PyTorch2 Python深度学习 - 初识PyTorch2,实现一个简单的线性神经网络
锋哥原创的PyTorch2 Python深度学习视频教程:
https://www.bilibili.com/video/BV1eqxNzXEYc
课程介绍

基于前面的机器学习Scikit-learn,深度学习Tensorflow2课程,我们继续讲解深度学习PyTorch2,所以有些机器学习,深度学习基本概念就不再重复讲解,大家务必学习好前面两个课程。本课程主要讲解基于PyTorch2的深度学习核心知识,主要讲解包括PyTorch2框架入门知识,环境搭建,张量,自动微分,数据加载与预处理,模型训练与优化,以及卷积神经网络(CNN),循环神经网络(RNN),生成对抗网络(GAN),模型保存与加载等。
PyTorch2 Python深度学习 - 初识PyTorch2,实现一个简单的线性神经网络
我们用 PyTorch 2 训练一个简单的神经网络,拟合函数,y=2x+1
让模型学会从输入 x 预测输出 y。
我们使用PyTorch2里的nn.Linear()来实现线性神经网络。
nn.Linear(in_features, out_features, bias=True)核心参数:
-
in_features
-
类型: int
-
作用: 指定输入特征的数量(输入维度)
-
说明: 每个输入样本的特征向量长度
-
out_features
-
类型: int
-
作用: 指定输出特征的数量(输出维度)
-
说明: 该线性层将产生的输出向量长度
-
bias
-
类型: bool
-
默认值: True
-
作用: 决定是否在变换中使用偏置项
-
说明:
-
如果
True,层会学习一个偏置参数b -
如果
False,层只进行线性变换而不加偏置
-
示例代码:
import torch
from torch import nn, optim
# 1,构造训练数据:y=2x+1
x = torch.linspace(-5, 5, 100).unsqueeze(1) # 100的样本,维度[100,1]
print(x, x.shape)
y = 2 * x + 1 + torch.randn(x.size()) # 添加噪声
# 2,定义简单的线性模型
model = nn.Linear(1, 1)
# 3, 定义损失函数与优化器
criterion = nn.MSELoss() # 均方误差
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 4,训练模型
epochs = 2000
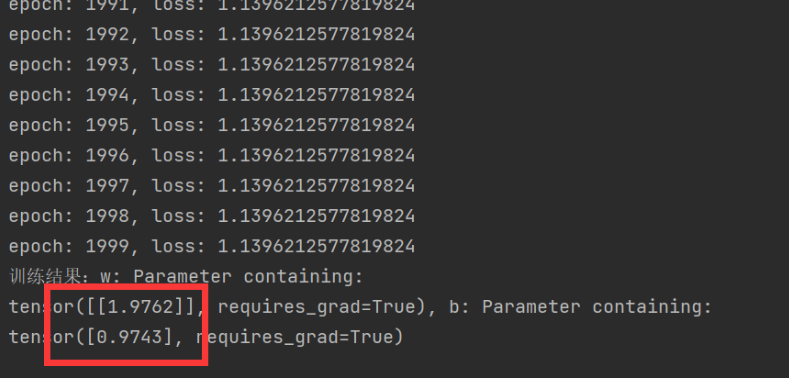
for epoch in range(epochs):y_pred = model(x) # 前向传播loss = criterion(y_pred, y) # 计算损失optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播optimizer.step() # 更新参数
print(f'epoch: {epoch}, loss: {loss.item()}')
# 5,查看结果
[w, b] = model.parameters()
print(f'训练结果:w: {w}, b: {b}')运行结果,已经非常接近2,1了。