基于 ComfyUI 的 Stable Diffusion 本地部署与使用教程(Windows + CUDA12.0)
前言
随着生成式人工智能技术的迅猛发展,基于 ComfyUI 的节点化工作流正成为图像创作的新趋势。ComfyUI 不仅采用了直观可视化的「搭砖块」方式来构建生成流程,而且能够灵活加载诸如 Stable Diffusion v1.5 这样强大的扩散模型,从而在本地 GPU 环境中高效、安全地生成高质量图像。本文旨在面向 Windows + CUDA 12.0 + cuDNN 8.9 环境,结合 Python 3.11.3,提供一份详细、清晰的 ComfyUI 配置与使用指南。无论你是初次尝试 AI 绘画还是希望搭建一个可扩展的本地创作平台,都可按本教程逐步操作,真正实现「在本地运行、可控生成、多模型切换」的创作体验。
一、环境准备
1. 安装 Python 、Git 、CUDA 与 cuDNN。
-
安装 Python
在安装 Python 3.11.3(以及上版本)时,如果你懒得手动配置环境变量,一定要在安装程序最开始的一个界面上勾选 “Add python.exe to PATH” 这个选项。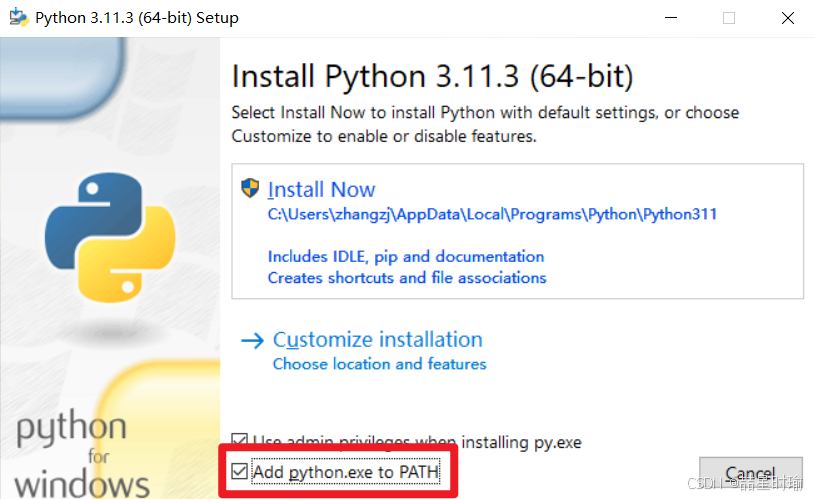
检验python安装结果。
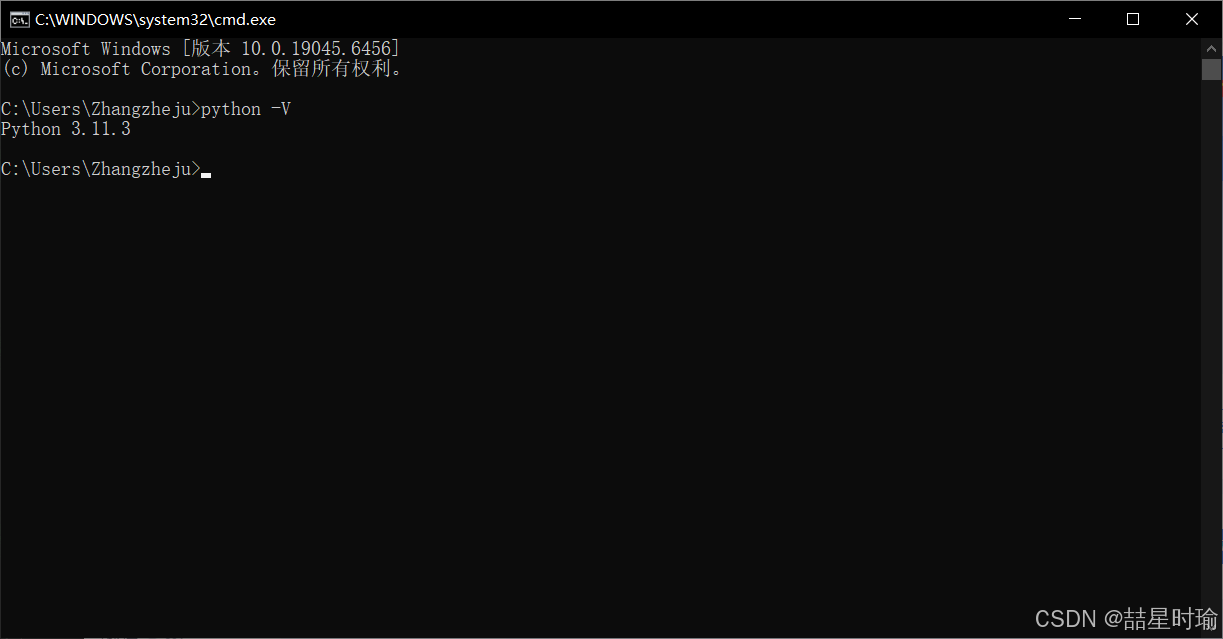
-
安装 Git (用于从 GitHub 中克隆源码)
对于小白:Git安装教程直接搜索一下吧,顺带看一下Git的使用教程。
-
安装CUDA 与 cuDN
本人已安装 CUDA 12.0 与 cuDNN 8.9(CUDA12.0以及对应版本cuDNN详细安装教程)
2. 安装支持 CUDA 的 PyTorch
