【医学影像 AI】AutoMorph:基于深度学习的视网膜血管自动化分析工具
更多内容请关注【医学影像 AI by youcans@Xidian 专栏】
【医学影像 AI】AutoMorph:基于深度学习的自动化视网膜血管分析工具
- 0. 论文简介
- 0.1 基本信息
- 0.2 论文概览
- 0.3 摘要
- 1. 引言
- 2. 方法
- 2.1 数据集
- 2.2 模块
- 2.3 集成与置信度分析
- 2.4 统计分析与对比方法
- 3. 结果
- 3.1 图像质量分级
- 3.2 解剖结构分割
- 3.3 血管特征测量
- 3.4 运行效率和界面
- 4. 讨论
- 5. 附录
- S1. 数据集
- S2. 图像质量分级模块
- S3. 解剖分割模块
- S4. C区和全图像中的血管特征
- S5. 测量特征的详细列表
- 6. Github 项目介绍
- 6.1 AutoMorph 项目介绍
- 6.2 AutoMorph 快速入门
- 6.3 常见问题
- 7. 参考文献
0. 论文简介
0.1 基本信息
2022年,Zhou Y等 在 Transl Vis Sci Technol 发布论文 【AutoMorph:基于深度学习的视网膜血管自动化分析工具】(AutoMorph: Automated Retinal Vascular Morphology Quantification Via a Deep Learning Pipeline)。
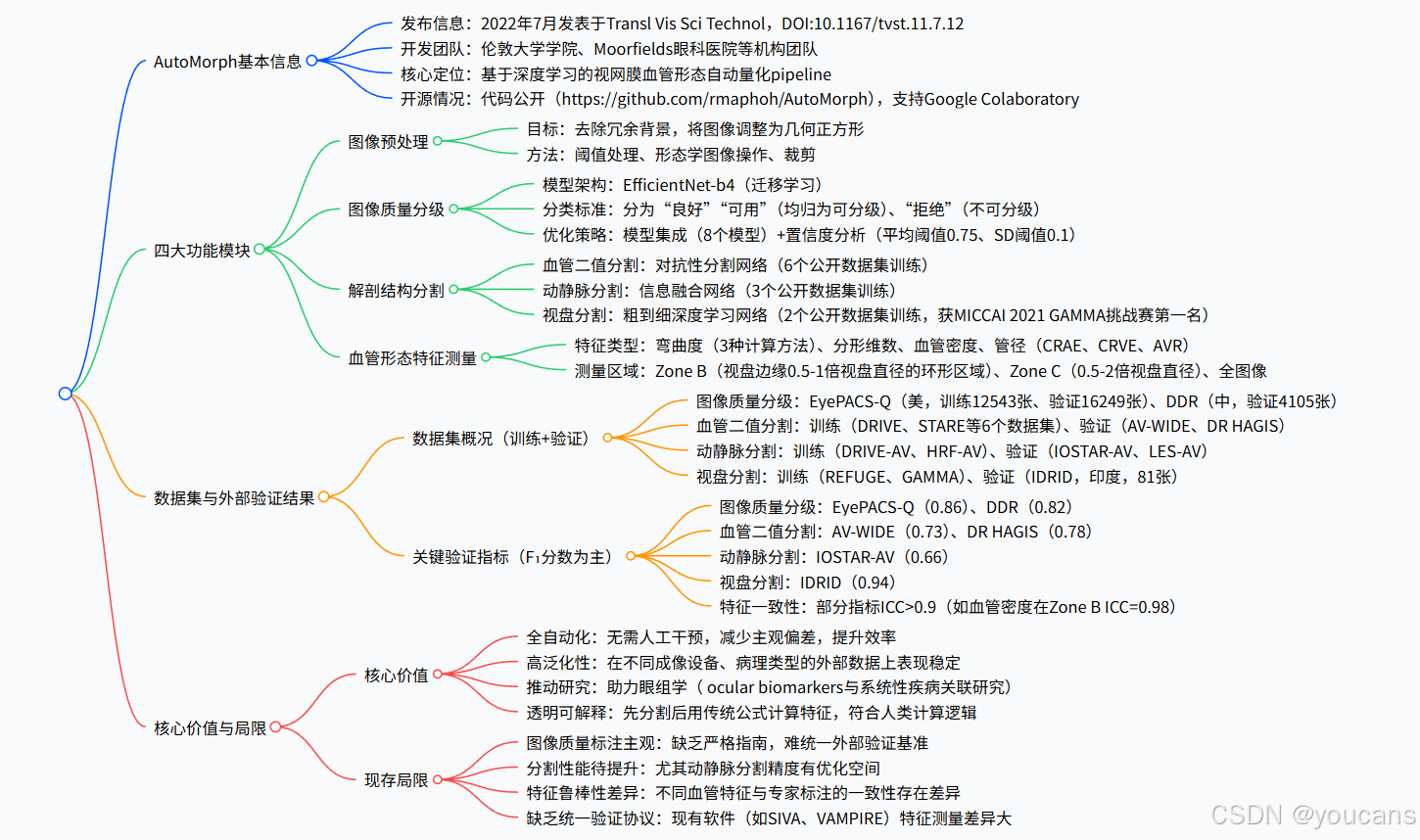
AutoMorph 是一款基于深度学习的视网膜血管自动化分析工具,包含图像预处理、图像质量分级、解剖结构分割、血管形态特征测量四大模块,通过模型集成与置信度分析提升可靠性,在多组独立公开数据集上外部验证表现优异(如图像质量分级 F₁分数 0.86、视盘分割 F₁分数 0.94),且测量特征与专家标注一致性良好,可助力眼科及系统性疾病研究,推动眼组学领域发展。
论文下载: nih,tvst
项目地址:github
引用格式: Zhou Y, Wagner SK, Chia MA, Zhao A, et al. AutoMorph: Automated Retinal Vascular Morphology Quantification Via a Deep Learning Pipeline. Transl Vis Sci Technol. 2022 Jul 8;11(7):12. doi: 10.1167/tvst.11.7.12.

0.2 论文概览
AutoMorph 是一款基于深度学习的视网膜血管形态自动量化 pipeline(代码库:https://github.com/rmaphoh/AutoMorph)。
核心目标:
通过深度学习 pipeline 实现视网膜眼底图像血管形态的全自动分析与量化,并通过外部验证验证其泛化性,最终开源以推动眼科及系统性疾病研究(尤其眼组学领域)。
功能模块
包含图像预处理、图像质量分级、解剖结构分割(含血管二值分割、动静脉分割、视盘 / 视杯分割)、血管形态特征测量四大功能模块。
-
1 、图像预处理模块
- 核心问题:视网膜眼底图像常含冗余背景,且尺寸可能偏离几何正方形,影响后续分析。
- 处理方法:结合阈值处理、形态学图像操作、裁剪技术,去除背景并将图像标准化为几何正方形(示例见补充图 S2)。
-
2、图像质量分级模块
- 目标:筛选出 “不可分级” 图像(避免其导致后续分割与测量误差),将图像分为 “良好”“可用”(均归为可分级)、“拒绝”(不可分级)三类。
- 模型架构:采用EfficientNet-b4,基于 EyePACS-Q 数据集进行迁移学习。
- 模型集成:使用 8 个基于不同训练子集训练的模型,提升结果鲁棒性。
- 置信度分析:计算 8 个模型预测结果的平均概率与标准差(SD),设置阈值(平均概率 <0.75 或 SD>0.1)将低置信度的 “可分级” 预测修正为 “不可分级”,最终将误判为可分级的图像数量减少76%。
-
3、解剖结构分割模块
该模块是特征测量的基础,针对三类关键结构设计 血管二值分割、动静脉分割、视盘分割网络。- 血管二值分割:血管细且低对比度背景干扰,通过对抗网络增强特征提取
- 动静脉分割:动静脉区分难度大,通过多源信息融合提升分类精度
- 视盘分割网络:近视或青光眼导致的视盘周围萎缩影响定位,通过 “粗定位 - 细分割” 提升准确性
-
4、血管形态特征测量模块
- (1)弯曲度:提供 3 种计算方法(距离测量弯曲度、平方曲率弯曲度、弯曲度密度)。
- (2)复杂程度:分形维数(Minkowski–Bouligand 维数)。
- (3)血管密度:血管面积与全图像面积的比值。
- (4)管径参数:计算视网膜中央动脉等效值(CRAE)、视网膜中央静脉等效值(CRVE)、动静脉比(AVR),采用 Hubbard 和 Knudtson 两种标准方法。
- 测量区域:
Zone B:视盘边缘 0.5-1 倍视盘直径的环形区域。
Zone C:视盘边缘 0.5-2 倍视盘直径的环形区域。
全图像:针对黄斑中心图像可能超出眼底范围的情况补充测量。
验证结果:
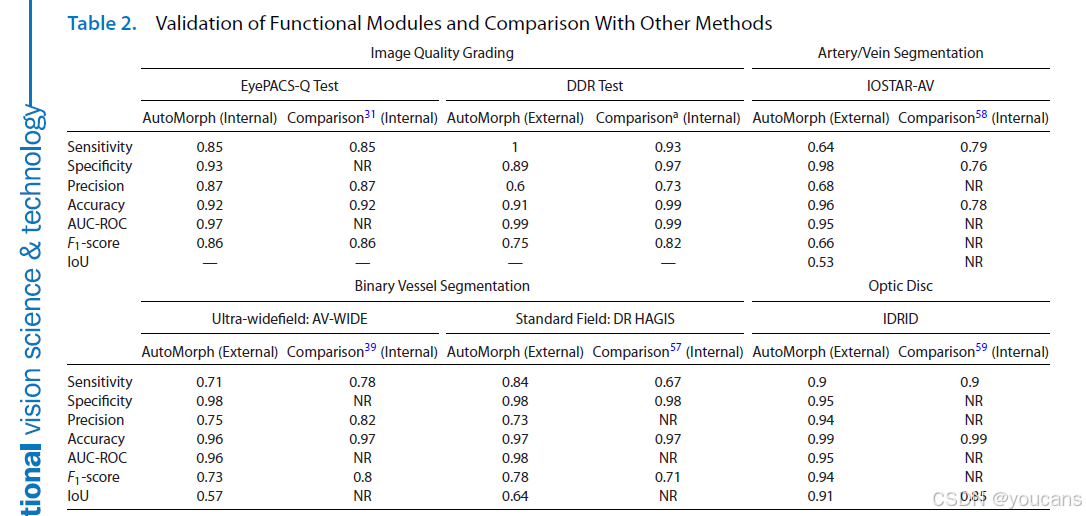
- AutoMorph 在各模块的外部验证中表现优异,关键指标(以 F₁分数为核心)如下表,且性能与现有最优方法相当或更优:
- 图像质量分级(EfficientNet-b4 架构)在 EyePACS-Q 数据集 F₁分数达0.86,
- 血管二值分割在 AV-WIDE 和 DR HAGIS 数据集 F₁分数分别为0.73和0.78,
- 动静脉分割在 IOSTAR-AV 数据集 F₁分数为0.66,
- 视盘分割在 IDRID 数据集 F₁分数为0.94
- 特征一致性验证:通过Bland-Altman 图与组内相关系数(ICC) 验证 AutoMorph 测量特征与专家标注的一致性,测量的血管形态特征与专家标注具有良好至优秀的一致性(部分指标 ICC>0.9),可助力眼科及系统性疾病研究,尤其推动新兴的眼组学(oculomics) 领域发展。
0.3 摘要
目的: 对外验证用于眼底照片视网膜血管形态自动化分析的深度学习流程(AutoMorph)。AutoMorph已公开提供,有助于在眼科和系统性疾病研究中广泛开展研究。
方法: AutoMorph由四个功能模块组成:图像预处理、图像质量分级、解剖分割(包括二进制血管、动脉/静脉和视盘/杯分割)以及血管形态特征测量。图像质量分级和解剖分割采用了最新的深度学习技术。我们采用模型集成策略以获得稳健的结果,并分析预测置信度以纠正图像质量分级中的错误分级情况。我们在几个独立的公开可用数据集上对外验证了每个模块的性能。
结果: 图像分级模块中使用的EfficientNet-b4架构在EyePACS-Q上实现了与现有最佳水平相当的性能,F1分数为0.86。置信度分析将错误评估为可分级的图像数量减少了76%。二进制血管分割在AV-WIDE上实现了0.73的F1分数,在DR HAGIS上实现了0.78的F1分数。动脉/静脉分数在IOSTAR-AV上为0.66,视盘分割在IDRID中实现了0.94的分数。从AutoMorph分割图和专家注释中测量的血管形态特征显示出良好到极佳的一致性。
结论: 即使在外部验证数据与训练数据存在领域差异(例如,使用不同的成像设备)的情况下,AutoMorph模块仍然表现良好。因此,这一完全自动化的流程可以实现对彩色眼底照片视网膜血管形态的详细、高效和全面分析。
