elasticSearch之API:Ingest Pipeline Painless Script
文章目录
一、Ingest Pipeline & Painless Script
1、应用场景
应用场景: 修复与增强写入数据
案例
需求:Tags字段中,逗号分隔的文本应该是数组,而不是一个字符串。后期需要对Tags进行Aggregation统计
#Blog数据,包含3个字段,tags用逗号间隔
PUT tech_blogs/_doc/1
{"title":"Introducing big data......","tags":"hadoop,elasticsearch,spark","content":"You konw, for big data"
}
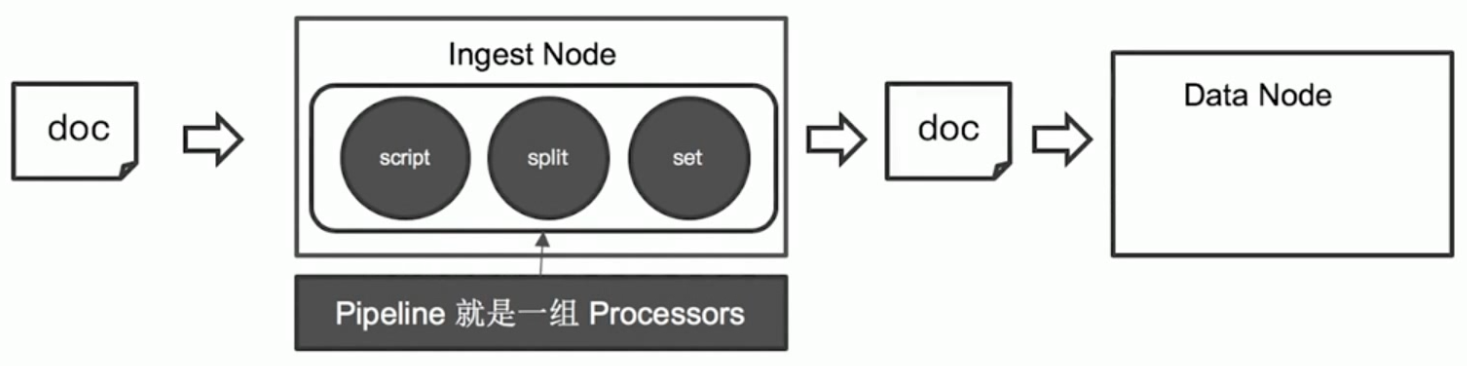
2、Ingest Node
Elasticsearch 5.0后,引入的一种新的节点类型。默认配置下,每个节点都是Ingest Node:
具有预处理数据的能力,可拦截lndex或 Bulk API的请求
对数据进行转换,并重新返回给Index或 Bulk APl
无需Logstash,就可以进行数据的预处理,例如:
为某个字段设置默认值;重命名某个字段的字段名;对字段值进行Split 操作
支持设置Painless脚本,对数据进行更加复杂的加工
3、Pipeline & Processor
(1)简介
Pipeline ——管道会对通过的数据(文档),按照顺序进行加工
Processor——Elasticsearch 对一些加工的行为进行了抽象包装
Elasticsearch 有很多内置的Processors,也支持通过插件的方式,实现自己的Processor
一些内置的Processors
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/ingest-processors.html
Split Processor : 将给定字段值分成一个数组
Remove / Rename Processor :移除一个重命名字段
Append : 为商品增加一个新的标签
Convert:将商品价格,从字符串转换成float 类型
Date / JSON:日期格式转换,字符串转JSON对象
Date lndex Name Processor︰将通过该处理器的文档,分配到指定时间格式的索引中
Fail Processor︰一旦出现异常,该Pipeline 指定的错误信息能返回给用户
Foreach Process︰数组字段,数组的每个元素都会使用到一个相同的处理器
Grok Processor︰日志的日期格式切割)
Gsub / Join / Split︰字符串替换│数组转字符串/字符串转数组
Lowercase / upcase︰大小写转换
# 测试split tags
POST _ingest/pipeline/_simulate
{"pipeline": {"description": "to split blog tags","processors": [{"split": {"field": "tags","separator": ","}}]},"docs": [{"_index": "index","_id": "id","_source": {"title": "Introducing big data......","tags": "hadoop,elasticsearch,spark","content": "You konw, for big data"}},{"_index": "index","_id": "idxx","_source": {"title": "Introducing cloud computering","tags": "openstack,k8s","content": "You konw, for cloud"}}]
}#同时为文档,增加一个字段。blog查看量
POST _ingest/pipeline/_simulate
{"pipeline": {"description": "to split blog tags","processors": [{"split": {"field": "tags","separator": ","}},{"set":{"field": "views","value": 0}}]},"docs": [{"_index":"index","_id":"id","_source":{"title":"Introducing big data......","tags":"hadoop,elasticsearch,spark","content":"You konw, for big data"}},{"_index":"index","_id":"idxx","_source":{"title":"Introducing cloud computering","tags":"openstack,k8s","content":"You konw, for cloud"}}]
}
(2)创建pipeline
# 为ES添加一个 Pipeline
PUT _ingest/pipeline/blog_pipeline
{"description": "a blog pipeline","processors": [{"split": {"field": "tags","separator": ","}},{"set":{"field": "views","value": 0}}]
}#查看Pipleline
GET _ingest/pipeline/blog_pipeline(3)使用pipeline更新数据
#不使用pipeline更新数据
PUT tech_blogs/_doc/1