若有旧版本PyTorch先卸载可能已安装的版本:
pip uninstall torch torchvision torchaudio
然后安装支持 CUDA 11.8 的 PyTorch 版本(示例命令,你可根据 CUDA 12.0 查找更合适的版本,但很多教程推荐 cu118):
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
这一步确保 PyTorch 能调用你的 GPU。
注意:本人虽然用的是 CUDA 12.0,但是官方 whl 可能没有 “cu120” 分类,所以此时选择了用 cu118 这个常见且可用的方案。
二、克隆 ComfyUI 源码 + 安装依赖
1. 克隆 ComfyUI 源码
通过Github网址你可以看到 ComfyUI 源码 内容。我们需要将源码通过Git进行拉取
于目标文件夹内右键打开 Open Git Bash here
输入指令,等待拉取。
git clone https://github.com/comfyanonymous/ComfyUI
✅拉取完成
2. 安装依赖
进入源码 ComfyUI 根目录后,执行:
pip install -r requirements.txt
等待时间可能较长。
二、配置 Stable Diffusion 模型 v1.5 + ❗❗ 启动 ComfyUI
1. 下载模型
下载 StableDiffusion v1.5 模型:
https://hf-mirror.com/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.safetensors直接复制链接通过浏览器打开进行下载,此处使用的是huggingface镜像下载链接,提高下载速度。请确保你已成功下载