转化相关性:通过将AutoMorph公开并开源,我们希望促进眼科和系统性疾病的研究,特别是在新兴的视网膜组学领域。
1. 引言
近几十年来,快速、无创的视网膜成像技术得以广泛应用,这已成为眼科学领域最显著的进展之一。
视网膜血管在眼科疾病评估中的重要性已广为人知;此外,其在揭示系统性疾病相关信息方面的作用也引发了越来越多的关注,这一领域被称为 “眼组学(oculomics)”[1-4]。视网膜动脉变窄与高血压和动脉粥样硬化相关 [5-8],视网膜静脉扩张则与糖尿病视网膜病变有关 [9-11]。研究还发现,视网膜动脉弯曲度增加同样与高胆固醇血症和高血压存在关联 [12-14]。
鉴于人工血管分割和特征提取不仅极为耗时,且可重复性较差 [15],研发能够全自动提取视网膜血管特征的工具已成为当前研究的热点方向。
近几十年来,大量技术研究聚焦于视网膜血管图分割领域。从无监督的基于图和特征的方法 [16-20],到有监督的深度学习模型 [21],各类技术的应用使得分割性能得到了显著提升。然而,尽管取得了这些进展,这些技术在临床研究中的广泛应用仍受到诸多因素的限制。首先,许多技术论文 [21-25] 往往仅关注单一功能的实现,却忽略了预处理 [24,25] 和特征测量 [21-23] 等上下游任务。其次,现有技术在实际临床环境中应用时,由于在其开发环境之外的泛化能力较差,往往表现不佳 [26,27]。
尽管已有部分软件应用于临床研究,但其中大多数为半自动化工具,需要人工干预以校正血管分割结果和识别动静脉 [6,24,25,28,29]。这不仅限制了流程效率,还会引入主观偏差,可能对最终结果产生影响。此外,大多数现有软件未能集成该类流程所需的关键功能,即图像裁剪、质量评估、分割和血管特征测量。例如,在研究队列中,医生通常需要手动筛选低质量图像,这无疑会增加大量工作负担。同时,利用最新的机器学习进展改进基础分割算法,进而提高血管特征测量的准确性,仍有较大的探索空间。
在本研究中,我们探索了利用深度学习流程对彩色眼底图像进行视网膜血管形态自动分析的可行性。我们提出的 AutoMorph 流程具有以下三个独特优势:
- AutoMorph 包含四个功能模块,分别为:(1)视网膜图像预处理;(2)图像质量分级;(3)解剖结构分割(包括血管二值分割、动静脉分割和视盘分割);(4)形态特征测量。
- AutoMorph 通过解决两个关键问题,减少了对医生干预的需求。一方面,我们采用集成技术结合置信度分析,减少了将不可分级图像错误分类为可分级图像(误判可分级图像)的数量;另一方面,精准的血管二值分割和动静脉识别降低了人工校正的需求。AutoMorph 能够生成多种视网膜特征测量结果,已有研究表明这些特征有望用于探索系统性疾病的眼部生物标志物。
- 最重要的是,我们已将 AutoMorph 公开,以期推动新兴的眼组学领域取得突破性进展。
2. 方法
AutoMorph 流程包含四个模块:(1)图像预处理、(2)图像质量分级、(3)解剖结构分割、(4)指标测量(图 1)。
该流程的源代码可从https://github.com/rmaphoh/AutoMorph获取。
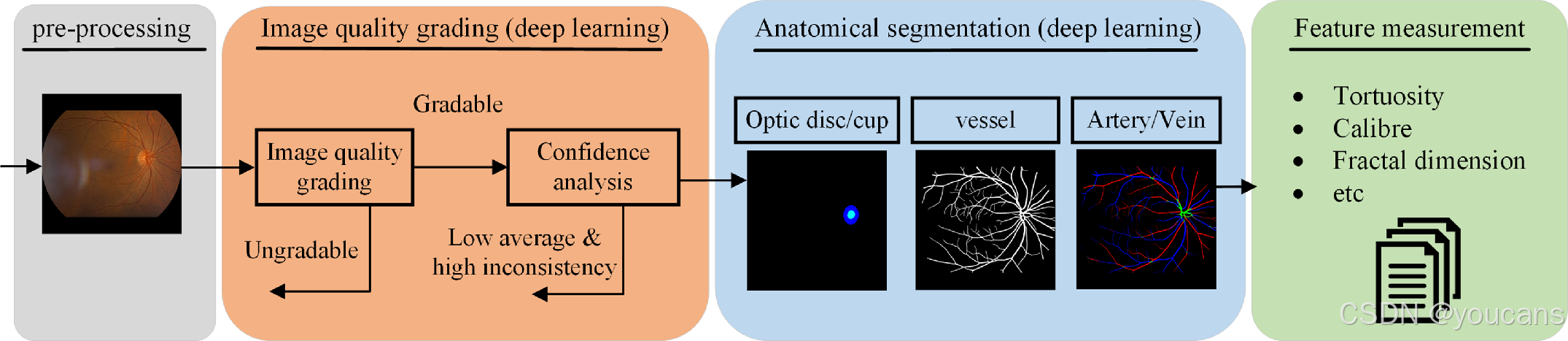
AutoMorph 流程示意图。输入为彩色眼底照相,最终输出为测得的血管形态特征。
图像质量分级与解剖结构分割模块采用深度学习模型;置信度分析在图像质量分级模块中降低被误判为可分级图像的比例。
2.1 数据集
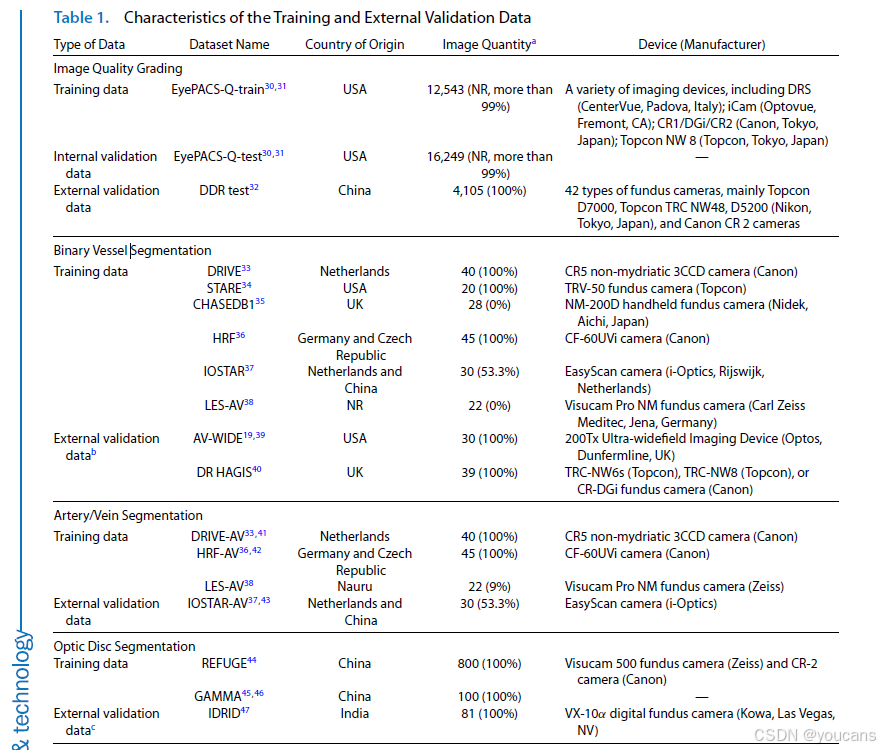
本研究中用于深度学习模型开发与外部验证的数据集汇总于表 1 及补充材料 S1。在模型训练阶段,我们选择了包含大量标注图像的公开数据集 [30]。重要的是,为提升模型的外部泛化能力,我们采用了多种公开数据集的组合。部分图像示例见图 S1(补充材料)。在模型验证阶段,我们使用与训练数据集完全独立的数据集(例如,成像设备、来源国家、病理类型不同的数据集)对训练后的模型性能进行外部评估。所有数据集均提供视网膜眼底图像及相应的专家标注。
对于图像质量分级数据集(以 EyePACS-Q 为例),两名专家根据图像亮度、伪影及专家对常见眼部疾病的可诊断性,将每张图像分为 “良好”“可用”“不合格” 三个质量等级。对于解剖结构分割数据集(如用于血管二值分割任务的数字视网膜血管提取数据集 DRIVE),两名专家会将每个像素标注为 “血管” 或 “背景”,从而生成与视网膜眼底图像尺寸一致的真值图 —— 其中白色代表血管像素,黑色代表背景像素。更多细节可参见补充材料 S1。
2.2 模块
- 图像预处理
视网膜眼底图像通常包含冗余背景,导致图像尺寸偏离几何正方形。为解决这一问题,我们采用了一种结合阈值处理、形态学图像操作与裁剪的技术 [31],去除背景并将图像调整为几何正方形(示例见图 S2,补充材料)。
- 图像质量分级
为筛选出可能导致分割与测量模块失效的不可分级图像,AutoMorph 集成了一个分类模型用于识别不可分级图像。该模型将每张图像分为 “良好”“可用”“不合格” 三个质量等级。在本研究中,“良好” 与 “可用” 图像被归为可分级图像;但在数据量充足的情况下,也可调整判定标准,仅将 “良好” 图像归为可分级图像。我们采用 EfficientNet-B4 [48] 作为模型架构,并在 EyePACS-Q 数据集上进行迁移学习。更多细节详见补充材料 S2 及图 S3(补充材料)。
- 解剖结构分割
血管结构纤细,尤其在低对比度背景下更难识别。为提升血管二值分割性能,AutoMorph 采用了对抗性分割网络 [23],并使用 6 个公开数据集进行模型训练(表 1)。
动静脉精准分割一直是一项难题。为解决这一问题,我们采用了专为动静脉分割设计的信息融合网络 [22],并使用 3 个数据集进行训练。
近视或青光眼可能导致视盘旁萎缩性改变,这种改变会给视盘定位与分割带来较大误差。为应对这一问题,AutoMorph 采用了一种从粗到细的深度学习网络 [49]—— 该网络曾在 2021 年国际医学图像计算与计算机辅助干预会议(MICCAI)GAMMA 挑战赛中获得视盘分割任务第一名 [45,46]。模型训练使用了 2 个公开数据集。更多详细信息详见补充材料 S3。
表1 训练数据与外部验证数据的特征
- 血管形态特征测量
AutoMorph 可测量一系列具有临床意义的血管特征,汇总于图 2(完整特征列表见图 S13,补充材料)。该流程提供三种血管弯曲度计算方法,包括距离测量弯曲度、平方曲率弯曲度 [50] 及弯曲度密度 [51]。分形维数(闵可夫斯基 - 布利冈德维数)[52] 用于衡量血管网络的复杂程度;血管密度指血管面积与整个图像面积的比值。
在血管管径方面,AutoMorph 会计算视网膜中央动脉等效值(CRAE)、视网膜中央静脉等效值(CRVE)以及动静脉比(AVR)[53-55]。此外,AutoMorph 还会在标准区域(包括 B 区:距视盘边缘 0.5-1 个视盘直径的环形区域;C 区:距视盘边缘 0.5-2 个视盘直径的环形区域)[29] 测量上述特征。考虑到以黄斑为中心的图像中,B 区和 C 区可能超出眼底圆形区域范围,该流程还会对全图像的血管特征进行测量。
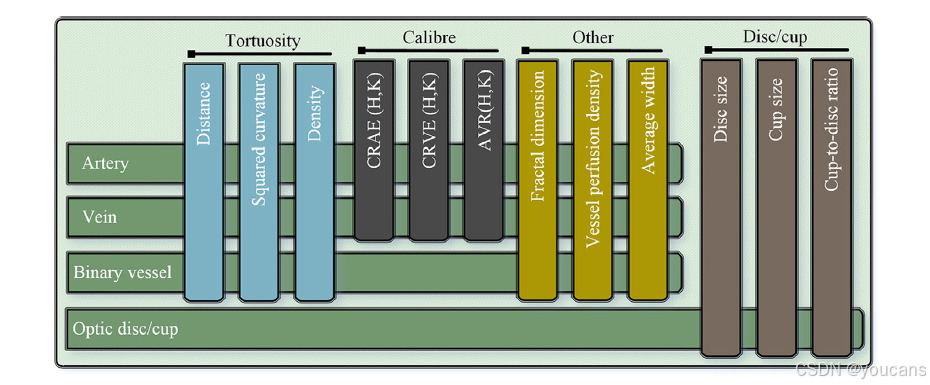
图2. AutoMorph 测量的特征,包括迂曲度、血管口径、视盘-视杯比等。对每张图像,测量视盘/视杯信息,含高度、宽度及杯盘比。对二值血管,测量迂曲度、分形维数、血管密度及平均宽度。除上述特征外,还利用动脉/静脉,通过 Hubbard 与 Knudtson 方法测量口径特征 CRAE、CRVE 与 AVR。
