机器人中的多模态——RoboBrain
论文下载地址:arxiv.org/pdf/2502.21257
代码地址:https://github.com/FlagOpen/RoboBrain/
数据集下载地址:https://github.com/FlagOpen/ShareRobot/
目录
- 1.关于RoboBrain
- 1.1 RoboBrain的潜在应用场景
- 1.2 RoboBrain具备哪些能力
- 2.关于ShareRobot数据集
- 2.1 ShareRobot的主要特性
- 2.2 ShareRobot数据集筛选标准
- 2.3 ShareRobot数据标注流程
- 2.4 ShareRobot数据构造过程
- 2.5 ShareRobot的动作统计
- 3.RoboBrain的模型结构
- 3.1 总览
- 3.2 规划模型
- 3.3 可供性感知和轨迹预测
- 4.RoboBrain的训练流程
- 4.1 Phase1通用 OV 训练
- 4.2 Phase2机器人训练
- 5.RoboBrain的可视化推理结果
- 6.代码推理过程
1.关于RoboBrain
1.1 RoboBrain的潜在应用场景
- 智能家居领域:在智能家居场景中,机器人需要理解人类的自然语言指令并完成复杂任务。比如将“整理客厅”这样的抽象指令分解为具体子任务,如识别并捡起地上的物品、将物品分类放置到相应位置等。通过物体可供性感知,它能确定不同物品的抓取位置,预测机械臂的操作轨迹,精准地拿起和放置物品,实现客厅的自动整理,提升家居生活的便利性和智能化程度。
- 工业制造领域:在工业生产线上,机器人需要执行高精度的操作任务。比如可以根据生产任务的要求,规划机器人的动作序列,比如在零件组装任务中,准确规划机械臂抓取不同零件的顺序和路径。利用物体可供性感知,它能快速识别零件的可抓取部位,结合轨迹预测,确保机械臂准确地抓取和组装零件,提高生产效率和产品质量,降低生产成本。
