实验室PRCV 2025论文分享|如何利用大模型自动生成高质量英语阅读理解练习题
本推文详细介绍了一篇实验室的论文《Generating Reading Comprehension Exercises with Large Language Models for Educational Applications》。该论文已被第八届中国模式识别与计算机视觉大会(PRCV 2025)接收,论文的第一作者为黄星宇。论文提出了一个面向教育应用的英语阅读理解习题生成框架RCEG(Reading Comprehension Exercise Generation)。该框架通过指令微调、奖励优化与后生成控制,自动生成高质量、个性化的英语阅读理解材料。具体包括:基于监督微调与近端策略优化的两阶段训练流程,以及基于动态属性图的可控文本生成(Dynamic Attribute Graphs-based controlled text generation,DATG)与生成式判别器(Generative Discriminator,GeDi)的候选生成与筛选机制。为训练和评估性能,构建了专门针对英语阅读理解的数据集,并采用内容多样性、事实准确性、语言安全性等综合指标进行评估。实验结果表明,RCEG在各项指标上显著优于基线模型,尤其在内容相关性与认知适宜性方面提升明显,表明该框架能够有效生成符合教学需求的阅读理解练习题。
推文作者为黄星宇,审校为许东舟和邱雪。
论文链接:https://pan.baidu.com/s/1AuO5-pG00YP2LKrFKXBJjA?pwd=jc4k
扫描二维码直接跳转到下载页面

一、会议介绍

第八届中国模式识别与计算机视觉大会(The 8th Chinese Conference on Pattern Recognition and Computer Vision, PRCV 2025)于2025年10月15日至18日在国家会展中心(上海)举办。PRCV是国内模式识别和计算机视觉领域顶级学术盛会,也是国际上重要且受到国际学术界认可的会议,被中国计算机学会推荐的C类会议。本次会议由中国图象图形学学会、中国人工智能学会、中国计算机学会和中国自动化学会联合主办,上海交通大学承办。
二、研究背景及主要贡献
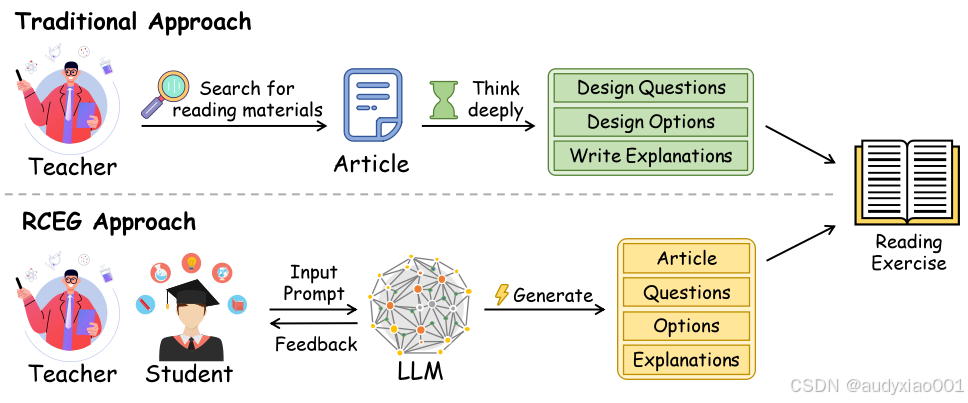
图 1 传统模式与RCEG框架生成英语阅读理解练习的流程比较
近年来,尽管大语言模型在自然语言生成方面表现出巨大潜力,并在教育技术领域得到了广泛应用,如对话系统和写作辅导等,但其在教育评估内容生成,特别是阅读理解练习的自动创建方面的探索仍相对不足。传统方法及现有研究多集中于教学辅助,而缺乏能够生成高质量、个性化、且符合教学目标的自动化习题生成框架,这限制了自适应学习系统的进一步发展。