Qwen系列模型:WAN介绍
概述
阿里通义实验室开源视频生成系列模型,之前介绍Qwen系列模型时没有提到WAN,故有此文:
- Qwen家族系列模型概述(一)
- Qwen家族系列模型概述(二)
中文名通义万相,简称万相,英文名WAN。产品独有官网,通义官网。
GitHub开源包括:
- Wan2.1
- Wan2.2
版本:
- 2.1:已开源GitHub和ModelScope
- 2.2:已开源GitHub和ModelScope
- 2.5:目前是预览版,官网可体验
2.1
技术报告
一个全面且开放的视频基础模型套件,在视频生成方面突破现有技术的界限,具备如下关键特性:
- SOTA性能:在多个基准测试中始终优于现有的开源模型和最先进的商业解决方案;
- 支持消费级GPU:T2V-1.3B模型仅需8.19GB显存,使其几乎兼容所有消费级GPU。可在4090上大约4分钟内生成一段5秒的480P视频(不使用量化等优化技术)。其性能甚至可与某些闭源模型相媲美;
- 多种任务:在文本到视频、图像到视频、视频编辑、文本到图像以及视频到音频等方面表现出色,推动了视频生成领域的发展;
- 视觉文本生成:首个能够生成中英文文本的视频模型,具备强大的文本生成功能,增强其实用性;
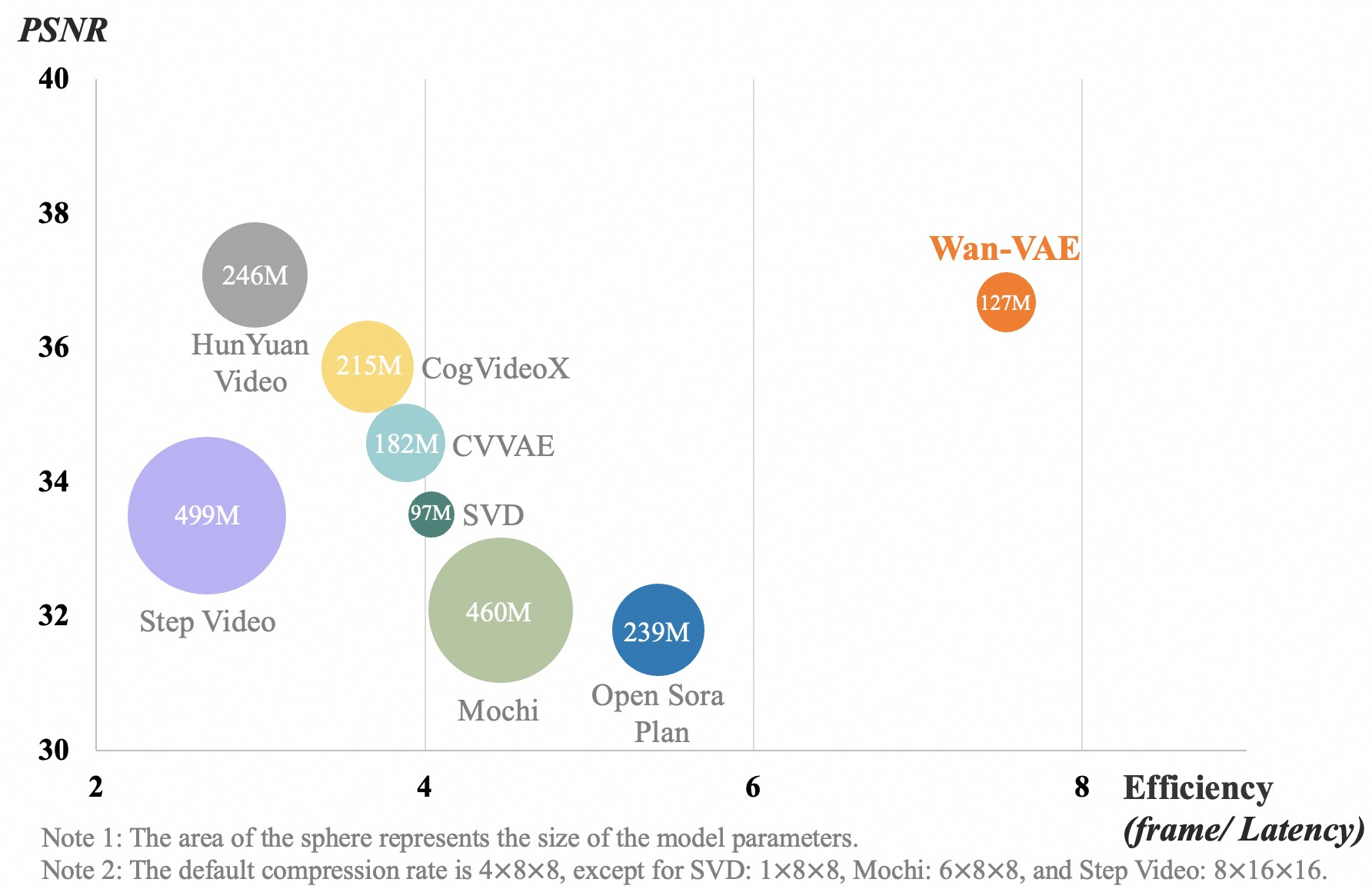
- 强大的视频VAE:Wan-VAE具有卓越的效率和性能,可编码和解码任意长度的1080P视频,并保留时间信息,是视频和图像生成的理想基础。
系列模型:
- 文生视频:T2V,Text to Video
- 视频生成编辑:VACE,用于视频创作和编辑的一体化模型
- 图像生视频:I2V,Image to Video
- FLF2V:First-Last-Frame-to-Video,首尾帧到视频生成,以首帧和尾帧作为控制条件,仅需用户提供两张图像,模型即可自动生成一段5秒720p分辨率视频
| 模型 | HF链接 | MS链接 | 备注 |
|---|---|---|---|
| T2V-1.3B | Huggingface | ModelScope | 支持480P |
| T2V-14B | Huggingface | ModelScope | 支持480P和720P |
| T2V-1.3B-Diffusers | Huggingface | ModelScope | 支持480P |
| T2V-14B-Diffusers | Huggingface | ModelScope | 支持480P和720P |
| I2V-14B-720P | Huggingface | ModelScope | 支持720P |
| I2V-14B-480P | Huggingface | ModelScope | 支持480P |
