MySQL-TrinityCore异步连接池的学习(七)
一、异步连接池
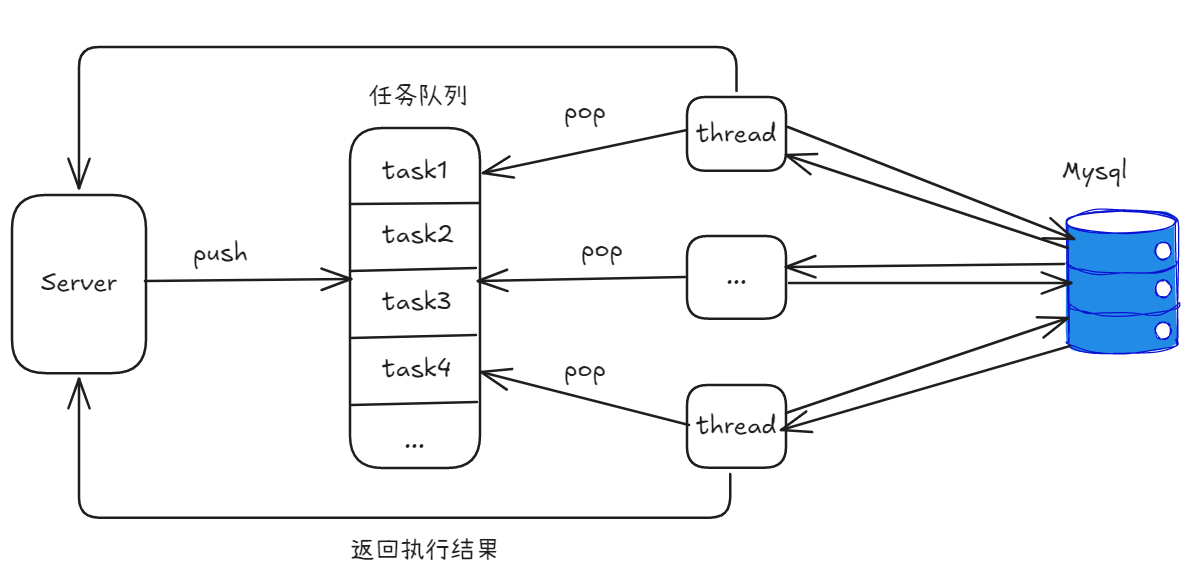
1.1、总体设计思路
异步连接池,可分为完全异步连接池以及半异步连接池两个部分;TrinityCore采用的是半异步连接池
大致流程如下:
1.2、多种异步操作方式
//DatabaseWorkerPool.h
template <class T>
class DatabaseWorkerPool
{public://......QueryCallback AsyncQuery(char const* sql); //单语句异步查询QueryCallback AsyncQuery(PreparedStatement<T>* stmt); //执行单个预编译语句的异步查询SQLQueryHolderCallback DelayQueryHolder(std::shared_ptr<SQLQueryHolder<T>> holder); // 延迟查询,批量异步查询// 事务支持SQLTransaction<T> BeginTransaction();void CommitTransaction(SQLTransaction<T> transaction);TransactionCallback AsyncCommitTransaction(SQLTransaction<T> transaction); // 事务的异步执行void DirectCommitTransaction(SQLTransaction<T>& transaction);void ExecuteOrAppend(SQLTransaction<T>& trans, char const* sql);void ExecuteOrAppend(SQLTransaction<T>& trans, PreparedStatement<T>* stmt);//......
};
从以上部分代码,可以看出,TrinityCore的异步连接池,提供了多种异步操作方式:单语句异步查询,多条语句异步查询,延迟查询,批量异步查询,以及事务的异步执行等。可以说是满足大部分场景的使用。
Tips: 同步连接池也存在多种操作方式.