v1-5-pruned.safetensors文件。
2. 放置模型至 ComfyUI 目录
在 ComfyUI 源码目录下新建目录(如尚未有):
ComfyUI\models\checkpoints\
将你下载的 v1-5-pruned.safetensors 放入 models\checkpoints\ 文件夹。
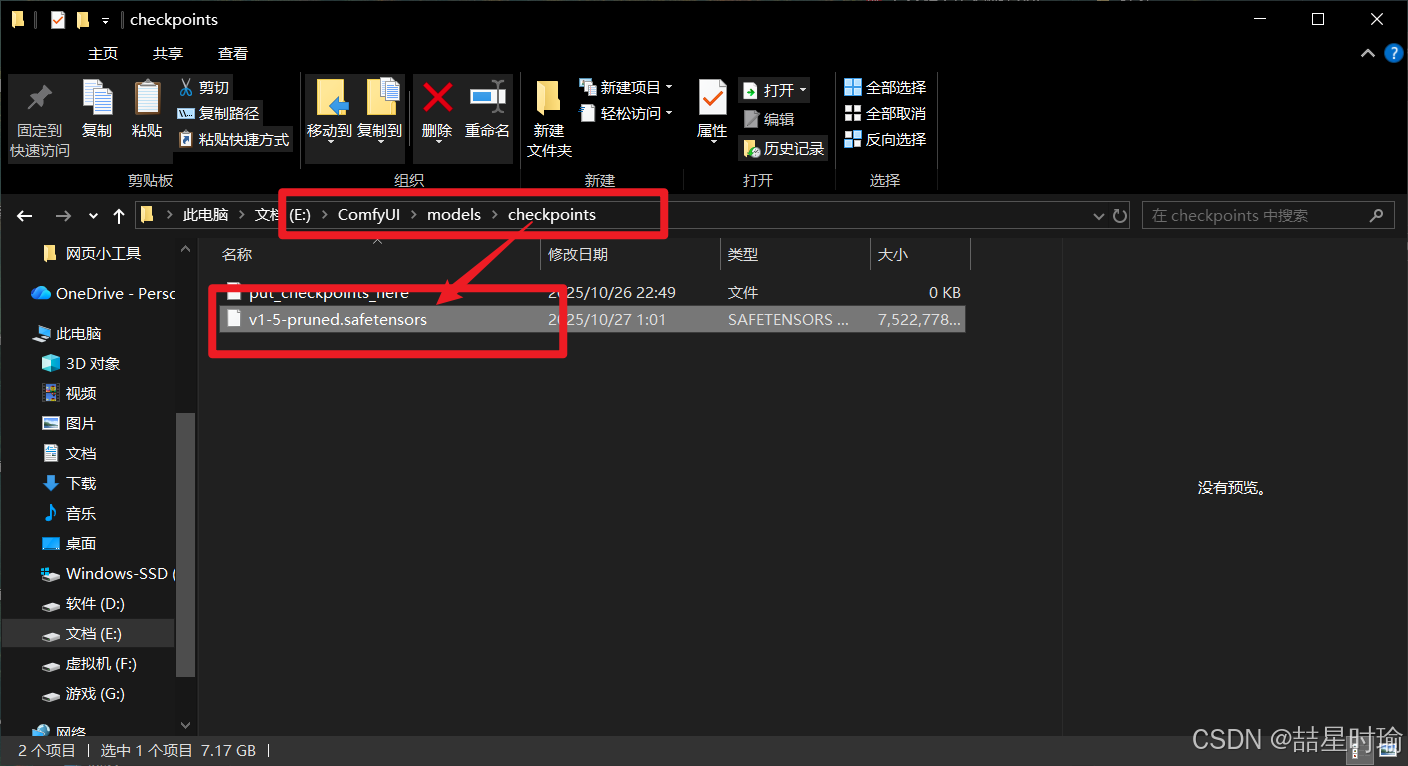
注:“将下载的模型文件放在 …\models\checkpoints 文件夹”
建议你对于版本管理,可以再在 checkpoints 下建子文件夹,例如:models\checkpoints\SD1.5\这样便于管理多个模型版本。
3. ❗❗ 启动 ComfyUI 并验证模型可用
在 ComfyUI 源码根目录执行(命令行):
python main.py
✅如果一切正常,命令行会显示类似:
To see the GUI go to: http://127.0.0.1:8188
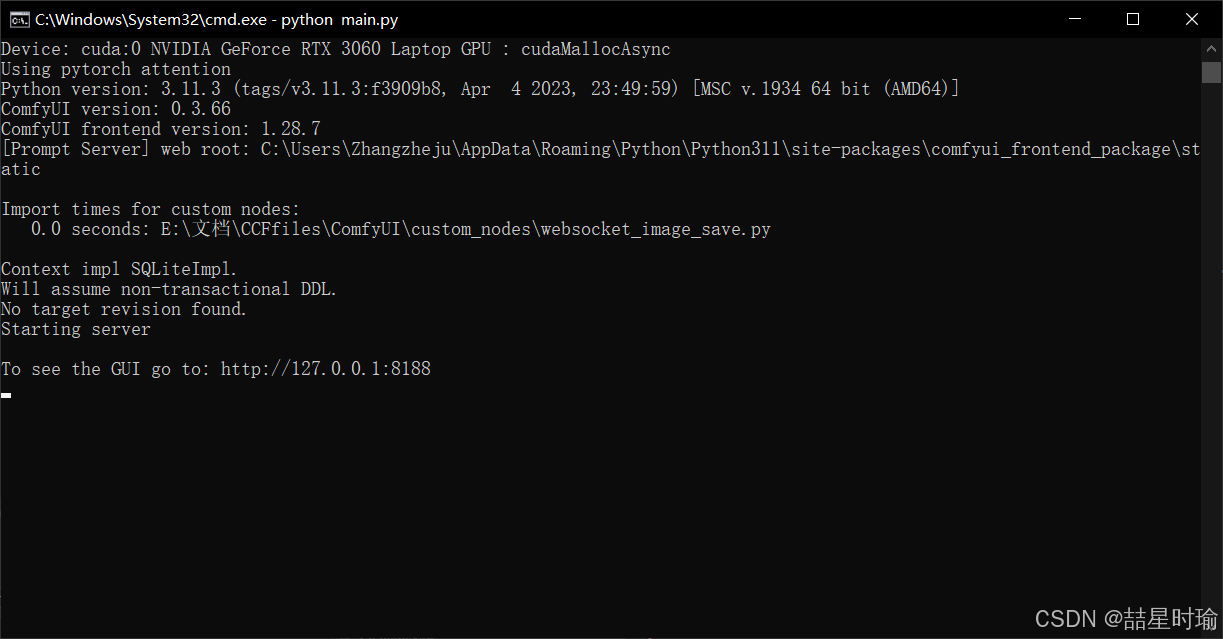
✅在浏览器中打开对应网址 http://127.0.0.1:8188/ 后,恭喜你已经完成安装并且成功打开。打开的页面情况如下。
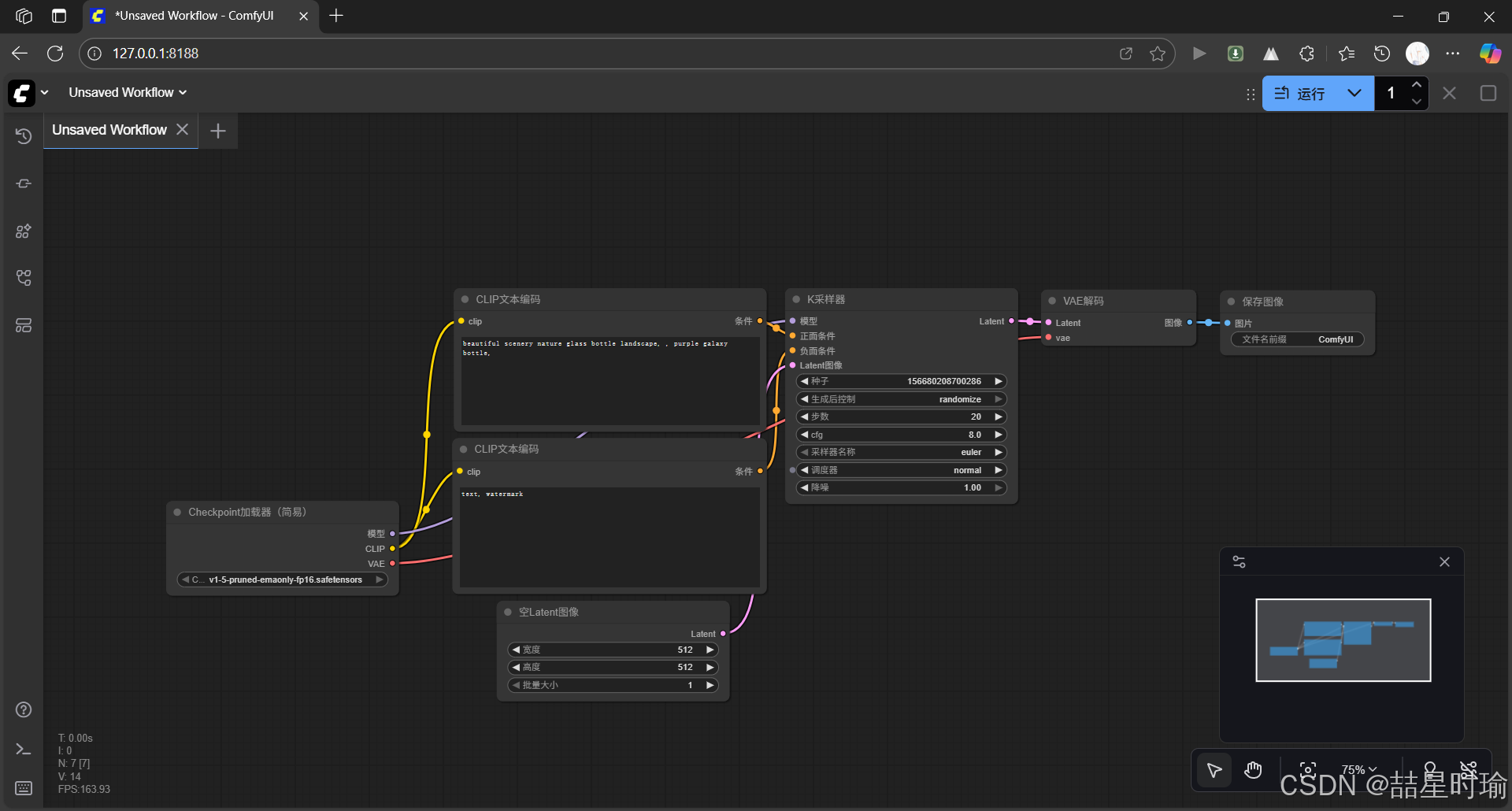
(端口可能默认为 8188)
打开浏览器访问http://localhost:8188,如果看到 ComfyUI 界面即启动成功。
此时,在界面中选中 “Load Checkpoint” 节点,应当可见你放入的v1-5-pruned.safetensors模型选项。若不可见,请检查文件是否放在正确目录。
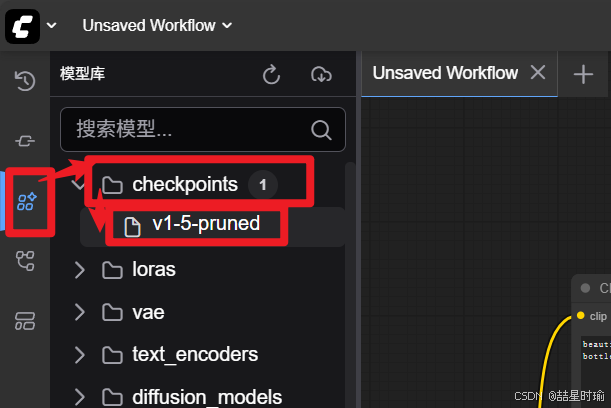
