小白入门:基于k8s搭建训练集群,实战CIFAR-10图像分类
一、引言
近年来随着大模型的大放异彩,AI被推上了新的高度,学习AI是每个人的必修课。AI模型的训练,需要用到很多的计算资源,单机往往不能满足训练的需求。为满足提高训练效率,加快模型迭代的需求,多机多卡训练成为自然而然的选择。如何管理显卡资源,如何调度训练任务,实现多机多卡的集群。本文将详细介绍如何在Kubernetes环境下,基于Python搭建一个高效的分布式深度学习训练平台。
二、环境准备
- 服务器准备:1 master 1 worker
- 操作系统:Centos 7
- Kubernetes:1.18.2
- Docker:19.03.1
- Python:3.9
- 深度学习框架:pytorch
三、K8S集群搭建
192.168.5.101 k8s-master
192.168.5.102 k8s-worker01
Docker安装
- 修改主机名
192.168.5.101机器 hostnamectl set-hostname k8s-master
192.168.5.102机器 hostnamectl set-hostname k8s-worker01
- 配置本地域名解析
两个机器上都执行
cat >> /etc/hosts << EOF
192.168.5.101 k8s-master
192.168.5.102 k8s-worker01
EOF
- 关闭防火墙并禁止其开机自启动
systemctl stop firewalld & systemctl disable firewalld
- 关闭selinux(关闭selinux以允许容器访问宿主机的文件系统)
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config && setenforce 0
- 关闭swap分区(影响k8s内存性能)
sed -i '/ swap / s/^/#/' /etc/fstab
swapoff -a
- 配置yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum -y install yum-utils
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
- 安装docker
yum install docker-ce-19.03.1 -y
- 启动一下我们的docker容器并设置为开机自启动
systemctl start docker & systemctl enable docker
执行命令docker version,检查docker是否安装完成,如下则标准成功。
K8S安装
- 添加kubernetes源,这里配置为阿里云的镜像源
#配置kubernetes源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg \
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
- 安装kubernetes组件
yum install -y kubelet-1.18.2 kubeadm-1.18.2 kubectl-1.18.2
- 启动kubelet
systemctl enable kubelet && systemctl start kubelet
- 配置master节点,本步只在master节点执行
kubeadm init --pod-network-cidr=192.168.0.0/16 --kubernetes-version=v1.18.2 --apiserver-advertise-address=192.168.5.101 --image-repository=registry.aliyuncs.com/google_containers
控制台会输出提示,需要建目录,执行如下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
完成该步后,会在控制台打印输出,记住它,拷贝它:
kubeadm join 192.168.23.101:6443 --token 6rc83u.nh3m19pypf024dw7 --discovery-token-ca-cert-hash sha256:cf73c46a33f6abae1bfc9eb6ef29050ddaadc3c7be880ec8cbe26fb4b2c42aaa
- 安装网络插件
kubectl apply -f https://docs.projectcalico.org/v3.10/manifests/calico.yaml
- 检查主节点是否已经在运行
kubectl get nodes

kubectl -n kube-system get pods
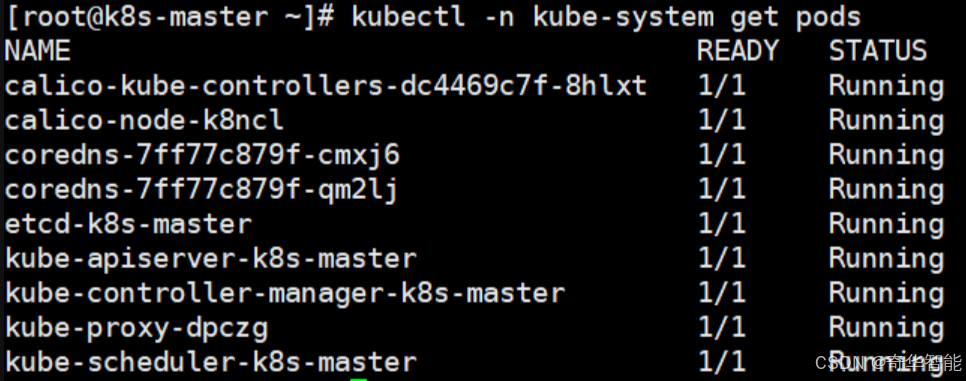
若status不是ready状态,可以等待一下,初始化需要时间。
至此,我们的master节点已经配置完成,后面就是怎么把其他的work节点加入到我们集群中。
- 加入work节点
在k8s-worker01上执行上面我们保存的命令
kubeadm join 192.168.5.101:6443 --token 6rc83u.nh3m19pypf024dw7 --discovery-token-ca-cert-hash sha256:cf73c46a33f6abae1bfc9eb6ef29050ddaadc3c7be880ec8cbe26fb4b2c42aaa
- 查看集群状态
kubectl get nodes

可以给work01节点设置角色为worker:
kubectl label nodes k8s-worker01 node-role.kubernetes.io/worker=
查看pod的状态
kubectl -n kube-system get pods -o wide
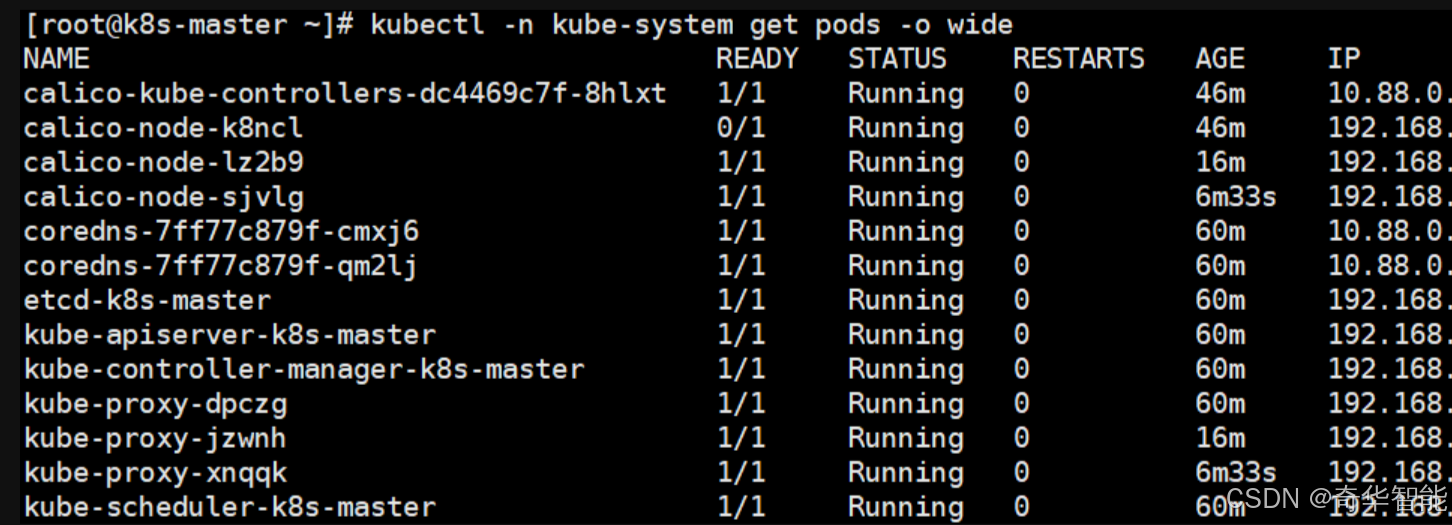 等等一会后,所有的都ready,择表示机集群部署成功了。
等等一会后,所有的都ready,择表示机集群部署成功了。
若安装遇到问题,我们有时候需要移除节点,移除节点的方法如下:
#在主节点执行以下命令,这里以work01为例
kubectl drain k8s-worker01 --delete-local-data --force --ignore-daemonsets
kubectl delete node k8s-worker01
#在k8s-worker01节点上执行以下命令,重置节点
kubeadm reset -f
四、训练模型
训练镜像构建
Dockerfile文件内容
FROM python:3.8RUN pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpuWORKDIR /COPY demo.py demo.pydemo.py
