6.2 大数据方法论与实践指南-任务元数据
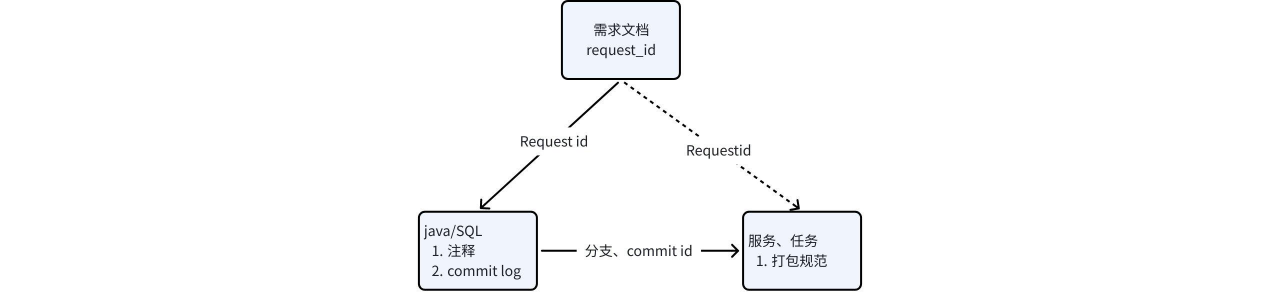
通过以上章节的可知,每个产品需求都会有对应的需求 id(request_id), 此 id 会流转到对应的主函数入口 comment,git commit log 中。这样线上任务的 SQL/jar 包根据分支、commit id ,及 main 函数,就能获取到线上程序与需求对应关系。
大数据实时任务的元数据是描述实时流处理任务全生命周期(定义、运行、链路)的关键信息,需精准反映流处理的 “低延迟、持续性、状态依赖” 等特性。以下从静态定义元数据、动态运行元数据、数据链路元数据三个维度,系统梳理实时任务元数据的核心字段、特性及管理价值。
一、静态定义元数据(任务固有属性)
静态元数据描述实时任务的 “先天属性”,不随运行状态变化,是任务调度、资源分配的基础依据。
| 元数据类别 | 核心字段 | 流处理特性说明 |
| 基础标识信息 | 任务唯一 ID(如RT-TASK-ORDER-001)、名称(“实时订单金额统计”)、所属业务域(电商)、负责人、版本号(v2.3) | ID 需与离线任务区分(如前缀RT-),版本号跟踪代码迭代(含算子逻辑变更) |
| 技术栈信息 | 处理引擎(Flink/Spark Streaming)、引擎版本(Flink 1.17)、开发语言(Java/Scala/Python) | 关联引擎特性(如 Flink 的状态后端、Spark Streaming 的微批处理机制) |
| 流处理逻辑信息 | 算子链路(Source→Filter→Window→Aggregate→Sink)、窗口配置(类型:滑动窗口;大小:5 分钟;滑动步长:1 分钟)、状态管理策略(如 TTL=24 小时) | 核心区别字段,反映实时计算规则(如 “每 5 分钟统计最近 10 分钟的订单量”) |
| 资源配置信息 | 总并行度(12)、算子级并行度(Source=2;Window=6;Sink=4)、TaskManager 内存(8G / 实例)、CPU 核数(2 核 / 实例) | 需精细化分配(避免某算子成为瓶颈),支持动态扩缩容(如峰值时自动提升并行度) |
| 容错配置信息 | Checkpoint 间隔(30 秒)、存储路径(HDFS /flink/checkpoints/rt-order)、状态后端(RocksDB)、Savepoint 策略(每日凌晨 3 点触发) | 直接影响故障恢复能力(如 Checkpoint 失败会导致状态丢失风险) |
| 接入配置信息 | 数据源类型(Kafka/CDC/ 日志流)、Kafka 主题(order-events)、消费组(order-count-group)、起始偏移量策略(earliest/latest) | 流数据入口参数,偏移量管理决定数据完整性(如 “从最新偏移量开始消费” 避免重复计算) |
点击图片可查看完整电子表格
二、动态运行元数据(任务实时状态)
动态元数据记录任务运行过程中的实时指标,反映流处理的 “即时性能、健康状态、数据波动”,是监控告警的核心依据。
| 元数据类别 | 核心字段 | 流处理特性说明 |
| 实时性能指标 | 输入 QPS(当前 5000 条 / 秒,峰值 12000 条 / 秒)、处理延迟(平均 80ms,95 分位 150ms)、背压状态(无 / 轻度 / 重度) | 直接体现实时性,延迟超阈值(如 200ms)需告警,背压说明下游处理能力不足 |
| 运行状态信息 | 任务状态(运行中 / 暂停 / 失败)、连续运行时长(30 天 2 小时)、失败原因(如 “Kafka 连接超时”)、恢复次数(今日 2 次) | 实时任务需长期运行,状态异常需快速介入(如失败后自动重启并从最近 Checkpoint 恢复) |