❗❗如果你只是为了安装配置ComfyUI与Stable Diffsion模型,到这一步就可以了。
❗❗如果你只是为了安装配置ComfyUI与Stable Diffsion模型,到这一步就可以了。
❗❗如果你只是为了安装配置ComfyUI与Stable Diffsion模型,到这一步就可以了。
可以看一下 下文的 “三、(可选)安装 ComfyUI Manager(管理自定义节点)” 如果扩展节点、插件、自定义工作流,安装 ComfyUI Manager 很有用。
对于 “四、(使用)首次运行文本→图像(Text-to-Image)流程” 涉及使用,本人还没有完全弄明白操作流程,建议去别处再看看。
三、(可选)安装 ComfyUI Manager(管理自定义节点)
虽然你只是想简单用 Stable Diffusion 生成图像,但如果未来想扩展节点、插件、自定义工作流,安装 ComfyUI Manager 很有用。通过Github网址你可以看到 ComfyUI-Manager 源码 内容。我们需要将源码通过Git拉取到custom_nodes文件夹中。
- 于custom_nodes文件夹内右键打开 Open Git Bash here。(或者通过github直接下载压缩包解压后放入)
- 输入指令,等待拉取。
git clone https://github.com/ltdrdata/ComfyUI-Manager.git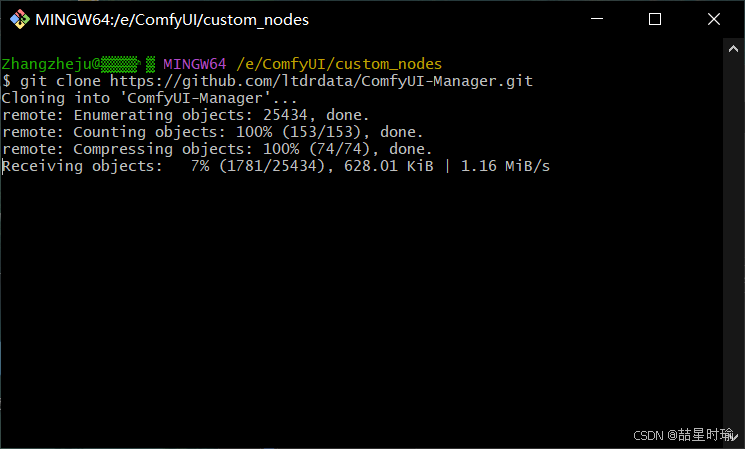
- ✅拉取完成
- 重启 ComfyUI 界面(关闭命令行窗口后重新执行
python main.py) - 界面顶部应出现 “Manager” 按钮,用于安装/更新节点、模型。
