计算机视觉:pyqt5+yoloV5目标检测平台 python实战 torch 目标识别 大数据项目 目标跟踪(建议收藏)✅
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
1、2026年计算机专业毕业设计选题大全(建议收藏)✅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
技术栈:
python语言、pyqt5、yoloV5、torch
pyqt5+yoloV5目标检测平台
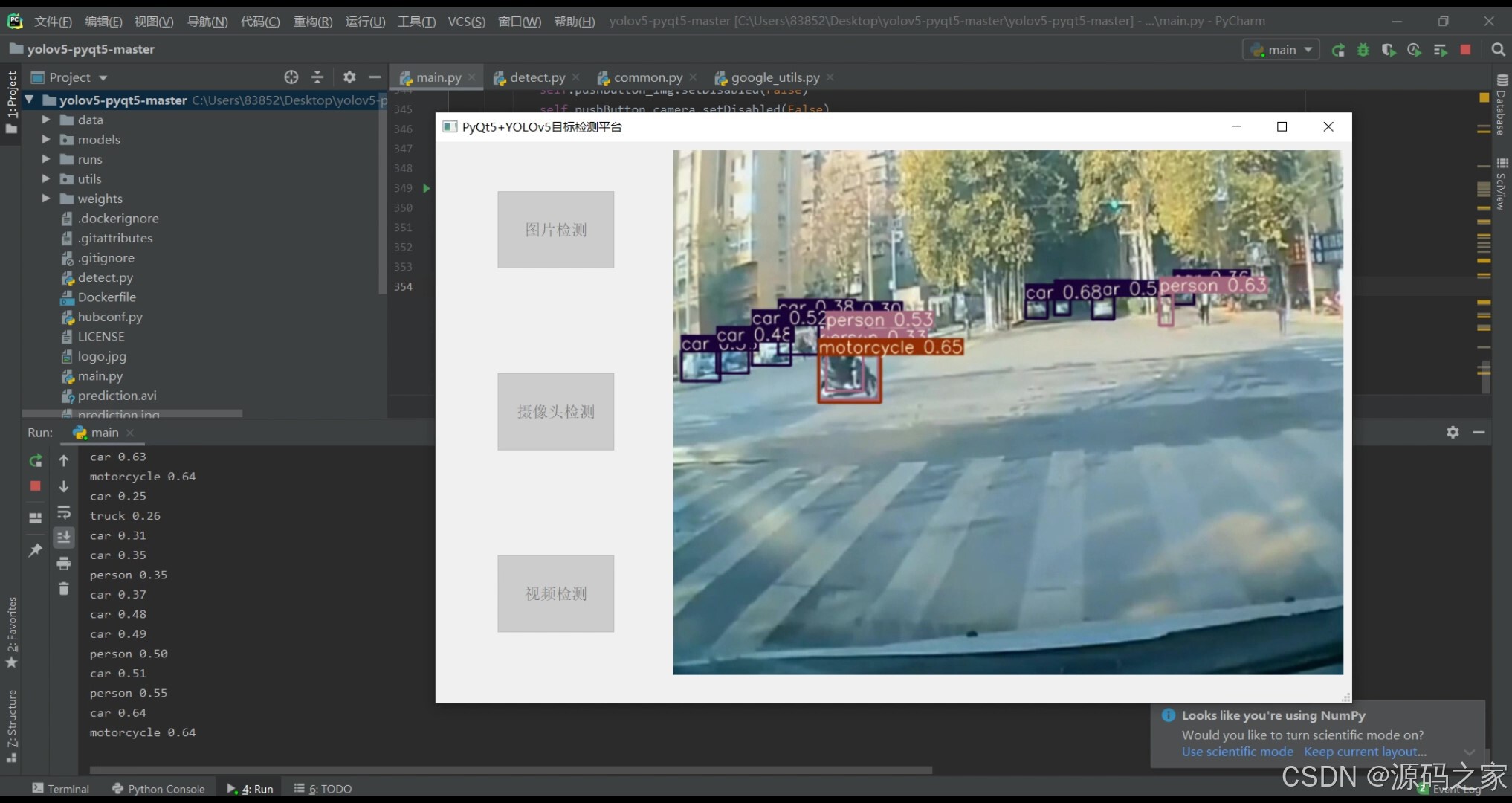
2、项目界面
(1)上传图片检测–识别人、汽车、自行车、摩托车、书包等等
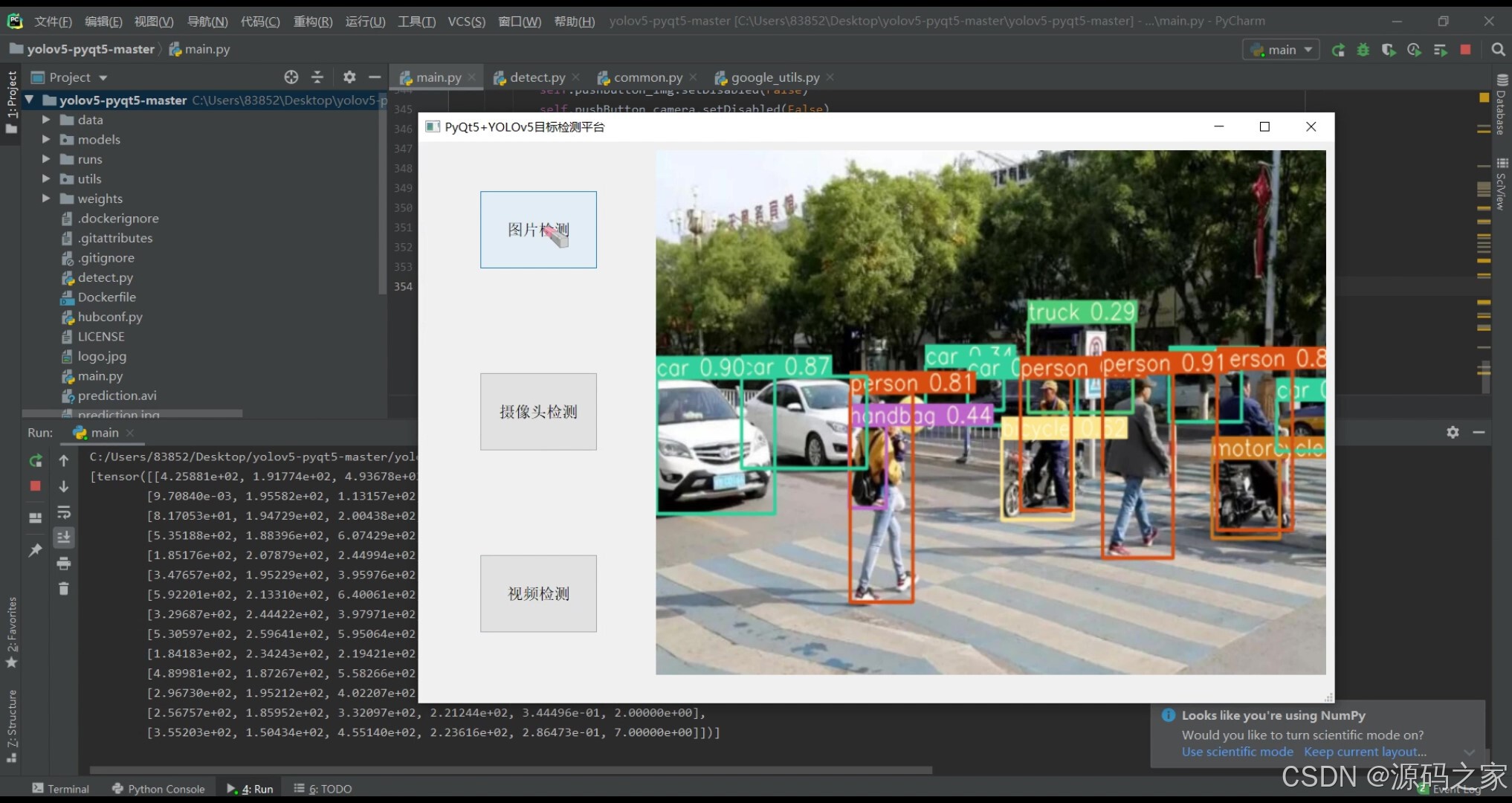
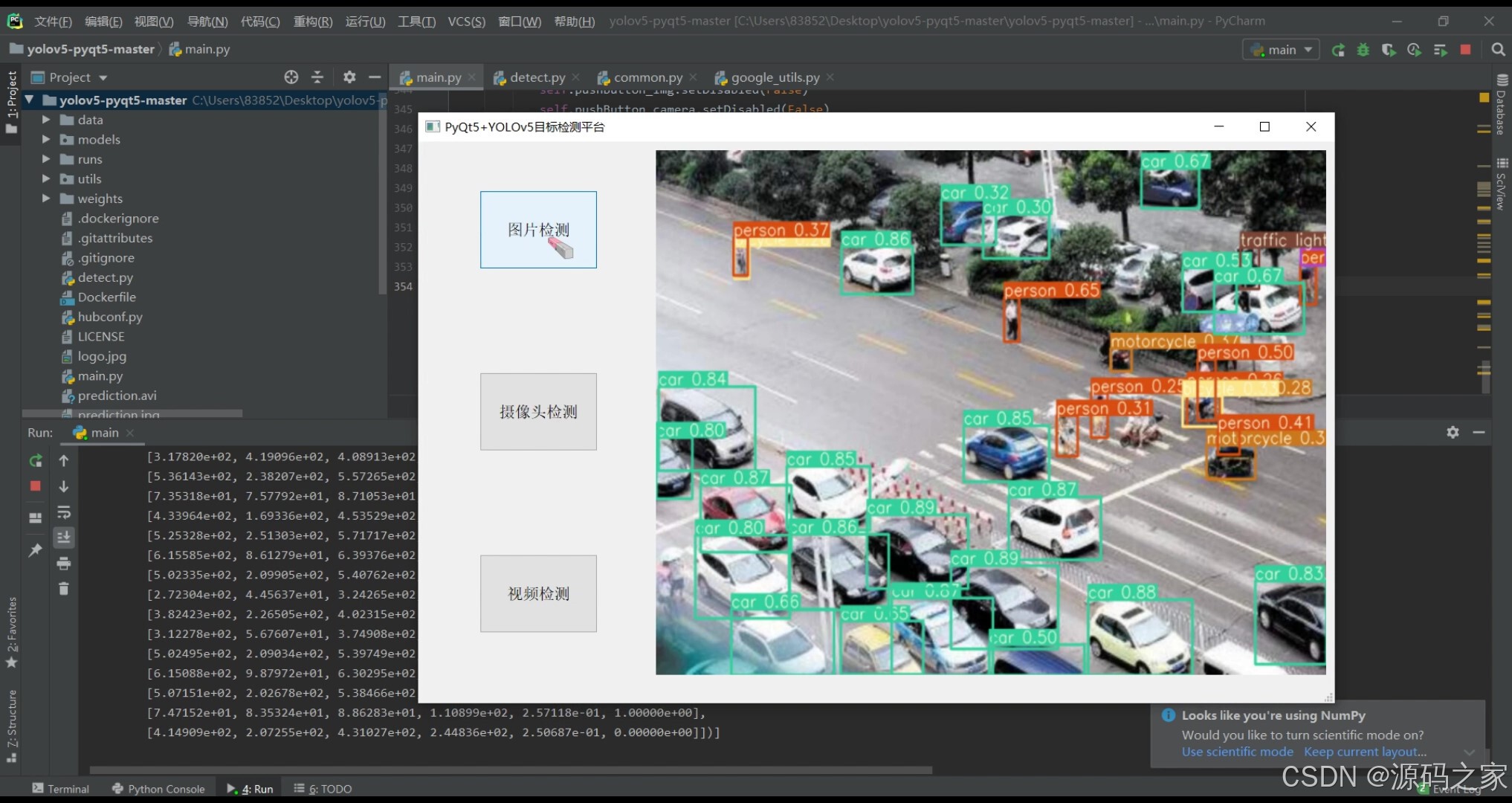
(2)上传图片检测–识别人、汽车、自行车、摩托车等等
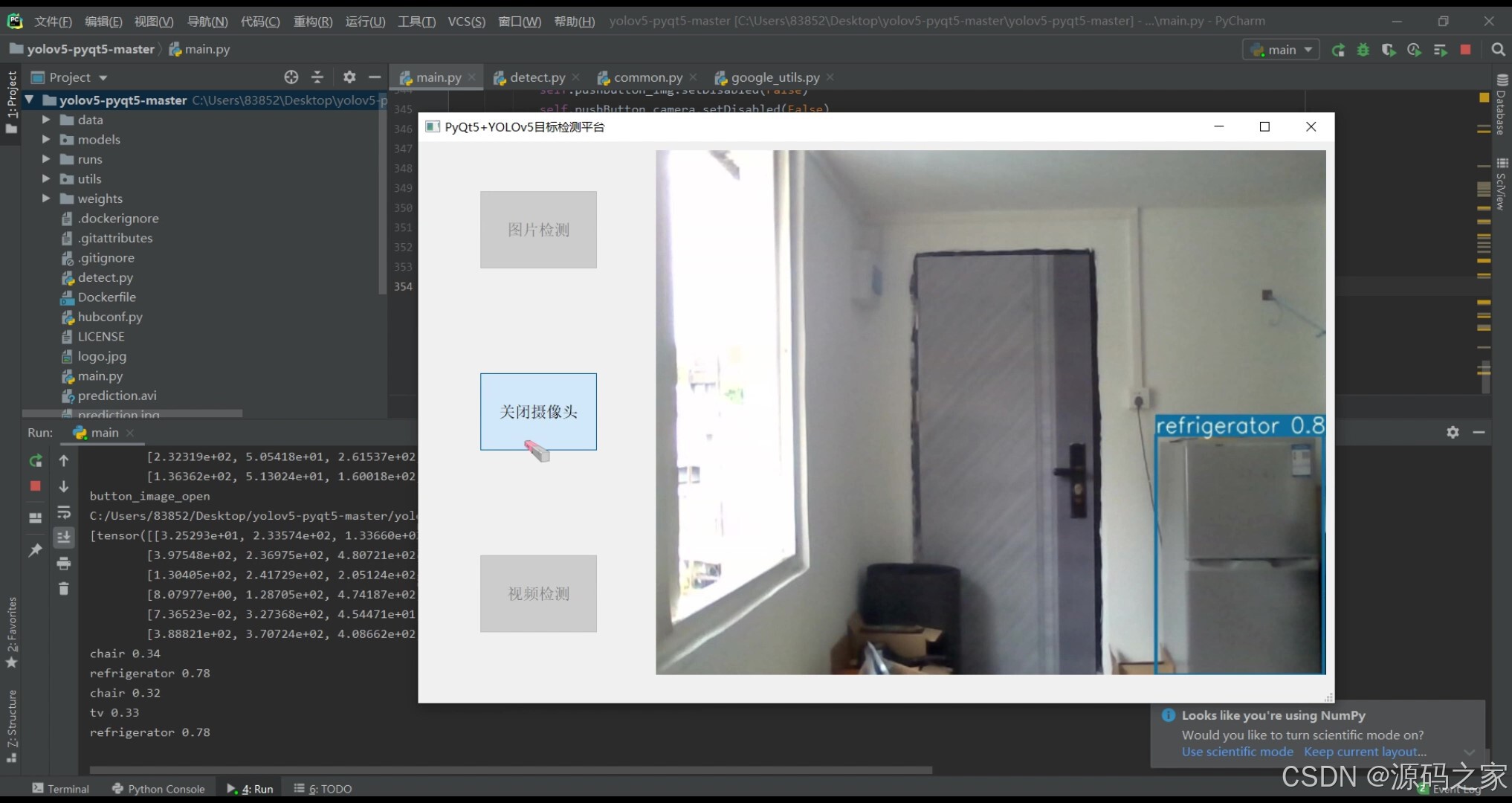
(2)摄像头实时检测–识别冰箱等
(3)视频检测
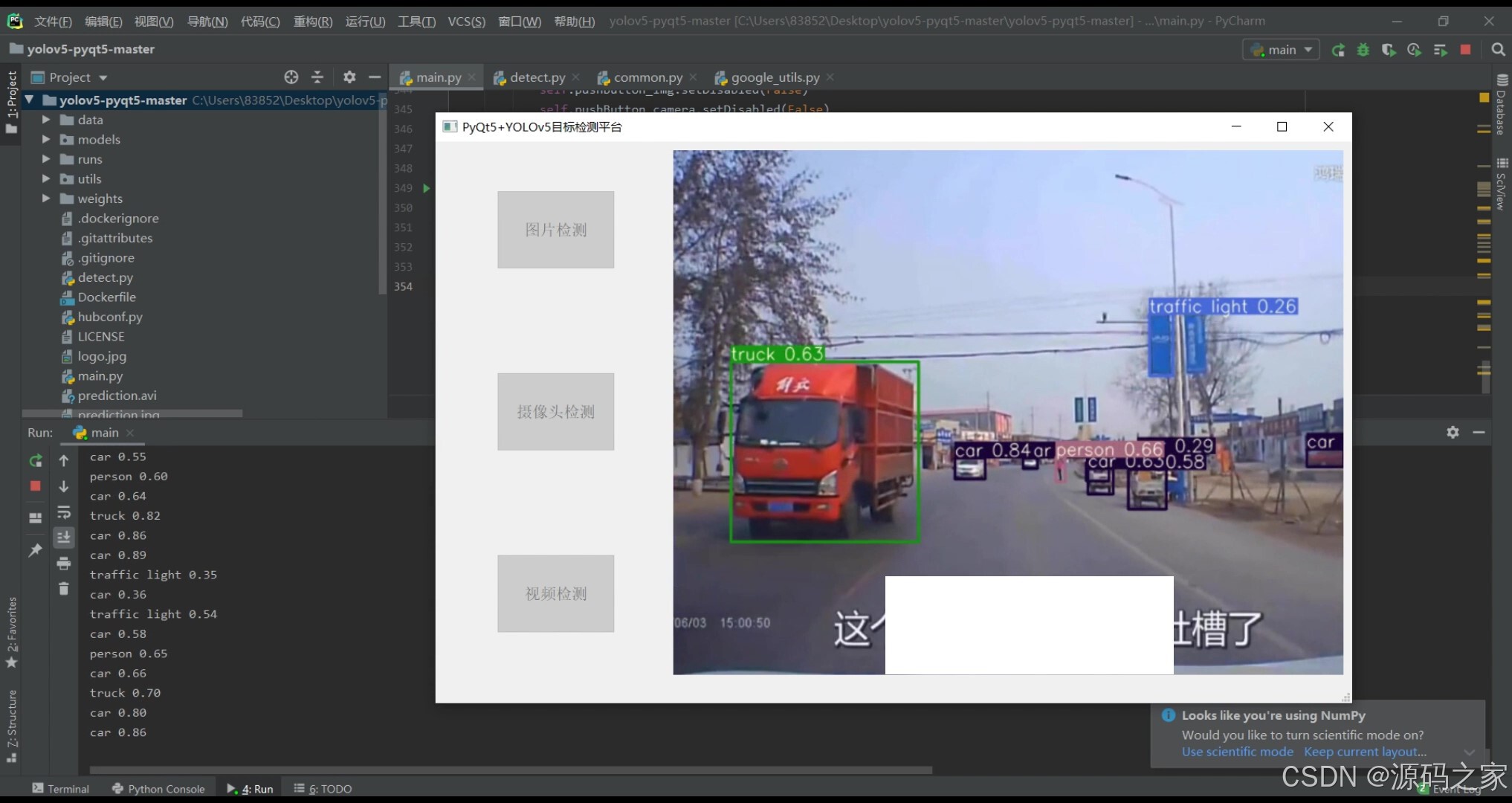
(5)视频检测识别
3、项目说明
基于PyQt5与YOLOv5的目标检测平台项目介绍
一、项目概述
本项目是一个智能化、多功能的目标检测平台,采用Python语言开发,结合PyQt5框架构建用户界面,集成YOLOv5深度学习模型与PyTorch框架实现高效目标检测。平台支持图片上传检测、摄像头实时检测、视频文件检测三大核心功能,可精准识别人、汽车、自行车、摩托车、书包、冰箱等多样化目标物体,广泛应用于安防监控、智能交通、生活场景分析等领域。
二、技术栈与核心组件
Python语言:作为项目开发的基础语言,负责算法调用、数据处理及界面逻辑实现。
PyQt5框架:构建直观、易用的图形用户界面,提供文件上传、摄像头调用、视频播放等交互功能。
YOLOv5模型:采用先进的深度学习目标检测算法,具有高精度、高速度的特点,支持多类别目标识别。
PyTorch框架:作为YOLOv5的底层深度学习框架,提供模型训练、推理及优化支持。
OpenCV库:辅助图像处理,实现图像预处理、后处理及可视化展示。