| FLF2V-14B | Huggingface | ModelScope | 支持720P |
| VACE-1.3B | Huggingface | ModelScope | 支持480P |
| VACE-14B | Huggingface | ModelScope | 支持480P和720P |
备注:
- 1.3B模型能够生成720P分辨率的视频。然而由于在该分辨率下的训练有限,结果通常比480P不稳定。为了获得最佳性能,建议使用480P分辨率;
- 对于FLF2V,模型主要在中文文本-视频对上进行训练,建议使用中文提示。
技术创新
3D变分自编码器
提出新的3D因果VAE架构Wan-VAE(变分自编码器,Variational Auto-Encoder),专门用于视频生成。通过结合多种策略,提高时空压缩效果,减少内存使用,并确保时间因果关系。与其它开源VAE相比,Wan-VAE在性能效率方面表现出显著优势。Wan-VAE可对无限长度的1080P视频进行编码和解码,而不会丢失历史时间信息,使其特别适合视频生成任务。
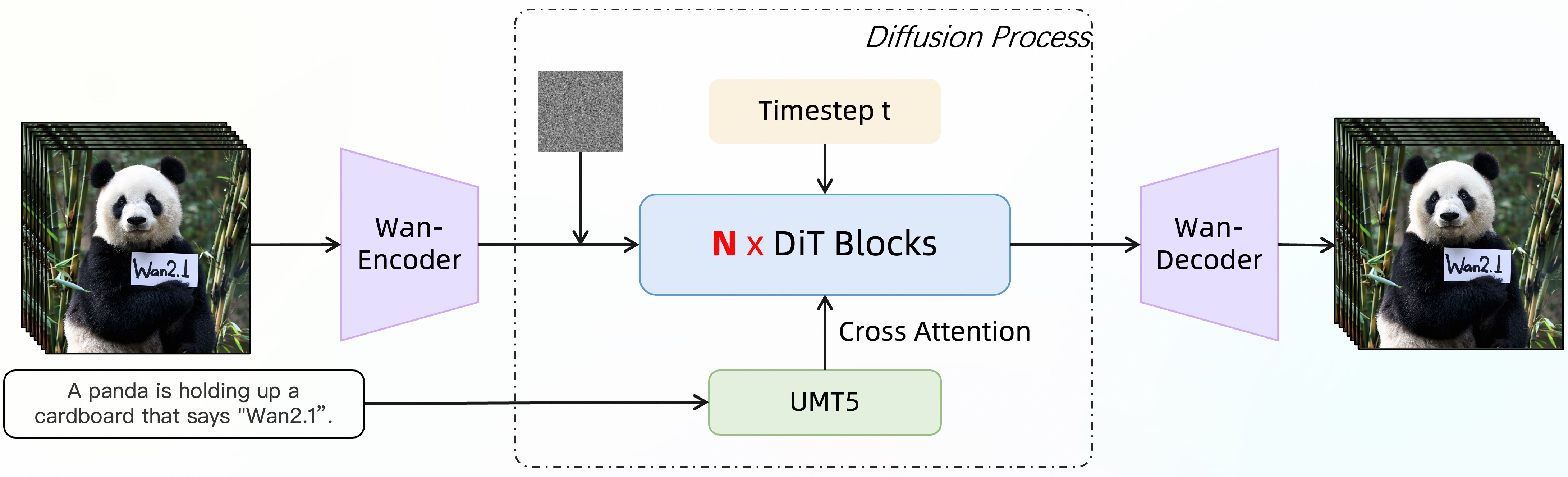
视频扩散DiT
在主流扩散变换器范式的Flow Matching框架下设计的。模型架构使用T5编码器对多语言文本输入进行编码,在每个变换器块中通过交叉注意力将文本嵌入到模型结构中。使用带有线性层和SiLU层的MLP来处理输入的时间嵌入,并分别预测六个调制参数。这个MLP被所有变换器块共享,每个块学习一组独特的偏置。
| 模型 | 维度 | 输入维度 | 输出维度 | 前馈维度 | 频率维度 | 头数 | 层数 |
|---|---|---|---|---|---|---|---|
| 1.3B | 1536 | 16 | 16 | 8960 | 256 | 12 | 30 |
| 14B | 5120 | 16 | 16 | 13824 | 256 | 40 | 40 |
整理并去重一个包含大量图像和视频数据的候选数据集。在数据整理过程中,设计四步的数据清洗流程,重点关注基本维度、视觉质量和运动质量。通过强大的数据处理流水线,可轻松获得高质量、多样化且大规模的图像和视频训练集。
Wan-Bench
用于基准测试Benchmark,涵盖动态质量、图像质量和指令跟随三个核心维度,使用精心设计的1035个内部提示集,包含14个主要维度和26个子维度。
| 维度 | 含义解释 |
|---|---|
| 大范围运动生成(Large Motion Generation) | 评估视频中主体进行大幅度、明显运动的能力,如行走、奔跑、旋转等,而不仅仅是细微动作 |
| 人造物体生成(Human Artifacts) | 评估生成人造物品(如杯子、汽车、家具)的能力,要求结构合理、符合常识 |
| 像素级稳定性(Pixel-level Stability) | 评估视频在像素级别的时间一致性,避免帧间闪烁、噪点或随机像素变化 |