从图1中可以能看出,教师在使用传统的方法制作习题时耗时耗力,使用大模型生成较为迅速。因此,该研究抓住这个切入点,填补这一空白,探索利用大语言模型自动生成高质量英语阅读理解练习的可行性与有效性,提出了一种英语阅读理解习题生成框架,称为RCEG。该研究的贡献可以概括为:
1、构建了三个针对特定任务的数据集,以支持教育内容生成的完整指令对齐训练流程。这些数据集分别用于监督微调(Supervised Fine-Tuning,SFT)、奖励模型训练和基于近端策略优化(Proximal Policy Optimization,PPO)的强化学习。
2、提出了阅读理解练习生成框架,该框架将经过微调的语言模型与后处理模块相结合。该模块融合了基于动态属性图的受控生成技术DATG和基于GeDi的判别器重排机制。此外,开发了基于Gradio的交互式界面,以支持学生和教师的实际使用。
3、开展了涵盖连贯性、相关性和安全性等多维度的综合评估,同时采用自动指标和人工偏好评分。结果表明,框架在生成高质量、适应学习者需求的阅读理解练习方面显著超越了现有基线方法。
三、方法
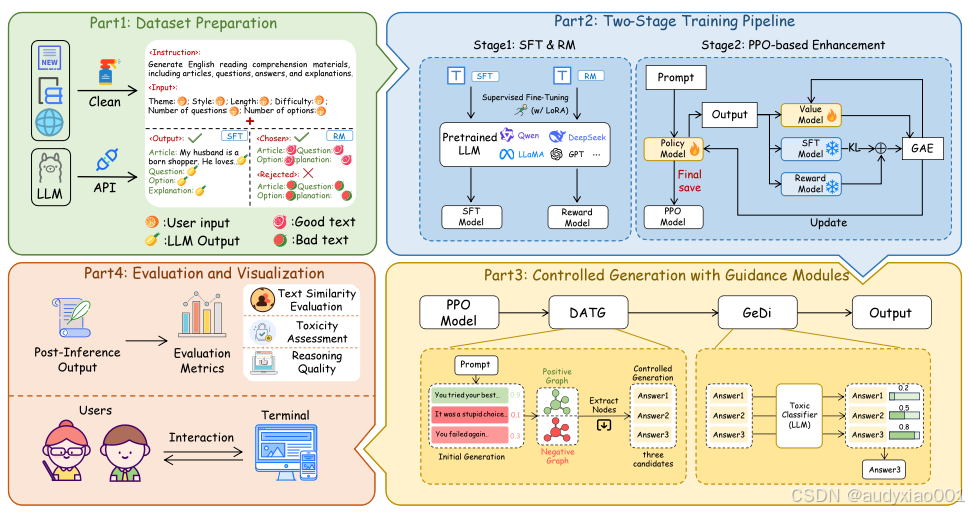
图 2 RCEG框架的组成
RCEG框架是一个集成了数据准备、模型训练、可控生成与多维度评估的完整系统。其核心架构遵循清晰的四阶段流程,如图2所示。