{"title":"Introducing big data......","tags":"hadoop,elasticsearch,spark","content":"You konw, for big data"
}#使用pipeline更新数据
PUT tech_blogs/_doc/2?pipeline=blog_pipeline
{"title": "Introducing cloud computering","tags": "openstack,k8s","content": "You konw, for cloud"
}
(4)借助update_by_query更新已存在的文档
#update_by_query 会导致错误
POST tech_blogs/_update_by_query?pipeline=blog_pipeline
{
}#增加update_by_query的条件
POST tech_blogs/_update_by_query?pipeline=blog_pipeline
{"query": {"bool": {"must_not": {"exists": {"field": "views"}}}}
}GET tech_blogs/_search
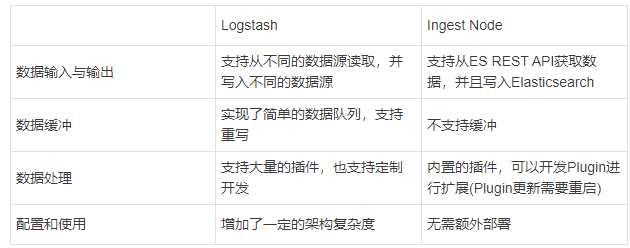
(5)Ingest Node VS Logstash
(6)Painless
自Elasticsearch 5.x后引入,专门为Elasticsearch 设计,扩展了Java的语法。6.0开始,ES只支持 Painless。Groovy,JavaScript和 Python 都不再支持。Painless支持所有Java 的数据类型及Java API子集。
Painless Script具备以下特性:
高性能/安全
支持显示类型或者动态定义类型
Painless的用途:
可以对文档字段进行加工处理
.更新或删除字段,处理数据聚合操作
.Script Field:对返回的字段提前进行计算
.Function Score:对文档的算分进行处理
在lngest Pipeline中执行脚本
在Reindex APl,Update By Query时,对数据进行处理
通过Painless脚本访问字段
测试:
# 增加一个 Script Prcessor
POST _ingest/pipeline/_simulate
{"pipeline": {"description": "to split blog tags","processors": [{"split": {"field": "tags","separator": ","}},{"script": {"source": """if(ctx.containsKey("content")){ctx.content_length = ctx.content.length();}else{ctx.content_length=0;}"""}},{"set":{"field": "views","value": 0}}]},"docs": [{"_index":"index","_id":"id","_source":{"title":"Introducing big data......","tags":"hadoop,elasticsearch,spark","content":"You konw, for big data"}},{"_index":"index","_id":"idxx","_source":{"title":"Introducing cloud computering","tags":"openstack,k8s","content":"You konw, for cloud"}}]
}DELETE tech_blogs
PUT tech_blogs/_doc/1
{"title":"Introducing big data......","tags":"hadoop,elasticsearch,spark","content":"You konw, for big data","views":0
}POST tech_blogs/_update/1
{"script": {"source": "ctx._source.views += params.new_views","params": {"new_views":100}}
}# 查看views计数
POST tech_blogs/_search#保存脚本在 Cluster State
POST _scripts/update_views
{"script":{"lang": "painless","source": "ctx._source.views += params.new_views"}
}POST tech_blogs/_update/1
{"script": {"id": "update_views","params": {"new_views":1000}}
}GET tech_blogs/_search
{"script_fields": {"rnd_views": {"script": {"lang": "painless","source": """java.util.Random rnd = new Random();doc['views'].value+rnd.nextInt(1000);"""}}},"query": {"match_all": {}}
}
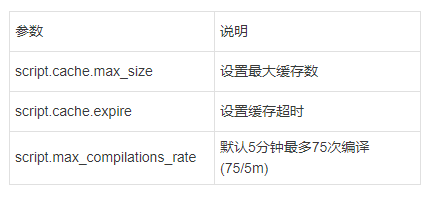
(7)脚本缓存
脚本编译的开销较大,Elasticsearch会将脚本编译后缓存在Cache 中
.Inline scripts和 Stored Scripts都会被缓存
.默认缓存100个脚本