从入门到实操:贝叶斯分析完整技术步骤与核心R包指南
从入门到实操:贝叶斯分析完整技术步骤与核心R包指南
在统计分析领域,贝叶斯方法因能量化不确定性、融合先验信息与数据证据的独特优势,正被越来越多领域(如医学、生态学、心理学)的研究者采用。但对新手而言,贝叶斯分析的技术流程与R包选择常令人困惑。本文将拆解贝叶斯分析的标准技术步骤,搭配对应场景的核心R包实操指南,帮你快速上手从建模到结果解读的全流程。
一、贝叶斯分析核心技术步骤框架
贝叶斯分析的核心逻辑是“先验信息+数据证据→后验推断”,对应的技术流程可归纳为5个关键步骤,每个步骤都有其明确目标与适配工具:
- 问题定义与数据准备:明确研究问题(如“暴露因素与结局的关联是否存在?”)、结局类型(二分类/连续型/时序),并整理数据(含原始数据或文献提取的效应量数据)。
- 先验分布设定:根据领域知识或历史研究设定先验(无信息先验/信息先验),信息先验可通过Meta分析整合历史证据获得。
- 模型构建与采样:选择适配模型结构(如线性回归、混合效应模型),通过MCMC(马尔可夫链蒙特卡洛)采样获得后验分布。
- 模型诊断:检验采样收敛性,确保后验结果可靠。
- 后验推断与可视化:提取后验统计量(均值、可信区间)、计算关键概率,通过可视化呈现结果并撰写结论。
接下来,我们按步骤拆解每个环节的核心R包与实操代码。
二、分步骤实操:核心R包与代码示例
Step 1:问题定义与数据准备——基础工具铺垫
此步骤重点是数据清洗与格式标准化,需区分“新研究原始数据”和“Meta分析的历史研究数据”两类场景,核心工具为tidyverse(数据处理)。
示例场景:研究某药物对高血压的疗效(二分类结局:有效=1/无效=0),需同时处理:①新研究的原始病例数据;②10项历史研究的效应量数据(用于构建信息先验)。
library(tidyverse)
# 1. 新研究原始数据(药物组vs对照组)
new_data <- tibble(group = rep(c("drug", "control"), each = 100), # 每组100例effect = c(rbinom(100, 1, 0.6), rbinom(100, 1, 0.4)) # 疗效概率分别为60%、40%
)
# 2. 历史研究数据(已提取OR及标准误,用于后续Meta分析)
historical_data <- tibble(study = 1:10,logOR = rnorm(10, 0.5, 0.2), # 历史研究的logOR(OR取对数更易建模)se_logOR = rnorm(10, 0.15, 0.03) # logOR的标准误
)
Step 2:先验分布设定——信息先验的构建(Meta分析核心)
先验设定是贝叶斯分析的灵魂,信息先验能整合历史证据提升推断效率,核心通过贝叶斯Meta分析包实现;无信息先验(如normal(0,10))可直接在建模时设定。
此环节有两个核心R包:metaBMA(擅长模型比较与贝叶斯因子)和bayesmeta(支持原始数据直接计算效应量,新手友好)。
场景2.1:用metaBMA构建信息先验(需预处理效应量)
若已有历史研究的效应量(如logOR)和标准误,直接用metaBMA做Meta分析,提取合并效应量的后验分布作为信息先验。
library(metaBMA)
# 贝叶斯随机效应Meta分析(整合历史证据)
meta_result <- meta_bma(yi = logOR, # 历史研究的效应量(logOR)se = se_logOR, # 效应量的标准误study = study, # 研究IDdata = historical_data,prior_mu = normal(0, 1), # Meta分析本身的初始模糊先验prior_tau = halfnormal(0, 1) # 异质性参数先验
)
# 提取信息先验参数(logOR服从正态分布N(m, s))
info_prior <- posterior(meta_result, pars = "mu") # 合并效应量的后验分布
info_params <- fitdistr(info_prior[, "mu"], "normal") # 拟合正态分布
m <- info_params$estimate["mean"] # 先验均值
s <- info_params$estimate["sd"] # 先验标准差
