Java IO 流之转换流:InputStreamReader/OutputStreamWriter(字节与字符的桥梁)

引言:为什么会有乱码?
你是否遇到过这样的场景:用FileInputStream读取文本文件,输出到控制台时变成了一堆???或乱码?明明文件内容是中文,却怎么也读不对 —— 这不是代码的错,而是字节与字符的 “沟通障碍” 导致的。
想象一下:计算机底层只认识字节(0 和 1),而人类读写的是字符(如 “中”“a”“€”)。字符到字节需要 “编码”(如 UTF-8),字节到字符需要 “解码”(用相同的编码)。如果编码和解码用了不同的规则,就会出现乱码。
而 Java 中的转换流(InputStreamReader/OutputStreamWriter) 正是解决这个问题的关键:它们是字节流与字符流之间的 “翻译官”,负责在两者之间进行编码转换。本文将彻底讲透转换流的原理、用法和避坑指南,让你从此告别文本处理的乱码烦恼。
一、核心问题:字节与字符的本质区别
在讲转换流之前,我们必须先搞懂一个基础问题:字节(Byte)和字符(Char)到底是什么关系?
- 字节:计算机存储和传输的基本单位(1 字节 = 8 位),范围是
0-255,本质是二进制数据。- 字符:人类可识别的符号(如字母、汉字、符号),Java 中
char占 2 字节(UTF-16 编码),范围是0-65535。
关键结论:字符不能直接存储或传输,必须通过编码规则转换为字节;反之,字节也必须通过相同的编码规则转换为字符。这个 “转换” 的过程,就是转换流的核心工作。
1.1 编码与解码的流程
下图直观展示字符与字节的转换过程:

示例:字符 “中” 的编码过程
- 用 UTF-8 编码:转换为 3 个字节
0xE4 0xB8 0xAD- 用 GBK 编码:转换为 2 个字节
0xD6 0xD0- 若用 UTF-8 编码的字节,却用 GBK 解码,会得到乱码 “涓”(这就是乱码的根源)。
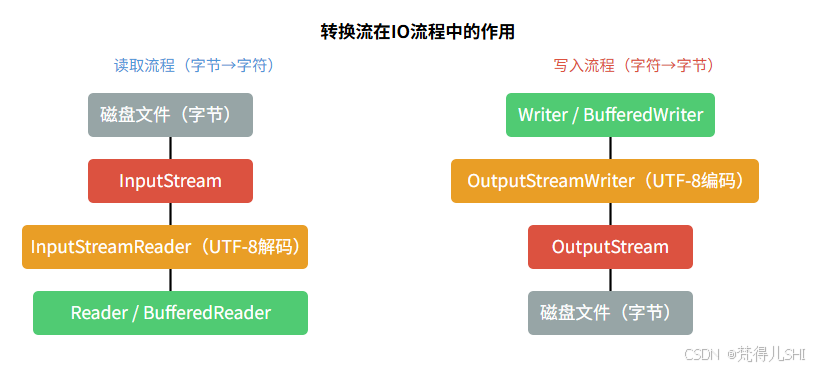
二、转换流的作用:字节流 → 字符流的桥梁
Java 的 IO 流分为字节流(InputStream/OutputStream)和字符流(Reader/Writer)两大体系,它们之间不能直接转换。而转换流就是连接两者的桥梁:
- InputStreamReader:将字节输入流(
InputStream)转换为字符输入流(Reader),负责解码(字节→字符)。- OutputStreamWriter:将字节输出流(
OutputStream)转换为字符输出流(Writer),负责编码(字符→字节)。
2.1 为什么需要转换流?
