webrtc代码走读(七)-QOS-FEC-ulpfec rfc5109
1、ULPFEC核心原理通俗解读
ULPFEC(Uneven Level Protection Forward Error Correction,非均匀级别保护前向纠错)是WebRTC用于提升实时通信质量的关键QOS技术,核心思路是**“提前发‘备用数据’,丢包时能‘补救’”**。打个比方:你给朋友邮寄一套4本的漫画书(对应4个媒体数据包A、B、C、D),担心运输中丢书,就额外复印2份“备用页组合”(对应2个FEC包)。其中1份备用页能补A、B,另1份既能补C、D,还能补A、B、C、D的组合——这样无论丢1本还是连续丢几本,都能用备用页拼出完整漫画,这就是ULPFEC的核心逻辑。
下面从报文结构、保护规则、数据保护实例三方面拆解原理:
1.1 RTP-FEC报文结构
ULPFEC的数据包由“基础标签(RTP头)+FEC专属标签(FEC头)+分级保护标签(FEC Level头)+实际备用数据(Payload)”组成,博文中3张图片分别展示了整体结构、FEC头格式、FEC Level头格式,以下逐一解析:
1. FEC数据包整体结构(FEC Packet Structures)
 **:
**:
(注:“octets”即“字节”,“Cont.”是“Continue”的缩写,表示“延续的负载”)
通俗解释:
这张图相当于“快递包裹的分层包装示意图”,每一层都有明确作用:
- 最外层(RTP头):给包裹贴“身份证”,包含收件人、发件人、包裹编号等基础信息,确保快递员能识别;
- 中间层(FEC头):贴“备用说明标签”,告诉收件人“这个备用包裹能补哪些主包裹”;
- 内层(FEC Level头+Payload):分“基础备用层(Level 0)”和“高级备用层(Level 1)”,Level 0负责补少量主包裹,Level 1负责补更多主包裹,Payload就是实际的“备用页数据”。
关键细节:
Level 0和Level 1是ULPFEC的“分级保护核心”——Level 0是基础保护,Level 1是扩展保护,一个FEC包可以同时包含两个级别的保护(如同时补2个和4个主包裹),避免单一保护级别无法应对多种丢包场景。
2. RTP头-RTP Header for FEC Packets(RFC 3550)
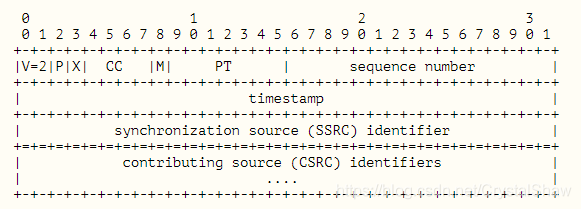
Header for FEC Packets(RFC 3550)”:FEC包的“基础身份证”
| 字段 | 位数 | 位置(字节范围) | 核心作用(通俗解释) |
|---|---|---|---|
| V(版本) | 2 | 0字节(bit 0-1) | 固定为2,标识RTP协议版本,确保收发双方用同一版本解析 |
| P(填充) | 1 | 0字节(bit 2) | 标记包末尾是否有“无效填充数据”——填1表示有,需忽略填充部分;填0表示无 |
| X(扩展) | 1 | 0字节(bit 3) | 标记是否有“扩展头”——填1表示有额外扩展信息(如自定义字段);填0表示无,直接接负载 |
| CC(CSRC计数) | 4 | 0字节(bit 4-7) | 记录后续“贡献源标识(CSRC)”的数量——如填2表示后面有2个4字节的CSRC |
| M(标记) | 1 | 1字节(bit 0) | 关键标记位——对FEC包而言,通常填0;对媒体包(如视频关键帧)填1,标识“这是重要数据的结束” |
| PT(负载类型) | 7 | 1字节(bit 1-7) | 标识包的“内容类型”——如音频包PT=0(PCMU编码)、视频包PT=96(H.264),FEC包有专属PT(如RFC5109指定的动态PT) |
| sequence number(序列号) | 16 | 2-3字节 | 包的“连续编号”——如媒体包从100开始,依次是101、102,FEC包也按顺序编号,确保接收方能发现丢包(如收到100、102,知道丢了101) |
| timestamp(时间戳) | 32 | 4-7字节 | 包的“生成时间戳”——媒体包用它同步播放(如音频按时间戳顺序播放),FEC包用它匹配“要保护的媒体包时间范围”,避免补错包 |
| SSRC(同步源标识) | 32 | 8-11字节 | 包的“主发送方ID”——如同一用户的音频、视频、FEC包用同一个SSRC,接收方能区分不同用户的包 |
| CSRC(贡献源标识) | 32×CC | 12字节后(可选) | 记录“辅助发送方ID”——如多方会议中,一个包包含3个用户的音频,CSRC就记录这3个用户的ID,用于溯源 |