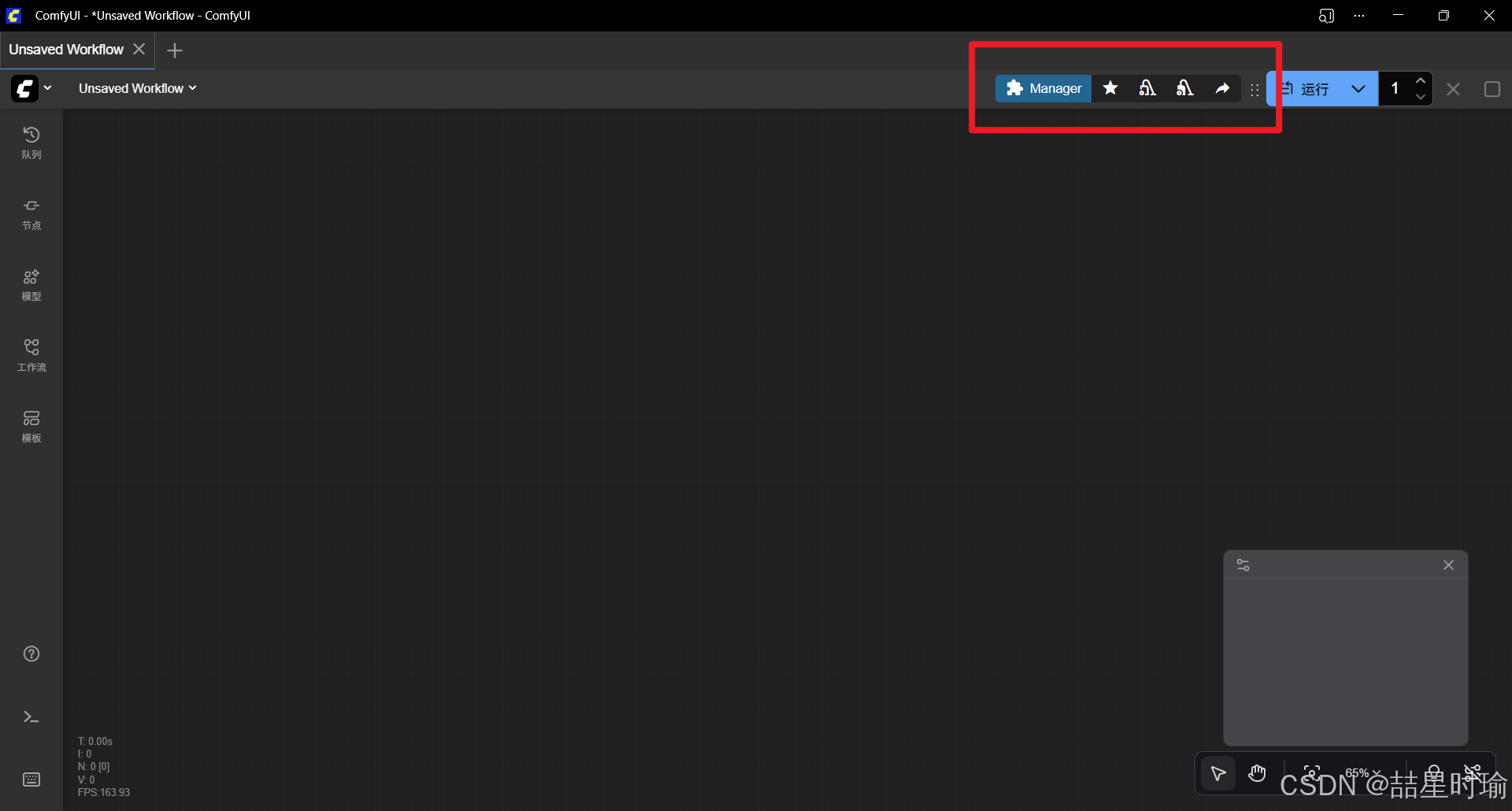
注意:如果未显示 Manager,可能是 Git 未安装或任务目录结构不正确。
也可能是 toml 缺少依赖。在custom_nodes文件夹中运行cmd添加依赖。
pip install toml GitPython requests packaging
四、(使用)首次运行文本→图像(Text-to-Image)流程
以下流程基于你已将 v1.5 模型加载成功。
1. 在 ComfyUI 界面中,加载默认工作流
- 如果界面打开后看不到任何节点图,可以点击右侧 “Load Default” 按钮,加载默认 text2img 工作流。
2. 确保 “Load Checkpoint” 节点已指向你的 SD1.5 模型
- 点击该节点,模型名称下拉框应显示你之前放入的 v1-5-pruned 模型,选择它。
3. 配置生成参数
- 在节点 “KSampler” 或类似节点中,设置步数(Steps)、分辨率(如 512×512)、随机种子(Seed)、正向提示(Positive Prompt)和负向提示(Negative Prompt)等。
根据教程,步数越高、采样越充分,但运行时间越长。 - 确保分辨率适合你的 GPU VRAM(例如 512×512 或 768×768 若 VRAM 足够)。
4. 点击 “Queue Prompt” 或 “Run” 开始生成
- 系统将运行采样,输出图像。
- 输出完成后,可在 ComfyUI 界面中查看、保存图像。
5. 进阶:尝试 Img2Img、Upscale、ControlNet 等
- 若想更复杂,可尝试基于图片输入 (Img2Img)、使用放大器 (Upscale)、加入 ControlNet 等节点。教程中亦有介绍。