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from model import SimpleCNNtransform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),
])
train_dataset = datasets.CIFAR10(root='/data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)def train(model, device, train_loader, optimizer, epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % 10 == 0:print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} ({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')def main():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = SimpleCNN().to(device)optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)for epoch in range(1, 11): # 训练10个epochtrain(model, device, train_loader, optimizer, epoch)torch.save(model.state_dict(), "model.pth")if __name__ == "__main__":main()
model.py 模型定义
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transformsclass SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.fc1 = nn.Linear(2304, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = nn.functional.relu(x)x = nn.functional.max_pool2d(x, 2)x = self.conv2(x)x = nn.functional.relu(x)x = nn.functional.max_pool2d(x, 2)x = torch.flatten(x, 1)x = self.fc1(x)x = nn.functional.relu(x)x = self.fc2(x)return nn.functional.log_softmax(x, dim=1)构建命令
docker build -t my_train_test_image:v0.1 .
如此,则构建好训练镜像。
创建k8s训练任务
train_job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pytorch-job
spec:
template:
spec:
containers:
- name: pytorch-container
image: my_train_test_image:v0.1
command: ["python3", "/demo.py"]
args: ["--epochs", "10"]
volumeMounts:
- name: pytorch-data
mountPath: /data
restartPolicy: OnFailure
volumes:
- hostPath:
path: /data
type: DirectoryOrCreate
name: pytorch-data
提交任务到集群
kubectl apply -f train_job.yaml -n kube-system
通过kubectl get pods -A命令,查看job容器是否完成,在训练中,可已通过kubectl logs -f poxxxx 命令,查看训练的日志输出。
完成,则会保存模型到/model.pth文件中。
五、模型推理
这一步,加载第四步里面的模型文件,来做推理。
test.py
import torch
import torch.nn.functional as F
from torch.autograd import Variable
from model import SimpleCNN
import numpy as np
import cv2def main():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = SimpleCNN()model.load_state_dict(torch.load("model.pth"))model = model.to(device)model.eval()image = cv2.imread('010029.jpg')image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image = cv2.resize(image, (32, 32))image = image.astype(np.float32) / 255.0image = (image - 0.5) / 0.5image = image.transpose(2, 0, 1)image_tensor = torch.from_numpy(image).unsqueeze(0)with torch.no_grad():output = model(image_tensor)pred_class = output.argmax(dim=1).item()probability = torch.exp(output[0, pred_class]).item()print(f"label: {pred_class}, score: {probability:.4f}")if __name__ == "__main__":main()
docker run -it --name zzztest111 my_train_test_image:v0.1 python3 /test.py
六、总结
本篇文章我们从0到1实战了从部署k8s集群,到训练一个CV算法模型的小案例,不仅掌握了构建集群和训练CNN模型的基本流程,还学习了如何评估使用模型进行推理,帮助将来使用的时候得心应手。K8S工具功能强大,如何进行计算资源分配,限制,调度等延伸能力,感兴趣的同学可以继续往下深究,如何训练模型,使用模型这些技能都是CV算法工程师的基础能力,若感兴趣可以在案例的基础上进行延伸扩展,试试模型优化参数调优。是不是比较简单,赶紧动手学习起来吧。