| 状态数据指标 | 状态大小(当前 15GB)、状态增长率(500MB / 天)、Checkpoint 成功率(99.7%)、Checkpoint 耗时(平均 5 秒) | 状态数据是流计算的 “记忆”(如窗口聚合的中间结果),过大可能导致性能下降 |
| 数据质量指标 | 输入数据合规率(99.9%)、字段缺失率(0.05%)、格式错误率(0.02%)、输出重复率(0%) | 实时数据质量需即时监控(如格式错误率突增可能是上游系统变更导致) |
| 资源使用指标 | 内存使用率(70%)、CPU 使用率(65%)、网络 IO(200MB/s) | 反映资源瓶颈(如内存使用率持续 > 90% 需扩容),支持弹性资源调度 |
点击图片可查看完整电子表格
三、数据链路元数据(血缘与依赖)
数据链路元数据构建实时任务的 “数据血缘图谱”,记录数据从 “输入→处理→输出” 的全链路依赖,支撑影响分析与问题追溯。
| 元数据类别 | 核心字段 | 流处理特性说明 |
| 上游数据源信息 | 数据源类型(Kafka)、主题 / 表名(order-events)、分区数(8)、数据格式(Protobuf)、字段结构(order_id/amount/create_time) | 需记录实时消费进度(如当前各分区偏移量:partition 0: 100000) |
| 下游输出信息 | 输出类型(Redis/ClickHouse/Kafka)、目标地址(Redis rt:order:amount)、更新策略(每 100ms 批量写入)、数据格式(JSON) | 输出可能直接对接业务系统(如实时大屏、风控引擎),需记录更新频率确保时效性 |
| 血缘关系信息 | 上游依赖任务(如RT-TASK-LOG-002:订单日志解析任务)、下游消费任务(如RT-TASK-ALERT-001:异常订单告警任务) | 包含 “状态数据血缘”(如窗口聚合依赖前序 Checkpoint 的中间结果) |
| 数据转换规则 | 字段映射关系(amount字段从order_total转换而来)、过滤条件(仅保留pay_status=1的订单)、聚合逻辑(SUM(amount)按merchant_id分组) | 实时转换规则需精准记录(如逻辑错误会导致下游数据失真) |
点击图片可查看完整电子表格
四、实时任务元数据的核心特性(与离线对比)
| 特性维度 | 实时任务元数据 | 离线任务元数据 |
| 时间特性 | 持续更新(如 QPS 每秒刷新),关注 “瞬时值” 与 “波动趋势” | 周期更新(如任务结束后记录一次),关注 “总量” 与 “耗时” |
| 状态依赖 | 强依赖 “状态数据” 元数据(如 Checkpoint、窗口状态),影响故障恢复 | 弱依赖状态(可重跑全量数据),元数据不包含中间状态信息 |
| 粒度要求 | 细至 “算子级”“分区级”(如某 Kafka 分区消费滞后) | 粗至 “任务级”“表级”(如某 Hive 表全量处理耗时) |
| 实时性要求 | 元数据采集延迟需≤10 秒(否则监控告警滞后) | 元数据采集延迟可容忍(如任务结束后 1 小时内同步) |
点击图片可查看完整电子表格
五、元数据管理与应用场景
- 实时监控与告警
基于动态元数据设置阈值(如 “处理延迟> 200ms”“Checkpoint 连续 3 次失败”),通过监控平台(如 Prometheus+Grafana)实时预警,保障任务稳定性。例如:某实时订单任务 QPS 突增至 20000 条 / 秒,触发 “背压告警”,运维人员立即扩容 Window 算子并行度。
- 故障溯源与恢复
当任务失败时,结合 “静态配置(如 Checkpoint 路径)+ 动态状态(如最后成功 Checkpoint 时间)+ 数据链路(如上游 Kafka 偏移量)” 快速定位原因。例如:任务失败后,通过元数据确认最近一次成功 Checkpoint 位置,一键恢复至故障前状态。