1.3、业务抽象模式
- pipeline模式:将多个不相关的SQL语句一起处理,可以将本来多个SQL回调融合到一个回调中,使得逻辑更加清晰
- chain模式:将多个相关的SQL语句进行链式处理,采用责任链模式,展现SQL关联逻辑关联;同时多个相关联的SQL语句的回调在一个语句中,是这些闭包回调可复用相同的上下文
- transaction模式:实现将多个相关的SQL进行原子性处理
1. pipeline模式
将多个不相关的SQL语句一起处理,可以将本来多个SQL回调融合到一个回调中,使得逻辑更加清晰;减少服务器与数据库的交互次数,提高效率。
pipeline模式,主要是通过SQLQueryHolderCallback DelayQueryHolder(std::shared_ptr<SQLQueryHolder<T>> holder)来实现,将多个SQL语句封装到一个回调中;
- 先看下
SQLQueryHolderCallback是什么?
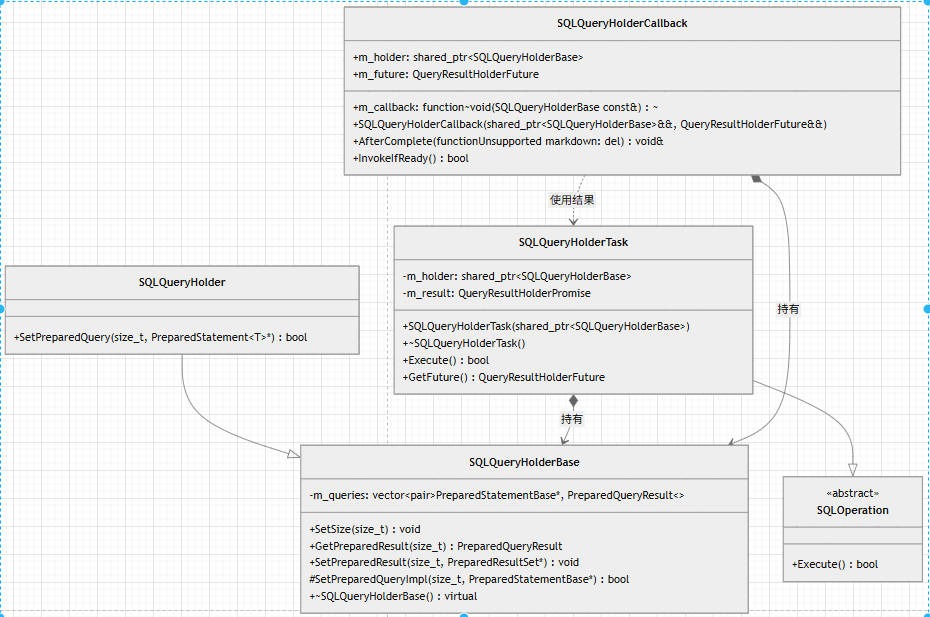
- SQLQueryHolderBase(查询容器基类)
```c++// 核心数据结构std::vector<std::pair<PreparedStatementBase*, PreparedQueryResult>> m_queries;```
- SQLQueryHolder(查询容器)```c++//进行查询设置bool SetPreparedQuery(size_t index, PreparedStatement<T>* stmt){return SetPreparedQueryImpl(index, stmt);}```
- SQLQueryHolderTask(查询任务)```c++// 继承自 SQLOperationstd::shared_ptr<SQLQueryHolderBase> m_holder; // 持有的查询容器QueryResultHolderPromise m_result; // 异步结果承诺bool Execute(); // 执行所有查询QueryResultHolderFuture GetFuture(); // 获取异步结果```
- SQLQueryHolderCallback(查询回调)```c++// 持有查询容器和异步结果std::shared_ptr<SQLQueryHolderBase> m_holder;QueryResultHolderFuture m_future;std::function<void(SQLQueryHolderBase const&)> m_callback;// 主要方法void AfterComplete(std::function<void(SQLQueryHolderBase const&)> callback);bool InvokeIfReady(); // 检查并触发回调 ```
- 流程示意

- DelayQueryHolder函数
SQLQueryHolderCallback DatabaseWorkerPool<T>::DelayQueryHolder(std::shared_ptr<SQLQueryHolder<T>> holder)
{// 创建批量查询任务SQLQueryHolderTask* task = new SQLQueryHolderTask(holder);// 存储异步结果,在入队前完成,防止任务执行后被删除QueryResultHolderFuture result = task->GetFuture();// 将任务加入异步队列Enqueue(task);// 返回查询回调,转移所有权return { std::move(holder), std::move(result) };
}
回顾下SQLQueryHolderCallback的构造函数
SQLQueryHolderCallback(std::shared_ptr<SQLQueryHolderBase>&& holder, QueryResultHolderFuture&& future): m_holder(std::move(holder)), m_future(std::move(future)) { }
回调触发机制
bool SQLQueryHolderCallback::InvokeIfReady()
{// 检查 future 是否就绪if (m_future.valid() && m_future.wait_for(std::chrono::seconds(0)) == std::future_status::ready) {// 触发用户设置的回调函数m_callback(*m_holder);return true; // 回调已执行}return false; // 结果尚未就绪
}
2. chain模式
***简而言之:***就是将多个异步查询按顺序连接起来,形成一个链式调用。每个查询的回调函数将作为下一个查询的输入参数或前置条件。
***Chain模式实现方式:***通过QueryCallback类来实现
- 先看下