| 身份一致性(ID Consistency) | 评估主体(尤其是人物)在整个视频中保持同一性,避免特征莫名其妙变化 |
| 物理合理性(Physical Plausibility) | 评估内容是否符合物理定律,如重力、惯性,避免违反常识的现象 |
| 运动平滑度(Smoothness) | 评估物体或相机运动的流畅程度,要求连续自然而非生硬卡顿 |
| 综合图像质量(Comprehensive Image Quality) | 评估每一帧作为静态图像的质量,包括清晰度、色彩、光照、纹理等 |
| 场景生成质量(Scene Generation Quality) | 评估整个场景的构建和渲染能力,包括背景完整性和元素布局协调性 |
| 风格化能力(Stylization Ability) | 评估根据文本指令生成特定艺术风格视频的能力,如水墨风、赛博朋克等 |
| 单一物体准确性(Single Object Accuracy) | 评估视频中单个物体的外观、形状和结构是否符合文本描述 |
| 多物体准确性(Multiple Object Accuracy) | 评估多个物体同时符合文本描述,且所有提及物体都正确出现 |
| 空间位置准确性(Spatial Position Accuracy) | 评估物体间相对位置关系是否符合描述,如"猫在沙发上"的方位关系 |
| 摄像机控制(Camera Control) | 评估执行摄像机运动指令的能力,如拉近、平移、俯视、环绕等 |
| 动作指令跟随(Action Instruction Following) | 评估理解和执行具体动作指令的能力,如"挥手"必须出现挥手动作 |
实战
下载源码并安装依赖:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
单GPU推理:
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --sample_shift 8 --sample_guide_scale 6 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
解读:
- 若遇到OOM(内存不足)问题,可使用
--offload_model True和--t5_cpu选项来减少GPU内存使用; - 若使用T2V-1.3B模型,建议设置参数
--sample_guide_scale 6; --sample_shift参数可根据性能在[8,12]内进行调整。
对于FLF2V模型的单GPU推理:
python generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --prompt "..."