- 性能优化
分析 “算子并行度 - 处理延迟” 关联数据,优化资源分配。例如:发现 Sink 算子并行度不足导致整体延迟,将其从 4 提升至 6,延迟降低 40%。
- 变更影响分析
当上游 Kafka 主题字段变更时,通过血缘元数据快速定位所有依赖的下游实时任务(如订单统计、库存更新任务),提前通知开发团队适配。
- 合规审计
元数据记录 “数据来源(如用户订单信息)、处理逻辑(如脱敏规则)、输出用途(如实时推荐)”,满足《个人信息保护法》对数据处理活动的追溯要求。
六、元数据采集与存储方案
- 采集方式:
- 静态元数据:通过代码解析(如 Flink SQL AST 分析算子逻辑)、配置文件同步(如从 Flink 配置提取 Checkpoint 参数)获取。
- 动态元数据:通过引擎 API(如 Flink Metric API)实时采集性能指标,结合监控系统(如 Flink Dashboard)同步状态信息。
- 数据链路元数据:参考《Spark/Flink 任务开发规范》中『数据源配置规范』章节,通过配置及启动参数解析工具,可以将线上服务与其外部数据系统依赖建立对应关系。(技术上可以参考, CDC 工具(如 Debezium)捕获数据变更,结合血缘分析工具(如 Apache Atlas)自动构建血缘关系。)
- 存储方案:
- 静态元数据:存储于关系型数据库(如 MySQL),支持结构化查询。
- 动态元数据:存储于时序数据库(如 InfluxDB、Prometheus),优化时间序列查询性能。
- 血缘元数据:存储于图数据库(如 Neo4j),便于展示 “任务 - 数据 - 任务” 的关联图谱。
总结
实时任务元数据是保障流处理系统 “高可用、低延迟、可追溯” 的核心基础设施,其设计需紧扣 “实时性、状态性、细粒度” 三大特性。通过构建完整的元数据体系,企业可实现实时任务的全链路可视化管理,快速响应业务波动、定位故障根因、满足合规要求,最终提升实时数据服务的可靠性与价值。
大数据离线任务的元数据是描述离线批处理任务全生命周期(定义、运行、数据链路)的结构化信息,需精准反映其 “周期性、批量处理、历史数据依赖” 等核心特性。以下从静态定义元数据、动态运行元数据、数据链路元数据三个维度,系统梳理离线任务元数据的核心字段、特性及实践价值。
一、静态定义元数据(任务固有属性)
静态元数据记录离线任务的 “先天属性”,不随运行状态变化,是任务调度、资源分配和版本管理的基础。
| 元数据类别 | 核心字段 | 批处理特性说明 |
| 基础标识信息 | 任务唯一 ID(如BATCH-TASK-USER-001)、名称(“用户行为日志日清洗”)、所属项目(用户画像)、负责人、版本号(v1.2) | ID 需与实时任务区分(如前缀BATCH-),版本号关联代码迭代(如逻辑优化、字段新增) |
| 技术栈信息 | 处理引擎(Hive/Spark/MapReduce)、引擎版本(Spark 3.3)、实现方式(SQL 脚本 / Python/Scala 代码) | 关联批处理特性(如 Hive 的 MapReduce 执行引擎、Spark 的内存计算优化) |
| 批处理逻辑信息 | 处理类型(全量 / 增量)、核心逻辑描述(“每日清洗前一天的用户点击日志,过滤无效 IP”)、核心 SQL / 代码片段(关键逻辑摘要) | 增量任务需明确增量字段(如按dt=20250907分区)和抽取规则(如where create_time >= 'xxx') |
| 调度配置信息 | 调度周期(Cron 表达式:0 2 * * *,即每日凌晨 2 点)、依赖任务(如BATCH-TASK-ODS-003:ODS 层日志同步完成)、重试策略(失败后重试 3 次,间隔 10 分钟) | 核心区别于实时任务的字段,体现 “周期性触发” 特性,依赖关系决定任务执行顺序 |