1、首先,在数据准备阶段,构建三个专门的指令数据集,分别用于后续的监督微调、奖励模型训练和强化学习。如图左侧所示,每个数据样本都明确了生成任务(如生成阅读理解材料)和内容约束(如主题、风格、难度、题目数量等),为模型提供了清晰的学习目标。
2、接下来,框架进入核心的两阶段训练Pipeline。第一阶段,基础大模型在指令数据集上进行监督微调,学习生成符合教育规范的练习初稿;同时,训练一个奖励模型,用于评判生成内容的质量。第二阶段,利用近端策略优化算法PPO,根据奖励模型的反馈对微调后的模型进行强化学习,使其输出在相关性、流畅度上不断优化。
3、随后,经过训练的模型在推理时,会进入受控生成与引导模块。PPO模型会先生成多个候选答案,接着由DATG模块进行动态属性图引导,输出增强其教学适宜性属性。然后,GeDi判别器作为一个毒性分类器,会对候选答案进行安全过滤,最终选出最优质、最安全的答案作为最终输出。
最后,在评估与可视化阶段,系统会从文本相似度、推理质量和毒性等多个维度对输出进行自动化评估。同时,还制作了一个基于Gradio的交互界面,支持教师和学生实时生成并体验阅读理解练习,实现了从算法研究到实际教育应用的无缝衔接。
四、实验
(1)实验参数
表 1 三个数据集细节参数
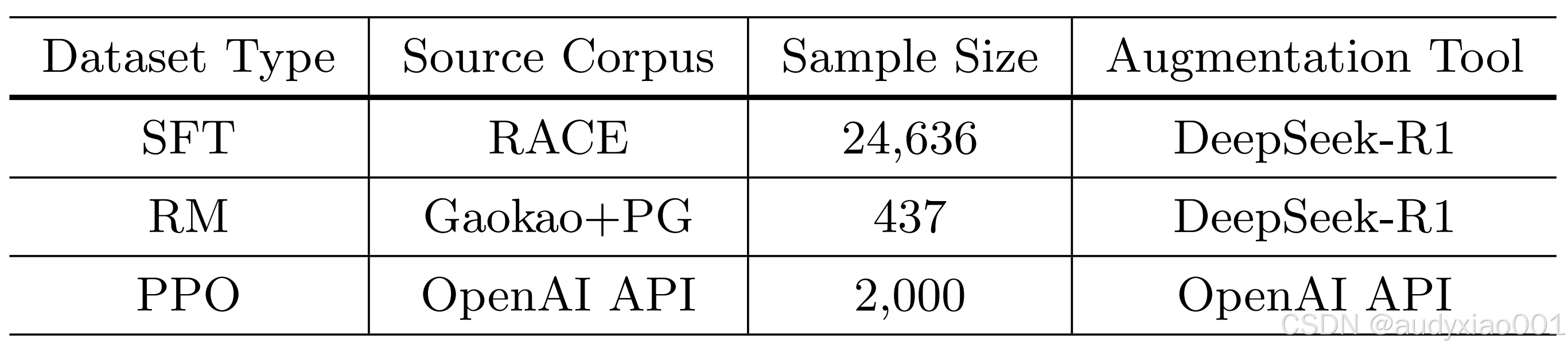