对于VACE模型的单GPU推理:
python generate.py --task vace-1.3B --size 832*480 --ckpt_dir ./Wan2.1-VACE-1.3B --src_ref_images examples/girl.png,examples/snake.png --prompt "在一个欢乐而充满节日气氛的场景中,穿着鲜艳红色春服的小女孩正与她的可爱卡通蛇嬉戏。她的春服上绣着金色吉祥图案,散发着喜庆的气息,脸上洋溢着灿烂的笑容。蛇身呈现出亮眼的绿色,形状圆润,宽大的眼睛让它显得既友善又幽默。小女孩欢快地用手轻轻抚摸着蛇的头部,共同享受着这温馨的时刻。周围五彩斑斓的灯笼和彩带装饰着环境,阳光透过洒在她们身上,营造出一个充满友爱与幸福的新年氛围。"
使用FSDP+xDiT USP进行多GPU推理:
torchrun --nproc_per_node=8 generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --dit_fsdp --t5_fsdp --ulysses_size 8 --sample_shift 8 --sample_guide_scale 6 --prompt "..."
两种策略:
- Ulysess(乌利塞斯):设置
--ulysses_size $GPU_NUMS,num_heads应该能被ulysses_size整除,1.3B模型num_heads=12 - Ring(环形):设置
--ring_size $GPU_NUMS,sequence length应该能被ring_size整除。
两种策略可结合使用。
运行本地Gradio:
cd gradio
DASH_API_KEY=your_key python t2v_1.3B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir ./Wan2.1-T2V-1.3B
# 或
python t2v_1.3B_singleGPU.py --prompt_extend_method 'local_qwen' --ckpt_dir ./Wan2.1-T2V-1.3B
扩展提示,能有效地丰富生成视频中的细节,进一步提高视频质量。建议启用提示扩展,提供两种方法:
- Dashscope API:对于文本到视频的任务使用
qwen-plus模型,对于图像到视频的任务使用qwen-vl-max模型;参数--prompt_extend_model修改用于扩展的模型
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --prompt "..." --use_prompt_extend --prompt_extend_method 'dashscope' --prompt_extend_target_lang 'ch'
- 使用本地模型:对于文本到视频的任务,可使用
Qwen/Qwen2.5-14B-Instruct等模型;对于图像到视频的任务,可使用诸如Qwen/Qwen2.5-VL-7B-Instruct等模型。较大的模型通常提供更好的扩展结果,但需要更多的GPU内存。此外,使用最新系列模型如Qwen3,也能达到类似效果,参考文首。
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --prompt "..." --use_prompt_extend --prompt_extend_method 'local_qwen' --prompt_extend_target_lang 'ch'
使用Diffusers运行:
import torch
from diffusers.utils import export_to_video
from modelscope import AutoencoderKLWan, WanPipeline
from diffusers.schedulers.scheduling_unipc_multistep import UniPCMultistepScheduler# 仅支持Diffusers模型
model_id = "Wan-AI/Wan2.1-T2V-14B-Diffusers"
vae = AutoencoderKLWan.from_pretrained(model_id, subfolder="vae", torch_dtype=torch.float32)
flow_shift = 5.0 # 5.0用于720P, 3.0用于480P
scheduler = UniPCMultistepScheduler(prediction_type='flow_prediction', use_flow_sigmas=True, num_train_timesteps=1000, flow_shift=flow_shift)
pipe = WanPipeline.from_pretrained(model_id, vae=vae, torch_dtype=torch.bfloat16)
pipe.scheduler = scheduler
pipe.to("cuda")prompt = "A cat and a dog baking a cake together in a kitchen. The cat is carefully measuring flour, while the dog is stirring the batter with a wooden spoon. The kitchen is cozy, with sunlight streaming through the window."