| 资源配置信息 | 内存(Driver 4G,Executor 16G)、CPU(Executor 4 核)、并行度(Spark spark.sql.shuffle.partitions=200)、队列(离线计算队列batch-queue) | 资源配置基于历史数据量估算(如 100GB 数据对应 200 并行度),支持按周期动态调整 |
| 输出配置信息 | 输出类型(Hive 表 / HDFS 文件 / MySQL 表)、存储路径(/user/hive/warehouse/dwd.db/user_click_clean)、分区策略(按dt日分区)、存储格式(Parquet)、压缩算法(ZSTD) | 离线任务多产出分层数据(如 DWD/DWS 层),分区策略需匹配调度周期(日 / 周 / 月) |
点击图片可查看完整电子表格
二、动态运行元数据(任务执行状态)
动态元数据记录任务每次运行的实时状态,反映批处理的 “执行效率、数据质量、资源消耗”,是监控、优化和问题排查的核心依据。
| 元数据类别 | 核心字段 | 批处理特性说明 |
| 执行指标 | 执行周期(20250907)、开始 / 结束时间(02:00:00-02:35:20)、耗时(35 分钟 20 秒)、处理数据量(120GB)、输出记录数(800 万条) | 体现批处理的 “一次性” 特性,用于 SLA 监控(如是否在 4 小时内完成当日任务) |
| 运行状态信息 | 任务状态(成功 / 失败 /killed)、失败阶段(Map 阶段 / Reduce 阶段)、失败原因(“HDFS 读写超时”“主键冲突”)、日志路径(YARN 日志 URL) | 失败原因需精确到代码行(如 SQL 报错位置),便于快速定位问题(如数据倾斜导致 OOM) |
| 资源消耗指标 | 峰值内存使用率(85%)、CPU 平均负载(60%)、Shuffle 数据量(30GB)、GC 耗时(5 分钟) | 反映资源匹配度(如 Shuffle 数据量过大说明 Join 逻辑需优化) |
| 数据质量指标 | 输入空值率(0.1%)、清洗过滤率(2.3%)、输出数据与前一日偏差率(3.5%)、主键重复率(0%) | 离线任务多通过事后校验(如 SQL 脚本检查)生成,偏差率超阈值(±5%)需人工介入 |
| 历史运行趋势 | 近 7 天平均耗时(32 分钟)、最长耗时(45 分钟,20250905)、失败次数(1 次,20250903) | 用于识别周期性问题(如周末数据量激增导致耗时变长) |
点击图片可查看完整电子表格
三、数据链路元数据(血缘与依赖)
数据链路元数据构建离线任务的 “数据血缘图谱”,记录数据从 “源头→处理→输出” 的全链路流转,支撑影响分析、数据溯源和合规审计。
| 元数据类别 | 核心字段 | 批处理特性说明 |
| 上游输入信息 | 数据源类型(ODS Hive 表 / MySQL 业务库 / HDFS 日志文件)、表名 / 路径(ods.user_click_log)、分区范围(dt=20250907)、数据格式(JSON)、字段结构(user_id/click_time/url) | 增量任务需明确输入分区依赖(如仅读取dt=前一天的数据) |
| 下游输出信息 | 输出表名 / 路径(dwd.user_click_clean)、分区(dt=20250907)、字段变更(新增ip_region字段)、权限信息(仅数据开发组可写) | 输出多为下游任务的输入(如 DWS 层聚合任务),需记录字段变更影响范围 |
| 血缘关系信息 | 上游依赖任务(如BATCH-TASK-ODS-003:日志同步任务)、下游消费任务(如BATCH-TASK-DWS-005:用户行为汇总任务) | 体现 “任务→数据→任务” 的批处理链路(如 A 任务输出表是 B 任务的输入表) |