2.3 集成与置信度分析
在模型训练过程中,80% 的训练数据用于模型训练,20% 用于调整训练超参数(如学习率调度)。在视网膜图像分级任务中,我们对 8 个基于不同训练子集训练的模型的输出结果进行集成 —— 这种集成策略通常能获得更稳健的结果 [56]。此外,我们还计算了 8 个模型预测结果的平均值与标准差(SD),用于置信度分析。
平均概率反映预测结果的置信度:平均概率较低的图像(如示例图 3c)往往更容易出现误判。标准差则反映模型间预测结果的一致性:标准差较大(如示例图 3d)表明模型间预测差异显著,这类图像同样可能存在误判。在本研究中,平均概率较低或标准差较大的图像会被自动识别为低置信度图像,并被修正为不可分级图像。
不可分级图像若被误判为可分级图像,可能导致解剖结构分割模块失效,进而使血管特征测量产生巨大误差。通过置信度分析,我们减少了此类误差,同时降低了对医生干预的需求,提升了 AutoMorph 的可靠性。据我们所知,本研究首次将置信度分析与模型集成相结合,并应用于血管分析流程中。
平均阈值对应操作点的变化,标准差阈值则涉及不确定性理论。在本研究中,我们设置平均阈值为 0.75、标准差阈值为 0.1,用于筛选并修正误判的可分级图像。具体而言,平均概率低于 0.75 或标准差大于 0.1 的图像会被修正为不可分级图像。选择这些阈值的依据是调优数据的概率分布直方图,更多细节详见补充材料 S2 及图 S4(补充材料)。
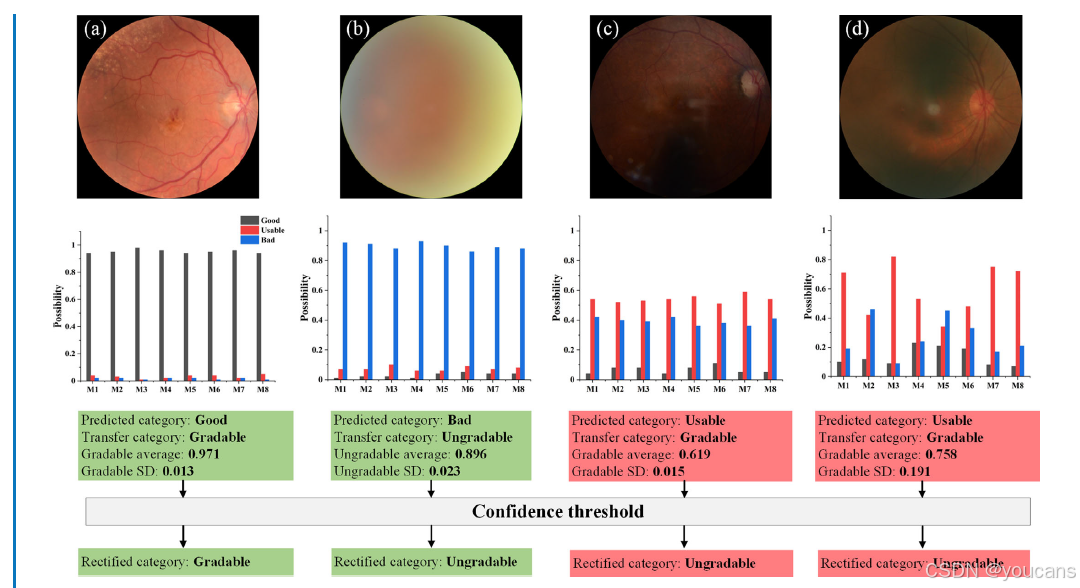
图3. 图像质量分级的置信度分析。M1–M8 表示八个集成模型。对每张图像,将预测类别映射为可分级或不可分级(good 与 usable 视为可分级,reject 视为不可分级)。计算预测类别对应的平均概率及标准差(SD)。(a、b)两个预测置信度较高的图像示例。(c)所示示例被初分为可分级,但平均概率仅 0.619;(d)所示示例标准差高达 0.191;二者在本研究中被定义为低置信度图像。尽管(c)与(d)初分结果为可分级,最终借助置信度阈值被修正为不可分级。
2.4 统计分析与对比方法
对于深度学习功能模块,我们以已验证的专家标注作为参考标准,通过定量方式评估模块性能。我们计算了灵敏度、特异性、阳性预测值(精确度)、准确率、受试者工作特征曲线下面积(AUC-ROC)、F₁分数及交并比(IoU)等指标来验证模型性能,各指标计算公式如下:
准确率(Accuracy):
Accuracy=TP+TNTP+FP+TN+FN\text{Accuracy} = \frac{TP + TN}{TP + FP + TN + FN} Accuracy=TP+FP+TN+FNTP+TN
灵敏度(Sensitivity):
Sensitivity=TPTP+FN\text{Sensitivity} = \frac{TP}{TP + FN} Sensitivity=TP+FNTP
特异性(Specificity):
Specificity=TNTN+FP\text{Specificity} = \frac{TN}{TN + FP} Specificity=TN+FPTN
精确度(Precision,阳性预测值):
Precision=TPTP+FP\text{Precision} = \frac{TP}{TP + FP} Precision=TP+FPTP
F1 分数(F1-score):
F1=2×Sensitivity×PrecisionSensitivity+PrecisionF_1 = \frac{2 \times \text{Sensitivity} \times \text{Precision}}{\text{Sensitivity} + \text{Precision}} F1=Sensitivity+Precision2×Sensitivity×Precision
其中,真阳性(TP)指实际为阳性且被模型正确预测为阳性的样本,真阴性(TN)指实际为阴性且被模型正确预测为阴性的样本,假阳性(FP)指实际为阴性但被模型错误预测为阳性的样本,假阴性(FN)指实际为阳性但被模型错误预测为阴性的样本。
AUC-ROC 曲线是评估分类模型在不同阈值下性能的指标,反映模型区分不同类别的能力。在分割任务中,IoU 用于衡量真值图与分割图的重叠程度。
参照已有研究设置 [31,39,57-59],在图像质量分级任务中,我们将不可分级图像设为阳性类别。不可分级类别的概率等同于 “不合格” 质量的概率,可分级类别的概率则为 “良好” 质量与 “可用” 质量的概率之和。如置信度分析部分所述,我们将平均值 0.75 和标准差 0.1 作为阈值,最终确定可分级与不可分级图像的类别。
在血管二值分割任务中,视网膜眼底图像的每个像素均对应一项二分类任务:血管像素为阳性类别,背景像素为阴性类别。每个像素的概率取值范围为 0-1,数值越大表示该像素为血管像素的概率越高。我们采用 0.5 作为阈值对分割图进行二值化处理 —— 这是医学图像二值分割任务中的标准阈值。
视盘分割与血管二值分割类似,不同之处在于视盘分割中阳性类别为视盘像素。在动静脉分割任务中,每个像素包含四种类别概率:动脉、静脉、不确定像素及背景。参照多类别分割任务的标准设置,我们将概率最大的类别作为该像素的最终类别。更多信息详见补充材料 S3。
为验证 AutoMorph 的泛化能力,我们在外部验证数据集上将其与其他主流方法进行了定量对比。我们以其他已发表研究的内部验证结果作为性能优良模型的基准 —— 这些方法均采用合理的数据划分比例(如 80% 数据用于训练与调优,20% 用于验证训练后的模型的五折交叉验证),并宣称达到了当前最优(SOTA)性能。
如第 1 章表 1 所示,AutoMorph 的模型基于多个公开数据集训练,并在独立数据集上进行外部验证;而对比方法 [39,57-59] 的训练数据集与验证数据集来自同一领域,且训练图像数量更少。需要说明的是,本研究的对比目的并非证明 AutoMorph 在技术上优于最新方法(这一点已在先前发表的研究中得到验证 [22,23,47,48]),而是为了证明:由于训练数据的多样性,即使外部数据集包含不同病理类型且与训练数据存在较大领域差异,AutoMorph 仍能在这些数据集上表现出优良性能。此外,为证明该方法的技术优势,我们在补充表 S1 中提供了 AutoMorph 的内部验证结果。
由于我们采用标准公式 [29,50-52] 测量血管形态特征,因此测量误差仅来源于解剖结构分割的不准确性。为评估血管分割导致的测量误差,我们分别基于 AutoMorph 的分割结果与专家的血管标注结果测量血管特征,随后绘制 Bland-Altman 图。参照已有评估方法 [3,60],我们还计算了组内相关系数(ICCs),以定量方式体现两者的一致性。此外,AutoMorph 分割结果与专家标注结果在血管特征上的差异箱线图见图 S9-S11(补充材料)。
3. 结果
AutoMorph 的外部验证结果汇总于表 2。
表2 功能模块的验证及与其他方法的比较
“Internal”表示验证与训练数据来自同一数据集但相互隔离;“External”表示验证数据来自外部数据集。比较对象为图像质量分级、31二值血管分割、39、57动脉/静脉分割58及视盘分割59的现有竞争方法。NR,未报告。
3.1 图像质量分级