字符流操作文本更方便(如readLine()读取一行),但字符流不能直接操作字节流(如文件、网络的底层都是字节流)。转换流的作用就是:让字符流能处理字节流的数据源,同时指定编码规则避免乱码。
比如:读取一个 UTF-8 编码的文本文件,流程是:FileInputStream(字节流) → InputStreamReader(转换流,指定 UTF-8 解码) → BufferedReader(字符缓冲流,方便读写)
三、转换流的使用:从入门到实战
3.1 构造方法(核心参数是编码)
InputStreamReader 构造方法
// 用默认编码(不推荐,可能随系统变化)
InputStreamReader(InputStream in)// 显式指定编码(推荐,如StandardCharsets.UTF_8)
InputStreamReader(InputStream in, String charsetName)
InputStreamReader(InputStream in, Charset cs) // 更安全,避免字符串编码名拼写错误
OutputStreamWriter 构造方法
// 用默认编码(不推荐)
OutputStreamWriter(OutputStream out)// 显式指定编码(推荐)
OutputStreamWriter(OutputStream out, String charsetName)
OutputStreamWriter(OutputStream out, Charset cs)
注意:
Charset类是 Java NIO 中引入的编码工具类,StandardCharsets提供了常用编码(如UTF_8、GBK),比字符串形式(如 "UTF-8")更安全(避免拼写错误导致的异常)。
3.2 基础示例:用指定编码读写文本文件
需求:用 UTF-8 编码写入一段中文到文件,再用 UTF-8 解码读取,确保无乱码。
public class ConversionStreamDemo {public static void main(String[] args) {String filePath = "test_utf8.txt";String content = "转换流:解决乱码问题的关键!";// 1. 用UTF-8编码写入(字符→字节)try (// 字节输出流(底层)OutputStream os = new FileOutputStream(filePath);// 转换流:指定UTF-8编码(字符→字节)OutputStreamWriter osw = new OutputStreamWriter(os, StandardCharsets.UTF_8);// 配合缓冲流提升性能(字符缓冲流)BufferedWriter bw = new BufferedWriter(osw)) {bw.write(content);bw.flush(); // 确保数据写入System.out.println("写入成功!");} catch (IOException e) {e.printStackTrace();}// 2. 用UTF-8解码读取(字节→字符)try (// 字节输入流(底层)InputStream is = new FileInputStream(filePath);// 转换流:指定UTF-8解码(字节→字符)InputStreamReader isr = new InputStreamReader(is, StandardCharsets.UTF_8);// 配合缓冲流提升性能BufferedReader br = new BufferedReader(isr)) {String line;while ((line = br.readLine()) != null) {System.out.println("读取内容:" + line); // 输出:转换流:解决乱码问题的关键!}} catch (IOException e) {e.printStackTrace();}}
}
关键:写入和读取必须使用相同的编码(这里都是 UTF-8),否则会乱码。
3.3 乱码演示:编码与解码不一致
如果写入用 UTF-8,读取用 GBK,会发生什么?
// 错误示例:编码和解码不一致
try (InputStream is = new FileInputStream(filePath);// 错误:用GBK解码UTF-8编码的字节InputStreamReader isr = new InputStreamReader(is, "GBK");BufferedReader br = new BufferedReader(isr)
) {String line = br.readLine();System.out.println("乱码结果:" + line); // 输出:杞崲娴侊細瑙e喅鐩稿唽闂鐨勫叧閿!
} catch (IOException e) {e.printStackTrace();
}
结果:输出的是一堆乱码,因为 GBK 无法正确解析 UTF-8 的字节序列。
四、深入原理:转换流如何进行编码和解码?
转换流的核心是编码解码器(CharsetEncoder/CharsetDecoder),它们由Charset类提供。我们以InputStreamReader为例,看看其内部工作流程:
4.1 InputStreamReader 解码流程(字节→字符)
// InputStreamReader 关键源码简化
public class InputStreamReader extends Reader {private final StreamDecoder sd; // 核心:字节→字符的解码器public InputStreamReader(InputStream in, Charset cs) {// 创建解码器(基于指定的字符集)sd = StreamDecoder.forInputStreamReader(in, this, cs.newDecoder());}@Overridepublic int read(char[] cbuf, int off, int len) throws IOException {// 实际调用解码器读取字节,转换为字符return sd.read(cbuf, off, len);}
}
流程:
InputStreamReader接收一个字节流(InputStream)和编码规则(Charset);- 内部创建
StreamDecoder(解码器),负责将字节流按指定编码转换为字符; - 调用
read()方法时,实际是解码器从字节流读取字节,解码为字符数组。
4.2 OutputStreamWriter 编码流程(字符→字节)
// OutputStreamWriter 关键源码简化
public class OutputStreamWriter extends Writer {private final StreamEncoder se; // 核心:字符→字节的编码器public OutputStreamWriter(OutputStream out, Charset cs) {// 创建编码器(基于指定的字符集)se = StreamEncoder.forOutputStreamWriter(out, this, cs.newEncoder());}@Overridepublic void write(char[] cbuf, int off, int len) throws IOException {// 实际调用编码器将字符转换为字节,写入输出流se.write(cbuf, off, len);}
}
流程:
OutputStreamWriter接收一个字节流(OutputStream)和编码规则(Charset);- 内部创建
StreamEncoder(编码器),负责将字符按指定编码转换为字节; - 调用
write()方法时,编码器将字符数组编码为字节,写入底层字节流。
4.3 转换流的工作模型
用下图展示转换流在 IO 流程中的位置:
五、转换流 vs 其他字符流:为什么推荐用转换流?