negative_prompt = "Bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, images, static, overall gray, worst quality, low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, misshapen limbs, fused fingers, still picture, messy background, three legs, many people in the background, walking backwards"output = pipe(prompt=prompt,negative_prompt=negative_prompt,height=720,width=1280,num_frames=81,guidance_scale=5.0,
).frames[0]
export_to_video(output, "output.mp4", fps=16)
社区
基于Wan2.1改进的开源作品:
- Phantom:基于Wan2.1-T2V-1.3B开发一个针对单个或多个主题参考的统一视频生成框架。
- UniAnimate-DiT:基于Wan2.1-14B-I2V训练一个人体图像动画模型。
- CFG-Zero:从CFG角度增强Wan2.1,涵盖T2V和I2V模型。
- TeaCache:Wan2.1加速,提高约两倍。
- DiffSynth-Studio:为Wan2.1提供更多支持,包括视频到视频转换、FP8量化、显存优化、LoRA训练等。
2.2
在2.1基础上,引入以下创新:
- 高效MoE架构:在视频扩散模型中引入MoE架构。通过用专门的强大专家模型跨时间步分离去噪过程,扩大整体模型容量,同时保持相同的计算成本;
- 电影级美学:引入精心策划的美学数据,包括详细的照明、构图、对比度、色调等标签。这使得能够更精确和可控地生成电影风格,并有助于创建具有可定制美学偏好的视频;
- 复杂的运动生成:训练数据量显著增加,图像增加+65.6%,视频增加+83.2%。显著增强模型在多个维度上的泛化能力,如运动、语义和美学,在所有开源和闭源模型中达到顶级性能;
- 高效的高清混合TI2V:开源一个基于先进的Wan2.2-VAE构建的5B模型,实现16×16×4压缩比,支持720P分辨率、24fps的文本到视频和图像到视频生成,可在像4090这样的消费级显卡上运行。目前最快的720P@24fps模型之一,能够同时服务于工业界和学术界。
基于WAN2.2基座模型有一系列拓展模型,下面列出的模型开源地址均为ModelScope,可无缝替换为HuggingFace地址:
- 文本转视频:开源T2V-A14B,MoE模型,支持480P、720P
- 图像转视频:开源I2V-A14B,MoE模型,支持480P、720P
- 文本+图像转视频:开源TI2V-5B:同时支持文本转视频和图像转视频,即
TI2V=T2V+I2V,基于高压缩VAE,支持720P - 语音转视频模型,也叫人声生视频,技术报告,Wan2.2-S2V在线体验,开源Wan2.2-S2V-14B,专为音频驱动的电影视频生成而设计的模型,支持480P、720P
- 数字人:Wan2.2-Animate在线体验,开源Animate-14B:统一的角色动画和替换模型,具有整体动作和表情复制功能。
创新
MoE
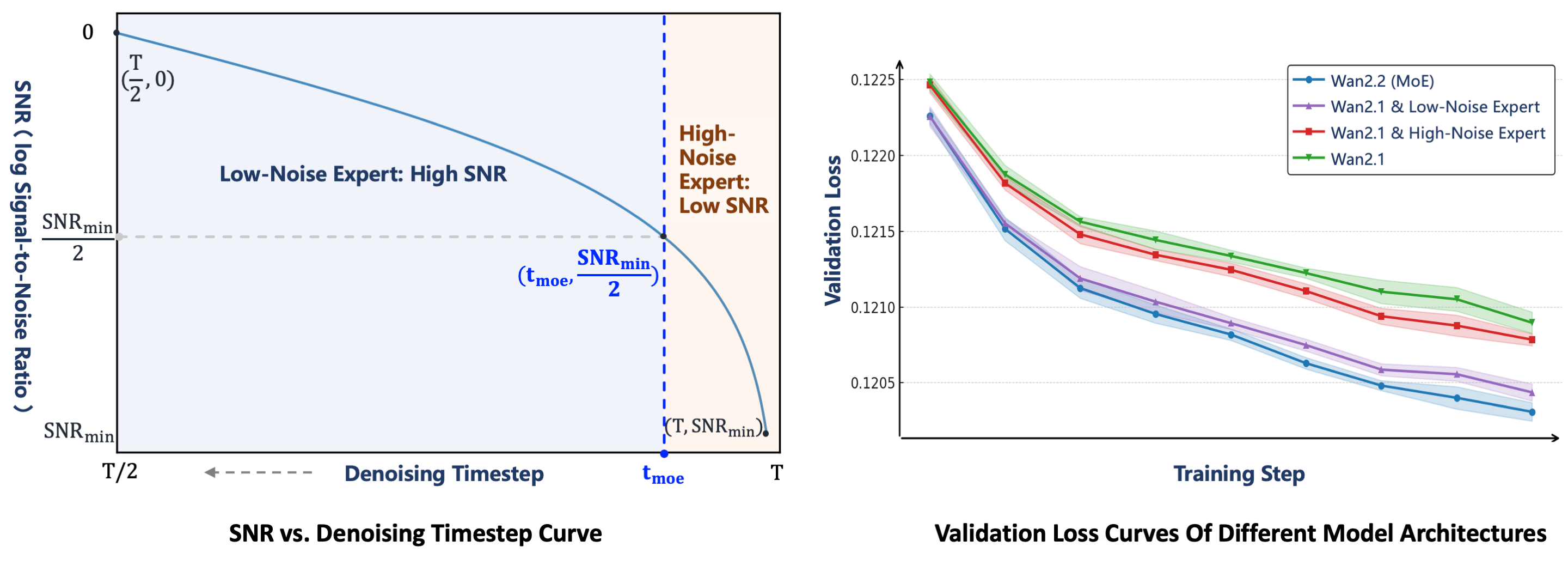
Wan2.2将MoE架构引入视频生成扩散模型。MoE已在LLM中得到广泛验证,是一种在保持推理成本几乎不变的情况下增加总模型参数的有效方法。在Wan2.2中,A14B系列模型采用针对扩散模型去噪过程量身定制的双专家设计:早期阶段的高噪声专家,专注于整体布局;后期阶段的低噪声专家,细化视频细节。每个专家模型约有14B参数,总计27B参数,但每步只有14B活跃参数,保持推理计算和GPU内存几乎不变。