QueryCallback类关键部分
class QueryCallback
{
private:union {QueryResultFuture _string;PreparedQueryResultFuture _prepared;};bool _isPrepared;// 关键:回调函数队列std::queue<QueryCallbackData, std::list<QueryCallbackData>> _callbacks;
};
- 链式调用机制
QueryCallback&& QueryCallback::WithChainingCallback(std::function<void(QueryCallback&, QueryResult)>&& callback)
{// 将回调函数加入队列_callbacks.emplace(std::move(callback));return std::move(*this); // 返回引用,支持链式调用
}
- 链式执行
bool QueryCallback::InvokeIfReady()
{QueryCallbackData& callback = _callbacks.front();auto checkStateAndReturnCompletion = [this]() // 链式回调处理{_callbacks.pop();bool hasNext = !_isPrepared ? _string.valid() : _prepared.valid();if (_callbacks.empty()){ASSERT(!hasNext);return true;}// abort chainif (!hasNext)return true;ASSERT(_isPrepared == _callbacks.front()._isPrepared);return false;};if (!_isPrepared) // 区分查询类型,是普通查询还是预处理查询{if (_string.valid() && _string.wait_for(std::chrono::seconds(0)) == std::future_status::ready){QueryResultFuture f(std::move(_string));std::function<void(QueryCallback&, QueryResult)> cb(std::move(callback._string));// 执行当前链节的回调cb(*this, f.get());// 移动到下一个链节_callbacks.pop();// 检查是否还有后续链节bool hasNext = _string.valid();if (_callbacks.empty()){return true; // 链结束}return false; // 链继续}}else{if (_prepared.valid() && _prepared.wait_for(std::chrono::seconds(0)) == std::future_status::ready){PreparedQueryResultFuture f(std::move(_prepared));std::function<void(QueryCallback&, PreparedQueryResult)> cb(std::move(callback._prepared));cb(*this, f.get());return checkStateAndReturnCompletion();}}return false;
}
3. transaction模式
事务,数据库操作中老生常谈的概念,是用户定义的,将多条命令打包,在服务端执行,要么全部执行,要么全部不执行。保证不会被其他命令加塞,打断。
在TrinityCore的异步连接池中,专门添加了transaction模式,用于处理数据库事务,确保数据库操作要么全部成功,要么全部失败。
- Transaction 类结构
template<class T>
class Transaction
{
private:friend class TransactionTask;// 存储事务中的所有操作std::list<SQLElementData> m_queries;public:// 添加原始 SQL 语句void Append(char const* sql);// 添加预编译语句void Append(PreparedStatement<T>* stmt);// 获取操作数量size_t GetSize() const { return m_queries.size(); }// 清理资源void Cleanup();
};
- 事务操作
// 事务中的元素类型
struct SQLElementData