通俗解释:
RTP头对FEC包而言,就像“备用包裹的基础快递单”——上面写着“包裹版本(V=2)”“是否有额外包装(P/X)”“包裹类型(PT=FEC)”“包裹编号(sequence number)”“发货时间(timestamp)”“发件人ID(SSRC)”,确保快递员(网络传输设备)能正确识别、转发这个备用包裹,接收方(如对方浏览器)能快速判断“这是哪个用户的FEC包,该用它补哪些媒体包”。
关键细节(FEC包与媒体包的RTP头差异):
- 媒体包的PT是“媒体类型”(如视频、音频),FEC包的PT是“FEC类型”(由RFC5109指定,如动态分配的PT值),接收方通过PT快速区分“这是主包裹(媒体包)还是备用包裹(FEC包)”;
- 媒体包的M位可能为1(如视频关键帧结束),FEC包的M位通常为0,因FEC包无需标识“重要数据结束”;
- 两者的SSRC必须一致——同一个用户的媒体包和FEC包用同一个SSRC,接收方才能确定“这个FEC包是补这个用户的媒体包的”,避免跨用户补包。
补充说明
-
FEC包与媒体包的RTP头“强绑定”逻辑:
两者的SSRC必须完全一致,这是接收方“匹配FEC包和媒体包”的核心依据——若FEC包SSRC=12345,媒体包SSRC=67890,接收方会认为这是两个不同用户的包,不会用前者补后者;同时,FEC包的序列号必须按“媒体包序列号+1”递增,避免接收方误以为FEC包是丢失的媒体包。 -
RTP头字段在FEC补包中的作用:
- 序列号:接收方通过“FEC包SN base + mask”确定“要补的媒体包序列号范围”,如SN base=100、mask=1100,就知道要补100、101的媒体包;
- 时间戳:通过FEC包的TS recovery字段反推丢失媒体包的时间戳,确保补包后能按正确时间顺序播放(如音频不会出现卡顿);
- PT:通过FEC包的PT recovery字段反推丢失媒体包的PT,确保补包的负载类型与原包一致(如补的是H.264视频包,不是PCMU音频包)。
-
RFC 3550对FEC包的特殊规定:
RFC 3550(RTP标准)明确要求:FEC包必须使用独立的PT(不能与媒体包PT重复),且M位通常为0,这是为了让RTP协议栈能快速区分“媒体包”和“FEC包”,避免解析错误——比如媒体包PT=96(H.264),FEC包PT=127(动态分配的FEC类型),协议栈收到PT=127的包就知道“这是FEC包,需要交给FEC解码器处理”。
3. FEC头格式(FEC Header Format)

(注:“flag”是“标志位”,“recovery”是“恢复字段”,用于丢包时计算原始数据)
通俗解释:
这张图是“备用说明标签的详细填写模板”,每一项都有明确含义:
- E flag(扩展位):预留的“备用填写位”,目前没用,填0即可;
- L flag(长掩码标志):决定“保护范围描述”的长度——填0表示用16位描述(能补最多16个主包裹),填1表示用48位描述(能补最多48个主包裹);
- P/X/CC/M/PT recovery(恢复字段):把所有主包裹的“小标签信息”(如是否有附加数据、是否是关键帧)用数学算法(XOR)压缩成6位,丢包时能通过这个字段反推原始信息;
- SN base(基准序列号):填写“能补的主包裹的最小编号”,比如主包裹编号是100、101、102,SN base就是100,方便收件人快速定位;
- TS recovery(时间戳恢复字段):压缩所有主包裹的“发货时间”,确保补包时时间能匹配;
- Length recovery(长度恢复字段):压缩所有主包裹的“尺寸大小”,确保补包时尺寸能匹配。
关键细节:
所有“recovery字段”都用XOR算法生成——XOR就像“数字拼图”,把多个数字拼在一起得到一个“拼图结果”,丢一个数字时,用“拼图结果”和其他数字就能反推出丢失的数字,这是FEC能“补包”的数学基础。
3. ULP Level头格式(ULP Level Header Format)

FEC Level头的结构,分为两种情况:
- 当FEC头中L flag=0时:4字节,包含
Protection Length(16位)、mask(16位); - 当FEC头中L flag=1时:8字节,包含
Protection Length(16位)、mask(48位)、mask cont.(32位,“cont.”表示“延续的掩码”)