内部验证在 EyePACS-Q 测试集上开展。为保证对比公平性 [31],我们评估了模型对 “良好”“可用”“不合格” 三类图像的质量分级性能,定量结果见表 2。该分类任务的 F₁分数达到 0.86,与当前最优方法的 F₁分数(0.86)持平 [31]。我们将模型预测结果进一步归为 “可分级”(良好 + 可用)和 “不可分级”(不合格)两类,EyePACS-Q 测试集验证结果的混淆矩阵见图 4。结果显示,置信度阈值处理对性能指标存在一定权衡效应:虽能降低误判可分级图像的比例,但同时会增加误判不可分级图像的数量。误判可分级图像易导致解剖结构分割模块失效,进而使血管特征测量产生较大误差及异常值;因此,尽管该阈值处理会筛除部分质量合格的图像,但有效保障了 AutoMorph 的可靠性。
外部验证在通用糖尿病视网膜病变数据集(DDR)测试集上开展。由于 DDR 数据集的图像质量标注仅分为 “可分级” 和 “不可分级” 两类,我们首先将 AutoMorph 对 “良好”“可用” 的预测结果归为 “可分级”,对 “不合格” 的预测结果归为 “不可分级”,再进行定量评估。尽管标注体系的差异可能低估 AutoMorph 的图像质量分级能力,但如表 2 所示,其在外部验证中的性能仍优于内部验证组。该验证结果的混淆矩阵及 AUC-ROC 曲线详见补充材料图 S5。值得注意的是,所有不可分级图像均被准确识别,这对保障 AutoMorph 的可靠性具有重要意义。
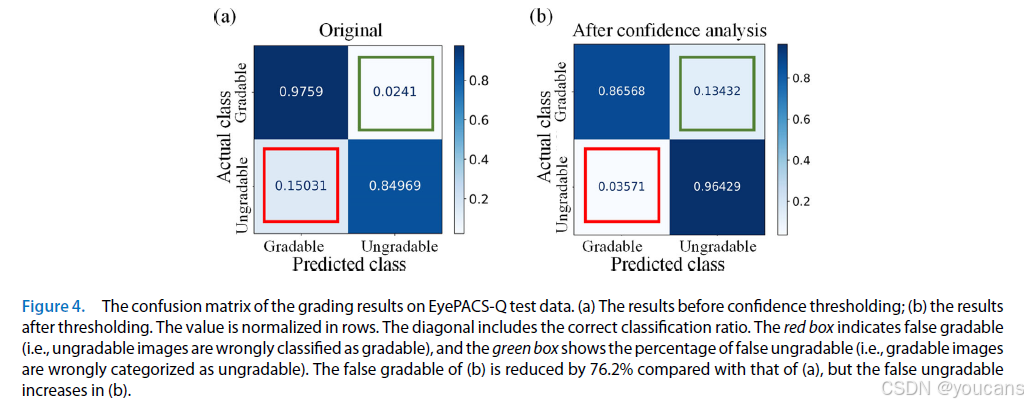
图4. 在 EyePACS-Q 测试数据上的分级结果混淆矩阵。(a)为置信度阈值处理前的结果;(b)为阈值处理后的结果。数值按行归一化,对角线表示正确分类比例。红色框表示假可分级(即不可分级图像被错误分类为可分级),绿色框显示假不可分级比例(即可分级图像被错误归类为不可分级)。与(a)相比,(b)的假可分级降低 76.2%,但(b)的假不可分级增加。
3.2 解剖结构分割
解剖结构分割的可视化结果见图 5,定量结果见表 2。在血管二值分割任务中,我们采用 AV-WIDE 和糖尿病视网膜病变、高血压、年龄相关性黄斑变性及青光眼图像集(DR HAGIS)两个公开数据集进行模型验证。结果显示,该血管二值分割模型在标准视野眼底图像(DR HAGIS)上的性能与当前最优水平相当,在超广角眼底图像(AV-WIDE)上表现中等。
在动静脉分割任务中,我们在 IOSTAR-AV 数据集上验证模型性能。与最新方法 [58] 相比,AutoMorph 的灵敏度更低,但特异性显著更高。来自 Moorfields 眼科医院和青光眼分析研究在线视网膜眼底图像数据集(ORIGA)的两个挑战性案例的分割可视化结果,详见补充材料图 S6。
在视盘分割任务中,我们在印度糖尿病视网膜病变图像数据集(IDRID)上验证模型性能。其性能与对比方法 [59] 持平,且 F₁分数略高;即便存在病理因素干扰,视盘分割结果仍展现出良好的稳健性。
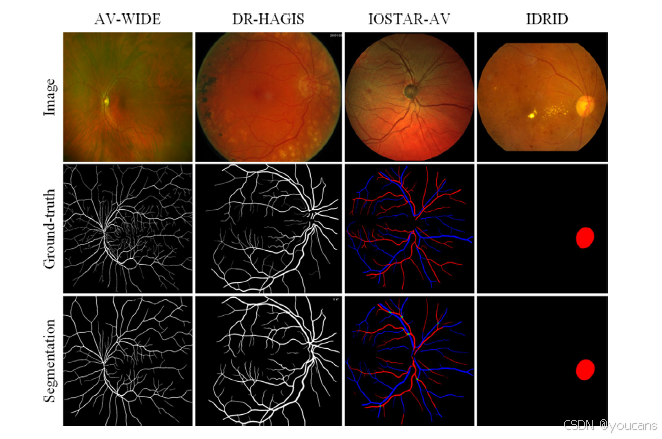
图5 解剖结构分割的可视化结果,包括二值血管(前两列)、动脉/静脉(第三列)及视盘(最后一列)。
3.3 血管特征测量
AutoMorph 测量的血管特征与专家标注特征的组内相关系数(ICCs)见表 3。在血管二值形态特征方面,分形维数、血管密度及平均宽度的可靠性均达到 “优秀” 水平(ICC>0.9),其他指标则呈现 “良好” 的一致性。B 区血管特征的 Bland-Altman 一致性分析图见图 6,所有特征均表现出良好的一致性:
- 分形维数:平均差异(MD)=-0.01,95% 一致性界限(LOA)为 - 0.05~0.03;
- 血管密度:MD=0.001,95% LOA 为 0~0.002;
- 平均宽度:MD=1.32 像素,95% LOA 为 0.44~2.19;
- 距离弯曲度:MD=0.02,95% LOA 为 - 2.18~2.22;
- 平方曲率弯曲度:MD=-1.02,95% LOA 为 - 14.59~12.56;
- 弯曲度密度:MD=0.02,95% LOA 为 - 0.09~0.13;
- 视网膜中央动脉等效值(CRAE,Hubbard 法):MD=-0.13,95% LOA 为 - 2.49~2.24;
- 视网膜中央静脉等效值(CRVE,Hubbard 法):MD=0,95% LOA 为 - 2.9~2.9;
- 动静脉比(AVR,Hubbard 法):MD=-0.03,95% LOA 为 - 0.17~0.11。
C 区及全图像的血管特征一致性分析结果,详见补充材料图 S7 和图 S8。需注意的是,由于图像分辨率信息未知,CRAE、CRVE 及平均宽度等指标的测量结果以 “像素” 为单位呈现。部分存在较大测量误差的图像示例,详见补充材料图 S12。
表3 AutoMorph 与专家标注所测血管特征的一致性计算
血管管径的一致性在 IOSTAR-AV 数据集上验证,其余指标在 DR HAGIS 数据集上验证。由于管径特征依赖 B 区与 C 区内的六条最大动静脉,故在整图层面不存在管径特征。
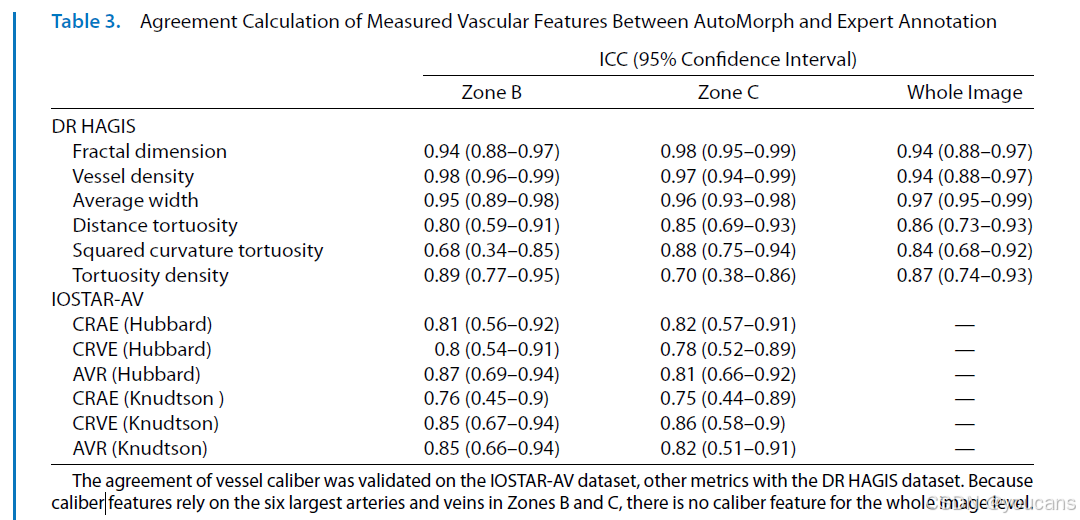
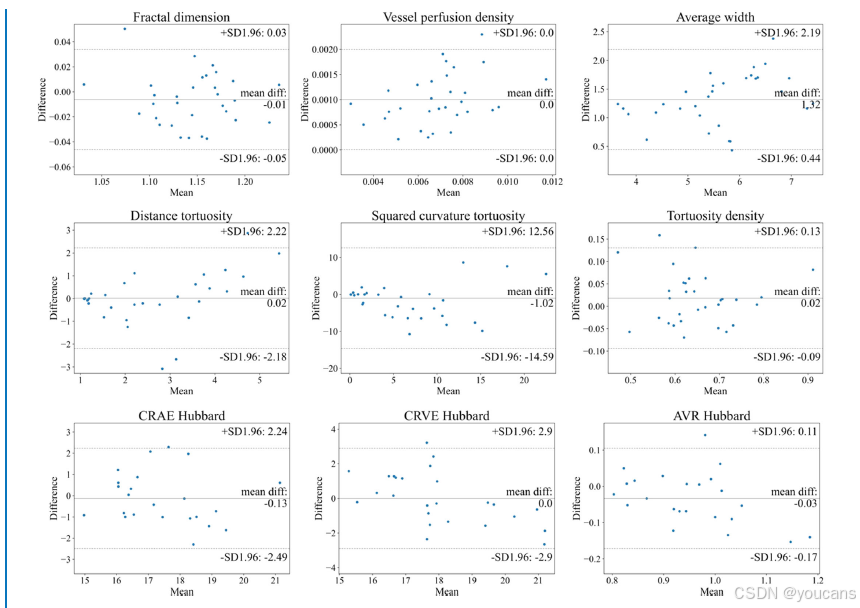
图6 专家标注与AutoMorph分割在B区血管特征一致性的Bland–Altman图。前两行特征(如弯曲度、分形维数)基于DR HAGIS的二值血管分割图计算;最后一行特征(管径)基于IOSTAR-AV的动脉/静脉分割图测量。每个子图中,中央线表示平均差值,两条虚线代表95%一致性界限。平均宽度、CRAE与CRVE的单位为像素,因分辨率未知。
3.4 运行效率和界面
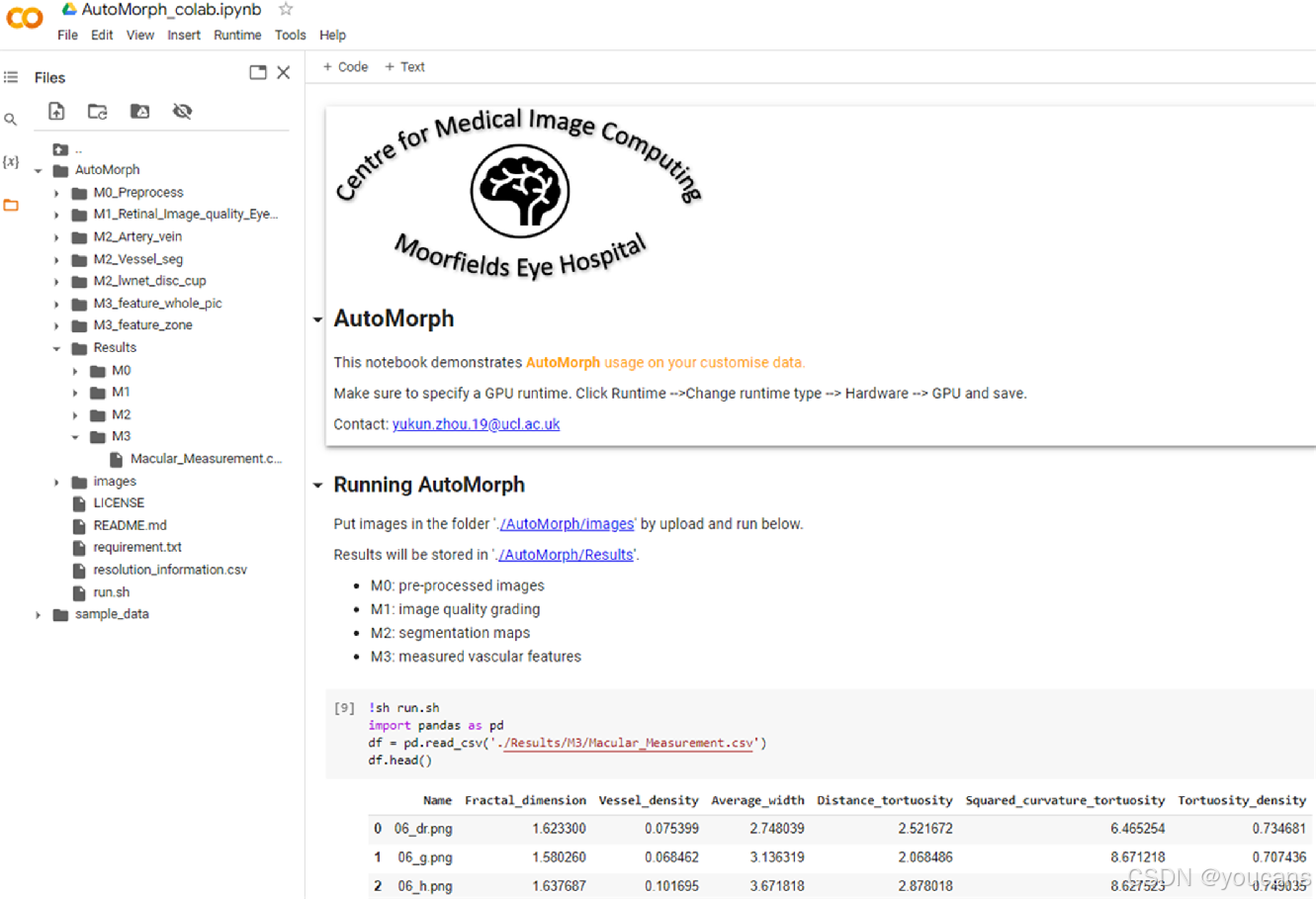
使用单个图形处理单元(GPU)Tesla T4显卡,从预处理到特征测量,每张图像的平均运行时间约为20秒。为了确保没有编码经验的研究人员也能使用,我们已使AutoMorph与Google Colaboratory(免费GPU)兼容(见图7)。该过程包括将图像放置在指定文件夹中,然后点击“运行”命令。所有结果都将被存储,包括分割图和包含所有测量特征的文件。
4. 讨论
本研究表明,AutoMorph 流程的四大功能模块在图像质量分级和解剖结构分割任务上,均实现了与当前最优水平相当或更优的性能。此外,我们提出的置信度分析方法将误判为可分级的图像数量减少了 76%,大幅提升了该流程的可靠性。由此可见,通过合理组合深度学习技术,对视网膜血管形态进行全自动精准分析是切实可行的。尽管我们已在超广角视网膜眼底数据集 AV-WIDE 上验证了血管二值分割模型的性能,但仍建议将 AutoMorph 应用于视野范围(FOV)为 25° 至 60° 的视网膜眼底图像 —— 因为所有深度学习模型的训练数据均来自该视野范围的图像,且预处理步骤也是针对这类图像专门设计的。
尽管采用了深度学习技术,AutoMorph 仍保持了计算过程的透明度。近年来,部分类似系统采用深度学习模型跳过中间步骤,直接预测形态学特征。例如,新加坡血管评估(SIVA)深度学习系统(DLS)无需进行视盘定位或动静脉分割,即可直接从视网膜眼底图像中预测血管管径 [3];另有研究采用端到端方式,直接从视网膜眼底图像中预测心血管疾病风险因素 [61]。尽管这些设计为深度学习在眼科学领域的应用提供了思路,但端到端流程牺牲了计算透明度,引发了模型可解释性方面的担忧,这可能成为其临床落地的障碍 [62,63]。具体而言,部分特征的计算依赖经验公式(例如,CRAE 和 CRVE 需基于六条最粗的动静脉计算),难以验证模型是否真正学习到了这类推导逻辑。与之相反,AutoMorph 流程保留了计算透明度:其先通过模型完成解剖结构分割,再利用传统公式计算血管特征,这一过程与人类的分析流程一致,从而提升了特征测量结果的可信度。