{enum Type{SQL_ELEMENT_RAW, // 原始 SQLSQL_ELEMENT_PREPARED // 预编译语句};Type type;union{struct{char const* query; // 原始 SQL 字符串} sql;struct{PreparedStatementBase* stmt; // 预编译语句} prepared;} element;
};
- 事务执行方式
- 同步执行
template <class T> void DatabaseWorkerPool<T>::DirectCommitTransaction(SQLTransaction<T>& transaction) {T* connection = GetFreeConnection();int errorCode = connection->ExecuteTransaction(transaction);if (!errorCode){connection->Unlock(); // 操作成功return;}// 处理死锁错误 (MySQL Error 1213)if (errorCode == ER_LOCK_DEADLOCK){// 重试机制uint8 loopBreaker = 5;for (uint8 i = 0; i < loopBreaker; ++i){if (!connection->ExecuteTransaction(transaction))break;}}// 清理事务资源transaction->Cleanup();connection->Unlock(); }- 异步执行
template <class T>void DatabaseWorkerPool<T>::CommitTransaction(SQLTransaction<T> transaction){#ifdef TRINITY_DEBUG// 调试模式下的验证switch (transaction->GetSize()){case 0:TC_LOG_DEBUG("sql.driver", "Transaction contains 0 queries. Not executing.");return;case 1:TC_LOG_DEBUG("sql.driver", "Warning: Transaction only holds 1 query, consider removing Transaction context in code.");break;default:break;}#endif// 将事务任务加入异步队列Enqueue(new TransactionTask(transaction));}
- 异步执行
- 同步执行
1.4、小结
| 特性 | pipeline | chain | Transaction |
|---|---|---|---|
| 核心思想 | 批量并行执行多个独立的数据库查询,一次性获取所有结果 | 串行执行有依赖关系的查询,前一个查询的结果作为后一个查询的输入 | 原子执行多个数据库操作,要么全部成功,要么全部失败 |
| 数据依赖 | 无依赖 | 强依赖 | 业务逻辑依赖 |
| 数据一致性 | 数据快照一致 | 最终一致 | 强一致 |
| 复杂度 | 低 | 中 | 高 |
| 适用场景 | 需要同时加载多个独立但相关的数据、数据间没有强依赖关系 | 有依赖关系的复杂查询、需要按特定顺序加载数据 | 需要保证原子性的业务操作,如转账、订单处理等 |
二、性能测试与实践验证
测试代码如下:
#include "DatabaseEnv.h"
#include "DatabaseLoader.h"
#include "DatabaseWorkerPool.h"
#include "DatabaseEnvFwd.h"
#include "Log.h"
#include "MySQLThreading.h"
#include <chrono>
#include <thread>
#include <atomic>
#include <vector>void SyncQueryTest();
void AsyncQueryTest();int main()
{// 数据库初始化MySQL::Library_Init();DatabaseLoader loader;loader.AddDatabase(MyDatabase, "192.168.127.132;3306;root;123456;wk", 8, 2); // 开启8个异步线程,2个同步线程if (!loader.Load()) {TC_LOG_ERROR("test", "database connect error");return 1;}TC_LOG_INFO("test", "数据库连接成功,开始测试...");SyncQueryTest(); // 同步查询测试AsyncQueryTest(); // 异步查询测试MyDatabase.Close();MySQL::Library_End();TC_LOG_INFO("test", "所有测试完成^_^^_^^_^");return 0;
}void SyncQueryTest()