两个专家之间的转换点由信噪比(Signal-to-Noise Ratio,SNR)决定,这是一个随着去噪步骤ttt增加而单调递减的度量。在去噪过程开始时,ttt很大且噪声水平很高,因此SNR处于其最小值SNRminSNR_{min}SNRmin。在这个阶段,激活高噪声专家。我们定义一个阈值步骤tmoett_{moet}tmoet对应于SNRminSNR_{min}SNRmin的一半,并在t<tmoet<t_{moe}t<tmoe时切换到低噪声专家。
高效的高清混合TI2V
为了实现更高效的部署,Wan2.2还探索一种高压缩设计。除27B MoE模型外,还发布5B密集模型,即TI2V-5B。它由高压缩率的Wan2.2-VAE支持,该VAE实现T×H×WT\times H\times WT×H×W压缩比为4×16×164\times16\times164×16×16,将整体压缩率提高到64同时保持高质量的视频重建。通过添加额外的图块化层(patchification layer),TI2V-5B的总压缩比达到4×32×324\times32\times324×32×32。未经特定优化,TI2V-5B可以在单个消费级GPU上不到9分钟内生成5秒的720P视频,是最快的720P@24fps视频生成模型之一。该模型还在一个统一框架内原生支持文本到视频和图像到视频任务,涵盖了学术研究和实际应用。
实战
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
pip install -r requirements.txt
单GPU语音转视频推理,GPU显存至少80GB方可运行:
python generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --offload_model True --convert_model_dtype --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard." --image "examples/i2v_input.JPG" --audio "examples/talk.wav"
解读:不带--num_clip参数时,生成视频自动和输入音频长度保持一致。
使用FSDP+DeepSpeed Ulysses的多GPU推理
torchrun --nproc_per_node=8 generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "..." --image "examples/i2v_input.JPG" --audio "examples/talk.wav"
姿态+音频驱动的生成
torchrun --nproc_per_node=8 generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "a person is singing" --image "examples/pose.png" --audio "examples/sing.MP3" --pose_video "./examples/pose.mp4"
解读:
- 对于语音转视频任务,
size参数表示生成视频的区域,宽高比遵循原始输入图像的比例; - 该模型可从音频输入结合参考图像和可选文本提示生成视频;
--pose_video参数启用姿态驱动的生成,允许模型在生成与音频输入同步的视频时跟随特定的姿态序列;--num_clip参数控制生成的视频片段数量,有助于通过缩短生成时间来快速预览。
其他
VACE
论文,GitHub,项目首页。
用户可输入文本提示以及可选的视频、遮罩和图像来进行视频生成或编辑。用户收集的材料需要被预处理成VACE可识别的输入,包括src_video, src_mask, src_ref_images, prompt。对于R2V(参考到视频生成),可跳过此预处理步骤,但对于V2V(视频到视频编辑)和MV2V(带遮罩的视频到视频编辑)任务,则需要额外的预处理来获取具有深度、姿态或遮罩区域等条件的视频。
FSDP
参考/推荐
- 通义万相AI生视频—使用指南