该研究使用三个精心构建的数据集对模型进行训练,数据集细节如表1所示。所有微调过程均采用LoRA方法。训练配置包括:批次大小为2,梯度累积步数为8,学习率为1e-5。监督微调和近端策略优化阶段均训练3个周期,而奖励模型则训练8个周期。序列长度限制截断为2048个token。所有实验均在单张NVIDIA GeForce RTX 4090 GPU上完成,整个训练流程基于LLaMA-Factory框架实现。
(2)实验结果
在实验部分,为全面评估所提出的RCEG框架的有效性,该研究进行了一系列严格的实验。这些实验从文本相似性、推理质量和内容安全性三个关键维度,将该研究的模型与多个基线模型进行了对比。实验结果表明,经过该研究两阶段训练并结合后处理控制机制的框架,在生成阅读理解练习的准确性、教育适配性以及安全性上均取得了显著且一致的提升。
表 2 基线模型与RCEG-SP(不含后处理)的性能对比
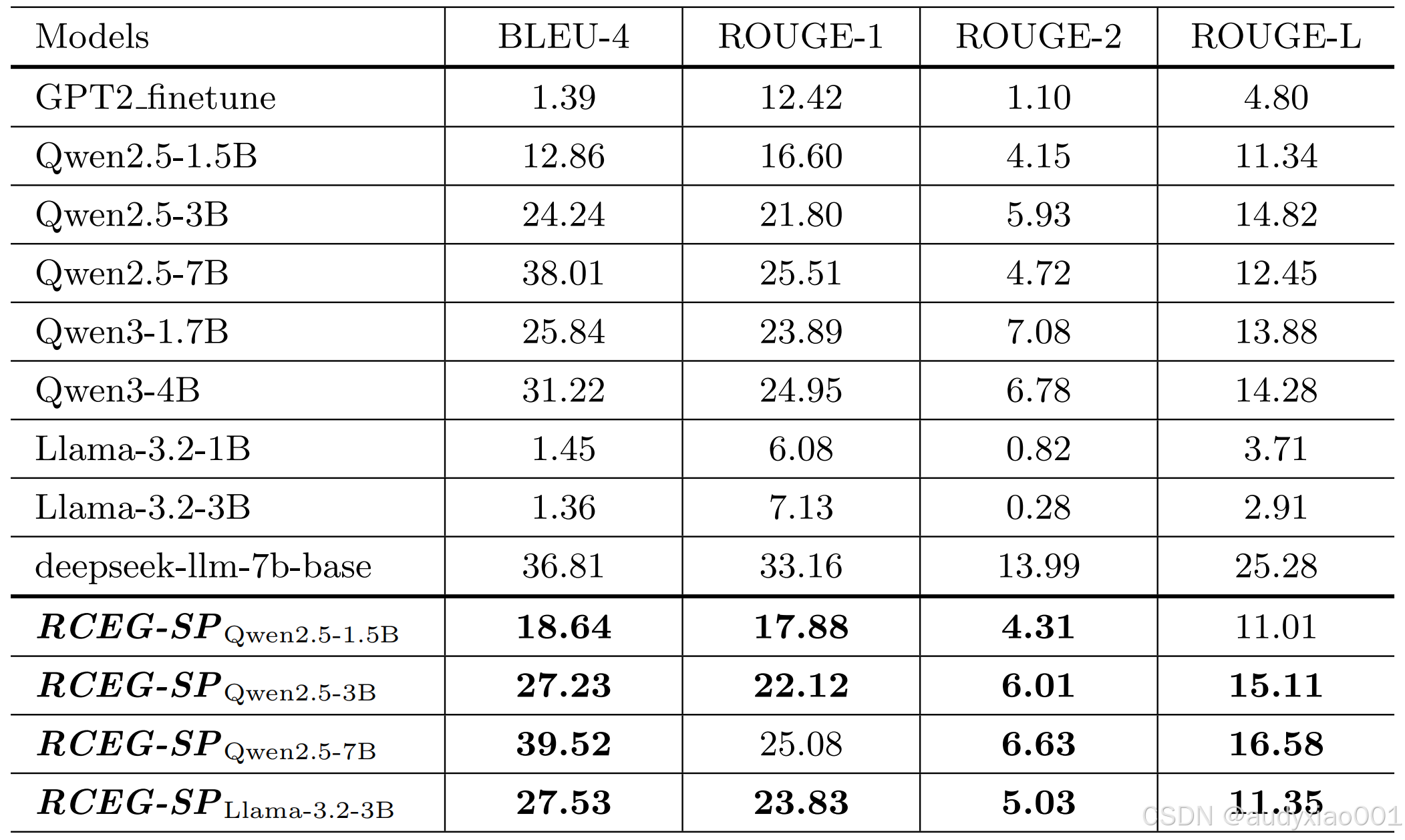
如表2所示,经过监督微调SFT和近端策略优化PPO两阶段训练的RCEG-SP模型,在BLEU-4和ROUGE系列指标上均显著超越其对应的基础模型以及先前的GPT2微调基线。这表明该研究的两阶段训练pipeline有效提升了模型生成内容与人类参考文本之间的词汇和语义对齐度。例如,Qwen2.5-3B模型在优化后,BLEU-4得分从24.24提升至27.23,这证实了该训练方法能够使模型产出更准确、更贴合预期的阅读理解练习内容。