三、项目功能与界面展示
本项目具备三大核心功能,满足不同场景下的目标检测需求:
图片上传检测
用户可通过界面上传本地图片,系统调用YOLOv5模型对图片进行目标检测,识别并标注出图中的人、汽车、自行车、摩托车、书包等目标物体。
界面展示:
示例图(1)、(2)展示了平台对上传图片的检测效果,目标物体被准确标注,类别信息清晰可见。
摄像头实时检测
平台支持调用电脑摄像头或外部摄像头设备,实现实时视频流的目标检测。用户可观察摄像头画面中的动态目标,如行人、车辆、冰箱等,系统实时标注并显示检测结果。
界面展示:
示例图(3)展示了摄像头实时检测效果,画面中的冰箱等目标被准确识别并标注。
视频文件检测
用户可上传本地视频文件,平台对视频逐帧进行目标检测,生成带有检测结果的视频输出。用户可观看检测后的视频,观察目标物体在视频中的动态变化。
界面展示:
示例图(4)、(5)展示了视频检测效果,视频中的目标物体被持续、准确地识别并标注,检测结果直观明了。
四、项目优势与特点
高精度检测:采用YOLOv5模型,实现多类别目标的高精度识别,检测结果准确可靠。
实时性处理:优化算法与硬件加速,确保摄像头实时检测与视频检测的高帧率处理,满足实时性需求。
用户友好界面:PyQt5构建的图形界面简洁直观,操作便捷,降低用户使用门槛。
多功能集成:集成图片、摄像头、视频三大检测功能,满足不同场景下的目标检测需求。
可扩展性强:基于模块化设计,易于扩展新的检测功能或集成其他深度学习模型。
五、项目应用场景
安防监控:实时检测监控画面中的异常目标,如入侵者、可疑物品等,提升安防效率。
智能交通:检测道路上的车辆、行人等目标,为交通管理、事故预警提供数据支持。
生活场景分析:分析家庭、商场等场景中的目标物体,如冰箱、商品等,为智能家居、零售分析提供解决方案。
本项目是一个功能强大、应用广泛的目标检测平台,结合了深度学习技术与用户友好界面,为各行各业提供智能化、高效化的目标检测解决方案。
4、核心代码
import argparse
import time