- 物流仓储领域:物流仓储场景下,机器人需要在复杂环境中搬运和分拣货物。比如通过理解任务指令,规划最优的搬运路径,避免与障碍物碰撞。通过对货物和货架的可供性感知,确定合适的抓取点和放置位置预测搬运过程中的轨迹,高效地完成货物的搬运和分拣任务,提升物流仓储的自动化水平和运营效率。
1.2 RoboBrain具备哪些能力
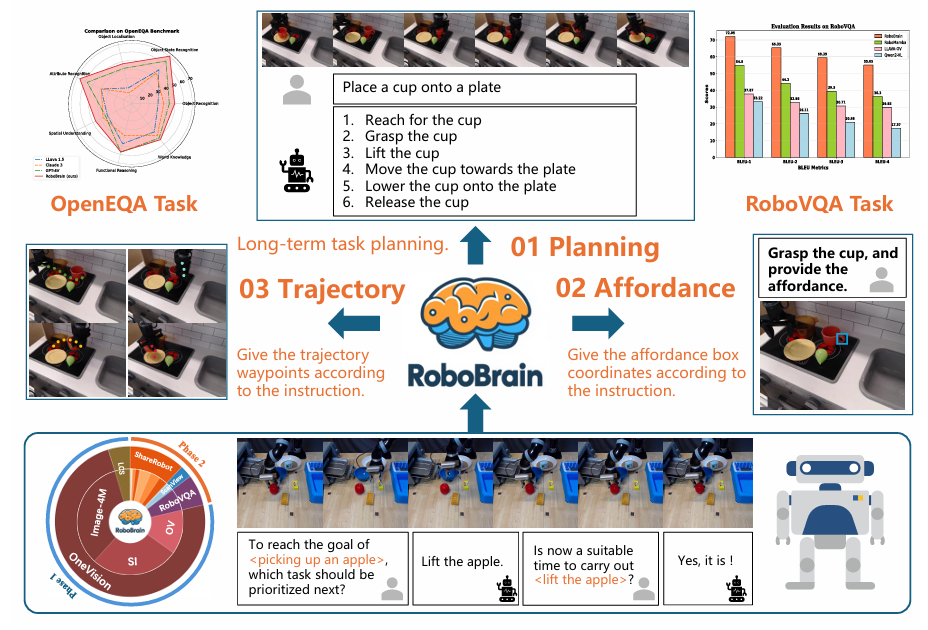
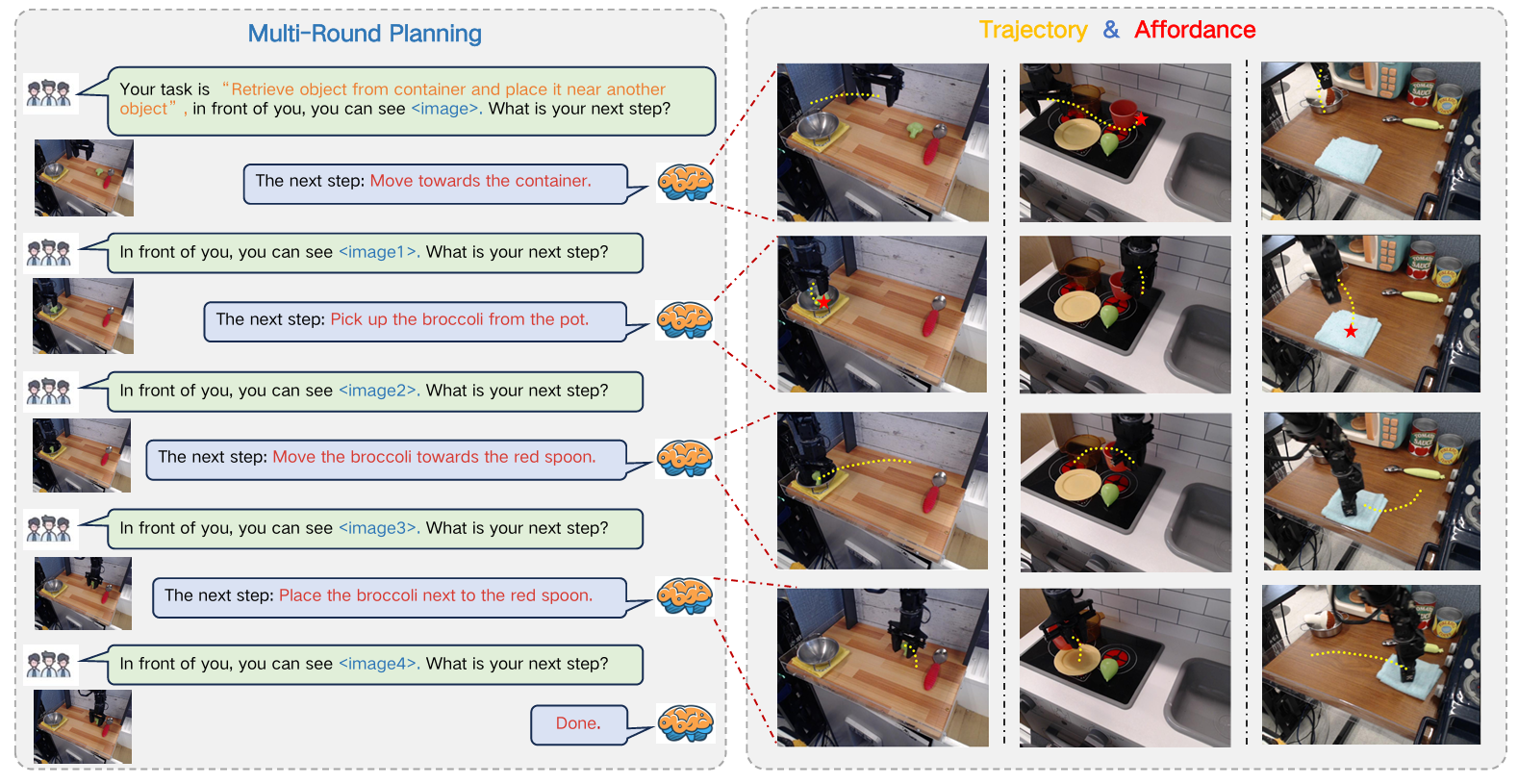
- 1.(Planning)长距离操作任务规划:可将复杂操作指令分解为一系列易于管理的子任务,如在“将杯子放到盘子上”任务中,能依次规划出“伸手拿杯子”“抓住杯子”“抬起杯子”“将杯子移向盘子”“把杯子放在盘子上”“松开杯子”等子任务,合理安排执行顺序,确保任务高效完成。在“用茶壶倒水进杯子”任务里,它能把任务分解为“靠近并拿起茶壶”“移动茶壶使壶嘴对准杯子”“倾斜茶壶倒水”等步骤,展现出强大的任务规划能力。
- 2.(Affordance)物体可供性感知:能够识别和解释交互对象的可供性,确定人类手与物体接触的区域,并用边界框表示。面对“用瓶子喝水”指令时,它能判断瓶子盖处于关闭状态,并提供瓶盖区域的可供性信息,帮助机器人准确理解与物体交互的可行区域,为后续动作执行提供关键信息。
- 3.(Trajectory)操作轨迹预测:可以预测末端执行器或手在操作过程中的完整轨迹,通过定义轨迹路标点为一系列2D坐标来实现。无论是简单还是复杂的操作,都能依据视觉观察和任务指令准确预测2D轨迹,且预测结果与实际轨迹结构紧密契合,还能通过学习优化执行路径,提高操作效率。在“拿起苹果”任务中,能精准规划从起始位置到苹果位置,再到目标位置的轨迹,确保机器人平稳、准确地完成操作。
- 4.视觉问答任务:在机器人视觉问答(RoboVQA)和开放式环境问答(OpenEQA)等视觉问答任务中表现卓越。能根据机器人所处场景的视觉信息和提出的问题,理解问题含义并给出准确答案,帮助机器人更好地理解环境和任务要求,与人类进行有效交互。在OpenEQA任务中,面对关于环境理解的问题,如“当前场景中是否可以执行某个动作”,它能结合视觉信息和自身知识给出合理判断。