表 3 RCEG在FreeEval基准上的零样本推理
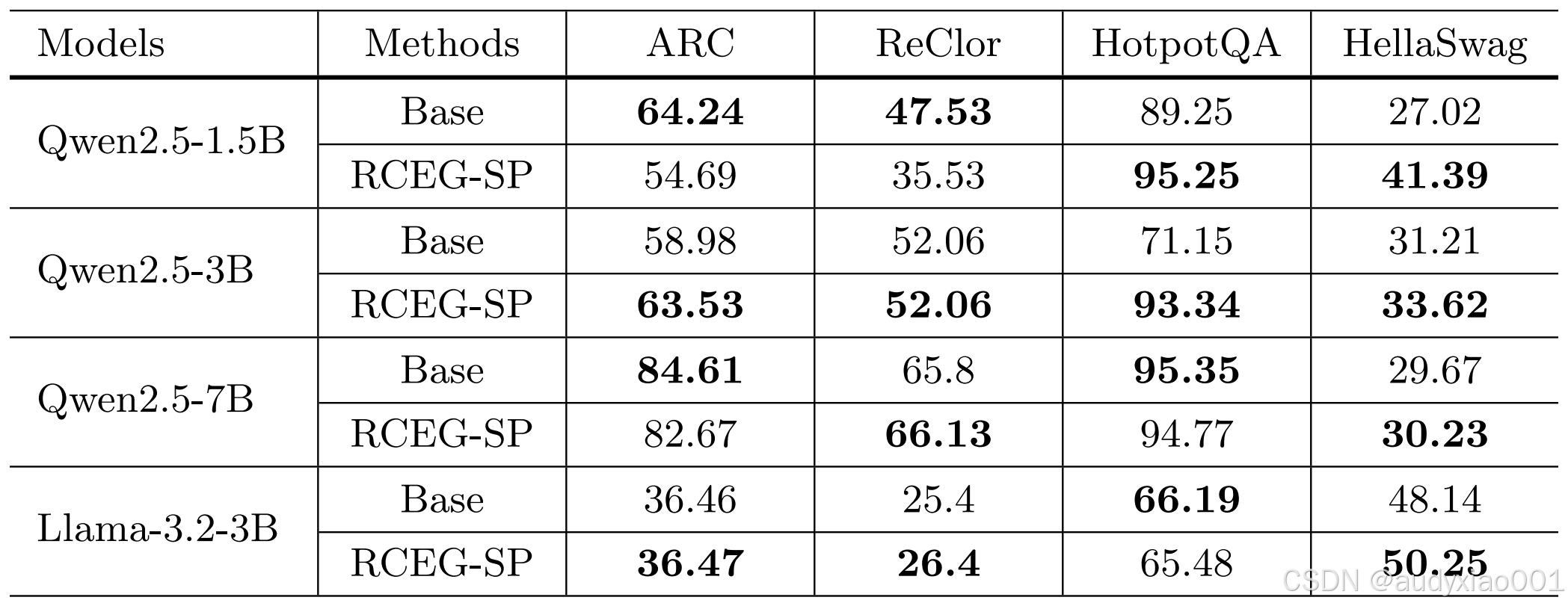
表3的零样本推理评估结果反映了模型在泛化能力上的变化。可以看到,经过RCEG-SP优化后,模型在需要多步推理(如HotpotQA)和常识推理(如HellaSwag)的任务上普遍取得了显著提升,这证明了该研究的训练框架增强了模型的深层理解与逻辑推理能力。然而,在部分任务(如ARC和ReClor)上性能出现轻微波动或下降,这表明在专注于提升教育内容生成质量的同时,可能会与某些特定形式的科学推理任务存在一定的权衡,但模型在整体推理能力上仍保持了强大竞争力。
表 4 RCEG(含后处理)在不同数据集上的困惑度
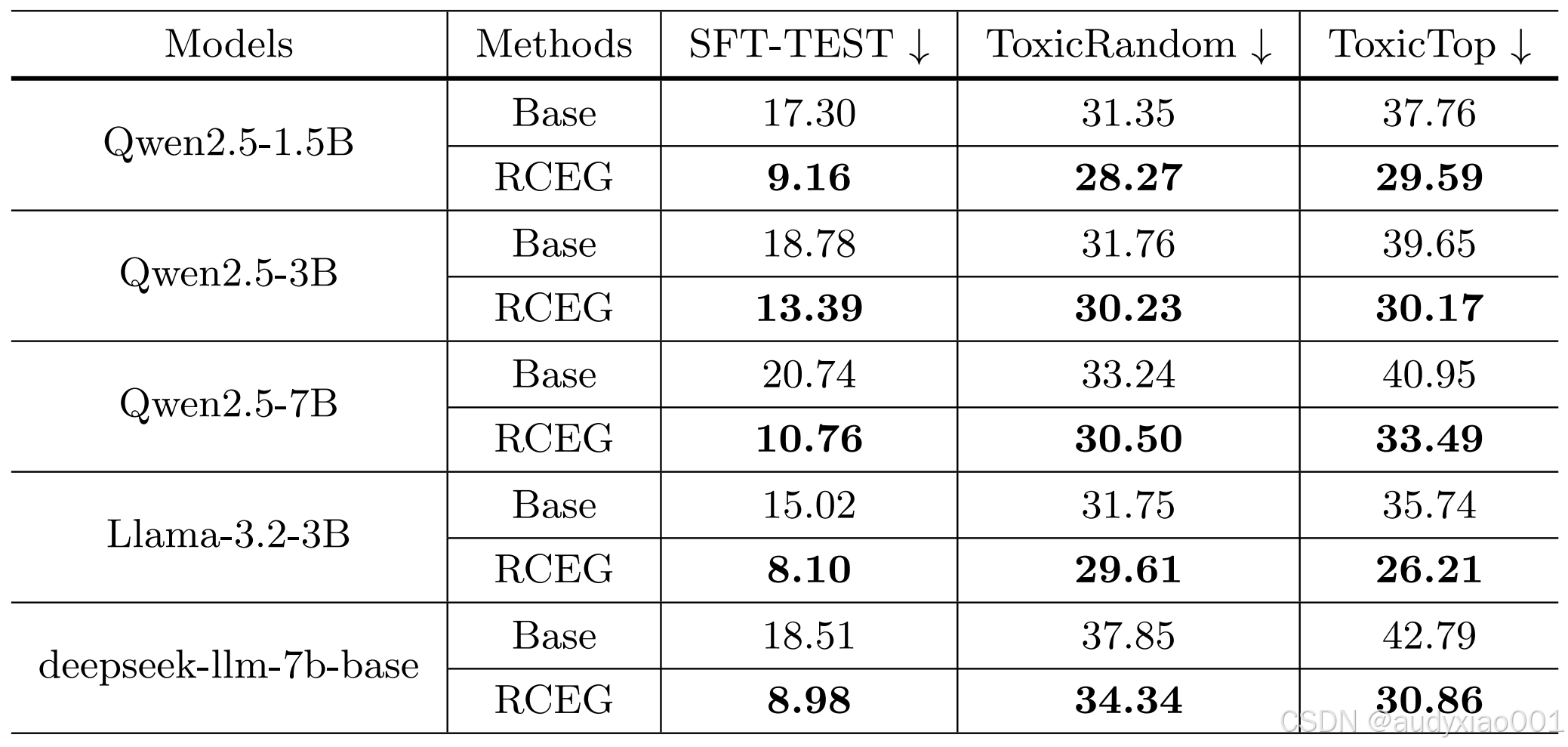
表4通过困惑度指标评估了模型在安全性与稳健性上的表现。结果显示,在引入了DATG引导生成和GeDi进行后处理筛选的完整RCEG框架后,所有模型在不同测试集(包括干净数据、随机毒性样本和高毒性样本)上的困惑度均显著降低。例如,Qwen2.5-1.5B在ToxicTop数据集上的困惑度从37.76大幅降至29.59。这充分证明,该研究的可控生成与过滤模块能有效抑制不良内容的产生,显著提升了生成内容的安全性和可靠性,使其更适用于教育这一对内容安全要求极高的场景。