场景2.2:用bayesmeta构建信息先验(支持原始数据)
若只有历史研究的原始四格表数据(如每组事件数/总样本量),bayesmeta可通过escalc()自动计算效应量,无需手动转换。
library(bayesmeta)
library(meta) # 辅助计算效应量
# 历史研究原始四格表数据(a=有效数, b=无效数, c=对照有效数, d=对照无效数)
raw_historical <- tibble(study = 1:3,a = c(60, 65, 58), b = c(40, 35, 42),c = c(40, 38, 45), d = c(60, 62, 55)
)
# 自动计算logOR和标准误
meta_data <- escalc(measure = "OR", a=a, b=b, c=c, d=d, data = raw_historical)
# 贝叶斯Meta分析
bayes_meta <- bayesmeta(meta_data, prior.tau = "halfcauchy(0,1)")
# 提取信息先验参数
m_bayes <- bayes_meta$mu # 合并logOR均值
s_bayes <- bayes_meta$se.mu # 标准误
Step 3:模型构建与采样——核心建模包选择
根据模型复杂度选择工具:新手优先选brms(语法贴近传统回归,无需写采样代码);复杂自定义模型选rstan(基于Stan语言,灵活高效)。
场景3.1:brms构建简单回归模型(新手首选)
以新研究的二分类结局为例,用brms构建逻辑回归模型,代入Step 2得到的信息先验。
library(brms)
# 构建贝叶斯逻辑回归模型(group为自变量,effect为结局)
model_info <- brm(formula = effect ~ group, # 结局~分组(默认logit链接,对应OR)data = new_data,family = bernoulli(), # 二分类结局prior = prior(normal(m, s), class = b, coef = groupdrug), # 代入信息先验chains = 4, iter = 4000, warmup = 2000, # 4条链,预热2000次迭代control = list(adapt_delta = 0.95) # 提高收敛稳定性
)
# 敏感性分析:用模糊先验验证结果(扩大标准差至2*s)
model_fuzzy <- update(model_info, prior = prior(normal(m, 2*s), class = b, coef = groupdrug))
场景3.2:rstan构建自定义模型(复杂场景)
若需自定义模型(如含交互项的分层模型),需编写Stan代码,通过rstan调用采样。
library(rstan)
rstan_options(auto_write = TRUE)
# 1. 准备数据列表
stan_data <- list(N = nrow(new_data),y = new_data$effect,x = as.integer(new_data$group == "drug"), # 分组转换为0-1变量m = m, s = s # 信息先验参数
)
# 2. 编写Stan模型代码(逻辑回归)
stan_code <- "
data {int N;int y[N];int x[N];real m;real s;
}
parameters {real alpha; // 截距real beta; // 分组系数(logOR)
}
model {// 先验设定alpha ~ normal(0, 10); // 无信息先验beta ~ normal(m, s); // 信息先验// 似然函数y ~ bernoulli_logit(alpha + beta*x);
}
generated quantities {real OR = exp(beta); // 转换为OR
}
"
# 3. 采样
stan_model <- stan(model_code = stan_code, data = stan_data, chains = 4, iter = 4000)}
Step 4:模型诊断——收敛性检验
核心指标为Rhat值(<1.01表示收敛良好),通过bayesplot可视化迹图(链的混合程度)。