2.关于ShareRobot数据集
1.专为机器人操作任务设计的大规模、细粒度数据集。
2.用于提升RoboBrain的规划、可供性感知以及轨迹预测能力。
2.1 ShareRobot的主要特性
- 1.细粒度(Fine-grained):每个数据点都包含与单个帧相关的详细低级规划指令,提高了模型在正确时间执行任务的准确性。在机器人进行“将物品放置到指定位置”的任务时,ShareRobot数据集能精确到每个动作对应的具体帧,指导机器人何时、以何种方式进行操作。
- 2.多维度(Multi-dimensional):该数据集标注了任务规划、物体可供性和末端执行器轨迹,在任务处理上提供了更大的灵活性和精确性。比如在机器人操作场景中,不仅规划了任务步骤,还明确了物体可被操作的区域以及机械臂的运动轨迹。
- 3.高质量(High quality):从Open-X-Embodiment数据集中筛选数据时建立了严格标准,聚焦于高分辨率、准确描述、任务执行成功、可见的可供性和清晰的运动轨迹。基于这些标准验证了51403个实例,为RoboBrain的核心能力奠定了基础。只有满足高分辨率图像、准确描述等条件的数据才会被纳入,确保数据质量。
- 4.大规模(Largescale):拥有1027990个问答对,是用于任务规划、可供性感知和轨迹预测的最大开源数据集,有助于更深入地理解从抽象到具体的复杂关系。大规模的数据量让模型能够学习到更多的任务模式和场景变化。
- 5.丰富多样性(Rich diversity):与RoboVQA数据集有限的场景不同,ShareRobot具有102个场景,涵盖12种机器人机体和107种原子任务类型(最小的任务单元,如抓取某个物体)。这种多样性使多模态大语言模型能够从各种现实世界场景中学习,增强在复杂多步规划中的稳健性。机器人可以在不同场景、使用不同机体执行多种任务,提升应对复杂情况的能力。