{TC_LOG_INFO("test", "=== 开始同步查询测试 ===");auto start_time = std::chrono::high_resolution_clock::now();// 同步原始SQL查询{TC_LOG_INFO("test", "=== 同步原始SQL查询 ===");auto result = MyDatabase.Query("SELECT * FROM tb_sanguo WHERE id <= 5");if(result){do{TC_LOG_INFO("test", "id=%u,name=%s,武力=%d,智力=%d,体力=%d,技力=%d",(*result)[0].GetUInt32(), //id(*result)[1].GetString(), //name(*result)[2].GetInt32(), //武力(*result)[3].GetInt32(), //智力(*result)[4].GetInt32(), //体力(*result)[5].GetInt32() //技力); }while(result->NextRow());}else{TC_LOG_ERROR("test", "同步原始SQL查询失败");}}// 同步预编译语句查询{TC_LOG_INFO("test", "=== 同步预编译语句查询 ===");auto stmt = MyDatabase.GetPreparedStatement(LOGIN_SEL_REALMLIST); stmt->setUInt32(0, 3); //查询id=3的记录auto result = MyDatabase.Query(stmt);if(result){TC_LOG_INFO("test", "id=%u,name=%s,武力=%d,智力=%d,体力=%d,技力=%d",(*result)[0].GetUInt32(), //id(*result)[1].GetString(), //name(*result)[2].GetInt32(), //武力(*result)[3].GetInt32(), //智力(*result)[4].GetInt32(), //体力(*result)[5].GetInt32() //技力); }else{TC_LOG_ERROR("test", "同步预编译语句查询失败");}}auto end_time = std::chrono::high_resolution_clock::now();auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end_time - start_time);TC_LOG_INFO("test", "同步查询总耗时: %lld 毫秒", duration.count());
}void AsyncQueryTest()
{TC_LOG_INFO("test", "=== 开始异步查询测试 ===");auto start_time = std::chrono::high_resolution_clock::now();std::atomic<int> completed_queries{0};const int total_queries = 3;// 存储回调对象std::vector<QueryCallback> query_callbacks;// 异步原始SQL查询{TC_LOG_INFO("test", "=== 异步原始SQL查询 ===");auto callback = MyDatabase.AsyncQuery("SELECT * FROM tb_sanguo WHERE id = 1").WithCallback([&completed_queries](QueryResult result){TC_LOG_INFO("test", "--- 异步原始SQL查询回调 ---");if (result){TC_LOG_INFO("test", "id=%u,name=%s,武力=%d,智力=%d,体力=%d,技力=%d",(*result)[0].GetUInt32(), //id(*result)[1].GetString(), //name(*result)[2].GetInt32(), //武力(*result)[3].GetInt32(), //智力(*result)[4].GetInt32(), //体力(*result)[5].GetInt32() //技力);}else{TC_LOG_ERROR("test", "异步原始SQL查询失败");}completed_queries++;});query_callbacks.push_back(std::move(callback));}// 异步预编译语句查询{TC_LOG_INFO("test", "=== 异步预编译语句查询 ===");auto stmt = MyDatabase.GetPreparedStatement(SAKILA_SEL_ACTOR_INFO);stmt->setUInt32(0, 2); // 