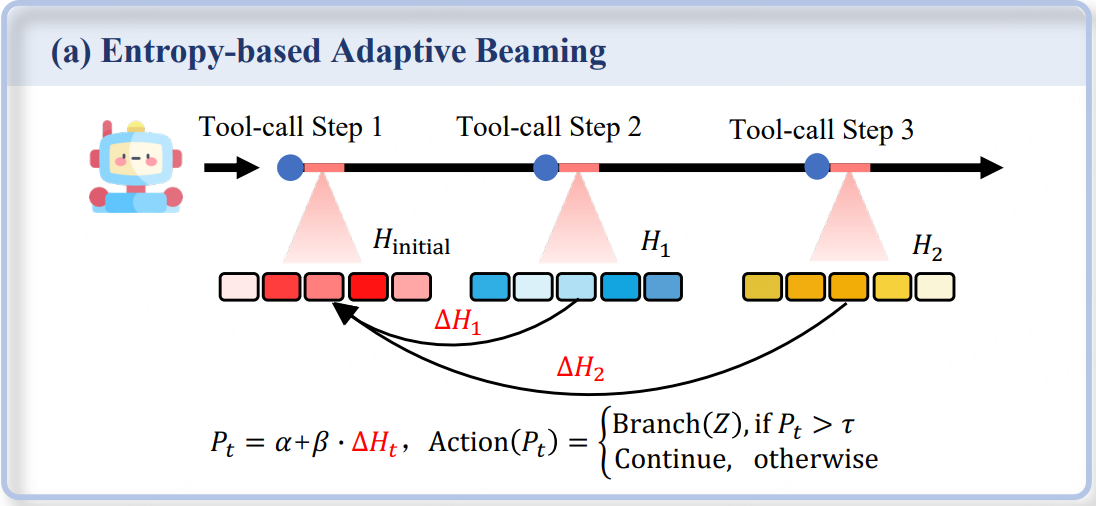
基于熵的自适应Rollout,简单来说,就是在rollout的过程中,并不是一次性rollout到结束,而是在工具调用节点进行判断,是否进行分支。
- 先初始化一些rollout直至第一次工具调用
- 计算每个rollout前k个token的熵
- 继续生成,在每次工具调用后继续生成k个token,并计算熵,根据当前熵判断是否产生分支还是继续生成
- 最终得到多个rollout,其中一些rollout会存在共享的节点
3.2 ADVANTAGE ATTRIBUTION ESTIMATION
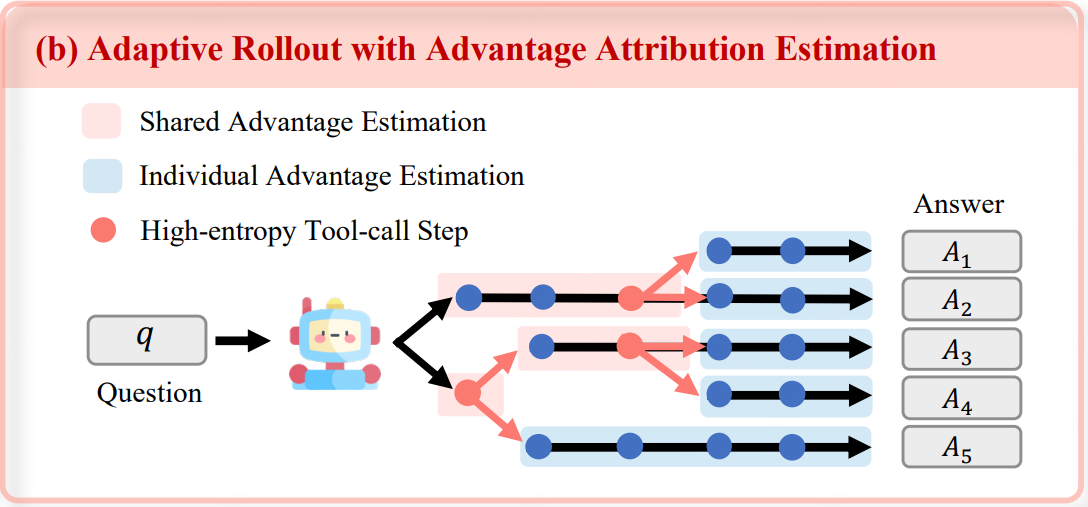
优势归因估计,上一步产生了大量具有“共同前缀+不同分支”结构的rollouts。如何将奖励分配给rollout上的不同节点以区分它们的重要性呢?论文提出了两种方法:
- Hard Advantage Estimation
共享、独占 token的优势独立计算 - Soft Advantage Estimation。通过重要性采样区分共享和独占tokens
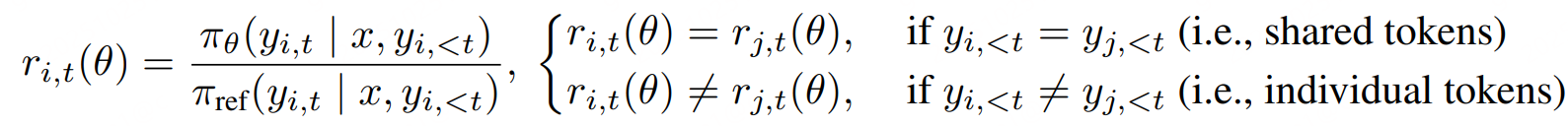
4. 实验
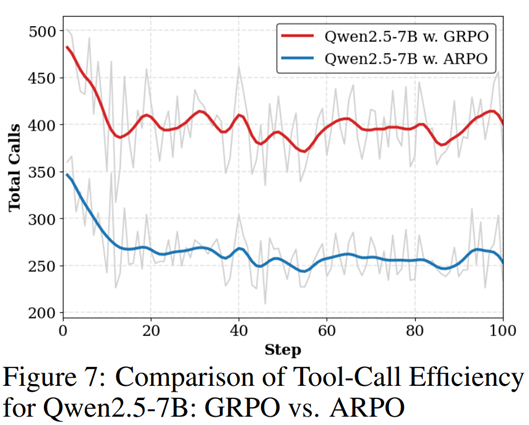
一般的实验对比自然不用说了,肯定是有提升的,如下图所示。
有一个有趣的点,可以看到Webthinker-14B在HLE这个测试集上表现的尤其好啊,可以体验一下~
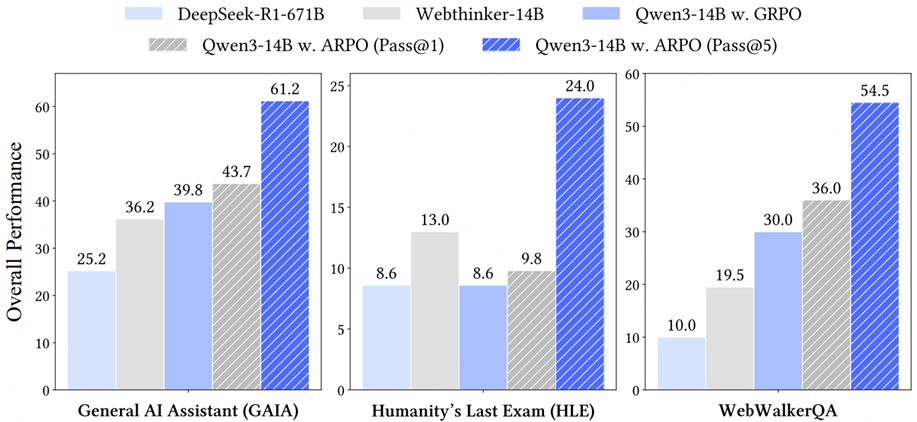
在效果提升的同时,也可以看到模型工具使用效率相比GRPO下降了一半,这点还是不错了,提升了Agent完成任务的效率。