from pathlib import Pathimport cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import randomfrom models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronizeddef detect(save_img=False):source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_sizesave_img = not opt.nosave and not source.endswith('.txt') # save inference imageswebcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))# Directoriessave_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir# Initializeset_logging()device = select_device(opt.device)half = device.type != 'cpu' # half precision only supported on CUDA# Load modelmodel = attempt_load(weights, map_location=device) # load FP32 modelstride = int(model.stride.max()) # model strideimgsz = check_img_size(imgsz, s=stride) # check img_sizeif half:model.half() # to FP16# Second-stage classifierclassify = Falseif classify:modelc = load_classifier(name='resnet101', n=2) # initializemodelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()# Set Dataloadervid_path, vid_writer = None, Noneif webcam:view_img = check_imshow()cudnn.benchmark = True # set True to speed up constant image size inferencedataset = LoadStreams(source, img_size=imgsz, stride=stride)else:dataset = LoadImages(source, img_size=imgsz, stride=stride)# Get names and colorsnames = model.module.names if hasattr(model, 'module') else model.namescolors = [[random.randint(0, 255) for _ in range(3)] for _ in names]# Run inferenceif device.type != 'cpu':model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run oncet0 = time.time()for path, img, im0s, vid_cap in dataset:img = torch.from_numpy(img).to(device)img = img.half() if half else img.float() # uint8 to fp16/32img /= 255.0 # 0 - 255 to 0.0 - 1.0if img.ndimension() == 3:img = img.unsqueeze(0)# Inferencet1 = time_synchronized()pred = model(img, augment=opt.augment)[0]# Apply NMSpred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)t2 = time_synchronized()# Apply Classifierif classify:pred = apply_classifier(pred, modelc, img, im0s)# Process detectionsfor i, det in enumerate(pred): # detections per imageif webcam: # batch_size >= 