研究队列的筛选由图像质量分级模块完成。与以往仅采用高质量图像的研究不同,本研究尝试探索 “可用” 质量图像的有效性。尽管仅纳入高质量图像可避免解剖结构分割模型面临的潜在挑战(如光照暗淡的图像),但也会筛除 “可用” 质量的图像 —— 这类图像本可扩大研究队列规模,帮助得出更具普适性的结论。此外,在临床实践中,大量图像虽达不到 “良好” 质量标准,但仍属于 “可用” 质量。在贴近临床实际的环境中开发的流程,更易于在临床场景中推广应用。在图像质量分级任务中,如第 3 章图 3 和图 4 所示,置信度分析通过阈值处理识别出了相当比例的误判可分级图像,并将其修正为 “不合格” 质量,从而避免了部分 “不合格” 图像因导致解剖结构分割失败,进而引发特征测量出现巨大误差的问题。尽管该阈值处理增加了误判不可分级的情况(图 4b 绿色框),但保障了识别误判可分级图像这一核心优先级。当然,若高质量图像数量充足,研究人员也可像以往研究那样,仅在研究队列中纳入高质量图像。
尽管本研究证实了深度学习流程在视网膜血管形态分析中的有效性,但在技术和标准化方面仍存在一些待解决的挑战。首先,视网膜图像质量标注具有主观性,且缺乏严格的指导标准,这使得外部验证性能难以进行基准对比。其次,解剖结构分割性能仍有提升空间,尤其是动静脉分割任务。第三,如第 3 章表 3 所示,不同血管特征与专家标注的一致性存在差异,因此有必要进一步比较这些特征的稳健性,并明确各类特征的优缺点。最后,视网膜分析流程的验证亟需统一协议 —— 现有软件(如 RA28、IVAN [6]、SIVA [29]、VAMPIRE [25])在特征测量结果上差异显著 [64,65]。这四大挑战在眼组学领域普遍存在,制约了该领域研究的进一步拓展。
为助力眼组学领域的研究(该领域聚焦眼部生物标志物与系统性疾病的关联),我们已将 AutoMorph 公开。同时,我们基于 Google Colaboratory 设计了 AutoMorph 的操作界面,以方便无编码经验的临床医生使用。在未来的研究中,我们将针对眼组学领域的上述挑战探索解决方案,并尝试将该全自动流程的应用范围扩展到其他成像模态,如光学相干断层扫描(OCT)和光学相干断层扫描血管造影(OCTA)。
5. 附录
S1. 数据集
数据集和真实标注
所有用于模型训练和外部验证的数据集均为公开可用。每个数据集包含一定数量的眼底照片及其对应的真实标注。我们总结了每个数据集的特征以及真实标注的信息。
图像质量分级数据集包括EyePACS-Q和DDR-test。EyePACS-Q基于EyePACS,其中包含在糖尿病视网膜病变筛查过程中由不同成像设备收集的大量图像。在构建EyePACS-Q时,两位专家被要求将图像质量分为三个类别:良好、可用和拒绝。良好质量的图像没有低质量因素,例如不均匀照明和模糊,所有视网膜病变特征都清晰可见。可用质量的图像存在一些轻微的低质量因素,但视盘、黄斑区和病变足够清晰,可供眼科医生识别。拒绝质量的图像存在严重质量问题,即使由眼科医生也无法用于提供完整且可靠的诊断。对于DDR-test数据集,图像质量分级有两个类别:可分级和不可分级。模糊区域超过70%且没有清晰可见的糖尿病视网膜病变病变的图像被认为是不可分级的。七名专业分级员由眼科医生培训。这七名分级员对相关图像进行投票评估,最终分类由多数投票决定。如果七名分级员无法确定分类结果,他们将咨询更有经验的专家。EyePACS-Q和DDR数据集确实基于专家对图像可分级性/可诊断性的评估建立了真实标注。这有助于识别具有严重伪影、不均匀照明和低对比度的眼底照片,这些也是深度学习分割方法(解剖分割模块)的挑战性案例。在这种情况下,通过筛选不可分级的图像,我们可以获得更准确的分割图以及更精确的血管特征估计。
对于二进制血管分割,真实标注图与眼底照片的大小相同。血管像素为白色,背景像素为黑色。DRIVE数据集包含40张眼底照片,其中包括7张糖尿病视网膜病变病变的图像。这些图像由眼科专家标注。对于STARE数据集,其中10张图像来自无病理的患者,10张图像包含病理,这些病理在图像的不同部分掩盖或混淆了血管的外观。CHASEDB1是从伦敦、伯明翰和莱斯特的200所小学的多民族学童中获取的,作为心血管健康调查的一部分,并由两名专家标注。HRF数据集的真实标注由从事视网膜图像分析领域的专家团队和合作眼科诊所的临床医生生成。IOSTAR数据集由从事视网膜图像分析领域的专家团队标注。LES-AV包含22张眼底照片,提供了视网膜血管的手动分割及其专家分类为动脉和静脉。外部验证数据包括DR-HAGIS和AV-WIDE。DR-HAGIS有39张眼底图像,分为四个亚组:青光眼、高血压、糖尿病视网膜病变和年龄相关性黄斑变性。手动分割由专家分级员提供。AV-WIDE由专家眼科医生提供基于图的注释,AV-WIDE是一个宽视场眼底数据集。
动脉/静脉真实标注图由四种颜色表示:红色代表动脉,蓝色代表静脉,绿色代表不确定像素(在动脉和静脉交叉处无法识别的血管),黑色代表背景。我们使用三个训练数据集,DRIVE-AV、LES-AV和HRF-AV,以及一个外部验证数据集IOSTAR-AV。DRIVE-AV数据集由专家补充了DRIVE数据集的动脉/静脉真实标注。HRF-AV的初始标注由视网膜图像分析专家完成,然后由眼科医生仔细校正。IOSTAR-AV由从事视网膜图像分析领域的专家团队标注。
视盘分割是一项二进制分割任务,将每个像素分类为视盘像素或背景。真实标注包括白色像素的视盘和黑色背景。对于REFUGE数据集,视盘的真实标注由中山眼科中心(中国中山大学)的七名独立青光眼专家提供。所有眼科医生独立审查后,通过七名专家注释的多数投票获得每张图像的单一分割。随后,一位拥有超过10年青光眼经验的高级专家进行了质量检查,分析了结果掩模以考虑潜在错误。对于GAMMA数据集,四名临床眼科医生手动标注了每张眼底图像的视盘初始分割区域。然后,高级眼科医生融合了四个初始分割结果,并选择了几位眼科医生标注结果的交集作为最终真实标注。对于外部验证数据集IDRID,所有观察者都由眼科专家培训以识别单独的病变和视盘。后来,每张图像上的标记由两名视网膜专家审查,并在达成必要共识后最终确定。
图S1展示了一些示例,以展示不同成像设备和研究带来的视觉差异。
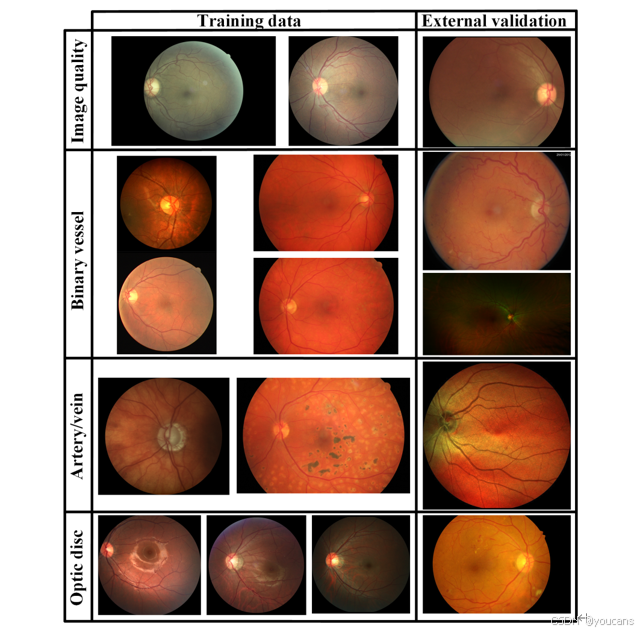
图 S1. 图像质量分级、二值血管分割、动脉/静脉分割及视盘分割任务所用训练数据与外部验证数据的图像示例。
S2. 图像质量分级模块
- 图像预处理
图像被处理成正方形,如图S2所示。
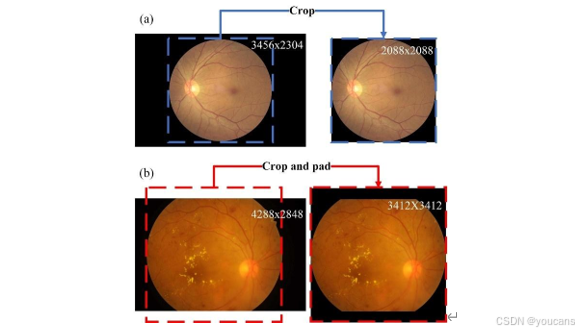
图 S2. 视网膜眼底图像预处理的两个示例。冗余背景通过裁剪在 (a) 与 (b) 中被移除,同时在 (b) 中加入部分填充使图像符合几何形状。图像尺寸列于右上角。
- 模型结构选择
我们比较了不同分类骨干网络的分类性能,分别为ResNeXt101-32x8d、EfficientNet-B4和EfficientNet-B5。这些模型在ImageNet数据集上进行了预训练,最终分类器的神经元从1000个替换为3个,分别对应良好、可用和拒绝图像质量的类别。训练周期为30次,批量大小为8。初始学习率为0.0002,优化器为Adam。我们采用了学习率调度和早停机制以避免模型过拟合。使用了交叉熵损失函数,并存储了损失最低的检查点以进行推理。我们使用了四块Tesla T4 GPU来训练模型。如图S3所示,三种骨干网络的性能没有统计学差异(p>0.05)。在这种情况下,我们选择了EfficientNet-B4作为骨干网络,因为它相比EfficientNet-B5和ResNeXt101-32x8d具有更少的参数。