6. 常见问题排查
- 若模型不出现在下拉框:确认模型文件是否在正确路径、是否为支持格式 (.ckpt 或 .safetensors)。
- 若启动失败或报错:确认 PyTorch 是否正确安装、CUDA 驱动是否匹配、Python 环境是否为你预期版本。
- 若 GPU 占用过高或出错:可尝试 “–force-fp16” 启动选项以降低精度。
五、推荐的补充配置与优化
-
建议为不同模型版本创建子目录(比如 SD1.5、SDXL 等)以便今后管理。
-
可通过 ComfyUI Manager 安装额外的自定义节点(如 LoRA、ControlNet、Live Portrait 等),扩展功能。
-
如果你希望 ComfyUI 界面从局域网其他设备访问,可在启动时加参数:
python main.py --listen 0.0.0.0这样可使用机器的 IP 在同一网段浏览。
-
若想让 Python 环境更可控,建议使用 virtualenv 或 conda 方式,而不是系统全局安装。
-
对于 VRAM 较少的显卡,可考虑减少生成分辨率或步数,或启用 fp16 模式。
-
定期从 GitHub 更新 ComfyUI 源码:
git pull pip install -r requirements.txt或通过 ComfyUI Manager 进行“Update All”。
六、完整操作流程(按顺序)
- 安装 Python 3.11.3、Git、CUDA 12.0 与 cuDNN 8.9。
- 安装 GPU 支持版 PyTorch。
- 克隆 ComfyUI 仓库。
- 安装依赖:
pip install -r requirements.txt。 - 下载 Stable Diffusion v1.5 模型文件(如