- 6.易扩展性(Easy scalability):数据生成管道设计具有高扩展性,便于随着新的机器人机体、任务类型和环境的发展进行扩展。这一特性确保 ShareRobot 数据集能够支持日益复杂的操作任务。当出现新的机器人类型或任务时,能够方便地添加新数据。
2.2 ShareRobot数据集筛选标准
ShareRobot数据集的数据选择基于 OpenX-embodiment 数据集进行,从中精心挑选了51403个实例,这些实例将作为后续数据标注和模型训练的重要基础。
数据筛选原则
- 高分辨率图像:高分辨率图像能提供更丰富准确的视觉信息。
- 准确描述:模型训练依赖于对任务的准确理解,模糊或缺失的描述会干扰模型学习任务规划。
- 成功状态:丢弃任务失败的视频,失败的任务演示无法为模型提供正确的操作范例,可能误导模型学习。
- 长视频长度:丢弃帧数少于30帧的视频,较短的视频包含的原子任务有限,无法充分展示复杂任务的完整流程,不利于模型学习多步骤操作,长视频能涵盖更丰富的任务动作序列。
- 物体未被覆盖:移除目标物体或末端执行器被其他物体覆盖的视频,模型需要准确识别末端执行器和物体的位置及可供性,被覆盖的情况会增加识别难度,影响模型训练效果。
- 清晰轨迹:不使用轨迹不清晰或不完整的演示数据,不清晰或不完整的轨迹数据会降低模型学习的准确性。
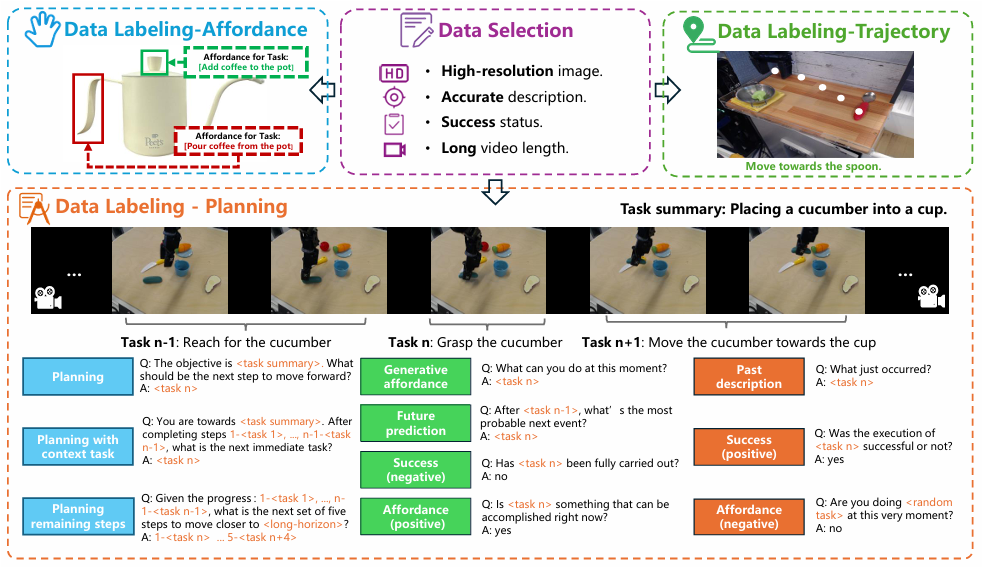
2.3 ShareRobot数据标注流程
- 1.规划标注(PlanningLabeling)
指令分解:从每个机器人操作演示中提取30帧,结合其高级描述,借助Gemini工具将其分解为低级规划指令。为确保标注精确,由三名注释者对这些指令进行审核和完善。在“将杯子放到盘子上”的操作演示里,Gemini可能将其分解为“移动到杯子位置”“抓取杯子”等具体步骤,注释者会检查这些步骤是否准确合理。