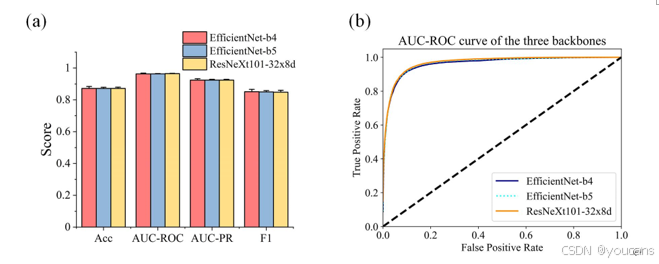
图 S3. 不同主干的图像质量分级模型性能比较。(a) 验证三种主干之间无显著差异;(b) 显示 AUC-ROC 曲线高度重叠。对每种主干,在 EyePACS-Q 训练数据的不同子集上训练八个模型,并在 EyePACS-Q 验证数据上验证。Acc,准确度;AUC-ROC,受试者工作特征曲线下面积;AUC-PR,精确率-召回率曲线下面积;F1,F1 分数。
- 置信度分析阈值
我们在置信度分析中计算集成概率的均值和标准差(SD)。如图S4所示,通过比较调优数据(训练数据的20%,用于在训练过程中调整训练超参数)中真实可分级和错误可分级的分布,我们发现假阳性(FP)案例具有较低的均值和较高的标准差。我们通过检查平均概率直方图和标准差直方图来选择阈值。我们选择了能够实现理想权衡的阈值,即在引入可接受数量的假不可分级案例的同时,大幅减少假可分级案例。我们采用了平均值阈值0.75和标准差阈值0.1。
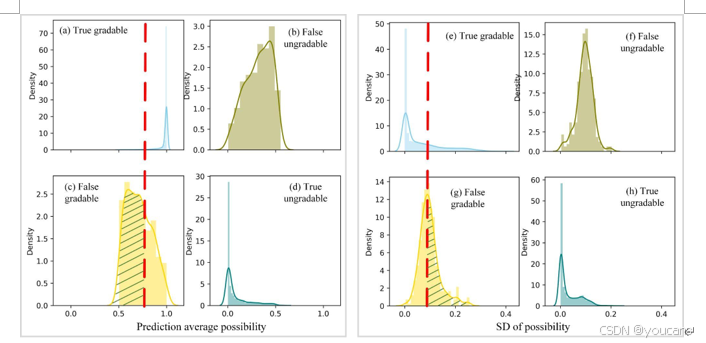
图 S4. (a–d) 分别展示平均概率直方图,依次表示真可分级、假不可分级、假可分级与真不可分级;(e–h) 为对应的 SD 直方图。对比真可分级与假可分级可见,真可分级平均概率 (a) 集中于 1,其 SD (e) 更接近 0。以平均概率 0.75 与 SD 阈值 0.1(红色虚线)进行阈值化,可将大量假可分级图像修正为不可分级并予以滤除,如绿色斜线区域所示。
- DDR上的混淆矩阵
DDR上的混淆矩阵和AUC-ROC曲线如图S5所示。
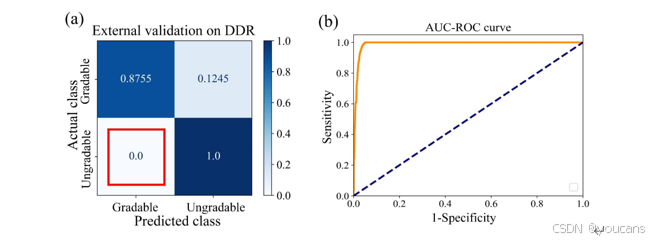
图 S5. (a) 混淆矩阵与 (b) AUC-ROC 曲线展示 AutoMorph 在外部 DDR 测试集上的性能。FP-gradable 比例为 0,表明所有不可分级图像均被正确识别,后续解剖分割步骤不再存在假可分级图像;AUC-ROC 曲线显示 AutoMorph 在 DDR 测试数据上表现良好。
S3. 解剖分割模块
-
二进制血管分割:
SEGAN是U-Net的一个变体,其在多尺度信息学习方面具有增强的性能。它由一个分割器和一个判别器组成,采用对抗学习策略进行训练。网络的输入是眼底照片,输出是与输入大小相同的分割图。预处理后的图像被调整为(912, 912)以减轻计算负担。分割图将被调整回原始大小以进行特征测量。分割图的每个像素显示为血管的概率。经过0.5的阈值处理后,值为1的像素为血管。训练周期为600次,批量大小为2。初始学习率为0.0002,优化器为Adam。采用学习率调度以实现稳健收敛。使用了三种损失函数,分别为对抗损失、均方误差和交叉熵损失。存储了F1分数最高的检查点。我们使用一块Tesla T4 GPU来训练模型。 -
动脉/静脉分割:
BFN将多分类任务分解为多个二进制任务,随后进行二进制到多分类信息融合,以纠正交叉点周围的信息。不同的分割器共享同一个判别器。网络的输入是眼底照片,输出是与输入大小相同的多分类分割图。预处理后的图像被调整为(720, 720)以减轻计算负担。多分类分割图将被调整回原始大小以进行特征测量。分割图的每个像素显示为动脉、静脉、不确定像素和背景的四元素概率。在选择最大概率作为最终类别后,值为0的像素为背景,1为动脉,2为静脉,3为不确定像素。红色、蓝色、绿色和黑色是转换后的可视化颜色。训练周期为1500次,批量大小为2。初始学习率为0.0008,优化器为Adam。采用学习率调度。使用了三种损失函数,分别为对抗损失、均方误差和交叉熵损失。存储了F1分数最高的检查点。使用一块Tesla T4 GPU来训练模型。 -
视盘分割:
LW-Net由两个简化的U-Net组成,其中第一部分生成粗略的分割结果,第二部分完善分割细节。这两部分之间的协作正则化在存在病理时增强了模型的分割性能。整体模型在参数数量上是轻量级的。网络的输入是眼底照片,输出是与输入大小相同的分割图。预处理后的图像被调整为(512, 512)以实现较大的批量大小。分割图将被调整回原始大小以进行特征测量和预定义区域的定义。分割图的每个像素显示为视盘的概率。经过0.5的阈值处理后,值为1的像素为视盘。训练周期为1000次,批量大小为16。初始学习率为0.01,优化器为Adam。采用学习率调度。使用交叉熵损失,并存储了AUC-ROC最高的检查点。使用一块Tesla T4 GPU来训练模型。
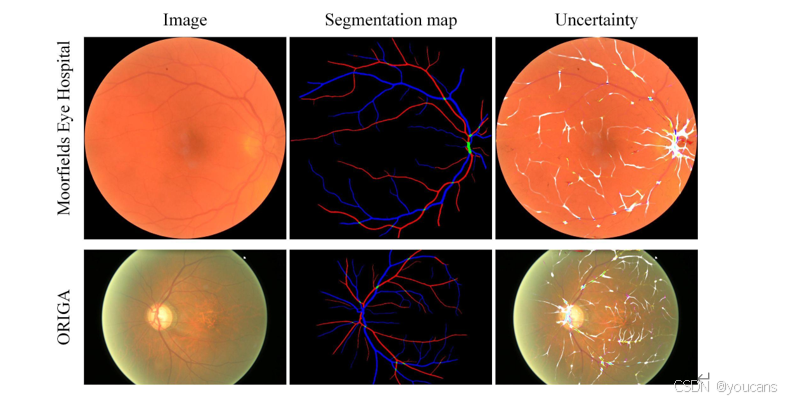
图 S6. 来自 Moorfields Eye Hospital 与 ORIGA 数据集的具有挑战性病例(模糊与光照不足)的动/静脉分割可视化示例。不确定性图叠加于眼底图像上,越亮的白色表示不确定性越高。
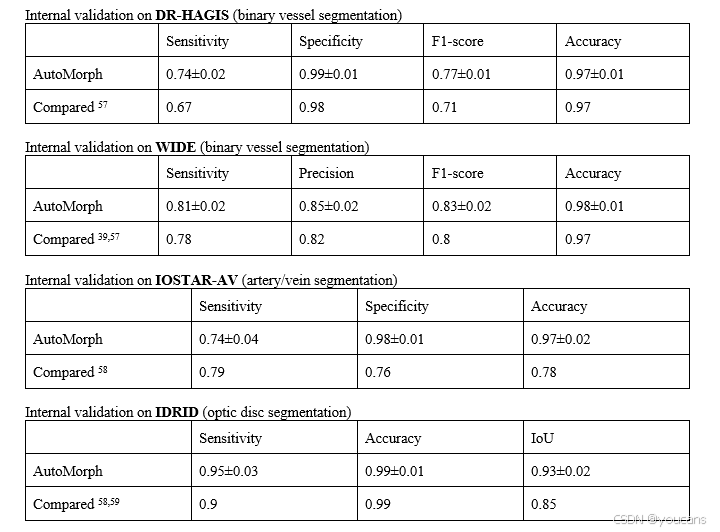
为了直接比较我们的分割方法与其他比较方法之间的技术性能,我们在表S1中列出了技术上公平的比较。所有模型都在相同的数据集上进行训练,并进行了内部验证。由于我们没有比较方法39,57–59的多组结果,因此无法测试是否存在统计学上的显著差异。但我们的结果显示出了明显更好的性能。我们比较了他们提供的所有指标。我们遵循了比较方法的训练和测试数据的相同划分。
S4. C区和全图像中的血管特征
在B区和全图像中部分血管形态特征的Bland-Altman图。
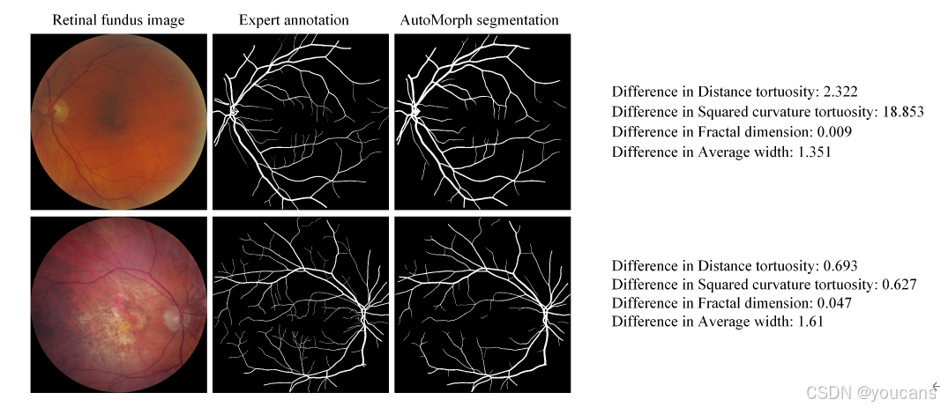
图S12. 大血管特征误差的示例。通过比较这两个案例,我们可以理解不同的血管特征对特定类型的分割误差具有敏感性,这取决于计算过程。当血管出现额外的连接点或遗漏连接点时,距离曲折度和平方曲率曲折度通常会显示出较大的误差,而当整体血管形态与专家注释存在显著差异(例如,遗漏了一些远端血管)时,分形维数会显示出误差。
S5. 测量特征的详细列表
所有测量的特征均列于图S13中。

图S13. 一份全面的测量血管特征列表。
6. Github 项目介绍
项目地址: [](Project website: https://rmaphoh.github.io/projects/automorph.html)
**github
6.1 AutoMorph 项目介绍
更新:
2025-05-16更新:Docker及其说明已更新。
2024-06-27更新:支持PyTorch 2.3和Python 3.11;支持Mac M2 GPU;支持CPU(感谢staskh)。
2023-08-24更新:增加了对视盘中心图像的特征测量;移除了一些未使用的文件。
像素分辨率
血管平均宽度、视盘/杯高度和宽度以及口径测量的单位定义为微米。为此,我们需要组织一个包含像素分辨率信息的resolution_information.csv文件,这些信息可以在FDA或Dicom文件中查询。或者,可以使用近似值,例如Topcon 3D-OCT的0.008。
如果你不使用这些特征或不关心它们的单位,你可以将所有图像放在./images文件夹中并运行
python generate_resolution.py
-
是什么促使了AutoMorph的开发?