(注:“Protection Length”是“保护长度”,“mask”是“掩码”,用于标记具体保护哪些主包裹)
通俗解释:
这张图是“备用包裹的保护范围清单”,明确“这个备用层能补多少主包裹”和“具体补哪几个”:
- Protection Length(保护长度):填写“能补的主包裹的总尺寸”,比如主包裹每个100字节,补2个就是200字节,确保补包时不会“尺寸 mismatch”;
- mask(掩码):用“0”和“1”标记保护范围——比如掩码是“1100”(4位),表示“补第1个和第2个主包裹”(1=保护,0=不保护),L flag=1时掩码更长,能标记更多主包裹。
关键细节:
掩码的“基准”是FEC头中的SN base——比如SN base=100,掩码第0位是1,就表示保护SN=100的主包裹;第1位是1,就表示保护SN=101的主包裹,以此类推,避免保护范围混淆。
1.2 保护规则:避免“备用数据浪费”的3条约定
为了让备用数据(FEC包)既有效又不占用太多网络带宽,ULPFEC定了3条“使用规矩”,结合上述图片实例更易理解:
- 规则a:媒体数据包在高于0级别的等级中只能被保护一次,但是可以在0级别中被多个FEC包保护(只要这些FEC包在0级别的保护长度相等)。
例:A、B在Level 1只被FEC包2保护一次,但在Level 0可以被FEC包1保护(若有其他FEC包,也能在Level 0保护A、B)——避免高级别重复保护导致“备用页冗余”,同时允许基础层多保护应对随机丢包。 - 规则b:如果媒体数据包在p级别被保护,那么它也必须在p-1级别被保护(保护p级别的FEC包和p-1级别的FEC包可能不是同一个)。
例:A、B在Level 1被FEC包2保护,就必须在Level 0被FEC包1保护——不能只给A、B配“能补4本的备用页(Level 1)”,却不配“能补2本的备用页(Level 0)”,否则丢A时,用Level 1的备用页补效率低。 - 规则c:如果FEC包包含p级别保护,那么它也必须包含p-1级别保护(p级别保护的数据包可能和p-1级别保护的数据包不是同一个)。
例FEC包2包含Level 1保护(A、B、C、D),就必须包含Level 0保护(C、D)——不能让一个备用页只“能补4本”却“不能补2本”,否则丢C时,需要先解Level 1的复杂逻辑,影响补包速度。
保护组合示例
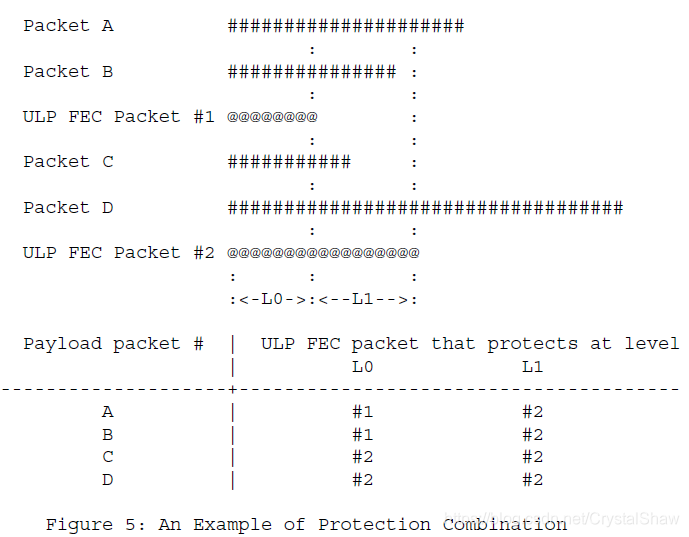
该图分为上下两部分,上部分是“数据包与FEC包的对应关系表”,下部分是“分级保护示意图”:
- 上部分表格:行是媒体数据包A、B、C、D和FEC包1(ULP FEC Packet #1)、FEC包2(##2),列是保护级别,FEC包1的“0级别”列标有“@@@@@@@”(表示保护),FEC包2的“0级别”和“1级别”列都标有“##”(表示保护);
- 下部分示意图:横向是媒体包A、B、C、D,纵向是保护级别Level 0和Level 1,FEC包1在Level 0覆盖A、B,FEC包2在Level 0覆盖C、D,在Level 1覆盖A、B、C、D。
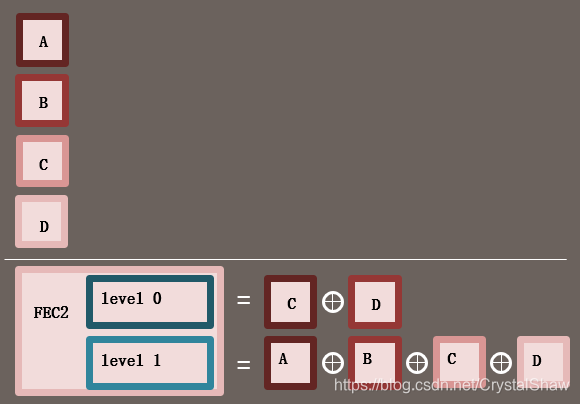
通俗解释:
这张图是“漫画书与备用页的保护关系表”,清晰展示了2个FEC包如何保护4个媒体包:
- FEC包1(备用页1):只在“基础层(Level 0)”工作,负责补A、B两本漫画书——如果A或B丢了,用这个备用页就能拼出来;
- FEC包2(备用页2):同时在“基础层(Level 0)”和“高级层(Level 1)”工作:
- Level 0:补C、D两本漫画书;
- Level 1:补A、B、C、D四本漫画书——如果同时丢了A、C,用这个备用页的Level 1保护就能一起补出来。
关键细节:
这个示例完美体现了ULPFEC的“分级保护优势”:Level 0应对“单个/少量丢包”(如丢A),Level 1应对“多个/连续丢包”(如丢A、B、C),两个FEC包配合就能覆盖大部分丢包场景,同时避免备用数据过多浪费带宽。
FEC Level Header for FEC之mask
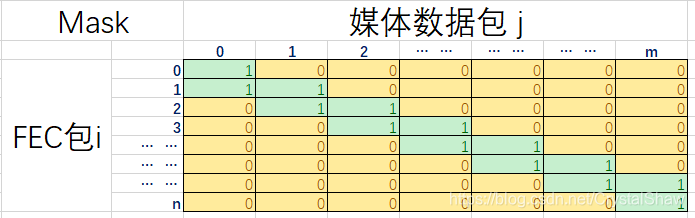
上图是FEC Level Header里面的mask
根据RFC5109定义,一个媒体数据包可以被多个FEC包保护,一个FEC包可以多保护多个媒体数据包。
假设m个媒体数据包需要n个FEC数据包保护,则可以定义一个如上图所示的二维的m * n零一矩阵来描述媒体数据包在fec包中的保护分布情况:
1)矩阵中元素m[i, j]置1表示第j个媒体数据包需要第i个FEC包保护。
2)从行角度来看,第i行元素表示第i个FEC包保护的媒体数据包的集合;
3)从列角度讲,第j列元素表示保护第j个媒体数据包的FEC包的集合。
由于该矩阵是零一矩阵,因此在存储上可以采用掩码来存储。这个掩码也就是FEC Level Header中所定义的mask掩码。
那么掩码中的0、1如何分布?现实世界中网络丢包分为随机丢包、突发丢包两种情况,FEC包需要能够针对这两种情况对媒体数据包进行保护。WebRTC预先构造两个掩码表kPacketMaskRandomTbl和kPacketMaskBurstyTbl,以模拟在随机情况和突发情况下媒体数据包在FEC包中的保护分配情况。
假设在随机丢包场景下,对于m * n的情况,我们只需要从kPacketMaskRandomTbl[m][n]就可以获取FEC包所需要的全部掩码,然后该掩码为基础,构造FEC数据包。
2、核心源码
WebRTC中ULPFEC的实现核心集中在UlpfecGenerator::AddRtpPacketAndGenerateFec(添加媒体包并生成FEC包)和GeneratePacketMasks(生成掩码,确定FEC包保护哪些媒体包)两个函数。以下是完整源码及注释:
(一)AddRtpPacketAndGenerateFec函数:FEC包的“生产入口”
功能:接收媒体数据包,判断是否满足生成FEC包的条件(如媒体包数量足够、带宽开销合理),若满足则调用编码接口生成FEC包(对应Figure 5中“FEC包生成逻辑”)。
// 函数头注释:
// 类:UlpfecGenerator(ULPFEC生成器,负责将媒体包转换为FEC包)
// 函数名:AddRtpPacketAndGenerateFec
// 功能:添加一个RTP媒体数据包到保护队列,当满足条件时生成FEC包
// 参数:
// - rtp_packet:待添加的RTP媒体数据包(const引用,避免拷贝)
// - complete_frame:标记当前媒体包是否为一帧的最后一个包(bool类型,true表示一帧结束,用于控制FEC生成时机)
// - generated_fec_packets:输出参数(vector引用,存储生成的FEC包)
// 返回值:int,错误码(0表示成功,非0表示失败,如参数无效、编码出错)
int UlpfecGenerator::AddRtpPacketAndGenerateFec(const RtpPacket& rtp_packet, bool complete_frame, std::vector<std::unique_ptr<RtpPacket>>* generated_fec_packets) {// 1. 校验输出参数是否有效(避免空指针访问,导致程序崩溃)if (!generated_fec_packets) {return -1; // 参数无效,返回错误码-1}// 2. 将当前媒体包添加到保护队列(media_packets_是类的成员变量,存储待保护的媒体包集合)// 调用Copy()拷贝媒体包,避免原包被外部修改(如原包被释放导致野指针)media_packets_.push_back(rtp_packet.Copy()); // 3. 统计已保护的帧数(num_protected_frames_是成员变量,记录当前已处理的完整帧数)if (complete_frame) {num_protected_frames_++;}// 4. 判断是否满足生成FEC包的条件(两个条件满足其一即可,对应“何时生成FEC包”的逻辑):// 条件1:已保护的帧数达到配置的最大帧数(params_.max_fec_frames,如每2帧生成一次FEC)// 条件2:(1)实际带宽开销与目标开销的差值小于允许的最大超额开销(kMaxExcessOverhead,如5%,避免FEC包过多)// (2)已收集的媒体包数量达到最小要求(MinimumMediaPacketsReached())if (complete_frame && (num_protected_frames_ == params_.max_fec_frames || (ExcessOverheadBelowMax() && MinimumMediaPacketsReached()))) {// 5. 配置FEC编码参数:关闭非均匀保护(目前WebRTC的视频编码器采用“单Slice编码”(一帧视频分成1个数据块),每个RTP包的重要性差不多,少了任何一个都不会导致整帧无法解码),因此无需给某些包额外分配更多FEC保护。