v1-5-pruned.safetensors)。 - 将模型文件放入
ComfyUI\models\checkpoints\目录。 - 启动 ComfyUI:
python main.py。 - 在浏览器访问 http://localhost:8188 界面打开。
- 加载默认工作流,选择模型,设置参数。
- 点击运行,生成图像。
- (可选)安装 ComfyUI Manager,扩展节点功能。
- 根据需要,通过 Manager 或手动更新、安装自定义节点。
- 若扩展到 Img2Img、Upscale、ControlNet,可加载相应流程并调整节点。
- 若想跨设备访问,启动时加
--listen 0.0.0.0。 - 若模型或节点有更新,定期
git pull并重启。
七、注意事项
- 模型版权/许可:你下载的模型需确认其使用许可。
- GPU VRAM 限制:高分辨率、高步数会占用大量 GPU 内存,建议先从 512×512、50 步数起。
- 操作系统权限:Windows 防火墙可能阻止 ComfyUI 端口访问,首次运行时注意允许。
- 安全备份:如果你未来安装大量自定义节点/模型,建议经常备份
models文件夹与 custom_nodes 目录。 - 故障排查时可参考CSDN。
八、总结
通过上述流程,你即可在 Windows + CUDA 12.0 + cuDNN 8.9 环境下,使用 Python 3.11.3 来运行 ComfyUI 并加载 Stable Diffusion v1.5 模型。这样你就拥有一个本地、可控、支持 GPU 的生成式 AI 图像创作平台。以后如想扩展为 Img2Img、多模型切换、ControlNet、LoRA 等,也可在此基础上继续扩展。
转载吱一声~