由于眼部组织的透明性,眼睛后部(视网膜)是人体内唯一可以轻松研究活体血管(称为“血管”)和神经的地方,而无需进行侵入性或可能有害的操作。一种简单的技术,称为“眼底摄影”,可以在瞬间捕捉到视网膜的血管。
眼底照片是常规眼部护理的一部分,通常在眼镜店和医院眼科诊所定期拍摄,用于检查多种常见眼部疾病,如糖尿病视网膜病变、年龄相关性黄斑变性(AMD)、黄斑水肿和视网膜脱离。然而,与光学相干断层扫描(OCT)等其他类型的高分辨率图像一样,眼底照片也可以为我们提供有关整体健康的线索,包括影响全身的疾病——所谓的“系统性疾病”。这包括高血压、高胆固醇、糖尿病、中风、心脏病发作和痴呆症等常见疾病。
解读这些照片——一个被称为“分级”的过程——通常需要经过高度训练的专业人员,并且非常耗时。Yukun着手创建一个能够自动执行这一过程的计算机模型,而且时间只需其中的一小部分。分析一张图像大约需要20秒。 -
这些测量结果能告诉我们什么?
利用眼睛对一个人的整体健康进行更广泛评估的科学至少可以追溯到一千年前,当时它首次被记录在阿拉伯文献中。*近年来,由于成像技术和计算技术的进步,这一领域取得了巨大的飞跃。研究人员越来越多地使用一种名为“机器学习”的过程,计算机能够非常快速地分析大量图像,比较眼睛后部的微小生物学变化,并将其与某人的整体健康记录联系起来。因此,研究人员开始发现一些可能根本无法被人类察觉的东西。对个体患者而言,医生将能够通过简单的扫描或照片来预测和监测许多严重的健康状况。
这一迅速发展的医学领域被称为“视网膜组学”——这个词结合了“oculus”(拉丁语中“眼睛”的意思)和后缀“-omics”(指的是利用大规模数据来理解一些重大的事物)。简而言之,视网膜组学是将来自众多人的眼睛和健康数据与机器学习相结合的科学,以便更好地理解身体的整体健康状况。 -
AutoMorph究竟做了什么?
AutoMorph会自动分析这些照片,并生成一系列关于眼底血管的测量数据。
手工分级的图像结果容易受到人类分级者之间差异的影响,而AutoMorph则能够提供一致且可靠的结果。 -
AutoMorph能否作为诊所中的诊断工具使用?
像AutoMorph这样的人工智能系统目前尚未在英国的眼科诊所中使用,尽管在美国等地,其他人工智能系统已经获得了监管批准。目前,AutoMorph的目标是帮助那些希望利用机器学习的力量来理解眼睛血管与身体其他部分关系的研究人员。然而,经过足够的改进和测试后,基于AutoMorph的系统最终可能会被纳入常规眼部护理中,帮助临床医生更快、更准确地解读眼底照片。
6.2 AutoMorph 快速入门
6.2.1 使用Colab运行
使用Google Colab和免费的Tesla T4 GPU,点击Colab链接。
APTOSxJSAIO 2025实践教程的特定版本
6.2.2 在本地/虚拟机上运行
在自己的机器上安装并使用 LOCAL.md。
需求:
(1)建议使用 Linux 或 Mac 系统。对于 Windows 系统,需要安装 MinGW-w64。
(2)必须安装 Anaconda 或 Miniconda。
(3)Python=3.11,torch=2.3 等(安装步骤如下)。
(4)必须有 GPU - NVIDIA(cuda)或 M2(mps)。
包安装:
- 创建虚拟环境:
conda update conda
conda create -n automorph python=3.11 -y
- 激活虚拟环境并克隆代码。
conda activate automorph
git clone https://github.com/rmaphoh/AutoMorph.git
cd AutoMorph
- 安装 PyTorch 2.3.1,使用 nvcc --version 检查 CUDA 版本。以 CUDA cuda_12.1 为例,运行以下安装命令:
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia -y
- 安装其他包:
pip install --ignore-installed certifi
pip install -r requirement.txt
pip install efficientnet_pytorch==0.7.1 --no-deps
运行
将图像放入 ‘images’ 文件夹,并运行以下命令:
sh run.sh
请注意,resolution_information.csv 包含图像的分辨率信息,即每个像素的大小。请为自定义数据准备相同格式的文件。
6.2.3 使用 Docker 运行
对Docker没有经验?不用担心,参考DOCKER.md。
运行 Docker
首先,创建一个名为 images 的文件夹,并将所有图像放入其中。为所有图像准备分辨率的 CSV 文件,示例可在 resolution_information.csv 中查看。
├──images├──1.jpg├──2.jpg├──3.jpg
├──resolution_information.csv
然后,拉取 Docker 镜像并运行工具。
docker pull yukunzhou/image_automorph:latest
请将 {images_path} 替换为图像文件夹的路径,例如 /home/AutoMorph/images。并将 {results_path} 替换为您希望保存结果的路径,例如 /home/AutoMorph/Results。
docker run --rm --shm-size=2g -v {images_path}:/app/AutoMorph/images -v {results_path}:/app/AutoMorph/Results -ti --runtime=nvidia -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all yukunzhou/image_automorph
6.3 常见问题
-
内存/ram错误
我们使用Tesla T4(16Gb)和32vCPUs(120Gb)。如果你在运行时遇到内存/ram问题,尝试减小批量大小:
./M1_Retinal_Image_quality_EyePACS/test_outside.sh -b=64改为更小的值,例如32或16。
./M2_Artery_vein/test_outside.sh --batch-size=8改为更小的值
./M2_lwnet_disc_cup/test_outside.sh --batchsize=8改为更小的值 -
无效结果
在csv文件中,无效值(例如视盘分割失败)用NAN值表示。 -
组件
-
血管分割 BF-Net:Learning-AVSegmentation
本仓库旨在通过减轻交叉点附近的段内误分类,提升视网膜眼底照片的多类别血管分割性能;实验所用研究数据集包括 DRIVE-AV 1,2、LES-AV 3 及 HRF-AV 4,5。 -
图像预处理 EyeQ:Eye-Quality (EyeQ) Assessment Dataset
MICCAI 2019 项目网页:“Evaluation of Retinal Image Quality Assessment Networks in Different Color-spaces”。
眼底增强:我们另有一项相关工作“Modeling and Enhancing Low-quality Retinal Fundus Images”,发表于 IEEE TMI,2021。代码已在 GitHub 发布:Cofe-Net。 -
视盘分割 lwnet:
基于极简模型的视网膜血管分割工作的官方仓库。上图所示为 WNet 架构,其参数量约 70k,性能与(或优于)其他更复杂的方法相当。有关本工作的更多细节,请查阅相关论文:The Little W-Net That Could: State-of-the-Art Retinal Vessel Segmentation with Minimalistic Models Adrian Galdran, André Anjos, Jose Dolz, Hadi Chakor, Hervé Lombaert, Ismail Ben Ayed https://arxiv.org/abs/2009.01907, Sep. 2020
7. 参考文献
1. Wagner SK, Fu DJ, Faes L, et al. Insights into systemicdisease through retinal imaging-based oculomics. Transl Vis Sci Technol. 2020;9:6.
2. Rizzoni D, Muiesan ML. Retinal vascular caliberand the development of hypertension: a metaanalysisof individual participant data. J Hypertens. 2014;32:225–227.
3. Cheung CY, Xu D, Cheng C-Y, et al. A deeplearningsystem for the assessment of cardiovasculardisease risk via the measurement ofretinal-vessel calibre. Nat Biomed Eng. 2021;5:498–508.
4. Wong TY,Mitchell P.Hypertensive retinopathy.NEngl J Med. 2004;351:2310–2317.
5. Cheung N, Bluemke DA, Klein R, et al. Retinalarteriolar narrowing and left ventricular remodeling:the multi-ethnic study of atherosclerosis. J AmColl Cardiol. 2007;50:48–55.
6. Wong TY, Islam FMA, Klein R, et al. Retinalvascular caliber, cardiovascular risk factors,and inflammation: the Multi-Ethnic Study ofAtherosclerosis (MESA). Invest Ophthalmol VisSci. 2006;47:2341.
7. Wong TY, Klein R, Sharrett AR, et al. Retinalarteriolar diameter and risk for hypertension. AnnIntern Med. 2004;140:248–255.
8. Wong TY, Shankar A, Klein R, Klein BEK,Hubbard LD. Prospective cohort study of retinalvessel diameters and risk of hypertension. BMJ. 2004;329:79.
9. Jaulim A, Ahmed B, Khanam T, ChatziralliIP. Branch retinal vein occlusion: epidemiology,pathogenesis, risk factors, clinical features, diagnosis,and complications. An update of the literature. Retina. 2013;33:901–910.
10. Yau JWY, Lee P, Wong TY, Best J, Jenkins A. Retinal vein occlusion: an approach to diagnosis,systemic risk factors and management. Intern MedJ. 2008;38:904–910.
11. Wong TY. Retinal vessel diameter as a clinical predictorof diabetic retinopathy progression: timeto take out the measuring tape. Arch Ophthalmol. 2011;129:95–96.
12. Owen CG, Rudnicka AR, Nightingale CM, et al. Retinal arteriolar tortuosity and cardiovascularrisk factors in a multi-ethnic population study of10-year-old children; the Child Heart and HealthStudy in England (CHASE). Arterioscler ThrombVasc Biol. 2011;31:1933–1938.
13. Cheung CY-L, Zheng Y, HsuW, et al. Retinal vasculartortuosity, blood pressure, and cardiovascularrisk factors. Ophthalmology. 2011;118:812–818.