你可能会问:FileReader和FileWriter也是字符流,为什么还要用转换流?
答案:FileReader和FileWriter本质是转换流的简化版,但存在一个致命缺陷 ——默认使用系统编码,而系统编码可能因环境(Windows/Linux/macOS)不同而变化,导致乱码。
// FileReader 源码(本质是转换流的子类)
public class FileReader extends InputStreamReader {public FileReader(String fileName) throws FileNotFoundException {// 隐藏了编码参数,默认使用系统编码(Charset.defaultCharset())super(new FileInputStream(fileName));}
}
问题示例:
- 在 Windows 系统(默认 GBK 编码)用
FileWriter写入中文,生成的文件是 GBK 编码;- 若在 Linux 系统(默认 UTF-8 编码)用
FileReader读取该文件,会因编码不一致导致乱码。
最佳实践:始终使用转换流(InputStreamReader/OutputStreamWriter),并显式指定编码(如StandardCharsets.UTF_8),避免依赖系统默认编码。
六、性能优化:转换流配合缓冲流使用
转换流本身不提供缓冲区,每次读写可能频繁触发编码 / 解码操作。因此,必须配合缓冲流(BufferedReader/BufferedWriter)使用,以提升性能。
// 推荐写法:转换流 + 缓冲流
try (InputStream is = new FileInputStream("file.txt");// 转换流:指定编码InputStreamReader isr = new InputStreamReader(is, StandardCharsets.UTF_8);// 缓冲流:减少IO次数BufferedReader br = new BufferedReader(isr)
) {// 高效读取String line;while ((line = br.readLine()) != null) {// 处理数据}
} catch (IOException e) {e.printStackTrace();
}
性能对比:
- 转换流单独使用:每次
read()可能读取 1 个字符,触发多次解码和字节读取;- 配合缓冲流:缓冲流先读取一批字节到缓冲区,转换流从缓冲区解码,减少 IO 和编码 / 解码次数。
七、避坑指南:转换流使用的常见问题
7.1 乱码的 3 种常见原因及解决
编码和解码不一致
- 例如:UTF-8 编码的文件用 GBK 解码。
- 解决:确保写入和读取使用相同的编码(推荐 UTF-8)。
使用系统默认编码
- 例如:用
FileReader/FileWriter或未指定编码的转换流。 - 解决:显式指定编码,如
StandardCharsets.UTF_8。
- 例如:用
编码不支持中文
- 例如:用 ISO-8859-1 编码(不支持中文)写入中文。
- 解决:使用支持中文的编码(UTF-8、GBK、GB2312 等)。
7.2 如何查看文件的编码?
- 记事本:打开文件→“另存为”→底部可查看编码;
- IDE(如 IDEA):打开文件→右下角显示编码;
- 命令行(Linux):
file -i filename。
7.3 处理 BOM 头问题
Windows 系统的记事本保存 UTF-8 文件时,可能会在开头添加 BOM(字节顺序标记,0xEF 0xBB 0xBF),导致读取时出现多余字符(如 “”)。
解决方法:使用UTF-8 without BOM编码保存文件,或在读取时跳过 BOM 头:
// 跳过UTF-8 BOM头
if (br.ready()) {char[] bom = new char[1];br.read(bom);if (bom[0] != '\ufeff') { // BOM的Unicode编码是\ufeff// 不是BOM头,回退指针br.reset();}
}
总结
转换流(InputStreamReader/OutputStreamWriter)是 Java IO 中连接字节流和字符流的核心组件,其本质是处理编码与解码,解决文本读写的乱码问题。本文要点:
- 核心作用:字节流→字符流的转换,负责编码(字符→字节)和解码(字节→字符);
- 关键参数:必须显式指定编码(如 UTF-8),避免依赖系统默认编码;
- 使用场景:所有文本处理场景(如读写配置文件、日志文件、网络文本数据);
- 最佳实践:配合缓冲流使用以提升性能,始终使用
StandardCharsets指定编码; - 避坑重点:确保编码和解码一致,警惕系统默认编码和 BOM 头问题。
掌握转换流,你就掌握了 Java 文本处理的 “翻译密码”,从此告别乱码烦恼!