查询id=2的记录auto callback = MyDatabase.AsyncQuery(stmt).WithPreparedCallback([&completed_queries](PreparedQueryResult result){TC_LOG_INFO("test", "--- 异步预编译语句查询回调 ---");if (result){TC_LOG_INFO("test", "id=%u,name=%s,武力=%d,智力=%d,体力=%d,技力=%d",(*result)[0].GetUInt32(), //id(*result)[1].GetString(), //name(*result)[2].GetInt32(), //武力(*result)[3].GetInt32(), //智力(*result)[4].GetInt32(), //体力(*result)[5].GetInt32() //技力);}else{TC_LOG_ERROR("test", "异步预编译语句查询失败");}completed_queries++;});query_callbacks.push_back(std::move(callback));}// 异步批量查询{TC_LOG_INFO("test", "=== 异步批量查询 ===");auto callback = MyDatabase.AsyncQuery("SELECT * FROM tb_sanguo WHERE id <= 3").WithCallback([&completed_queries](QueryResult result){TC_LOG_INFO("test", "--- 异步批量查询回调 ---");if (result){do{TC_LOG_INFO("test", "id=%u,name=%s,武力=%d,智力=%d,体力=%d,技力=%d",(*result)[0].GetUInt32(), //id(*result)[1].GetString(), //name(*result)[2].GetInt32(), //武力(*result)[3].GetInt32(), //智力(*result)[4].GetInt32(), //体力(*result)[5].GetInt32() //技力);}while(result->NextRow());}else{TC_LOG_ERROR("test", "异步批量查询失败");}completed_queries++;});query_callbacks.push_back(std::move(callback));}// 等待所有异步完成 - 修复:使用正确的方式处理回调TC_LOG_INFO("test", "--- 等待异步查询完成 ---");while (completed_queries < total_queries){std::this_thread::sleep_for(std::chrono::milliseconds(10));// 手动检查每个回调是否就绪for (auto& callback : query_callbacks){callback.InvokeIfReady();}}auto end_time = std::chrono::high_resolution_clock::now();auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end_time - start_time);TC_LOG_INFO("test", "异步查询总耗时: %lld 毫秒", duration.count());
}
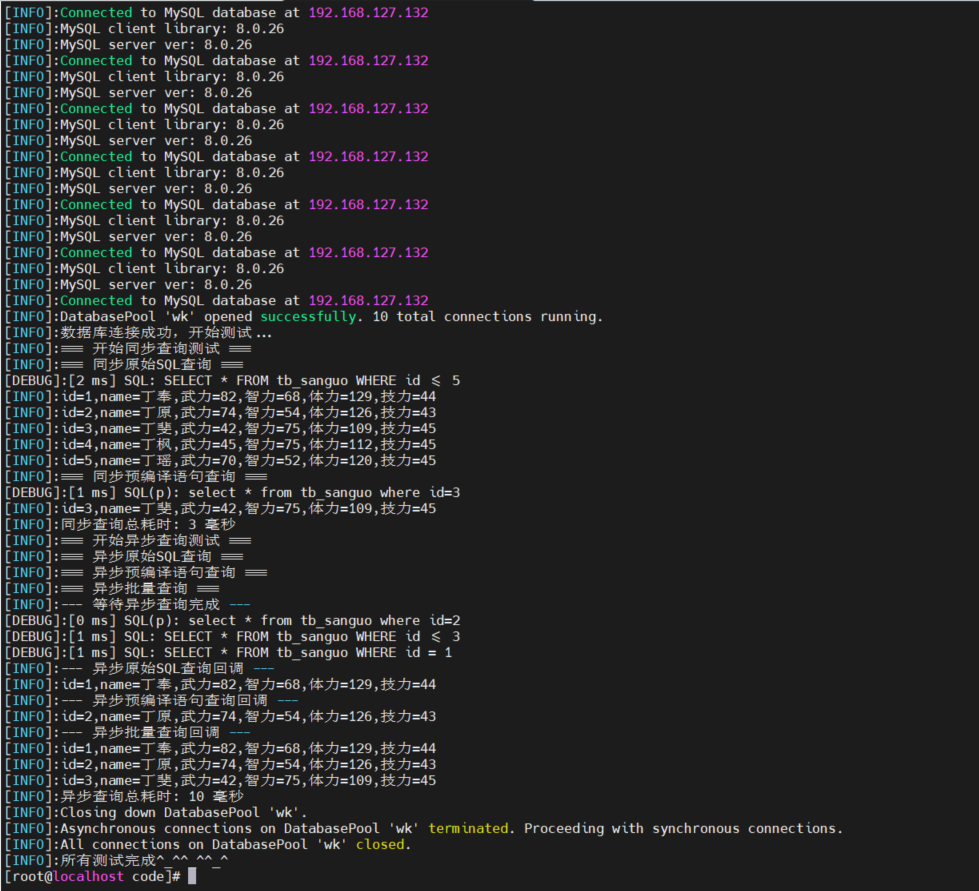
异步查询竟然比同步查询还要慢?
重新审视下代码,原来是这部分测试代码,数据量小,而且比较简单,所以看不出异步的优势。
异步慢的原因:
- 查询过于简单
- 异步的优势在于I/O等待,而查询执行太快
- I/O等待事件几乎为0—>异步的开销超过了优势
- 线程调度的开销:
- 异步查询需要在线程池中调度任务
- 线程切换、锁竞争、任务队列管理都有开销
- 同步查询直接在当前线程执行,没有这些开销
- 回调机制开销
- 异步查询需要设置回调函数、Promise/Future机制
- 结果需要在线程间传递
- 同步查询直接返回结果
- 连接池管理
- 异步查询需要从连接池获取连接、释放连接
- 同步查询可能重用当前连接
三、总结:
- 异步连接池
异步不是为了让单个查询更快,而是为了提高系统的整体吞吐量和响应性,不应滥用异步。
异步连接池的正真价值在于:
- 高并发时更好的性能
- 不阻塞主线程
- 更好的资源利用率
- 更快的系统响应时间,更好的用户体验
- 实践建议
- 避免滥用异步:在简单查询、低并发场景下,同步可能更优
- 合理选择模式:根据业务需求选择
Pipeline、Chain或Transaction模式 - 连接健康管理:在实际生产环境中加入连接有效性检测
- 性能监控:建立完善的性能监控体系,基于数据做优化决策