生成问答对:针对RoboVQA中的10种问题类型,为每种类型设计5种不同模板。在数据生成过程中,为每个实例随机选择每种问题类型的2个模板来生成问答对。这一操作将51403个实例扩展成了1027990个问答对。比如对于“放置杯子”任务,可能有“目标是放置杯子,下一步该做什么?”等不同模板生成的问题,对应的答案可能是“抓取杯子”等。在生成问答对时,注释者会监控数据生成过程,以维护数据集的完整性。
- 2.可供性标注(Affordance Labeling)
筛选与标注图像:筛选出6522张图像,依据其高级描述,为每张图像标注可供性区域,标注可供性区域的左上角坐标和右下角坐标。对于“拿起杯子”的任务图像,会标注出杯子上适合抓取部位的边界框坐标。
审核与完善:对每个标注指令进行严格的人工审核和细化,保证指令与相关可供性区域精确匹配,提高标注的准确性。
- 3.轨迹标注(Trajectory Labeling)
筛选与标注图像:挑选6870张图像,按照低级指令,为每张图像标注抓手的轨迹,且每条轨迹至少使用三个坐标点表示。在“移动杯子”任务的图像中,会标注出抓手在不同时间点的坐标来描述其运动轨迹。
审核与完善:对每个标注指令进行严格人工审核和细化,确保标注的轨迹与实际操作中的轨迹精确对齐,使标注数据能准确反映机器人的运动路径。
2.4 ShareRobot数据构造过程
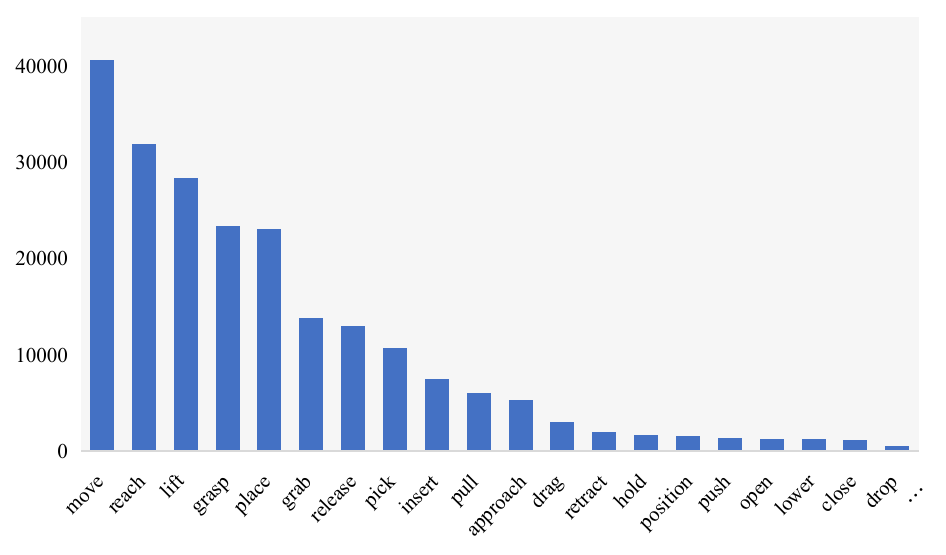
2.5 ShareRobot的动作统计
在ShareRobot数据集中,出现频率最高的前20个原子动作的分布情况。
3.RoboBrain的模型结构
3.1 总览
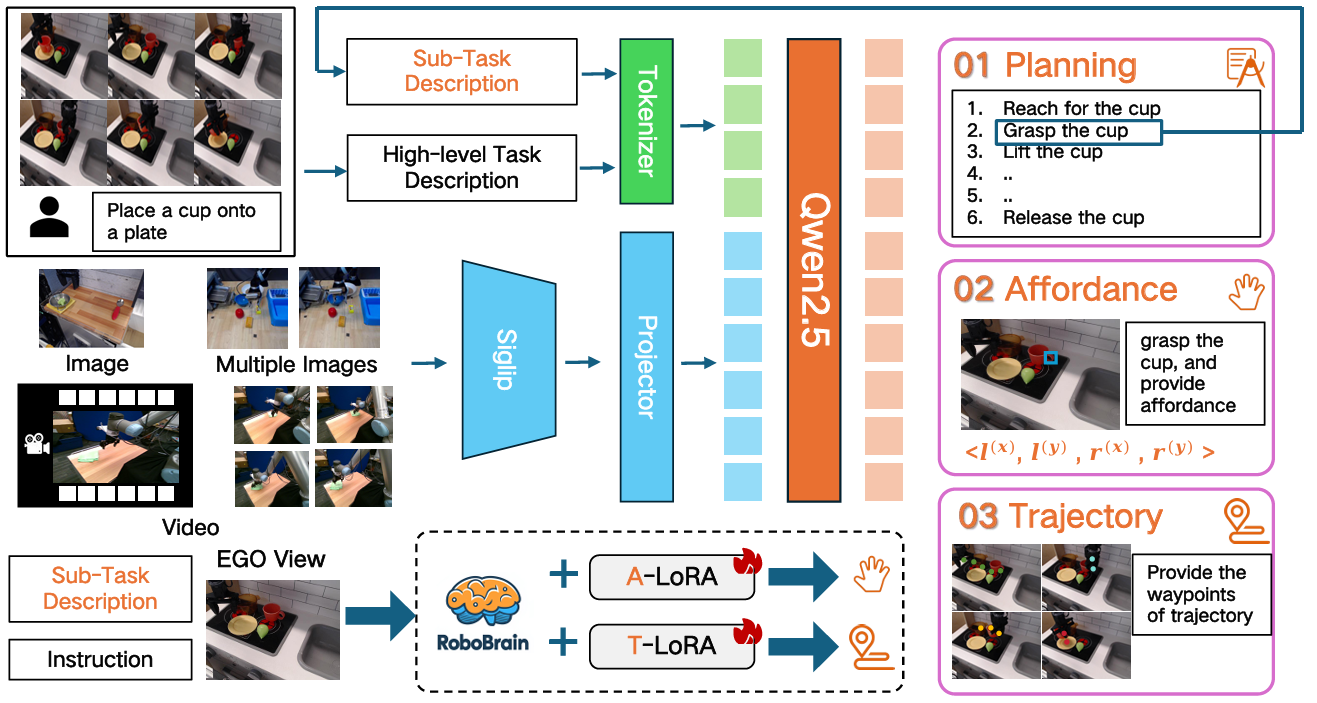
3.2 规划模型
使用LLaVA作为基础框架,由视觉编码器(ViT)、Projectior和大语言模型(LLM)三个主要模块组成。
https://zhuanlan.zhihu.com/p/690526314