library(bayesplot)
# 1. 查看Rhat值(brms模型)
summary(model_info)$fixed # 固定效应的Rhat值
# 2. 绘制迹图(查看链的混合情况)
mcmc_trace(model_info, pars = "b_groupdrug") + # 分组系数的迹图theme_minimal() +labs(title = "分组系数的MCMC迹图(Rhat<1.01为收敛)")
Step 5:后验推断与可视化——tidybayes高效处理
贝叶斯结果的核心是后验分布,tidybayes可将采样结果转换为整洁数据格式,无缝对接dplyr和ggplot2,实现统计量计算与可视化。
library(tidybayes)
# 1. 提取后验OR并计算关键概率
posterior_or <- model_info %>%spread_draws(b_groupdrug) %>% # 提取分组系数(logOR)mutate(OR = exp(b_groupdrug)) %>% # 转换为ORselect(OR)
# 计算OR>1(药物有效)的概率
prob_effect <- mean(posterior_or$OR > 1)
# 计算均值和95%可信区间
or_stat <- posterior_or %>%mean_qi(OR, .width = 0.95) # .width为可信区间宽度# 2. 可视化后验分布(含敏感性分析)
posterior_all <- bind_rows(model_info %>% spread_draws(b_groupdrug) %>% mutate(OR=exp(b_groupdrug), prior="信息先验"),model_fuzzy %>% spread_draws(b_groupdrug) %>% mutate(OR=exp(b_groupdrug), prior="模糊先验")
)
# 绘制后验密度图
ggplot(posterior_all, aes(x=OR, fill=prior)) +geom_density(alpha=0.5) +geom_vline(xintercept=1, linetype="dashed", color="red") + # 无效线(OR=1)geom_pointinterval(data=or_stat, aes(x=OR, y=0, xmin=.lower, xmax=.upper), color="black", position=position_dodge(width=0.5)) +labs(x="药物疗效OR值", y="后验密度", fill="先验类型") +theme_minimal()# 3. 输出结论
cat(paste("基于信息先验的分析显示:药物有效(OR>1)的概率为", round(prob_effect*100,1), "%\n"))
cat(paste("OR值的后验均值为", round(or_stat$OR,2), "(95%可信区间:", round(or_stat$.lower,2), "-", round(or_stat$.upper,2), ")\n"))
cat("敏感性分析显示结果稳健,不同先验设定下结论一致。")
三、核心R包速查表与学习路径
-
核心R包功能汇总
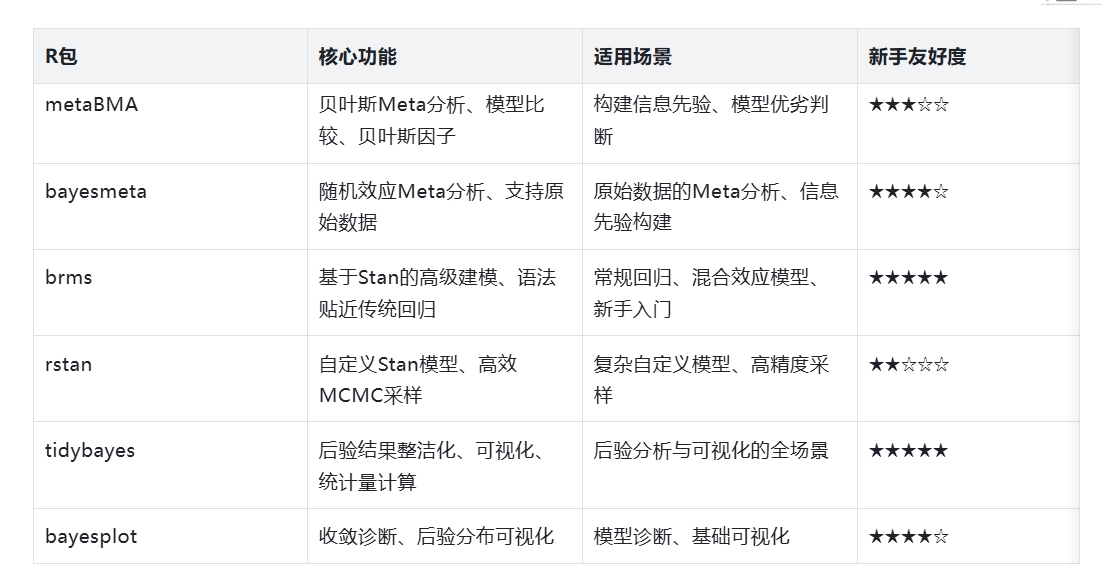
-
新手学习路径
-
基础铺垫:掌握tidyverse数据处理(必备),理解贝叶斯核心概念(先验、后验、可信区间)。
-
建模入门:从brms入手,用熟悉的回归语法构建简单模型,掌握采样与收敛诊断。
-
先验构建:学习bayesmeta(原始数据)或metaBMA(效应量数据),掌握信息先验整合方法。
-
后验分析:用tidybayes处理结果,结合ggplot2绘制专业图表。
-
进阶提升:学习rstan编写自定义模型,应对复杂研究场景。
四、总结
贝叶斯分析的核心价值在于“量化不确定性”,而R生态的丰富包资源已大幅降低了其入门门槛。从信息先验构建(metaBMA/bayesmeta)、模型建模(brms/rstan)到后验分析(tidybayes/bayesplot),一套完整的工具链已形成。新手无需追求一步到位,可从简单模型入手,逐步熟悉各环节工具,最终实现从数据到可靠结论的全流程贝叶斯分析。