若未来支持“多Slice编码”(一帧分成多个块,首块包含PPS/SPS等关键信息),非均匀保护可能会被启用,此时mask会针对首块做特殊标记(更多1)。)constexpr bool kUseUnequalProtection = false; // 非均匀保护开关(false=关闭,true=开启)constexpr int kNumImportantPackets = 0; // 重要媒体包数量(0表示所有包同等重要,无优先级)// 6. 调用FEC编码接口生成FEC包(核心步骤,对应“FEC包如何保护媒体包”)// fec_:FEC编码器实例(类成员变量,基于RFC5109实现,负责生成FEC头、Level头和Payload)// EncodeFec参数说明:// - media_packets_:待保护的媒体包队列// - params_.fec_rate:FEC码率(如5%,表示FEC包占用带宽为媒体包的5%,控制开销)// - kNumImportantPackets:重要包数量(0=无重要包,均匀保护)// - kUseUnequalProtection:是否启用非均匀保护(false=禁用,使用均匀保护)// - params_.fec_mask_type:掩码类型(如随机掩码kPacketMaskRandomTbl,对应mask生成逻辑)// - generated_fec_packets:输出生成的FEC包int ret = fec_->EncodeFec(media_packets_,params_.fec_rate,kNumImportantPackets,kUseUnequalProtection,params_.fec_mask_type,generated_fec_packets);// 7. 若生成的FEC包为空(如编码失败),重置生成器状态(避免残留数据影响下一次生成)if (generated_fec_packets->empty()) {ResetState(); // 重置媒体包队列、已保护帧数等成员变量}// 8. 返回编码结果(0=成功,非0=失败,如码率超限、媒体包不足)return ret;}// 9. 未满足生成条件(如媒体包数量不够、帧数未到),仅添加媒体包,不生成FEC包,返回成功return 0;
}// 辅助函数:ResetState(重置生成器状态,为下一轮FEC生成做准备)
// 功能:清空待保护的媒体包队列、重置已保护帧数,避免上一轮数据干扰
void UlpfecGenerator::ResetState() {media_packets_.clear(); // 清空媒体包队列,准备接收新包num_protected_frames_ = 0; // 重置已保护帧数为0
}
(二)GeneratePacketMasks函数:FEC包的“保护范围配置器”
功能:根据媒体包数量、FEC包数量、保护模式(均匀/非均匀),生成掩码(mask),确定每个FEC包具体保护哪些媒体包。
// 函数头注释:
// 函数名:GeneratePacketMasks
// 功能:生成FEC包的保护掩码,描述每个FEC包对媒体包的保护关系
// 参数:
// - num_media_packets:待保护的媒体包总数,对应FEC Level Header for FEC之mask图片中矩阵m,
// - num_fec_packets:要生成的FEC包总数,对应FEC Level Header for FEC之mask图片中矩阵n)
// - num_imp_packets:重要媒体包数量(如1个,表示第一个包更重要,当前默认0)
// - use_unequal_protection:是否启用非均匀保护(true=启用,false=禁用,默认false)
// - mask_table:掩码表(包含预定义的随机掩码表kPacketMaskRandomTbl和突发掩码表kPacketMaskBurstyTbl)
// - packet_mask:输出参数(uint8_t指针),存储生成的掩码数据(每个bit代表一个媒体包是否被保护,1=保护,0=不保护)
// 断言(assert):确保输入参数合法(如媒体包数量>0,FEC包数量在合理范围,避免逻辑错误)