- 视觉编码器:采用SigLIP模型(siglip-so400m-patch14-384),它在WebLi数据集上以384x384分辨率进行预训练,通过27个隐藏层,将输入图像按14 x 14大小的补丁处理,生成729个视觉标记,相比传统CLIP架构,SigLIP使用 sigmoid 损失函数,提升了训练效率。
- 投影(Projectior):由2层 MLP 组成,负责将视觉编码器输出的视觉标记投影到文本嵌入的维度,实现视觉特征与语言模型语义空间的对接。
- 大语言模型:采用 Qwen2.5-7B-Instruct,它具有28个隐藏层,支持长达128K令牌的长上下文输入,具备29种以上语言的多语言能力,能基于人类语言指令和视觉标记,以自回归方式生成文本响应,为机器人操作任务提供规划能力。
3.3 可供性感知和轨迹预测
- A-LoRA Module for Affordance Perception
可供性指人类手与物体接触的区域,通过边界框来表示。对于包含多个物体及其可供性的图像,每个物体可能有N个可供性区域。
A-LoRA模块帮助模型识别和解释交互对象的可供性,使机器人能够理解在当前场景下可以对物体进行何种操作,以及在物体的哪些部位进行操作。 - T-LoRA Module for Trajectory Prediction
负责轨迹预测,这里的轨迹指2D视觉痕迹。模型将轨迹路标点定义为一系列2D坐标。根据任务指令和视觉信息预测机器人末端执行器或手在操作过程中的完整轨迹,确保机器人在执行任务时能准确规划运动路径,提高操作的准确性和效率。
4.RoboBrain的训练流程
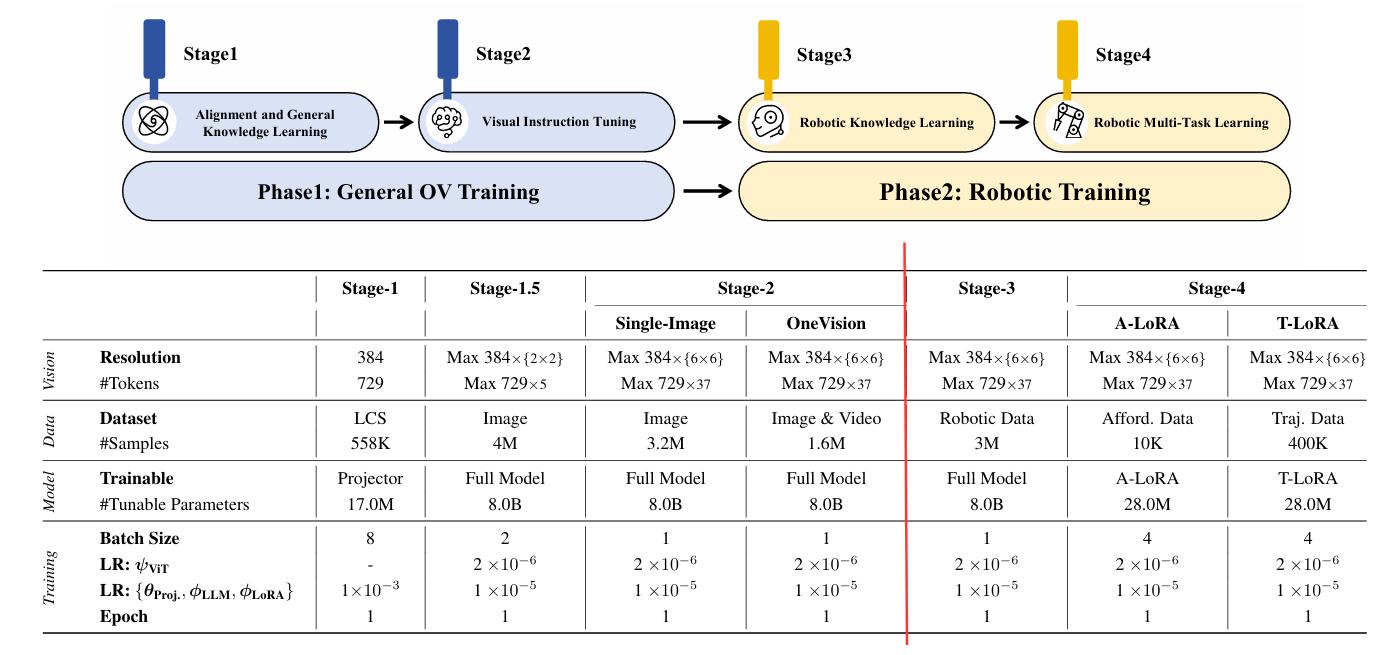
4.1 Phase1通用 OV 训练
借鉴了LLaVA-OneVision的训练数据和策略,构建一个具备通用多模态理解能力和视觉指令跟随能力的基础模型,为在Phase2中提升模型的机器人操作规划能力奠定了基础。
在RoboBrain模型的训练体系里,通用OV训练是重要的起始阶段。它借助已有的优秀训练资源搭建基础:
1.通过特定数据集让Projector能更好地融合视觉与语言特征
2.用大量数据提升模型对多模态知识的理解