14. Owen CG, Rudnicka AR, Mullen R, et al. Measuringretinal vessel tortuosity in 10-year-old children:validation of the Computer-Assisted ImageAnalysis of the Retina (CAIAR) program. InvestOphthalmol Vis Sci. 2009;50:2004–2010.
15. Couper DJ, Klein R, Hubbard LD, et al. Reliabilityof retinal photography in the assessment of retinalmicrovascular characteristics: the AtherosclerosisRisk in Communities Study. Am J Ophthalmol. 2002;133:78–88.
16. Huang F, Dashtbozorg B, ter Haar RomenyBM. Artery/vein classification using reflection featuresin retina fundus images. Mach Vis Appl. 2018;29:23–34.
17. Mirsharif Q, Tajeripour F, Pourreza H. Automatedcharacterization of blood vessels as arteriesand veins in retinal images. Comput Med ImagingGraph. 2013;37:607–617.
18. Dashtbozorg B, Mendonça AM, Campilho A. Anautomatic graph-based approach for artery/veinclassification in retinal images. IEEE Trans ImageProcess. 2014;23:1073–1083.
19. EstradaR,Allingham MJ,Mettu PS, Cousins SW,Tomasi C, Farsiu S. Retinal artery-vein classificationvia topology estimation. IEEE Trans MedImaging. 2015;34:2518–2534.
20. Srinidhi CL, Aparna P, Rajan J. Automatedmethod for retinal artery/vein separation via graphsearch metaheuristic approach [published onlineahead of print January 1, 2019]. IEEE TransImage Process, https://doi.org/10.1109/TIP.2018. 2889534.
21. Ronneberger O, Fischer P, Brox T. U-Net: convolutionalnetworks for biomedical image segmentation. In: Navab N, Hornegger J, WellsWM, Frangi A, eds. Medical Image Computingand Computer-Assisted Intervention–MICCAI2015. Berlin: Springer International Publishing;2015:234–241.
22. Zhou Y, Xu M, Hu Y, et al. Learning toaddress intra-segment misclassification in retinalimaging. In: de Bruijne M, Cattin PC, Cotin S,et al., eds. Medical Image Computing and ComputerAssisted Intervention–MICCAI 2021. Berlin:Springer International Publishing; 2021:482–492.
23. Zhou Y, Chen Z, Shen H, Zheng X, Zhao R,Duan X. A refined equilibrium generative adversarialnetwork for retinal vessel segmentation. Neurocomputing. 2021;437:118–130.
24. Fraz MM,Welikala RA,Rudnicka AR, Owen CG,Strachan DP, Barman SA. QUARTZ: quantitativeanalysis of retinal vessel topology and size – anautomated system for quantification of retinal vesselsmorphology. Expert Syst Appl. 2015;42:7221–7234.
25. Perez-Rovira A, MacGillivray T, Trucco E, et al. VAMPIRE: vessel assessment and measurementplatform for images of the retina. In: Annual InternationalConference of the IEEE Engineering inMedicine and Biology Society (EMBC). Piscataway,NJ: Institute of Electrical and ElectronicsEngineers; 2011:3391–3394.
26. Futoma J, Simons M, Panch T, Doshi-Velez F,Celi LA. The myth of generalisability in clinicalresearch and machine learning in health care. Lancet Digit Health. 2020;2:e489–e492.
27. Mårtensson G, Ferreira D, Granberg T, et al. Thereliability of a deep learning model in clinical outof-distribution MRI data: a multicohort study. Med Image Anal. 2020;66:101714.
28. Wong TY, Shankar A, Klein R, Klein BEK. Retinalvessel diameters and the incidence of gross proteinuriaand renal insufficiency in people with type1 diabetes. Diabetes. 2004;53:179–184.
29. Cheung CY, Tay WT, Mitchell P, et al. Quantitativeand qualitative retinal microvascularcharacteristics and blood pressure. J Hypertens. 2011;29:1380–1391.
30. Khan SM, Liu X, Nath S, et al. A global reviewof publicly available datasets for ophthalmologicalimaging: barriers to access, usability, and generalisability. Lancet Digit Health. 2021;3:e51–e66.
31. Fu H, Wang B, Shen J, et al. Evaluation of retinalimage quality assessment networks in differentcolor-spaces. In: International Conference on MedicalImage Computing and Computer-Assisted Intervention. Cham: Springer; 2019:48–56.
32. Li T, Gao Y, Wang K, Guo S, Liu H, KangH. Diagnostic assessment of deep learning algorithmsfor diabetic retinopathy screening. InformSci. 2019;501:511–522.
33. Staal J, Abramoff MD, Niemeijer M, ViergeverMA, van Ginneken B. Ridge-based vessel segmentationin color images of the retina. IEEE TransMed Imaging. 2004;23:501–509.
34. Hoover A, Kouznetsova V, Goldbaum M. Locating blood vessels in retinal images bypiecewise threshold probing of a matched filterresponse. IEEE Trans Med Imaging. 2000;19:203–210.
35. Fraz MM, Remagnino P, Hoppe A, et al. Anensemble classification-based approach applied toretinal blood vessel segmentation. IEEE TransBiomed Eng. 2012;59:2538–2548.
36. Budai A, Bock R, Maier A, Hornegger J, MichelsonG. Robust vessel segmentation in fundusimages. Int J Biomed Imaging. 2013;2013:154860.
37. Zhang J, Dashtbozorg B, Bekkers E, Pluim JPW,Duits R, Ter Haar Romeny BM. Robust retinalvessel segmentation via locally adaptive derivativeframes in orientation scores. IEEE Trans MedImaging. 2016;35:2631–2644.
38. Orlando JI, Breda JB, van Keer K, BlaschkoMB, Blanco PJ, Bulant CA. Towards a glaucomarisk index based on simulated hemodynamicsfrom fundus images. In: Medical Image Computingand Computer Assisted Intervention–MICCAI2018. Berlin: Springer International Publishing;2018:65–73.
39. Khanal A, Estrada R. Dynamic deep networksfor retinal vessel segmentation. Front Comput Sci. 2020;2:35.
40. Holm S, Russell G, Nourrit V, McLoughlin N. DR HAGIS-a fundus image database for the automaticextraction of retinal surface vessels fromdiabetic patients. J Med Imaging (Bellingham). 2017;4:014503.
41. Hu Q, Abràmoff MD, Garvin MK. Automatedseparation of binary overlapping trees in lowcontrastcolor retinal images. Med Image ComputComput Assist Interv. 2013;16:436–443.
42. Hemelings R, Elen B, Stalmans I, Van Keer K,De Boever P, Blaschko MB. Artery-vein segmentationin fundus images using a fully convolutionalnetwork. Comput Med Imaging Graph. 2019;76:101636.
43. Abbasi-Sureshjani S, Smit-Ockeloen I, Zhang J,Ter Haar Romeny B. Biologically-inspired supervisedvasculature segmentation in SLO retinal fundusimages. In: KamelM, Campilho A, eds. InternationalConference Image Analysis and Recognition. Berlin: Springer; 2015:325–334.
44. Orlando JI, Fu H, Breda JB, et al. REFUGEChallenge: a unified framework for evaluatingautomated methods for glaucoma assessmentfrom fundus photographs. Med Image Anal. 2020;59:101570.
45. OMIA. OMIA8: 8thMICCAIWorkshop on OphthalmicMedical Image Analysis. Available at:https://sites.google.com/view/omia8. Accessed July1, 2022.
46. Wu J, Fang H, Li F, et al. GAMMA Challenge:Glaucoma grAding from Multi-ModalityimAges. arXiv. 2022, https://doi.org/10.48550/arXiv.2202.06511.
47. Porwal P, Pachade S, Kamble R, et al. IndianDiabetic Retinopathy Image Dataset (IDRiD):a database for diabetic retinopathy screeningresearch. Data. 2018;3:25.
48. Tan M, Le Q. Efficientnet: rethinking model scalingfor convolutional neural networks. In: ChaudhuriK, Salakhutdinov R, eds. Thirty-Sixth InternationalConference on Machine Learning. SanDiego, CA: ICML; 2019:6105–6114.
49. Galdran A, et al. The littleW-Net that could: stateof-the-art retinal vessel segmentation with minimalisticmodels. arXiv. 2020, https://doi.org/10.48550/arXiv.2009.01907.
50. Hart WE, Goldbaum M, Côté B, Kube P, NelsonMR. Measurement and classification of retinalvascular tortuosity. Int J Med Inform. 1999;53:239–252.
51. Grisan E, Foracchia M, Ruggeri A. A novelmethod for the automatic grading of retinal vesseltortuosity. IEEE Trans Med Imaging. 2008;27:310–319.
52. Falconer K. Fractal Geometry: MathematicalFoundations and Applications. New York: JohnWiley & Sons; 2004.
53. Wong TY, Klein R, Klein BEK,Meuer SM, HubbardLD. Retinal vessel diameters and their associationswith age and blood pressure. Invest OphthalmolVis Sci. 2003;44:4644–4650.
54. Parr JC, Spears GF. General caliber of the retinalarteries expressed as the equivalent widthof the central retinal artery. Am J Ophthalmol. 1974;77:472–477.
55. Parr JC, Spears GFS. Mathematic relationshipsbetween thewidth of a retinal artery and the widthsof its branches. Am J Ophthalmol. 1974;77:478–483.
56. Hansen LK, Salamon P. Neural network ensembles. IEEE Trans Pattern Anal Mach Intell. 1990;12:993–1001.
57. Sarhan A, Rokne J, Alhajj R, Crichton A. Transferlearning through weighted loss function andgroup normalization for vessel segmentation fromretinal images. In: Proceedings of ICPR 2020: 25thInternational Conference on Pattern Recognition(ICPR). Piscataway, NJ: Institute of Electricaland Electronics Engineers; 2021.
58. Shin SY, Lee S, Yun ID, Lee KM. Topology-awareretinal artery–vein classification via deep vascularconnectivity prediction. Appl Sci. 2020;11:320.
59. Hasan MK, Alam MA, Elahi MTE, Roy S, MartíR. DRNet: segmentation and localization of opticdisc and fovea from diabetic retinopathy image. Artif Intell Med. 2021;111:102001.
60. Cheung CY-L, et al. A new method to measureperipheral retinal vascular caliber over anextended area. Microcirculation. 2010;17:495–503.
61. Poplin R, Varadarajan AV, Blumer K, et al. Predictionof cardiovascular risk factors from retinalfundus photographs via deep learning. Nat BiomedEng. 2018;2:158–164.
62. Kelly CJ, Karthikesalingam A, Suleyman M, CorradoG, King D.Key challenges for delivering clinicalimpact with artificial intelligence. BMC Med. 2019;17:195.
63. Singh RP, Hom GL, Abramoff MD, Campbell JP,Chiang MF, AOO Task Force on Artificial Intelligence. Current challenges and barriers to realworldartificial intelligence adoption for the healthcaresystem, provider, and the patient. Transl VisSci Technol. 2020;9:45.
64. Yip W, Tham YC, Hsu W, et al. Comparison ofcommon retinal vessel caliber measurement softwareand a conversion algorithm. Transl Vis SciTechnol. 2016;5:11.
65. McGrory S, Taylor AM, Pellegrini E, et al. Towards standardization of quantitative retinalvascular parameters: comparison of SIVA andVAMPIRE measurements in the Lothian BirthCohort 1936. Transl Vis Sci Technol. 2018;7:12.

引用说明: Zhou Y, Wagner SK, Chia MA, Zhao A, et al. AutoMorph: Automated Retinal Vascular Morphology Quantification Via a Deep Learning Pipeline. Transl Vis Sci Technol. 2022 Jul 8;11(7):12. doi: 10.1167/tvst.11.7.12.
版权说明:
youcans@xidian 作品,转载必须标注原文链接:
【医学影像 AI】AutoMorph:基于深度学习的自动化视网膜血管分析工具(https://youcans.blog.csdn.net/article/details/154020433)
Crated:2025-10