void GeneratePacketMasks(int num_media_packets,int num_fec_packets,int num_imp_packets,bool use_unequal_protection,const PacketMaskTable& mask_table,uint8_t* packet_mask) {// 1. 输入参数合法性校验(断言失败表示参数错误,程序终止,用于调试阶段发现问题)assert(num_media_packets > 0); // 媒体包数量必须大于0assert(num_fec_packets <= num_media_packets && num_fec_packets > 0); // FEC包数量需在(0, 媒体包数量](如2≤4且>0)assert(num_imp_packets <= num_media_packets && num_imp_packets >= 0); // 重要包数量需在[0, 媒体包数量](如0≤4)assert(packet_mask != nullptr); // 输出掩码指针不能为空(避免写空指针导致崩溃)// 2. 计算掩码所需的字节数(每个媒体包用1个bit表示,8个bit=1个字节,向上取整)// 例:num_media_packets=4 → (4+7)/8=1字节;num_media_packets=9 → (9+7)/8=2字节const int num_mask_bytes = PacketMaskSize(num_media_packets); // PacketMaskSize是辅助函数,实现逻辑:return (num_media_packets + 7) / 8;// 3. 处理“均匀保护”场景(默认场景,所有媒体包同等重要)if (!use_unequal_protection || num_imp_packets == 0) {// 均匀保护:直接从预定义掩码表中获取掩码(无需额外调整)// 掩码表索引规则:mask_table.fec_packet_mask_table()[m - n][n - 1]// 例:m=4(媒体包),n=2(FEC包)→ 索引[4-2][2-1] = [2][1],获取“4个媒体包用2个FEC包保护”的预定义掩码const uint8_t* predefined_mask = mask_table.fec_packet_mask_table()[num_media_packets - num_fec_packets][num_fec_packets - 1];// 将预定义掩码拷贝到输出参数(memcpy:内存拷贝函数,确保掩码数据正确传递到packet_mask)// 拷贝长度:每个FEC包的掩码字节数 × FEC包数量(如1字节/包 × 2包 = 2字节)memcpy(packet_mask, predefined_mask, num_mask_bytes * num_fec_packets);return; // 均匀保护处理完成,返回(无需执行后续非均匀保护逻辑)}// 4. 处理“非均匀保护”场景(当前WebRTC默认不启用,预留接口,用于媒体包有优先级的场景)// 非均匀保护:重要包(前num_imp_packets个)分配更多FEC保护,普通包分配较少保护(如PPS/SPS包比普通视频包重要)else {// 调用UnequalProtectionMask函数生成非均匀保护掩码(具体实现见下方,支持3种模式)UnequalProtectionMask(num_media_packets,num_fec_packets,num_imp_packets,num_mask_bytes,packet_mask,mask_table);}
}// 辅助函数:UnequalProtectionMask(生成非均匀保护掩码,预留接口)
// 功能:为重要媒体包和普通媒体包分配不同的FEC保护力度,支持3种模式(对应不同优先级场景)
// 参数与GeneratePacketMasks一致,新增num_mask_bytes(每个FEC包的掩码字节数)