3.强化模型对指令的响应以及对高分辨率图像和视频的处理能力,为后续专门针对机器人操作的训练做好准备,逐步提升模型在机器人领域的综合表现
Stage1:利用来自LCS-558K数据的图像文本数据训练Projector,促进视觉特征与大语言模型语义特征对齐。
Stage1.5:使用400万高质量图像文本数据训练整个模型,以增强模型的多模态常识理解能力。
Stage2:进一步使用320万单图像数据以及来自 LLaVA-OneVision-Data 的160万图像和视频数据训练整个模型,旨在提升RoboBrain的指令跟随能力,并增进对高分辨率图像和视频的理解。
4.2 Phase2机器人训练
是RoboBrain模型训练的关键环节,建立在Phase1通用OV训练的基础之上,目的是使RoboBrain能够理解复杂、抽象的指令,支持对历史帧信息和高分辨率图像的感知,准确输出物体的可供性区域,同时预测潜在的操作轨迹,从而实现从抽象指令到具体机器人操作的转化,提升其在机器人操作任务中的性能。
Stage3:收集了130万机器人数据,这些数据来源于RoboVQA800K、ScanView-318K(包含MMScan-224K、3RScan-43K、ScanQA-25K、SQA3d-26K)以及ShareRobot-200K等数据集。这些数据包含丰富的场景扫描图像、长视频和高分辨率数据,能支持模型感知多样环境,其中ShareRobot数据集中的精细高质量规划数据可增强模型的操作规划能力。为解决灾难性遗忘问题,从第一阶段选取约170万高质量图像文本数据与Stage3收集的机器人数据混合训练,并对整个模型进行相应调整。
Stage4:利用ShareRobot数据集及其他开源来源的可供性和轨迹数据,通过在训练过程中引入LoRA模块,增强模型从指令中感知物体可供性和预测操作轨迹的能力,赋予模型具体的操作能力。
5.RoboBrain的可视化推理结果
6.代码推理过程
代码地址:https://github.com/FlagOpen/RoboBrain/