| 数据转换规则 | 清洗规则(过滤user_id=null的记录)、字段映射(click_time格式从timestamp转为yyyy-MM-dd HH:mm:ss)、关联逻辑(左关联dim.ip_region表补充地域信息) | 规则需可追溯(如关联的维表版本),用于解释数据计算逻辑(如指标口径) |
点击图片可查看完整电子表格
四、离线任务元数据的核心特性(与实时对比)
| 特性维度 | 离线任务元数据 | 实时任务元数据 |
| 时间特性 | 按 “执行周期” 批量更新(如每日任务结束后记录一次),关注 “周期内总量” | 持续实时更新(如每秒刷新 QPS),关注 “瞬时值” 与 “波动” |
| 状态依赖 | 无状态依赖(失败可重跑全量数据),元数据不包含中间状态信息 | 强依赖状态数据(如 Checkpoint),元数据需记录状态大小、恢复能力 |
| 粒度要求 | 粗至 “任务级”“表级”“分区级”(如某 Hive 表dt=20250907分区的处理) | 细至 “算子级”“消息级”(如某 Kafka 分区的消费延迟) |
| 存储周期 | 长期存储(如 3 年),用于历史趋势分析(如季度数据量增长) | 短期存储(如 30 天),聚焦近期实时性能监控 |
点击图片可查看完整电子表格
五、元数据管理与应用场景
- 任务调度与依赖管理
调度系统(如 DolphinScheduler)基于静态元数据中的 “调度周期” 和 “依赖任务”,自动生成执行计划。例如:BATCH-TASK-DWD-001(用户清洗)依赖BATCH-TASK-ODS-003(日志同步),仅当前者成功后才触发后者。
- 问题排查与根因分析
当任务失败时,结合 “动态运行元数据”(如失败原因 “OOM”)和 “资源配置”(如 Executor 内存 16G),快速定位问题(如数据量突增导致内存不足),调整资源后重跑。
- 数据质量监控
基于 “数据质量指标”(如过滤率突增至 10%),触发告警并追溯上游数据(通过血缘元数据定位 ODS 层日志异常),避免脏数据流入下游。
- 资源优化与成本控制
分析 “历史运行趋势”(如某任务近 30 天平均耗时 20 分钟,但配置了 4 小时超时),缩减超时阈值和资源配置(如 Executor 内存从 16G 降至 12G),降低集群成本。
- 影响范围评估
当上游 ODS 表结构变更时,通过血缘元数据快速识别所有依赖的下游离线任务(如清洗、聚合、报表任务),评估整改范围并通知相关团队。
- 合规审计与追溯
元数据记录 “数据来源(用户日志)、处理逻辑(脱敏规则)、输出用途(用户画像)”,满足《数据安全法》对数据处理活动的可追溯要求。
六、元数据采集与存储方案
- 采集方式:
- 静态元数据:通过调度平台 API(如 DolphinScheduler 接口)同步任务配置,代码仓库(Git)解析获取处理逻辑摘要。
- 动态元数据:任务结束后,从引擎日志(YARN/Spark History Server)提取执行指标,质量校验脚本(如 Great Expectations)输出数据质量指标。
- 数据链路元数据:通过 SQL 解析工具(如 Calcite)提取输入输出表,结合调度平台的依赖关系自动构建血缘。
- 存储方案:
- 静态元数据:存储于关系型数据库(MySQL/PostgreSQL),支持结构化查询(如按 “所属项目” 筛选任务)。
- 动态元数据:存储于数据仓库(如 Hive),按 “任务 ID + 执行周期” 分区,支持历史趋势分析。
- 血缘元数据:存储于图数据库(Neo4j),直观展示 “表 - 任务 - 表” 的关联关系。
总结
离线任务元数据是离线数据仓库稳定性、可维护性的核心保障,其设计需紧扣 “周期性、批量处理、历史依赖” 三大特性。通过构建完整的元数据体系,企业可实现离线任务的全生命周期可视化管理,优化资源配置、加速问题排查、满足合规要求,最终提升离线数据服务的可靠性与效率。