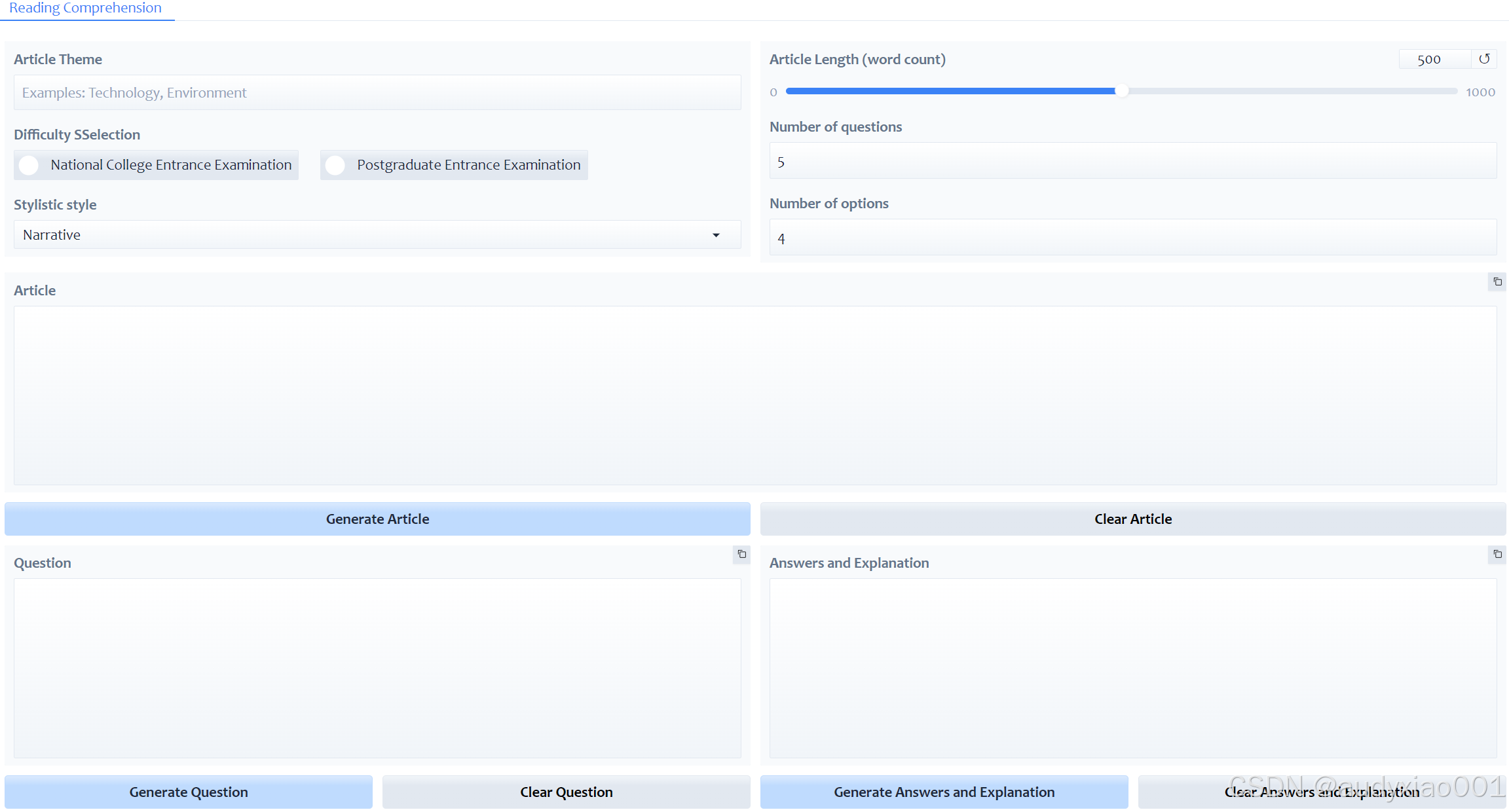
图 3 基于Gradio的RCEG交互界面
此外,为促进本框架的实际应用,该研究开发了一个基于Gradio的轻量级交互界面,如图3所示。该界面允许教育工作者无需任何编程背景,即可通过直观的下拉菜单和输入框,灵活设定阅读理解文章的主题、难度、长度、题目与选项数量等参数。用户点击生成按钮后,系统便能实时调用优化后的RCEG模型,自动产出包含文章、问题、答案及详细解析的完整练习材料。这一设计极大地提升了框架的易用性与实用性,使其能够无缝集成到真实的备课与学习流程中,真正体现了智能教育技术赋能教学实践的巨大潜力。
五.总结
论文提出了一个面向英语教学的阅读理解练习自动生成框架RCEG。该框架通过构建专用数据集,并采用监督微调、奖励模型与近端策略优化的两阶段训练流程,使大语言模型能够生成教学目标和内容约束高度对齐的初稿。在此基础上,创新性地引入基于DATG的动态属性图的受控生成模块与基于GeDi的判别器重排模块,对生成内容进行优化与过滤,确保其兼具教学适宜性与内容安全性。实验结果表明,RCEG在文本质量、推理能力和抗毒性方面均显著优于现有基线,并通过开发的交互界面验证了其教育应用的实用价值,为自适应学习资源的智能化生成提供了有效解决方案。