1p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.countelse:p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)p = Path(p) # to Pathsave_path = str(save_dir / p.name) # img.jpgtxt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txts += '%gx%g ' % img.shape[2:] # print stringgn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwhif len(det):# Rescale boxes from img_size to im0 sizedet[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()# Print resultsfor c in det[:, -1].unique():n = (det[:, -1] == c).sum() # detections per classs += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string# Write resultsfor *xyxy, conf, cls in reversed(det):if save_txt: # Write to filexywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywhline = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label formatwith open(txt_path + '.txt', 'a') as f:f.write(('%g ' * len(line)).rstrip() % line + '\n')if save_img or view_img: # Add bbox to imagelabel = f'{names[int(cls)]} {conf:.2f}'plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)# Print time (inference + NMS)print(f'{s}Done. ({t2 - t1:.3f}s)')# Stream resultsif view_img:cv2.imshow(str(p), im0)cv2.waitKey(1) # 1 millisecond# Save results (image with detections)if save_img:if dataset.mode == 'image':cv2.imwrite(save_path, im0)else: # 'video' or 'stream'if vid_path != save_path: # new videovid_path = save_pathif isinstance(vid_writer, cv2.VideoWriter):vid_writer.release() # release previous video writerif vid_cap: # videofps = vid_cap.get(cv2.CAP_PROP_FPS)w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))else: # streamfps, w, h = 30, im0.shape[1], im0.shape[0]save_path += '.mp4'vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))vid_writer.write(im0)if save_txt or save_img:s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''print(f"Results saved to {save_dir}{s}")print(f'Done. ({time.time() - t0:.3f}s)')if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcamparser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--view-img', action='store_true', help='display results')parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')parser.add_argument('--nosave', action='store_true', help='do not save images/videos')parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')parser.add_argument('--augment', action='store_true', help='augmented inference')parser.add_argument('--update', action='store_true', help='update all models')parser.add_argument('--project', default='runs/detect', help='save results to project/name')parser.add_argument('--name', default='exp', help='save results to project/name')parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')opt = parser.parse_args()print(opt)check_requirements(exclude=('pycocotools', 'thop'))with torch.no_grad():if opt.update: # update all models (to fix SourceChangeWarning)for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:detect()strip_optimizer(opt.weights)else:detect()🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