void UnequalProtectionMask(int num_media_packets,int num_fec_packets,int num_imp_packets,int num_mask_bytes,uint8_t* packet_mask,const PacketMaskTable& mask_table) {// 非均匀保护的3种模式(WebRTC定义,应对不同优先级场景)enum class UnequalMode {kModeNoOverlap, // 非叠加模式:重要包的掩码和普通包的掩码完全分离(互不干扰)kModeOverlap, // 叠加模式:重要包的掩码和普通包的掩码叠加(部分FEC包同时保护两种包)kModeBiasFirstPacket // 首包优先模式:在均匀保护基础上,所有FEC包都保护第一个包(第一个包最重要)};// 步骤1:配置非均匀保护参数(此处以kModeNoOverlap为例,其他模式逻辑类似)UnequalMode mode = UnequalMode::kModeNoOverlap;int num_fec_for_imp = num_fec_packets / 2; // 分配给重要包的FEC数量(如2个FEC包中分配1个给重要包)int num_fec_for_norm = num_fec_packets - num_fec_for_imp; // 分配给普通包的FEC数量(剩余1个给普通包)// 步骤2:生成重要包的掩码(前num_imp_packets个包,如前1个包是重要包)const uint8_t* imp_mask = mask_table.fec_packet_mask_table()[num_imp_packets - num_fec_for_imp][num_fec_for_norm - 1];// 步骤3:生成普通包的掩码(剩余num_media_packets - num_imp_packets个包,如后3个包是普通包)const uint8_t* norm_mask = mask_table.fec_packet_mask_table()[(num_media_packets - num_imp_packets) - num_fec_for_norm][num_fec_for_norm - 1];// 步骤4:根据模式组合掩码(以kModeNoOverlap为例,非叠加组合,避免保护范围冲突)switch (mode) {case UnequalMode::kModeNoOverlap:// 重要包掩码放在前num_fec_for_imp个FEC包,普通包掩码放在后num_fec_for_norm个FEC包memcpy(packet_mask, imp_mask, num_mask_bytes * num_fec_for_imp);memcpy(packet_mask + num_mask_bytes * num_fec_for_imp, norm_mask, num_mask_bytes * num_fec_for_norm);break;case UnequalMode::kModeOverlap:// 叠加模式:重要包掩码和普通包掩码拼接(每个FEC包同时包含两种掩码,覆盖更多场景)for (int i = 0; i < num_fec_packets; ++i) {uint8_t* current_fec_mask = packet_mask + i * num_mask_bytes;// 重要包部分掩码(前num_imp_packets个bit)memcpy(current_fec_mask, imp_mask + i * num_mask_bytes, num_mask_bytes);// 普通包部分掩码(后num_media_packets - num_imp_packets个bit)memcpy(current_fec_mask + (num_imp_packets + 7)/8, norm_mask + i * num_mask_bytes, num_mask_bytes);}break;case UnequalMode::kModeBiasFirstPacket:// 首包优先模式:先拷贝均匀保护掩码,再将所有FEC包的第一个bit(对应第一个媒体包)置1(确保首包被保护)GeneratePacketMasks(num_media_packets, num_fec_packets, 0, false, mask_table, packet_mask);for (int i = 0; i < num_fec_packets; ++i) {uint8_t* current_fec_mask = packet_mask + i * num_mask_bytes;// 将第一个bit置1(表示当前FEC包保护第一个媒体包,假设bit顺序是“高位在前”,第一个bit对应第7位)current_fec_mask[0] |= (1 << 7); }break;}
}
1